
c++11特性學習總結
ubuntu 16.04 自帶gcc 5.4 支援c++11
ubuntu 18.04 自帶gcc 7.3 支援c++14
檢視編譯器支援:
c++11
c++14
c++17
c++11 feature
- nullptr/constexpr
- enum class
- auto/decltype
- for iteration
- initialize_list
- lamda
- template
- rvalue/move
nullptr
以前的編譯器實現,可能會把NULL定義為0.所以,當你有兩個同名函式foo(int),foo(char*)時,foo(NULL)你的本意可能是呼叫後者,但實際呼叫的是前者.nullptr的引入就是為了解決這個問題.
void foo(char *ch) { std::cout << "call foo(char*)" << std::endl; } void foo(int i) { std::cout << "call foo(int)" << std::endl; } void test_nullptr() { if (NULL == (void *)0) std::cout << "NULL == 0" << std::endl; else std::cout << "NULL != 0" << std::endl; foo(0); //foo(NULL); // 編譯無法通過 foo(nullptr); }
constexpr
常量表達式的引入是為了提高效能,將執行期間的行為放到編譯期間去完成.如下程式碼
constexpr long int fib(int n) { return (n <= 1)? n : fib(n-1) + fib(n-2); } void test_constexpr() { auto start = std::chrono::system_clock::now(); const long int res = fib(30); auto end = std::chrono::system_clock::now(); std::chrono::duration<double> elapsed_seconds = end-start; cout << "elapsed_seconds:"<<elapsed_seconds.count()<<endl; start = std::chrono::system_clock::now(); long int res2 = fib(30); end = std::chrono::system_clock::now(); elapsed_seconds = end-start; cout << "elapsed_seconds:"<<elapsed_seconds.count()<<endl;
由於傳給fib(int n)的引數是30,是個固定的值.所以可以在編譯期間就求出來.當我們用const long和long宣告返回值時,對前者會在編譯期就做計算優化.如下圖,可以看到二者執行時間有數量級上的差異.

enum class
c++11中把列舉認為是一個類,以前的標準中列舉值就是一個整數而已.看如下程式碼
void test_enum()
{
enum color {black,white};
//auto white = true; //redeclared
enum class Color{r,g,b};
auto r = 1;
}以前的標準中enum color {black,white};相當於定義了兩個int變數black,white.所以//auto white = true;編譯期會報錯.引入了enum class則不再有這個問題.
auto/decltype
這個是c++11中非常重要的一點特性,極大地簡化了編碼的複雜.編譯期自動去推導變數的型別.再也不需要我們操心了.
auto做變數型別推導,decltype做表示式型別推導.
void test_auto()
{
std::vector<int> v;
v.push_back(1);
v.push_back(2);
for (std::vector<int>::iterator it = v.begin(); it != v.end(); it++)
{
cout << *it << endl;
}
for (auto it = v.begin(); it != v.end(); it++)
{
cout << *it << endl;
}
for (auto &i : v)
{
cout << i << endl;
i = 100; //修改掉v中的元素值
}
for (auto i : v)
{
cout << i << endl; //輸出100
i = 200; //不會修改v中的元素值
}
for (auto i : v)
{
cout << i << endl; //輸出為100
}
}
用法如上述程式碼所示.比如遍歷vector,寫法由for (std::vector
注意c++11中,auto變數自動推導有2個例外
- //int add(auto x,auto y); //c++14才支援函式引數為auto
- //auto arr[10] = {0}; //編譯錯誤 auto不能用於陣列型別的推導
decltype做表示式型別推導.假設我們要寫一個加法的模板函式,比如
template<typename R, typename T, typename U>
R add(T x, U y)
{
return x+y;
}
對於返回值型別R的話,我們必須在模板的引數列表中手動指明.呼叫的時候形式則為add<R,T,U>(x,y).而很可能我們並不知道返回型別是什麼,比如我使用一個第三方庫,我只是想對x,y做一個add操作,後續我可能會從x,y取一些資料做後續處理,此時我並不關心add操作返回值型別是什麼.
c++11中用decltype自動推導表示式型別解決這個問題.
template<typename T, typename U>
auto add_cxx11(T x, U y) -> decltype(x+y)
{
return x+y;
}用decltype(x+y)宣告返回值型別,讓編譯器自動推導就好了.
