
如果你也想做實時數倉…
資料倉庫也是公司資料發展到一定規模後必然會提供的一種基礎服務,資料倉庫的建設也是“資料智慧”中必不可少的一環。本文將從資料倉庫的簡介、經歷了怎樣的發展、如何建設、架構演變、應用案例以及實時數倉與離線數倉的對比六個方面全面分享關於數倉的詳細內容。
1.資料倉庫簡介
資料倉庫是一個面向主題的(Subject Oriented)、整合的(Integrate)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的資料集合,用於支援管理決策。
資料倉庫是伴隨著企業資訊化發展起來的,在企業資訊化的過程中,隨著資訊化工具的升級和新工具的應用,資料量變的越來越大,資料格式越來越多,決策要求越來越苛刻,資料倉庫技術也在不停的發展。
資料倉庫的趨勢:
- 實時資料倉庫以滿足實時化&自動化決策需求;
- 大資料&資料湖以支援大量&複雜資料型別(文字、影象、視訊、音訊);
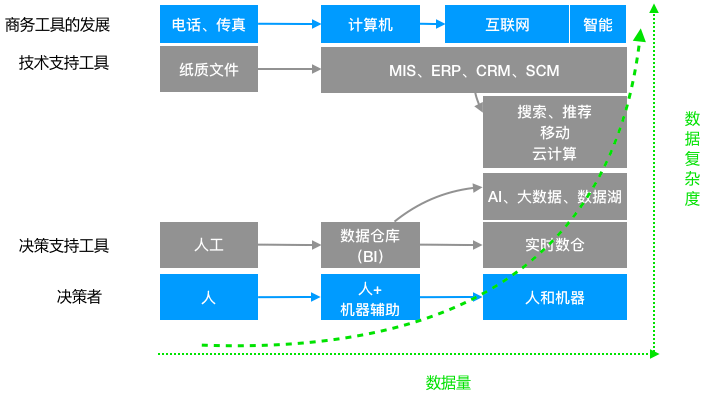
2.資料倉庫的發展
資料倉庫有兩個環節:資料倉庫的構建與資料倉庫的應用。
早期資料倉庫構建主要指的是把企業的業務資料庫如 ERP、CRM、SCM 等資料按照決策分析的要求建模並彙總到資料倉庫引擎中,其應用以報表為主,目的是支援管理層和業務人員決策(中長期策略型決策)。
隨著業務和環境的發展,這兩方面都在發生著劇烈變化。
- 隨著IT技術走向網際網路、移動化,資料來源變得越來越豐富,在原來業務資料庫的基礎上出現了非結構化資料,比如網站 log,IoT 裝置資料,APP 埋點資料等,這些資料量比以往結構化的資料大了幾個量級,對 ETL 過程、儲存都提出了更高的要求;
- 網際網路的線上特性也將業務需求推向了實時化,隨時根據當前客戶行為而調整策略變得越來越常見,比如大促過程中庫存管理,運營管理等(即既有中遠期策略型,也有短期操作型);同時公司業務網際網路化之後導致同時服務的客戶劇增,有些情況人工難以完全處理,這就需要機器自動決策。比如欺詐檢測和使用者稽核。

總結來看,對資料倉庫的需求可以抽象成兩方面:實時產生結果、處理和儲存大量異構資料。
注:這裡不討論資料湖技術。
3.資料倉庫建設方法論
3.1 面向主題
從公司業務出發,是分析的巨集觀領域,比如供應商主題、商品主題、客戶主題和倉庫主題
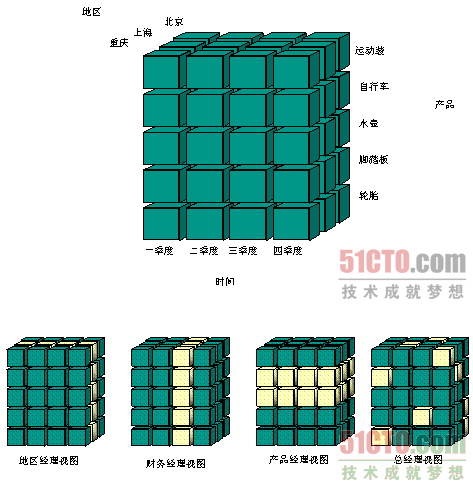
3.2 為多維資料分析服務
資料報表;資料立方體,上卷、下鑽、切片、旋轉等分析功能。
3.3 反正規化資料模型
以事實表和維度表組成的星型資料模型
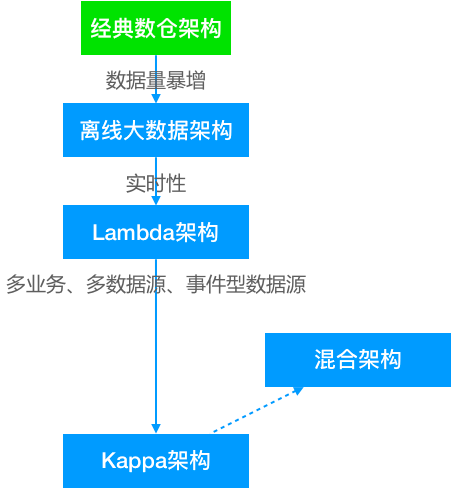
