
HDFS 讀寫流程-譯
HDFS 檔案讀取流程
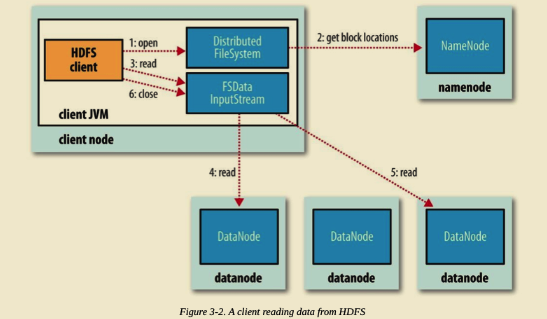
Client 端呼叫 DistributedFileSystem 物件的 open() 方法。
由 DistributedFileSystem 通過 RPC 向 NameNode 請求返回檔案的 Block 塊所在的 DataNode 的地址。(我們知道 HDFS 預設策略對某個 Block 會儲存三份副本到不同的 DataNode,那麼 NameNode 應該返回那個 DataNode?答案是根據 DataNode 到 Client 端的距離。假設請求的 Block 塊剛好就落在 Client 端所在機器上,即 Client 端本身也是 DataNode,那麼毫無疑問 DataNode 將會返回 Client 端所在機器地址。這也驗證了 Hadoop 的一個設計特性,移動計算而不是移動資料,極大了減小了頻寬。)
Client 端呼叫 FSDataInputStream 物件的 read() 方法,通過 FSDataInputStream 向 DataNode 獲取 Block 資料。之後資料流源源不斷地從 DataNode 返回至 Client。當最後一個 Block 返回至 Client 端後, DFSInputStream 會關閉與 DataNode 連線。上述過程對 Client 端都是透明的,從 Client 來看,它只是在不停的讀取資料流。
如果 DFSInputStream 在讀取的過程中發生了錯誤,將會嘗試與存有該 Block 副本且距離最近的 DataNode 通訊。同時,它會記錄下出問題的 DataNode,在之後的資料請求過程中不再與之通訊。並報告給 NameNode。DFSInputStream 具備檢查資料校驗和的功能。
HDFS 檔案寫入流程
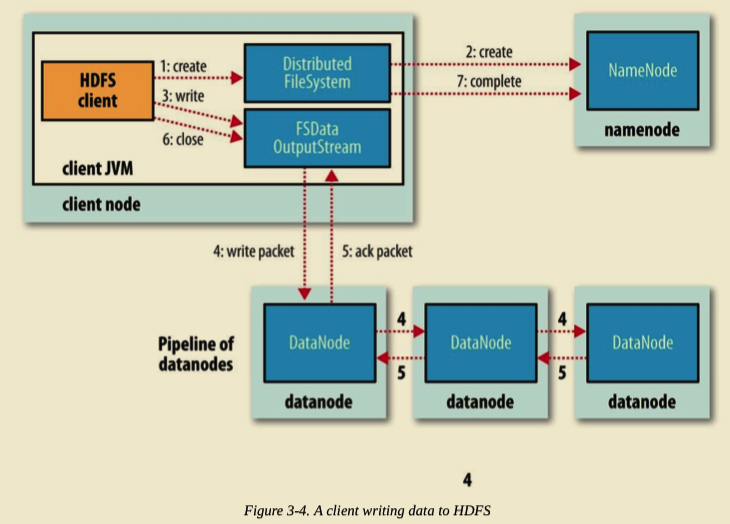
Client 寫入檔案時,呼叫 DistributedFileSystem 物件的 create() 方法。
DistributedFileSystem 通過 RPC 請求 NameNode 向其 NameSpace 寫入檔案元資料資訊。NameNode 會做多種檢查,如判斷檔案是否存在,是否有相應的寫許可權等等。如果檢查通過,NameNode 會將檔案元資料寫入 NameSpace。DistributedFileSystem 將會返回 FSDataOutputStream 用於 Client 端直接向 DataNode 寫入資料。
DFSOutputStream 將 Client 要寫入的資料分割成 Packets。Packets 會被儲存到 Data Queue 佇列中,並由 DataStreamer 消費處理。DataStreamer 請求 NameNode 分配 DataNode 列表,將 Packets 寫入到 DataNode 中。假設放置副本的預設策略是 3,那麼 NameNode 將返回 3 個 DataNode,並串聯起來組成一條 Pipeline。 DataStreamer 將 Packets 寫入到第一個 DataNode1,DataNode1 儲存完後直接轉發至 DataNode2,DataNode2 儲存完後再直接轉發至 DataNode3。(注意,這裡直接是 DataNode1 直接將 Packet 轉發至 DataNode2。)
DFSOutputStream 為了防止出問題時資料的丟失,維持了一個等待 DataNode 成功寫入的 ACK Queue。只有當 Packet 被成功寫入 Pipeline 中的每個 DataNode 時,此 Packet 才會從 ACK Queue 中移除。
