
JavaScript 資料結構與演算法之美 - 歸併排序、快速排序、希爾排序、堆排序

1. 前言
演算法為王。
想學好前端,先練好內功,只有內功深厚者,前端之路才會走得更遠。
筆者寫的 JavaScript 資料結構與演算法之美 系列用的語言是 JavaScript ,旨在入門資料結構與演算法和方便以後複習。
之所以把歸併排序、快速排序、希爾排序、堆排序放在一起比較,是因為它們的平均時間複雜度都為 O(nlogn)。
請大家帶著問題:快排和歸併用的都是分治思想,遞推公式和遞迴程式碼也非常相似,那它們的區別在哪裡呢 ? 來閱讀下文。
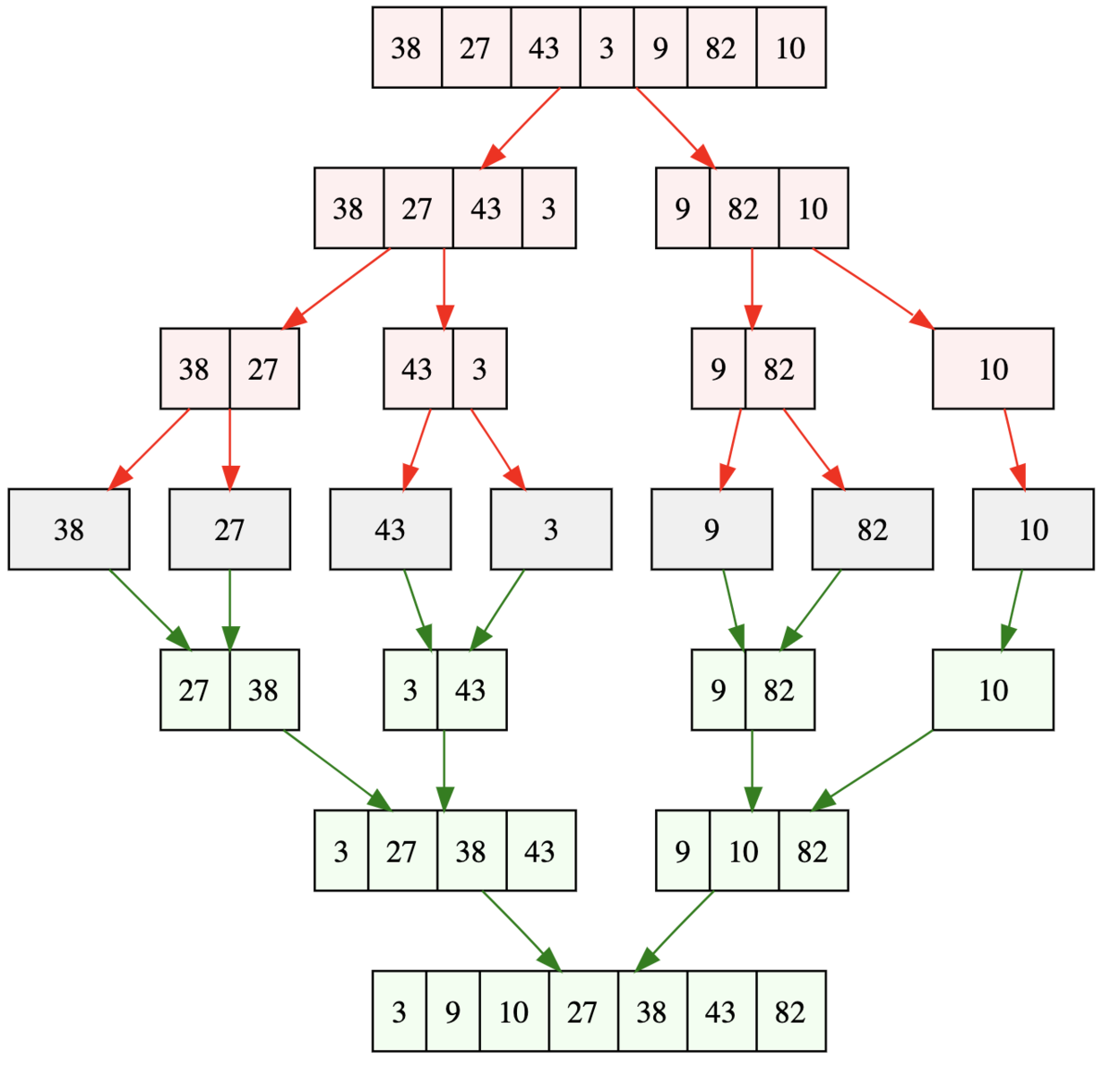
2. 歸併排序(Merge Sort)
思想
排序一個數組,我們先把陣列從中間分成前後兩部分,然後對前後兩部分分別排序,再將排好序的兩部分合並在一起,這樣整個陣列就都有序了。
歸併排序採用的是分治思想。
分治,顧名思義,就是分而治之,將一個大問題分解成小的子問題來解決。小的子問題解決了,大問題也就解決了。
注:x >> 1 是位運算中的右移運算,表示右移一位,等同於 x 除以 2 再取整,即 x >> 1 === Math.floor(x / 2) 。
實現
const mergeSort = arr => { //採用自上而下的遞迴方法 const len = arr.length; if (len < 2) { return arr; } // length >> 1 和 Math.floor(len / 2) 等價 let middle = Math.floor(len / 2), left = arr.slice(0, middle), right = arr.slice(middle); // 拆分為兩個子陣列 return merge(mergeSort(left), mergeSort(right)); }; const merge = (left, right) => { const result = []; while (left.length && right.length) { // 注意: 判斷的條件是小於或等於,如果只是小於,那麼排序將不穩定. if (left[0] <= right[0]) { result.push(left.shift()); } else { result.push(right.shift()); } } while (left.length) result.push(left.shift()); while (right.length) result.push(right.shift()); return result; };
測試
// 測試
const arr = [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48];
console.time('歸併排序耗時');
console.log('arr :', mergeSort(arr));
console.timeEnd('歸併排序耗時');
// arr : [2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
// 歸併排序耗時: 0.739990234375ms分析
第一,歸併排序是原地排序演算法嗎 ?