4.資料倉庫架構的演變
資料倉庫概念是 Inmon 於 1990 年提出並給出了完整的建設方法。隨著網際網路時代來臨,資料量暴增,開始使用大資料工具來替代經典數倉中的傳統工具。此時僅僅是工具的取代,架構上並沒有根本的區別,可以把這個架構叫做離線大資料架構。
後來隨著業務實時性要求的不斷提高,人們開始在離線大資料架構基礎上加了一個加速層,使用流處理技術直接完成那些實時性要求較高的指標計算,這便是 Lambda 架構。
再後來,實時的業務越來越多,事件化的資料來源也越來越多,實時處理從次要部分變成了主要部分,架構也做了相應調整,出現了以實時事件處理為核心的 Kappa 架構。
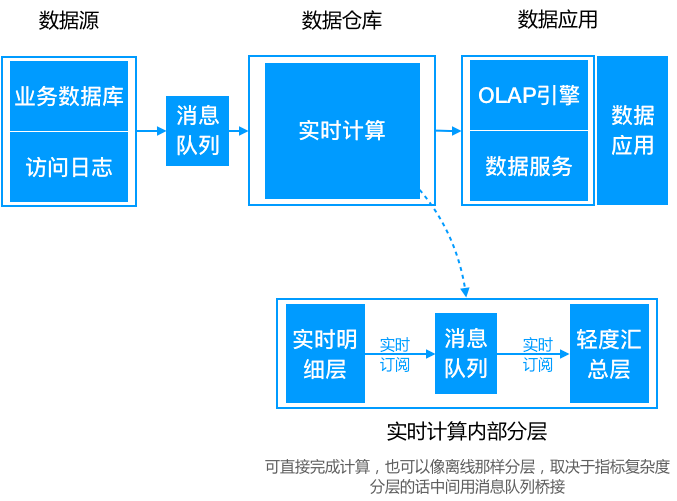
4.1 離線大資料架構
資料來源通過離線的方式匯入到離線數倉中。下游應用根據業務需求選擇直接讀取 DM 或加一層資料服務,比如 MySQL 或 Redis。資料倉庫從模型層面分為三層:
- ODS,操作資料層,儲存原始資料;
- DWD,資料倉庫明細層,根據主題定義好事實與維度表,儲存最細粒度的事實資料;
- DM,資料集市/輕度彙總層,在 DWD 層的基礎之上根據不同的業務需求做輕度彙總;
典型的數倉儲存是 HDFS/Hive,ETL 可以是 MapReduce 指令碼或 HiveSQL。

4.2 Lambda 架構
隨著大資料應用的發展,人們逐漸對系統的實時性提出了要求,為了計算一些實時指標,就在原來離線數倉的基礎上增加了一個實時計算的鏈路,並對資料來源做流式改造(即把資料傳送到訊息佇列),實時計算去訂閱訊息佇列,直接完成指標增量的計算,推送到下游的資料服務中去,由資料服務層完成離線&實時結果的合併。
注:流處理計算的指標批處理依然計算,最終以批處理為準,即每次批處理計算後會覆蓋流處理的結果。(這僅僅是流處理引擎不完善做的折中)
Lambda 架構問題:
- 同樣的需求需要開發兩套一樣的程式碼:這是 Lambda 架構最大的問題,兩套程式碼不僅僅意味著開發困難(同樣的需求,一個在批處理引擎上實現,一個在流處理引擎上實現,還要分別構造資料測試保證兩者結果一致),後期維護更加困難,比如需求變更後需要分別更改兩套程式碼,獨立測試結果,且兩個作業需要同步上線。
- 資源佔用增多:同樣的邏輯計算兩次,整體資源佔用會增多(多出實時計算這部分

4.3 Kappa 架構
Lambda 架構雖然滿足了實時的需求,但帶來了更多的開發與運維工作,其架構背景是流處理引擎還不完善,流處理的結果只作為臨時的、近似的值提供參考。後來隨著 Flink 等流處理引擎的出現,流處理技術很成熟了,這時為了解決兩套程式碼的問題,LickedIn 的 Jay Kreps 提出了 Kappa 架構。