在 Pipeline 寫入的過程中,如果某個 DataNode 出現問題,Pipeline 首先將會被關閉,隨後在 ACK Queue 中的 Packets 會被新增到 Data Queue 的最前面,用來防止位於問題節點下游的 DataNode 寫入時的資料丟失。出問題的 DataNode 會被從 Pipeline 中移除。NameNode 會重新分配一個健康的 DataNode 構成新的 Pipeline。
當 Client 端寫完資料,呼叫 DFSOutputStream 物件的 close() 方法。該操作將會將所有剩餘的 Packets 刷寫到 DataNode Pipeline 並等待返回確認,之後向 NameNode 傳送檔案寫入完成訊號。
歡迎關注我的公眾號

相關推薦
HDFS 讀寫流程-譯
HDFS 檔案讀取流程 Client 端呼叫 DistributedFileSystem 物件的 open() 方法。 由 DistributedFileSystem 通過 RPC 向 NameNode 請求返回檔案的 Block 塊所在的 DataNode 的地址。(我們知道 HDFS 預設策略對某個
HDFS讀寫流程簡介
HadoopHDFS寫流程: 1.初始化FileSystem,客戶端調用create()來創建文件 2.FileSystem用RPC調用元數據節點,在文件系統的命名空間中創建一個新的文件,元數據節點首先確定文件原來不存在,並且客戶端有創建文件的權限,然後創建新文件。 3.FileSystem返回DFSOut
HDFS讀寫流程
HDFS儲存資料 架構圖 HDFS 採用Master/Slave的架構來儲存資料,這種架構主要由四個部分組成,分別為HDFS Client、NameNode、DataNode和Secondary NameNode。 Client:就是客戶端。 1、切分檔案:檔
HDFS讀寫流程(重點)
@[toc] # 寫資料流程 ①服務端啟動HDFS中的`NN和DN`程序 ②客戶端建立一個分散式檔案系統客戶端,由客戶端向NN傳送請求,請求上傳檔案 ③NN處理請求,檢查客戶端是否有許可權上傳,路徑是否合法等 ④檢查通過,NN響應客戶端可以上傳 ⑤客戶端根據自己設定的塊大小,開始上傳`第一個塊`,預設0-12
HDFS文件讀寫流程簡單圖解
http pla ges jpg eight 簡單 系統 mage pan 在活動反思文件系統中 HDFS文件讀寫流程簡單圖解
Java操作HDFS開發環境搭建以及HDFS的讀寫流程
Hadoop CDH HDFS Java操作HDFS 大數據 Java操作HDFS開發環境搭建 在之前我們已經介紹了如何在Linux上進行HDFS偽分布式環境的搭建,也介紹了hdfs中一些常用的命令。但是要如何在代碼層面進行操作呢?這是本節將要介紹的內容: 1.首先使用IDEA創建一個ma
Hadoop_08_客戶端向HDFS讀寫(上傳)數據流程
pack 查詢 文件路徑 hdfs 校驗 blocks 管理 con 讀取數據 1.HDFS的工作機制: HDFS集群分為兩大角色:NameNode、DataNode (Secondary Namenode) NameNode負責管理整個文件系統的元數據 DataNode
hadoop學習筆記(三):hdfs體系結構和讀寫流程(轉)
sim 百萬 服務器 發表 繼續 什麽 lose 基於 一次 原文:https://www.cnblogs.com/codeOfLife/p/5375120.html 目錄 HDFS 是做什麽的 HDFS 從何而來 為什麽選擇 HDFS 存儲數據 HDFS
HDFS讀寫檔案的具體流程
HDFS讀寫檔案的具體流程 1.圖解寫檔案 2.流程詳解 3.圖解讀檔案 4.流程詳解 1.圖解寫檔案 2.流程詳解 1.客戶端通過Distributed FileSystem(分散式檔案系統)模組向NameNode請求
