
你需要的不是實時數倉 | 你需要的是一款強大的OLAP資料庫(下)
在上一章節中,我們講到實時數倉的建設,網際網路大資料技術發展到今天,各個領域基本已經成熟,有各式各樣的解決方案可以供我們選擇。
在實時數倉建設中,解決方案成熟,訊息佇列Kafka、Redis、Hbase鮮有敵手,幾乎已成壟斷之勢。而OLAP的選擇則制約整個實時數倉的能力。開源盛世的今天,可以供我們選擇和使用的OLAP資料庫令人眼花繚亂,這章我們選取了幾個最常用的OLAP開源資料引擎進行分析,希望能給正在做技術選型和未來架構升級的你提供一些幫助。
本文給出了常用的開源OLAP引擎的效能測評: https://blog.csdn.net/oDaiLiDong/article/details/86570211
OLAP百家爭鳴
OLAP簡介
OLAP,也叫聯機分析處理(Online Analytical Processing)系統,有的時候也叫DSS決策支援系統,就是我們說的資料倉庫。與此相對的是OLTP(on-line transaction processing)聯機事務處理系統。
聯機分析處理 (OLAP) 的概念最早是由關係資料庫之父E.F.Codd於1993年提出的。OLAP的提出引起了很大的反響,OLAP作為一類產品同聯機事務處理 (OLTP) 明顯區分開來。
Codd認為聯機事務處理(OLTP)已不能滿足終端使用者對資料庫查詢分析的要求,SQL對大資料庫的簡單查詢也不能滿足使用者分析的需求。使用者的決策分析需要對關係資料庫進行大量計算才能得到結果,而查詢的結果並不能滿足決策者提出的需求。因此,Codd提出了多維資料庫和多維分析的概念,即OLAP。
OLAP委員會對聯機分析處理的定義為:從原始資料中轉化出來的、能夠真正為使用者所理解的、並真實反映企業多維特性的資料稱為資訊資料,使分析人員、管理人員或執行人員能夠從多種角度對資訊資料進行快速、一致、互動地存取,從而獲得對資料的更深入瞭解的一類軟體技術。OLAP的目標是滿足決策支援或多維環境特定的查詢和報表需求,它的技術核心是"維"這個概念,因此OLAP也可以說是多維資料分析工具的集合。
OLAP的準則和特性
E.F.Codd提出了關於OLAP的12條準則:
- 準則1 OLAP模型必須提供多維概念檢視
- 準則2 透明性準則
- 準則3 存取能力準則
- 準則4 穩定的報表能力
- 準則5 客戶/伺服器體系結構
- 準則6 維的等同性準則
- 準則7 動態的稀疏矩陣處理準則
- 準則8 多使用者支援能力準則
- 準則9 非受限的跨維操作
- 準則10 直觀的資料操縱
- 準則11 靈活的報表生成
- 準則12 不受限的維與聚集層次
一言以蔽之:
OLTP系統強調資料庫記憶體效率,強調記憶體各種指標的命令率,強調繫結變數,強調併發操作,強調事務性; OLAP系統則強調資料分析,強調SQL執行時長,強調磁碟I/O,強調分割槽。