在c++14中,有了更好的支援,已經不再需要顯示地宣告返回值型別了.
//c++14支援
/*
template<typename T, typename U>
auto add_cxx14(T x, U y)
{
return x+y;
}
*/for迭代
基於範圍的for迭代,非常類似與python中的用法了.程式碼在前面auto/decltype一節已經展示.需要注意的是for (auto i : v)拿出的i是副本,不會修改v中的元素的值.for (auto &i : v)拿到的是引用,會修改掉v中的值.
初始化列表
c++11之前物件的初始化並不具有統一的表達形式,比如
int a[3] = {4,5,6}
/*
以前類的初始化只能通過拷貝建構函式或者()
比如 */
class A
{
A(int x,int y,int z)
}
A b;
A a(b);
A a2(1,2,3)
c++11提供了統一的語法來初始化任意物件.
比如
class XX
{
public:
XX(std::initializer_list<int> v):v_int(v)
{
}
vector<int> v_int = {3,4,5};
};
XX xxxxxx = {6,7,8,9,10};或者
struct A
{
int a_;
int b_;
};
A a {1,2};此外,初始化列表還可以作為函式的入參.
void f_take_initialize(initializer_list<int> list)
{
int sum = 0;
for (auto l : list)
{
sum += l;
}
cout << sum << endl;
}
void test_initialize()
{
f_take_initialize({1, 2, 3});
}
using關鍵字
using並不是c++11才有的,但是c++11中提升了這個關鍵字的功能,用於取代typedef,提供更加統一的表達形式.
template <typename T, typename U>
class SuckType;
typedef SuckType<std::vector<int>, std::string> NewType;
using NewType = SuckType<std::vector<int>, std::string>;
typedef int(*mycallback)(void*);
using mycallback = int(*)(void*);
lamda表示式
即匿名函式,這也是c++11中一個相當重要的特性.有的時候,我們可能需要使用某個功能,但這個功能可能只在某一個函式內部有用,那麼我們則沒有必要去寫一個全域性函式或者類的成員函式去抽象這個功能.這時候就可以實現一個匿名函式.
[捕獲列表](引數列表) -> 返回型別
{
// 函式體
}匿名函式的形式如上所示.引數列表,返回型別都很好理解.預設情況下,匿名函式是不可以使用匿名函式外部的變數的,捕獲列表就起到一個傳遞外部引數的作用
捕獲列表有下述幾種情況
- 值捕獲
- 引用捕獲
- 隱式捕獲
- 表示式捕獲 //c++14支援
值得注意的是,值捕獲的話,值是在匿名函式定義好的時候就做傳遞,而不是呼叫的時候做傳遞.
如下程式碼
void test_lamda()
{
auto add_func = [](int x,int y) -> int{return x+y;};
auto sum = add_func(3,4);
cout<<"sum="<<sum<<endl;
int a = 1;
auto copy_a = [a]{return a;};
a = 100;
auto a_i_get = copy_a();
printf("a_i_get=%d,a=%d\n",a_i_get,a);
auto copy_a_refrence = [&a]{a=50;return a;};
auto a_refrence_i_get = copy_a_refrence();
printf("a_i_get=%d,a=%d\n",a_refrence_i_get,a);
int b = 1;
auto f = [&](){return b;} ;
}

注意,第一個輸出的a_i_get=1而不是100.儘管a是100.這是因為在copy_a定義的時候,a的值是1. copy_a_refrence的捕獲列表是引用,函式體內修改a=50,所以輸出的是50
當要捕獲的變數非常多的時候,一個個寫是非常麻煩的,所以可以直接在捕獲列表裡用=和&表示傳值和傳引用
[](){} //傳空
[=](){} //傳值
[&](){} //傳引用變長模板
template<typename... Ts> class Magic;c++11之前,模板的引數是固定個數的.c++11之後支援不定長引數的模板.用...表示不定長.
c++11標準庫新引入的資料結構tuple就是用了這個特性實現的.
move語義和右值引用.
這也是c++11中引入的非常重要的一個特性.主要作用在於效能的提升.