這是因為歸併排序的合併函式,在合併兩個有序陣列為一個有序陣列時,需要藉助額外的儲存空間。
實際上,儘管每次合併操作都需要申請額外的記憶體空間,但在合併完成之後,臨時開闢的記憶體空間就被釋放掉了。在任意時刻,CPU 只會有一個函式在執行,也就只會有一個臨時的記憶體空間在使用。臨時記憶體空間最大也不會超過 n 個數據的大小,所以空間複雜度是 O(n)。
所以,歸併排序不是原地排序演算法。第二,歸併排序是穩定的排序演算法嗎 ?
merge 方法裡面的 left[0] <= right[0] ,保證了值相同的元素,在合併前後的先後順序不變。歸併排序是一種穩定的排序方法。第三,歸併排序的時間複雜度是多少 ?
從效率上看,歸併排序可算是排序演算法中的佼佼者。假設陣列長度為 n,那麼拆分陣列共需 logn 步, 又每步都是一個普通的合併子陣列的過程,時間複雜度為 O(n),故其綜合時間複雜度為 O(nlogn)。
最佳情況:T(n) = O(nlogn)。
最差情況:T(n) = O(nlogn)。
平均情況:T(n) = O(nlogn)。
動畫
3. 快速排序 (Quick Sort)
快速排序的特點就是快,而且效率高!它是處理大資料最快的排序演算法之一。
思想
- 先找到一個基準點(一般指陣列的中部),然後陣列被該基準點分為兩部分,依次與該基準點資料比較,如果比它小,放左邊;反之,放右邊。
- 左右分別用一個空陣列去儲存比較後的資料。
- 最後遞迴執行上述操作,直到陣列長度 <= 1;
特點:快速,常用。
缺點:需要另外宣告兩個陣列,浪費了記憶體空間資源。
實現
方法一:
const quickSort1 = arr => {
if (arr.length <= 1) {
return arr;
}
//取基準點
const midIndex = Math.floor(arr.length / 2);
//取基準點的值,splice(index,1) 則返回的是含有被刪除的元素的陣列。
const valArr = arr.splice(midIndex, 1);
const midIndexVal = valArr[0];
const left = []; //存放比基準點小的陣列
const right = []; //存放比基準點大的陣列
//遍歷陣列,進行判斷分配
for (let i = 0; i < arr.length; i++) {
if (arr[i] < midIndexVal) {
left.push(arr[i]); //比基準點小的放在左邊陣列
} else {
right.push(arr[i]); //比基準點大的放在右邊陣列
}
}
//遞迴執行以上操作,對左右兩個陣列進行操作,直到陣列長度為 <= 1
return quickSort1(left).concat(midIndexVal, quickSort1(right));
};
const array2 = [5, 4, 3, 2, 1];
console.log('quickSort1 ', quickSort1(array2));
// quickSort1: [1, 2, 3, 4, 5]方法二:
// 快速排序
const quickSort = (arr, left, right) => {
let len = arr.length,
partitionIndex;
left = typeof left != 'number' ? 0 : left;
right = typeof right != 'number' ? len - 1 : right;
if (left < right) {
partitionIndex = partition(arr, left, right);
quickSort(arr, left, partitionIndex - 1);
quickSort(arr, partitionIndex + 1, right);
}
return arr;
};
const partition = (arr, left, right) => {
//分割槽操作
let pivot = left, //設定基準值(pivot)
index = pivot + 1;
for (let i = index; i <= right; i++) {
if (arr[i] < arr[pivot]) {
swap(arr, i, index);
index++;
}
}
swap(arr, pivot, index - 1);
return index - 1;
};
const swap = (arr, i, j) => {
let temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
};測試
// 測試
const array = [5, 4, 3, 2, 1];
console.log('原始array:', array);
const newArr = quickSort(array);
console.log('newArr:', newArr);
// 原始 array: [5, 4, 3, 2, 1]
// newArr: [1, 4, 3, 2, 5]分析
第一,快速排序是原地排序演算法嗎 ?
因為 partition() 函式進行分割槽時,不需要很多額外的記憶體空間,所以快排是原地排序演算法。第二,快速排序是穩定的排序演算法嗎 ?
和選擇排序相似,快速排序每次交換的元素都有可能不是相鄰的,因此它有可能打破原來值為相同的元素之間的順序。因此,快速排序並不穩定。第三,快速排序的時間複雜度是多少 ?
極端的例子:如果陣列中的資料原來已經是有序的了,比如 1,3,5,6,8。如果我們每次選擇最後一個元素作為 pivot,那每次分割槽得到的兩個區間都是不均等的。我們需要進行大約 n 次分割槽操作,才能完成快排的整個過程。每次分割槽我們平均要掃描大約 n / 2 個元素,這種情況下,快排的時間複雜度就從 O(nlogn) 退化成了 O(n2)。
最佳情況:T(n) = O(nlogn)。
最差情況:T(n) = O(n2)。
平均情況:T(n) = O(nlogn)。
動畫
解答開篇問題
快排和歸併用的都是分治思想,遞推公式和遞迴程式碼也非常相似,那它們的區別在哪裡呢 ?