- Kappa 架構可以認為是 Lambda 架構的簡化版(只要移除 lambda 架構中的批處理部分即可)。
- 在 Kappa 架構中,需求修改或歷史資料重新處理都通過上游重放完成。
- Kappa 架構最大的問題是流式重新處理歷史的吞吐能力會低於批處理,但這個可以通過增加計算資源來彌補。
Kappa 架構的重新處理過程:
重新處理是人們對 Kappa 架構最擔心的點,但實際上並不複雜:
- 選擇一個具有重放功能的、能夠儲存歷史資料並支援多消費者的訊息佇列,根據需求設定歷史資料儲存的時長,比如 Kafka,可以儲存全部歷史資料。
- 當某個或某些指標有重新處理的需求時,按照新邏輯寫一個新作業,然後從上游訊息佇列的最開始重新消費,把結果寫到一個新的下游表中。
- 當新作業趕上進度後,應用切換資料來源,讀取 2 中產生的新結果表。
- 停止老的作業,刪除老的結果表。
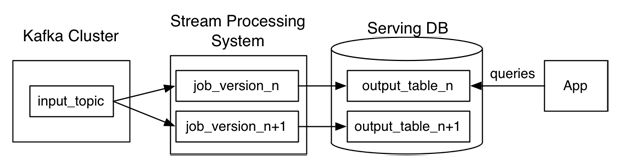
4.4 Lambda 架構與 Kappa 架構的對比

- 在真實的場景中,很多時候並不是完全規範的 Lambda 架構或 Kappa 架構,可以是兩者的混合,比如大部分實時指標使用 Kappa 架構完成計算,少量關鍵指標(比如金額相關)使用 Lambda 架構用批處理重新計算,增加一次校對過程。
- Kappa 架構並不是中間結果完全不落地,現在很多大資料系統都需要支援機器學習(離線訓練),所以實時中間結果需要落地對應的儲存引擎供機器學習使用,另外有時候還需要對明細資料查詢,這種場景也需要把實時明細層寫出到對應的引擎中。參考後面的案例。
- 另外,隨著資料多樣性的發展,資料倉庫這種提前規定 schema 的模式顯得越來難以支援靈活的探索&分析需求,這時候便出現了一種資料湖技術,即把原始資料全部快取到某個大資料儲存上,後續分析時再根據需求去解析原始資料。簡單的說,資料倉庫模式是 schema on write,資料湖模式是 schema on read。
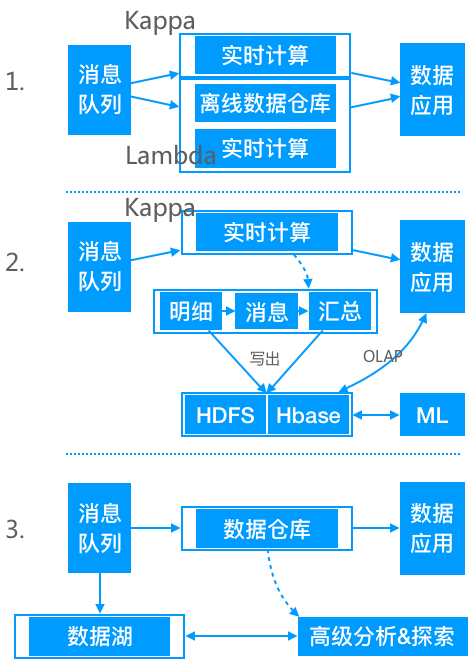
5.實時數倉案例
菜鳥倉配實時資料倉庫本案例參考自菜鳥倉配團隊的分享,涉及全域性設計、資料模型、資料保障等幾個方面。
注:特別感謝緣橋同學的無私分享。
5.1 整體設計
整體設計如下圖,基於業務系統的資料,資料模型採用中間層的設計理念,建設倉配實時數倉;計算引擎,選擇更易用、效能表現更佳的實時計算作為主要的計算引擎;資料服務,選擇天工資料服務中介軟體,避免直連資料庫,且基於天工可以做到主備鏈路靈活配置秒級切換;資料應用,圍繞大促全鏈路,從活動計劃、活動備貨、活動直播、活動售後、活動覆盤五個維度,建設倉配大促資料體系。