通俗地講,一個可以取地址的變數,即為左值,不可以取地址的即為右值.
以之前的vector.push_back()為例,插入的是資料的一份拷貝.當要插入的資料結構本身記憶體特別大的時候,這種拷貝帶來的效能消耗是非常大的.
move的引入即用於解決此類問題,move()將一個值轉換為右值. 標準庫的資料結構裡實現了void push_back( T&& value );的版本.
move()名字叫move,但他本身並不做任何move的操作,move更類似於淺拷貝,即拷貝待拷貝內容的地址過去.但是淺拷貝並不會使得之前的物件失去所有權,而move會,所以move所做的事情就是資源的所有權的轉移

先看一下這段程式碼
void test_move()
{
std::string str = "Hello world.";
std::vector<std::string> v;
// 將使用 push_back(const T&), 即產生拷貝行為
v.push_back(str);
// 將輸出 "str: Hello world."
std::cout << "str: " << str << std::endl;
// 將使用 push_back(const T&&), 不會出現拷貝行為
// 而整個字串會被移動到 vector 中,所以有時候 std::move 會用來減少拷貝出現的開銷
// 這步操作後, str 中的值會變為空
v.push_back(std::move(str));
// 將輸出 "str: "
std::cout << "str: " << str << std::endl;
}
即我們前面提到的"hello world"這些內容的所有權的轉移.move之後,原先的str已經失去了所有權,列印為空.
再來看一段程式碼.
void test_move_efficience()
{
vector<int> v_i;
for(auto i = 0;i<10000000;i++)
{
v_i.push_back(i);
}
auto f = [&](vector<int> v)
{
return v;
};
auto g = [&](vector<int>& v)
{
return v;
};
auto start = std::chrono::system_clock::now();
f(v_i);
auto end = std::chrono::system_clock::now();
std::chrono::duration<double,std::milli> elapsed_seconds = end-start;
cout << "f(v_i) elapsed_seconds:"<<elapsed_seconds.count()<<endl;
start = std::chrono::system_clock::now();
f(move(v_i));
end = std::chrono::system_clock::now();
elapsed_seconds = end-start;
cout << "f(move(v_i)) elapsed_seconds:"<<elapsed_seconds.count()<<endl;
start = std::chrono::system_clock::now();
g(v_i);
end = std::chrono::system_clock::now();
elapsed_seconds = end-start;
cout << "g(v_i) elapsed_seconds:"<<elapsed_seconds.count()<<endl;
list<int> li;
for(auto i = 0;i<10000000;i++)
{
li.push_front(i);
li.push_back(i+1);
}
vector<list<int>> vl;
start = std::chrono::system_clock::now();
vl.push_back(li);
end = std::chrono::system_clock::now();
elapsed_seconds = end-start;
cout << "vl.push_back(li) elapsed_seconds:"<<elapsed_seconds.count()<<endl;
start = std::chrono::system_clock::now();
vl.push_back(move(li));
end = std::chrono::system_clock::now();
elapsed_seconds = end-start;
cout << "vl.push_back(move(li)) elapsed_seconds:"<<elapsed_seconds.count()<<endl;
}先貼輸出
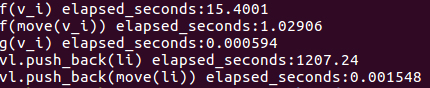
我們知道,函式傳參的時候,值傳遞的話,實際上是做了一份引數的拷貝.所以f(v_i)的開銷是最高的,達15ms,f(move(v_i))的話,沒有了拷貝的操作,耗時1ms.對於g(v_i)的話,引數為引用,沒有拷貝操作,耗時只有0.000594ms. 因為不管是f(),g(),函式內部都是非常簡單的,沒有任何操作,而move()本身會帶來一定消耗,所以f(move(v_i))耗時比g(v_i)更高.
而move語義更常見的使用在於標準庫裡的封裝.比如上述程式碼,vl.push_back(li)和vl.push_back(move(li))呼叫了不同的push_back(). 其效能是有著數量級的差異. 以我們的例子為例,其耗時分別為1207ms和0.001548ms.
所以如果我們自己的資料型別,內部含有大量的資料,我們應當自己去實現move建構函式.這樣使用標準庫時才可以更好的提高性