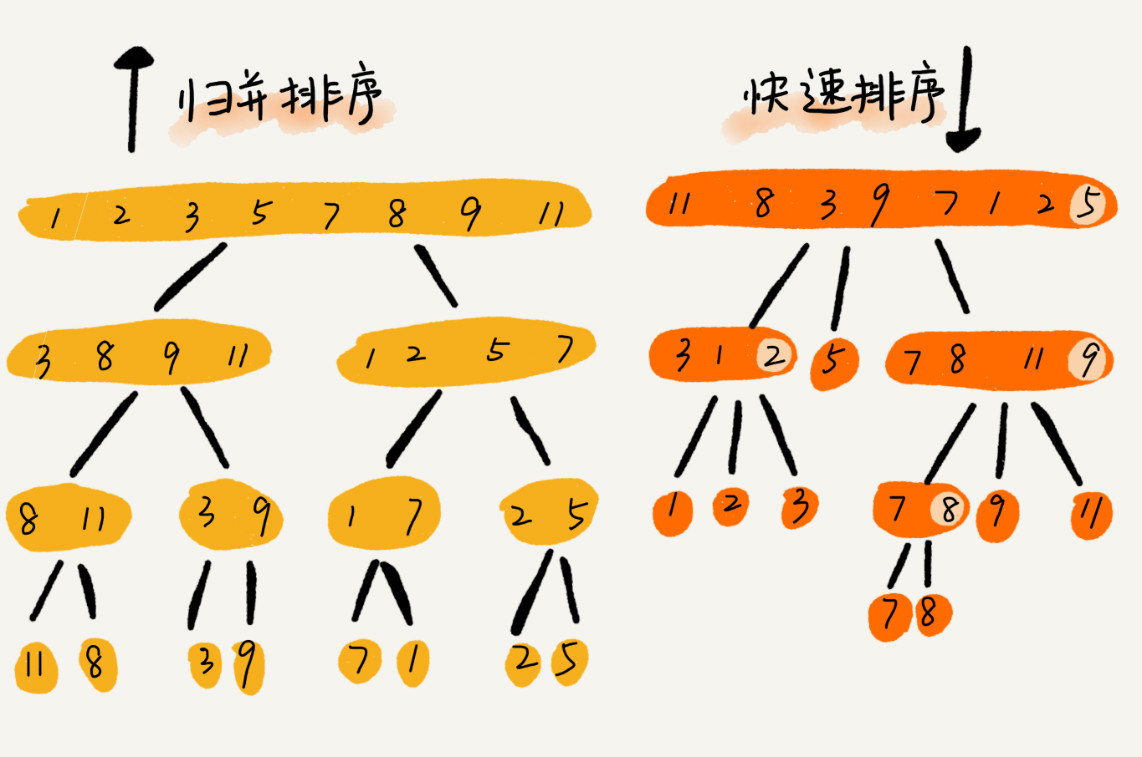
可以發現:
- 歸併排序的處理過程是
由下而上的,先處理子問題,然後再合併。 - 而快排正好相反,它的處理過程是
由上而下的,先分割槽,然後再處理子問題。 - 歸併排序雖然是穩定的、時間複雜度為 O(nlogn) 的排序演算法,但是它是非原地排序演算法。
- 歸併之所以是非原地排序演算法,主要原因是合併函式無法在原地執行。
- 快速排序通過設計巧妙的原地分割槽函式,可以實現原地排序,解決了歸併排序佔用太多記憶體的問題。
4. 希爾排序(Shell Sort)
思想
- 先將整個待排序的記錄序列分割成為若干子序列。
- 分別進行直接插入排序。
- 待整個序列中的記錄基本有序時,再對全體記錄進行依次直接插入排序。
過程
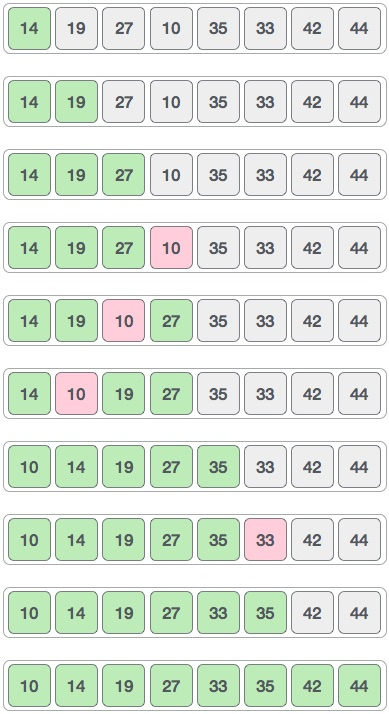
- 舉個易於理解的例子:[35, 33, 42, 10, 14, 19, 27, 44],我們採取間隔 4。建立一個位於 4 個位置間隔的所有值的虛擬子列表。下面這些值是 { 35, 14 },{ 33, 19 },{ 42, 27 } 和 { 10, 44 }。
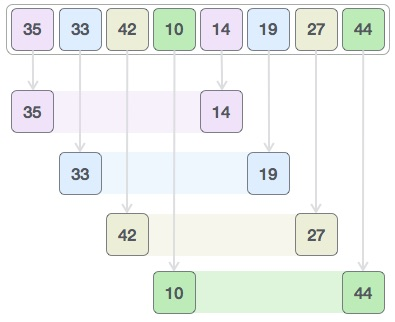
- 我們比較每個子列表中的值,並在原始陣列中交換它們(如果需要)。完成此步驟後,新陣列應如下所示。

- 然後,我們採用 2 的間隔,這個間隙產生兩個子列表:{ 14, 27, 35, 42 }, { 19, 10, 33, 44 }。
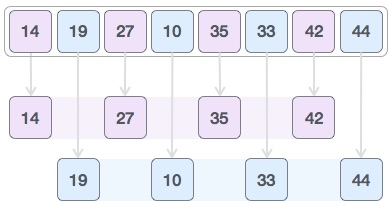
- 我們比較並交換原始陣列中的值(如果需要)。完成此步驟後,陣列變成:[14, 10, 27, 19, 35, 33, 42, 44],圖如下所示,10 與 19 的位置互換一下。

- 最後,我們使用值間隔 1 對陣列的其餘部分進行排序,Shell sort 使用插入排序對陣列進行排序。
實現
const shellSort = arr => {
let len = arr.length,
temp,
gap = 1;
console.time('希爾排序耗時');
while (gap < len / 3) {
//動態定義間隔序列
gap = gap * 3 + 1;
}
for (gap; gap > 0; gap = Math.floor(gap / 3)) {
for (let i = gap; i < len; i++) {
temp = arr[i];
let j = i - gap;
for (; j >= 0 && arr[j] > temp; j -= gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = temp;
console.log('arr :', arr);
}
}
console.timeEnd('希爾排序耗時');
return arr;
};測試
// 測試
const array = [35, 33, 42, 10, 14, 19, 27, 44];
console.log('原始array:', array);
const newArr = shellSort(array);
console.log('newArr:', newArr);
// 原始 array: [35, 33, 42, 10, 14, 19, 27, 44]
// arr : [14, 33, 42, 10, 35, 19, 27, 44]
// arr : [14, 19, 42, 10, 35, 33, 27, 44]
// arr : [14, 19, 27, 10, 35, 33, 42, 44]
// arr : [14, 19, 27, 10, 35, 33, 42, 44]
// arr : [14, 19, 27, 10, 35, 33, 42, 44]
// arr : [14, 19, 27, 10, 35, 33, 42, 44]
// arr : [10, 14, 19, 27, 35, 33, 42, 44]
// arr : [10, 14, 19, 27, 35, 33, 42, 44]
// arr : [10, 14, 19, 27, 33, 35, 42, 44]
// arr : [10, 14, 19, 27, 33, 35, 42, 44]
// arr : [10, 14, 19, 27, 33, 35, 42, 44]
// 希爾排序耗時: 3.592041015625ms
// newArr: [10, 14, 19, 27, 33, 35, 42, 44]分析
第一,希爾排序是原地排序演算法嗎 ?
希爾排序過程中,只涉及相鄰資料的交換操作,只需要常量級的臨時空間,空間複雜度為 O(1) 。所以,希爾排序是原地排序演算法。第二,希爾排序是穩定的排序演算法嗎 ?