5.2 資料模型
不管是從計算成本,還是從易用性,還是從複用性,還是從一致性等等,我們都必須避免煙囪式的開發模式,而是以中間層的方式建設倉配實時數倉。與離線中間層基本一致,我們將實時中間層分為兩層。
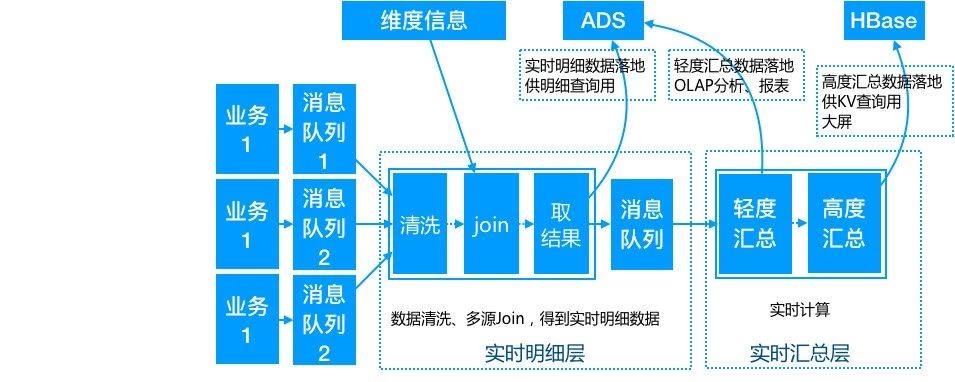
- 第一層 DWD 公共實時明細層
實時計算訂閱業務資料訊息佇列,然後通過資料清洗、多資料來源 join、流式資料與離線維度資訊等的組合,將一些相同粒度的業務系統、維表中的維度屬性全部關聯到一起,增加資料易用性和複用性,得到最終的實時明細資料。這部分資料有兩個分支,一部分直接落地到 ADS,供實時明細查詢使用,一部分再發送到訊息佇列中,供下層計算使用;
- 第二層 DWS 公共實時彙總層
以資料域+業務域的理念建設公共彙總層,與離線數倉不同的是,這裡彙總層分為輕度彙總層和高度彙總層,並同時產出,輕度彙總層寫入 ADS,用於前端產品複雜的 olap 查詢場景,滿足自助分析和產出報表的需求;高度彙總層寫入 Hbase,用於前端比較簡單的 kv 查詢場景,提升查詢效能,比如實時大屏等;
注:
- ADS 是一款提供 OLAP 分析服務的引擎。開源提供類似功能的有,Elastic Search、Kylin、Druid 等;
- 案例中選擇把資料寫入到 Hbase 供 KV 查詢,也可根據情況選擇其他引擎,比如資料量不多,查詢壓力也不大的話,可以用 MySQL;
- 因主題建模與業務關係較大,這裡不做描述;
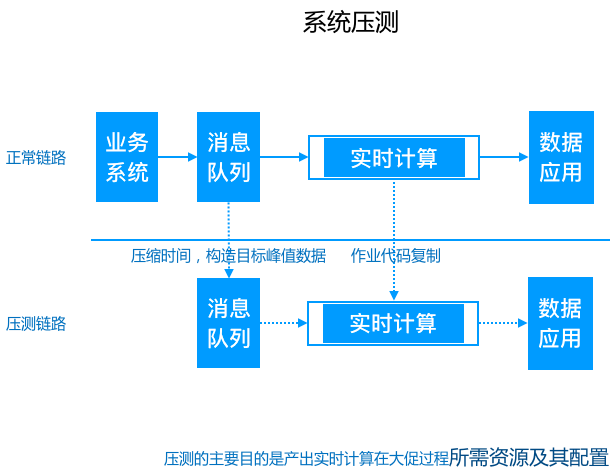
5.3 資料保障
阿里巴巴每年都有雙十一等大促,大促期間流量與資料量都會暴增。實時系統要保證實時性,相對離線系統對資料量要更敏感,對穩定性要求更高。所以為了應對這種場景,還需要在這種場景下做兩種準備:
- 大促前的系統壓測;
- 大促中的主備鏈路保障;
菜鳥雙11「倉儲配送資料實時化」詳情瞭解~

6. 實時數倉與離線數倉的對比
在看過前面的敘述與菜鳥案例之後,我們看一下實時數倉與離線數倉在幾方面的對比:
- 首先,從架構上,實時數倉與離線數倉有比較明顯的區別,實時數倉以 Kappa 架構為主,而離線數倉以傳統大資料架構為主。Lambda 架構可以認為是兩者的中間態。
- 其次,從建設方法上,實時數倉和離線數倉基本還是沿用傳統的數倉主題建模理論,產出事實寬表。另外實時數倉中實時流資料的 join 有隱藏時間語義,在建設中需注意。
- 最後,從資料保障看,實時數倉因為要保證實時性,所以對資料量的變化較為敏感。在大促等場景下需要提前做好壓測和主備保障工作,這是與離線資料的一個較為明顯的區別。
本文作者: 郭華(付空)
本文為雲棲社群原創內容,未經