HDFS儲存架構剖析以及讀寫流程
HDFS儲存架構主要由三部分組成:NameNode,DataNode,Client NameNode Namenode 是一箇中心伺服器,單一節點(簡化系統的設計和實現),負責管理檔案系統的名字空間(namespace)以及客戶端對檔案的訪問。 檔案
hdfs讀寫檔案核心流程詳解巧說
一.hdfs寫資料流程(面試重點) 1)客戶端(fs)向namenode請求上傳檔案,namenode檢查目標檔案是否已存在,父目錄是否存在。 2)namenode返回是否可以上傳。 3)客戶端請
HDFS 讀寫檔案流程詳解
1.HDFS寫流程: 客戶端要向HDFS寫資料,首先要跟名稱節點通訊以確認可以寫檔案並獲得接收檔案塊的資料節點,然後,客戶端按順序將檔案逐個塊傳遞給相應資料節點,並由接收到塊的資料節點負責向其他資料節點複製塊的副本 如圖:寫詳細步驟: 1、根namenode
淺談HDFS的寫流程
ont 返回 inxi 淺談 中繼 nod medium 大小 數據塊 1、使用HDFS提供的客戶端Client,向遠程的Namenode發起RPC請求2、Namenode會檢查要創建的文件是否已經存在,創建者是否有權限進行操作,成功則會為文件創建一個記錄,否則會讓客戶端拋
hbase讀寫流程
ems 服務 region flush 以及 hba 表數據 new 剛才 HBase讀數據流程 1) HRegionServer保存著meta表以及表數據,要訪問表數據,首先Client先去訪問zookeeper,從zookeeper裏面獲取meta表所在的位置信息,即找
linux塊設備讀寫流程
臨時 無效 rect patch 得到 喚醒 處理 字符 構建 在學習塊設備原理的時候,我最關系塊設備的數據流程,從應用程序調用Read或者Write開始,數據在內核中到底是如何流通、處理的呢?然後又如何抵達具體的物理設備的呢?下面對一個帶Cache功能的塊設備數據流程進行
2.HBase_儲存與讀寫流程
我們看到HBase叢集的物理模型,包括:Client、ZooKeeper、HMaster、HRegionServer、HLog、HRegion、Store、StoreFile、MemStore。對於HBase,它的元資料存放在ZooKeeper中,真實資料存放在MemFile(記憶體)和S
大資料開發之Hadoop篇----hdfs讀寫許可權操作
由於hdfs的結構和linux是差不多的,所以我們在hdfs的讀寫操作上也是會面臨許可權和路徑問題問題,先讓我們來看下這些都是些什麼問題。 這裡我先上傳了一個README.txt的檔案上去,通過hdfs dfs -ls /user/hadoop命令我們已經可以檢視到hdfs上有了這個檔案了
HDFS讀寫檔案
寫檔案: client向遠端NameNode發起RPC請求; NameNode檢查檔案是否存在,成功則為檔案建立一個記錄; client根據block size將檔案切分成多個packets,並以“data queue”的形式進行管理,另外獲取block的replication
Hbase讀寫流程和定址機制
寫操作流程 (1) Client通過Zookeeper的排程,向RegionServer發出寫資料請求,在Region中寫資料。 (2) 資料被寫入Region的MemStore,直到MemStore達到預設閾值。 (3) MemStore中的資料被Flush成一個StoreFile。 (4) 隨著S
大資料筆記 2--hdfs讀資料流程
注:以下簡化名稱所對應的全稱: NN == NameNode; IO == hdfsFileinputStream; DN == DataNode; DN1 == DataNode1; DN2 == DataNode2; DN3 == DataNode3; 詳