我們知道,單次直接插入排序是穩定的,它不會改變相同元素之間的相對順序,但在多次不同的插入排序過程中,相同的元素可能在各自的插入排序中移動,可能導致相同元素相對順序發生變化。
因此,希爾排序不穩定。第三,希爾排序的時間複雜度是多少 ?
最佳情況:T(n) = O(n log n)。
最差情況:T(n) = O(n log2 n)。
平均情況:T(n) = O(n log2 n)。
動畫
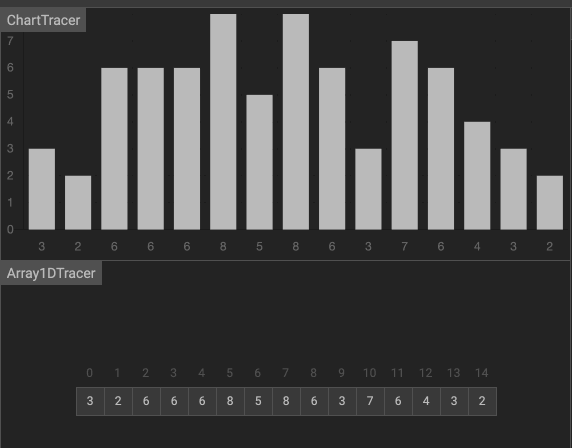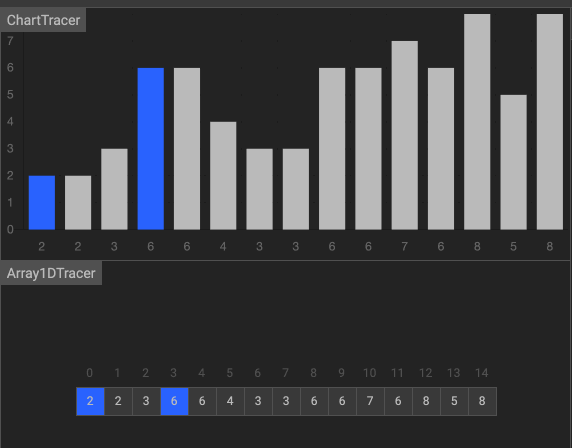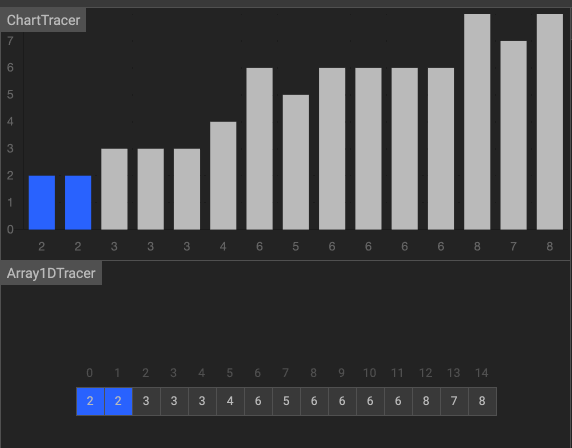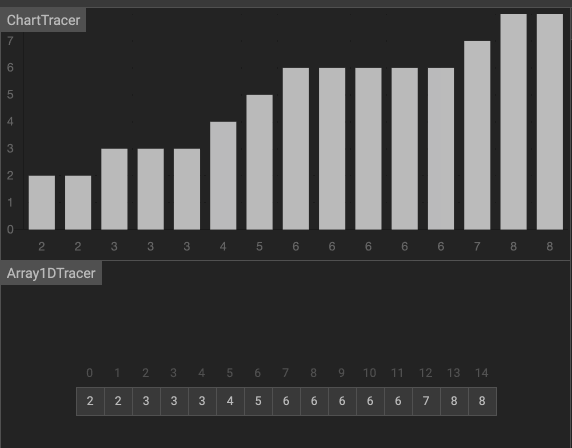
5. 堆排序(Heap Sort)
堆的定義
堆其實是一種特殊的樹。只要滿足這兩點,它就是一個堆。
- 堆是一個完全二叉樹。
完全二叉樹:除了最後一層,其他層的節點個數都是滿的,最後一層的節點都靠左排列。 - 堆中每一個節點的值都必須大於等於(或小於等於)其子樹中每個節點的值。
也可以說:堆中每個節點的值都大於等於(或者小於等於)其左右子節點的值。這兩種表述是等價的。
對於每個節點的值都大於等於子樹中每個節點值的堆,我們叫作大頂堆。
對於每個節點的值都小於等於子樹中每個節點值的堆,我們叫作小頂堆。
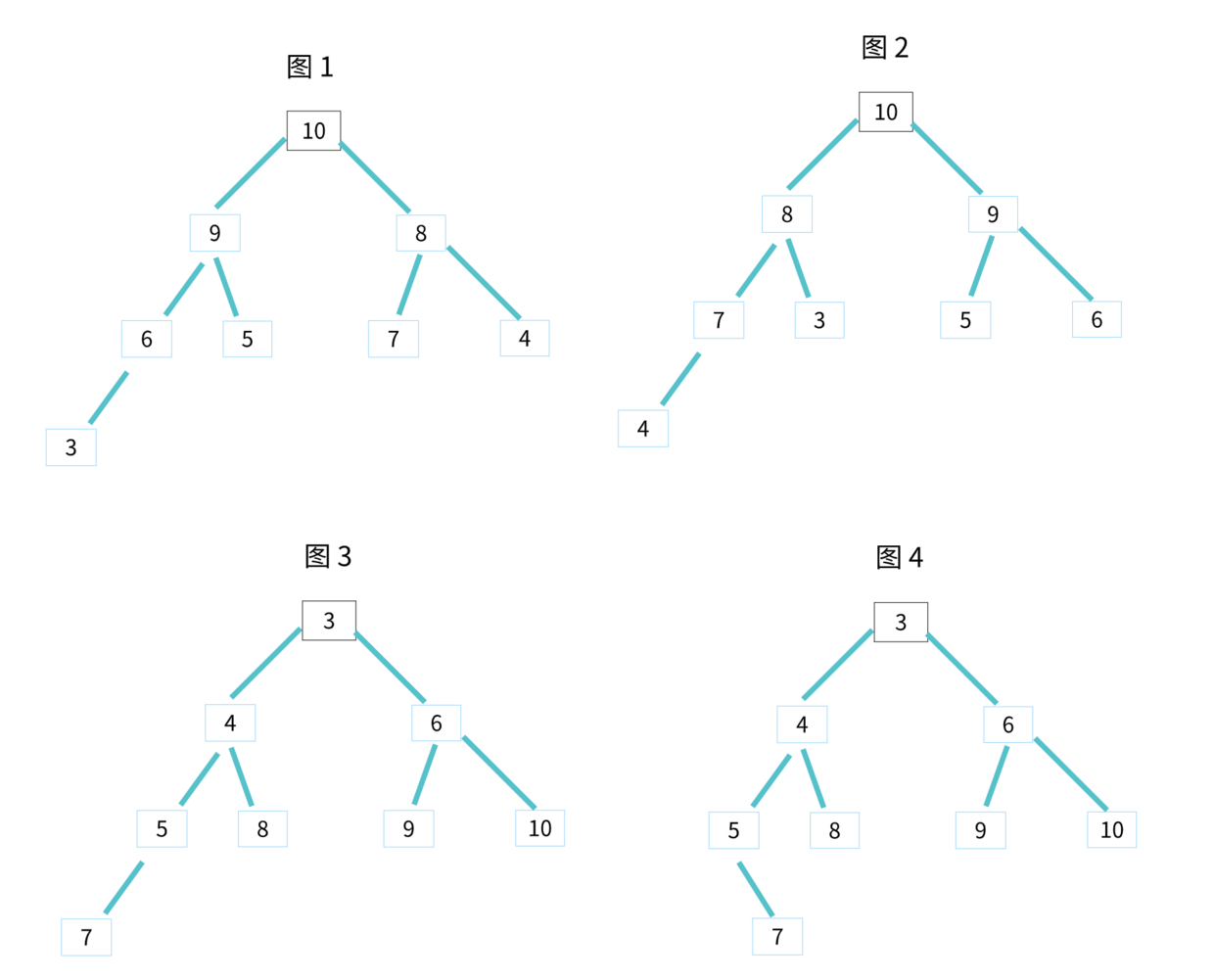
其中圖 1 和 圖 2 是大頂堆,圖 3 是小頂堆,圖 4 不是堆。除此之外,從圖中還可以看出來,對於同一組資料,我們可以構建多種不同形態的堆。
思想
- 將初始待排序關鍵字序列 (R1, R2 .... Rn) 構建成大頂堆,此堆為初始的無序區;
- 將堆頂元素 R[1] 與最後一個元素 R[n] 交換,此時得到新的無序區 (R1, R2, ..... Rn-1) 和新的有序區 (Rn) ,且滿足 R[1, 2 ... n-1] <= R[n]。
- 由於交換後新的堆頂 R[1] 可能違反堆的性質,因此需要對當前無序區 (R1, R2 ...... Rn-1) 調整為新堆,然後再次將 R[1] 與無序區最後一個元素交換,得到新的無序區 (R1, R2 .... Rn-2) 和新的有序區 (Rn-1, Rn)。不斷重複此過程,直到有序區的元素個數為 n - 1,則整個排序過程完成。
實現
// 堆排序
const heapSort = array => {
console.time('堆排序耗時');
// 初始化大頂堆,從第一個非葉子結點開始
for (let i = Math.floor(array.length / 2 - 1); i >= 0; i--) {
heapify(array, i, array.length);
}
// 排序,每一次 for 迴圈找出一個當前最大值,陣列長度減一
for (let i = Math.floor(array.length - 1); i > 0; i--) {
// 根節點與最後一個節點交換
swap(array, 0, i);
// 從根節點開始調整,並且最後一個結點已經為當前最大值,不需要再參與比較,所以第三個引數為 i,即比較到最後一個結點前一個即可
heapify(array, 0, i);
}
console.timeEnd('堆排序耗時');
return array;
};
// 交換兩個節點
const swap = (array, i, j) => {
let temp = array[i];
array[i] = array[j];
array[j] = temp;
};
// 將 i 結點以下的堆整理為大頂堆,注意這一步實現的基礎實際上是:
// 假設結點 i 以下的子堆已經是一個大頂堆,heapify 函式實現的
// 功能是實際上是:找到 結點 i 在包括結點 i 的堆中的正確位置。
// 後面將寫一個 for 迴圈,從第一個非葉子結點開始,對每一個非葉子結點
// 都執行 heapify 操作,所以就滿足了結點 i 以下的子堆已經是一大頂堆
const heapify = (array, i, length) => {
let temp = array[i]; // 當前父節點
// j < length 的目的是對結點 i 以下的結點全部做順序調整
for (let j = 2 * i + 1; j < length; j = 2 * j + 1) {
temp = array[i]; // 將 array[i] 取出,整個過程相當於找到 array[i] 應處於的位置
if (j + 1 < length && array[j] < array[j + 1]) {
j++; // 找到兩個孩子中較大的一個,再與父節點比較
}
if (temp < array[j]) {
swap(array, i, j); // 如果父節點小於子節點:交換;否則跳出
i = j; // 交換後,temp 的下標變為 j
} else {
break;
}
}
};測試
const array = [4, 6, 8, 5, 9, 1, 2, 5, 3, 2];
console.log('原始array:', array);
const newArr = heapSort(array);
console.log('newArr:', newArr);
// 原始 array: [4, 6, 8, 5, 9, 1, 2, 5, 3, 2]
// 堆排序耗時: 0.15087890625ms
// newArr: [1, 2, 2, 3, 4, 5, 5, 6, 8, 9]分析
- 第一,堆排序是原地排序演算法嗎 ?
整個堆排序的過程,都只需要極個別臨時儲存空間,所以堆排序是原地排序演算法。 第二,堆排序是穩定的排序演算法嗎 ?
因為在排序的過程,存在將堆的最後一個節點跟堆頂節點互換的操作,所以就有可能改變值相同資料的原始相對順序。
所以,堆排序是不穩定的排序演算法。第三,堆排序的時間複雜度是多少 ?
堆排序包括建堆和排序兩個操作,建堆過程的時間複雜度是 O(n),排序過程的時間複雜度是 O(nlogn),所以,堆排序整體的時間複雜度是 O(nlogn)。
最佳情況:T(n) = O(nlogn)。
最差情況:T(n) = O(nlogn)。
平均情況:T(n) = O(nlogn)。
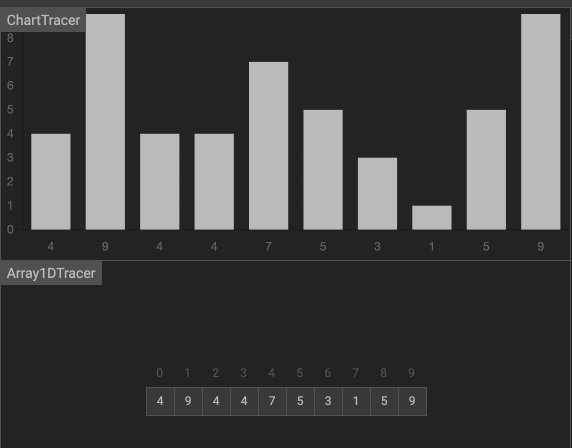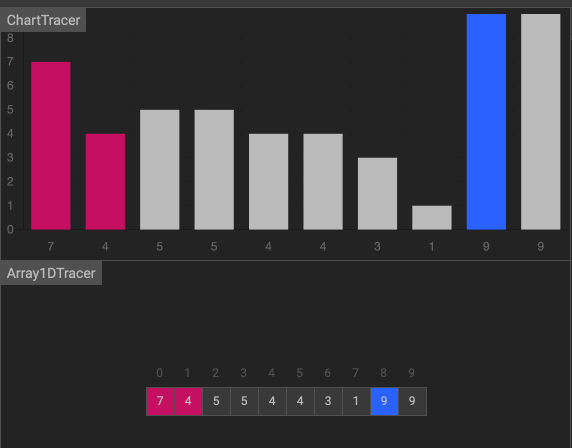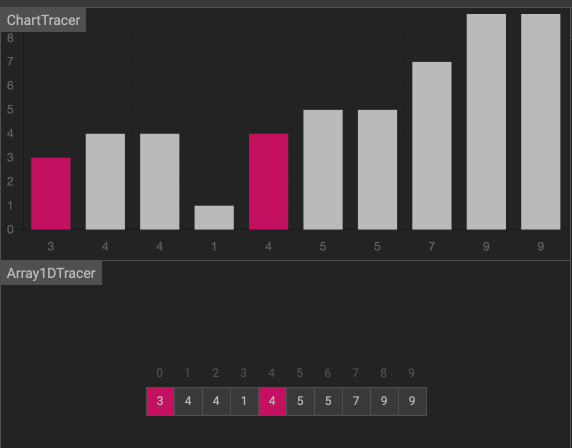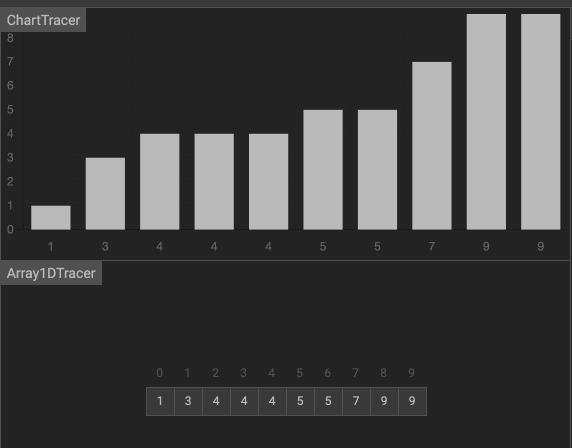
動畫

6. 排序演算法的複雜性對比
複雜性對比
| 名稱 | 平均 | 最好 | 最壞 | 空間 | 穩定性 | 排序方式 |
|---|---|---|---|---|---|---|
| 歸併排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | Yes | Out-place |
| 快速排序 | O(n log n) | O(n log n) | O(n2) | O(logn) | No | In-place |
| 希爾排序 | O(n log n) | O(n log2 n) | O(n log2 n) | O(1) | No | In-place |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | No | In-place |
演算法視覺化工具
- 演算法視覺化工具 algorithm-visualizer
演算法視覺化工具 algorithm-visualizer 是一個互動式的線上平臺,可以從程式碼中視覺化演算法,還可以看到程式碼執行的過程。
效果如下圖。
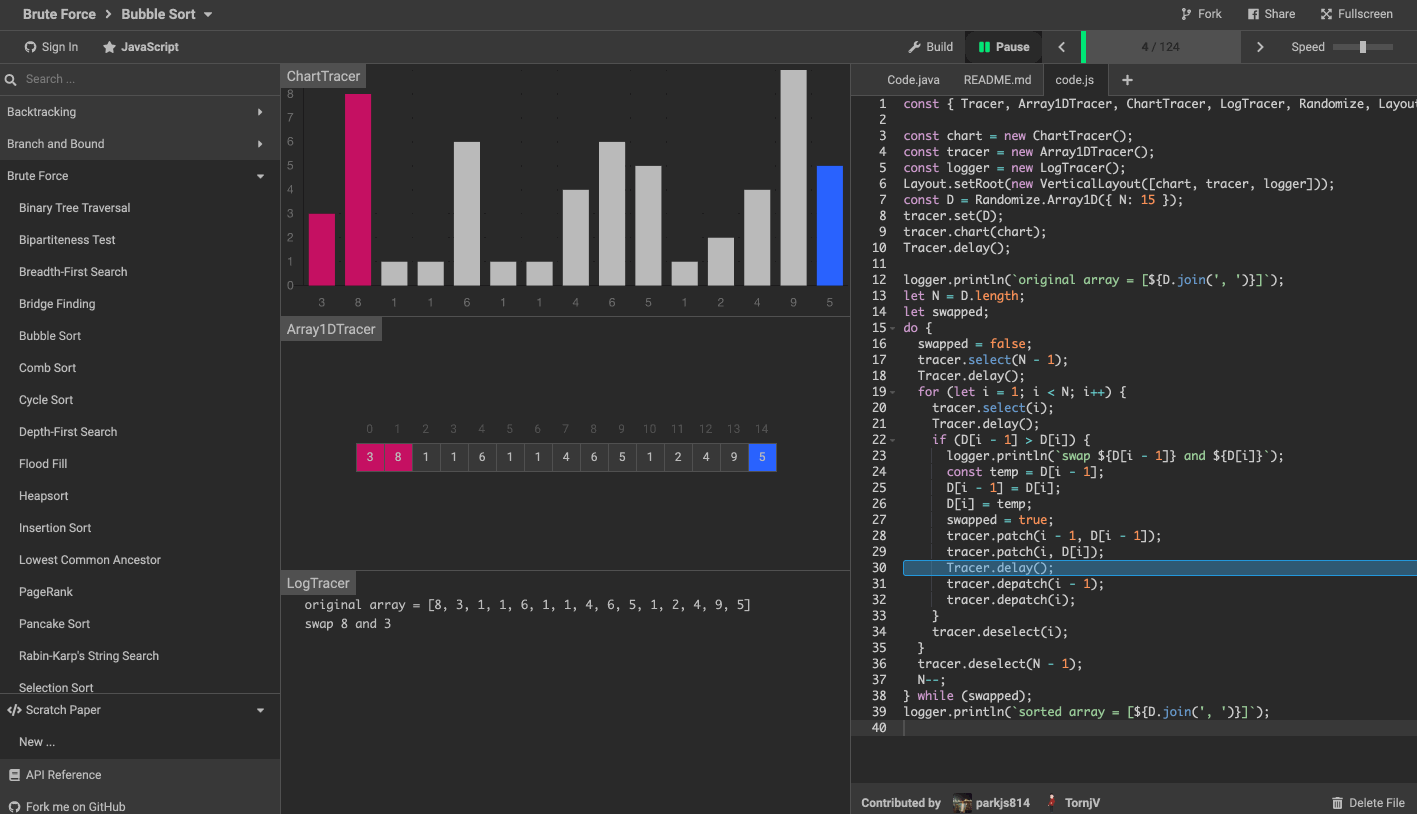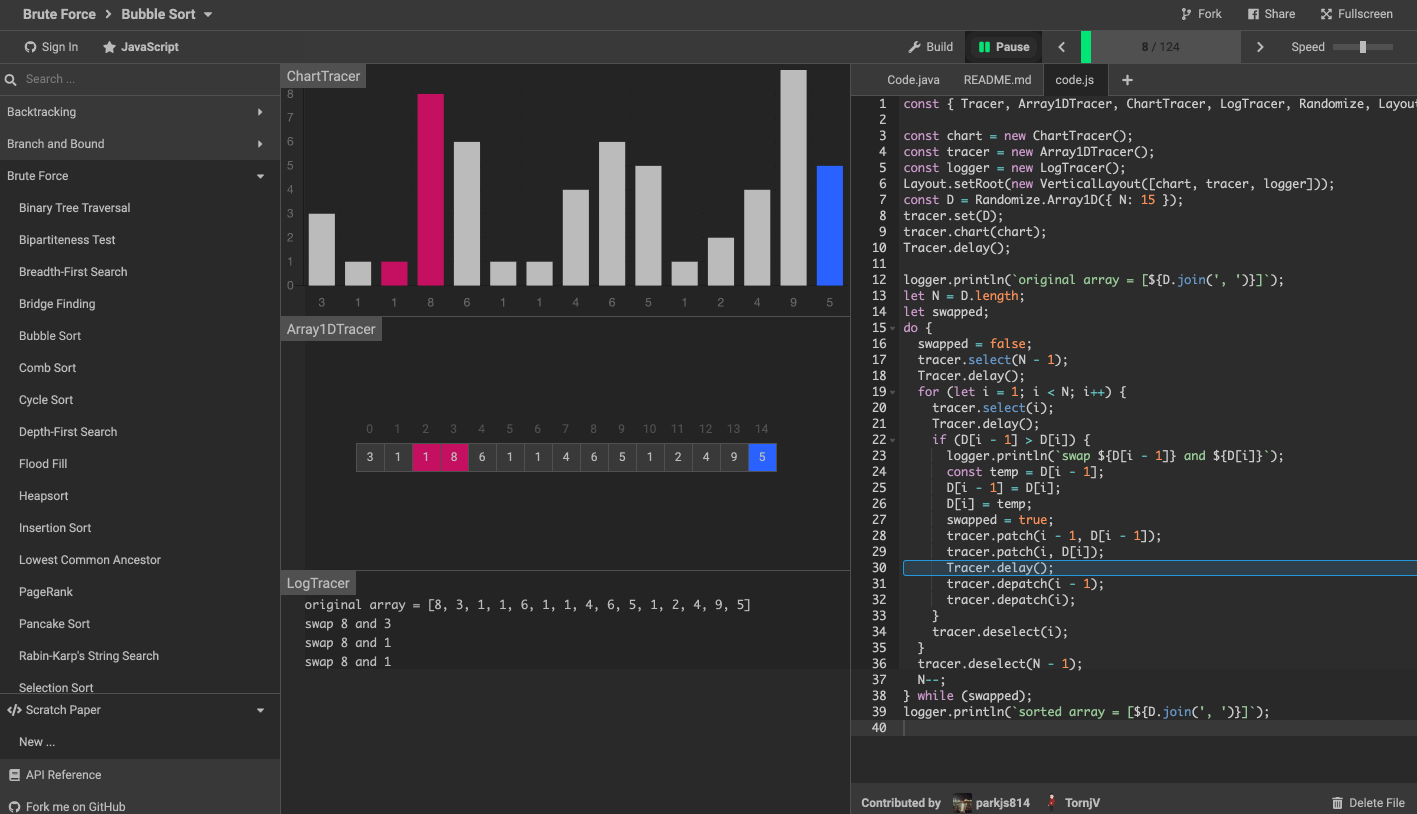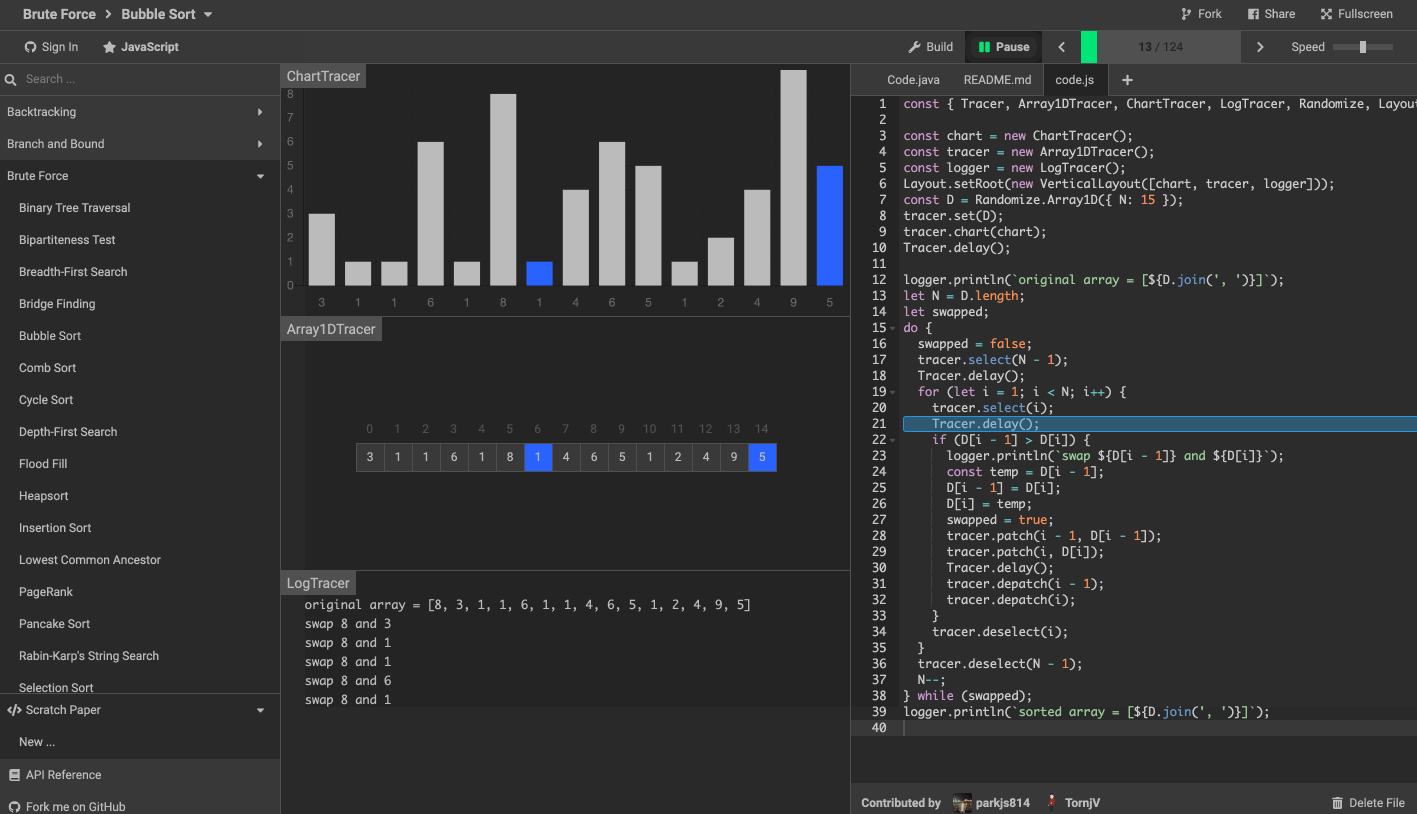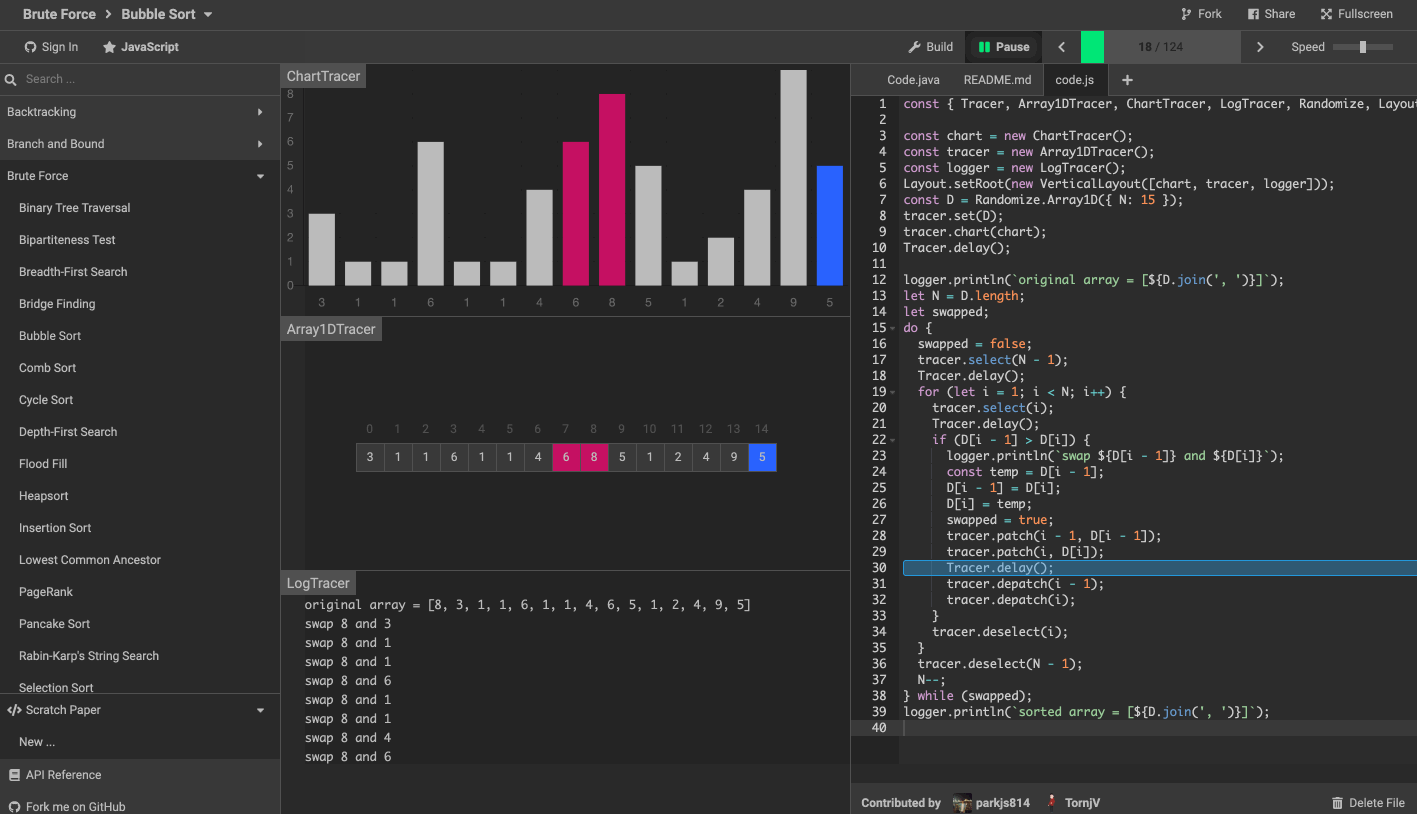
旨在通過互動式視覺化的執行來揭示演算法背後的機制。
演算法視覺化來源 https://visualgo.net/en
效果如下圖。
https://www.ee.ryerson.ca
- illustrated-algorithms
變數和操作的視覺化表示增強了控制流和實際原始碼。您可以快速前進和後退執行,以密切觀察演算法的工作方式。

7. 最後
文中所有的程式碼及測試事例都已經放到我的 GitHub 上了。
覺得有用 ?喜歡就收藏,順便給個小星星吧。
參考文章:
- JS 實現堆排序
- 資料結構與演算法之美
- 十大經典排序演算法總結(JavaScript 描述)
- JS 中可能用得到的全部的排序演算法