OLAP開源引擎
目前市面上主流的開源OLAP引擎包含不限於:Hive、Hawq、Presto、Kylin、Impala、Sparksql、Druid、Clickhouse、Greeplum等,可以說目前沒有一個引擎能在資料量,靈活程度和效能上做到完美,使用者需要根據自己的需求進行選型。
元件特點和簡介
Hive
Hive是基於Hadoop的一個數據倉庫工具,可以將結構化的資料檔案對映為一張資料庫表,並提供完整的sql查詢功能,可以將sql語句轉換為MapReduce任務進行執行。其優點是學習成本低,可以通過類SQL語句快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合資料倉庫的統計分析。
對於hive主要針對的是OLAP應用,其底層是hdfs分散式檔案系統,hive一般只用於查詢分析統計,而不能是常見的CUD操作,Hive需要從已有的資料庫或日誌進行同步最終入到hdfs檔案系統中,當前要做到增量實時同步都相當困難。
Hive的優勢是完善的SQL支援,極低的學習成本,自定義資料格式,極高的擴充套件性可輕鬆擴充套件到幾千個節點等等。
但是Hive 在載入資料的過程中不會對資料進行任何處理,甚至不會對資料進行掃描,因此也沒有對資料中的某些 Key 建立索引。Hive 要訪問資料中滿足條件的特定值時,需要暴力掃描整個資料庫,因此訪問延遲較高。
Hive真的太慢了。大資料量聚合計算或者聯表查詢,Hive的耗時動輒以小時計算,在某一個瞬間,我甚至想把它開除出OLAP"國籍",但是不得不承認Hive仍然是基於Hadoop體系應用最廣泛的OLAP引擎。
Hawq
http://hawq.apache.org https://blog.csdn.net/wzy0623/article/details/55047696 https://www.oschina.net/p/hawq
Hawq是一個Hadoop原生大規模並行SQL分析引擎,Hawq採用 MPP 架構,改進了針對 Hadoop 的基於成本的查詢優化器。除了能高效處理本身的內部資料,還可通過 PXF 訪問 HDFS、Hive、HBase、JSON 等外部資料來源。HAWQ全面相容 SQL 標準,能編寫 SQL UDF,還可用 SQL 完成簡單的資料探勘和機器學習。無論是功能特性,還是效能表現,HAWQ 都比較適用於構建 Hadoop 分析型資料倉庫應用。
一個典型的Hawq叢集元件如下:
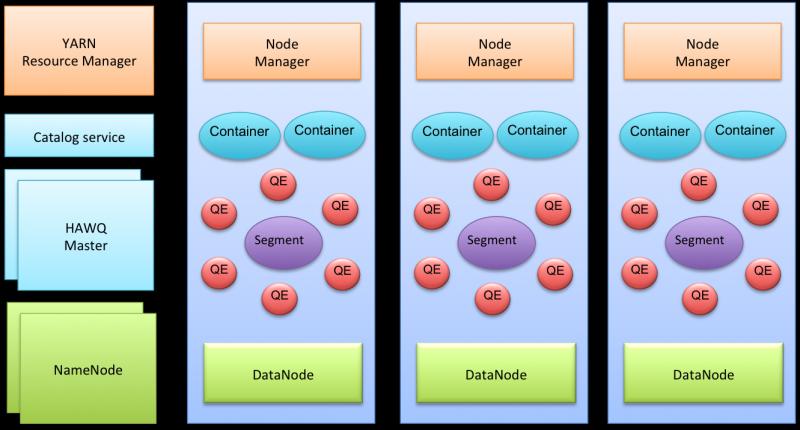
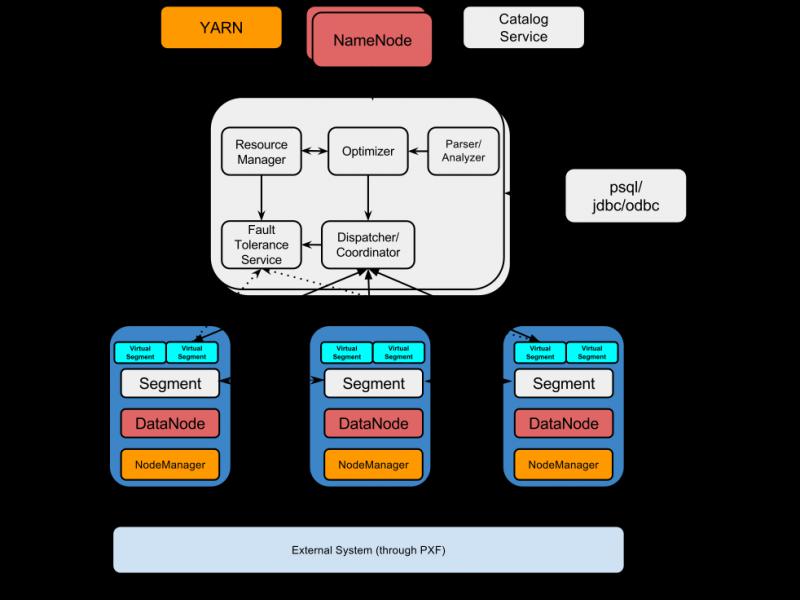
網路上有人對Hawq與Hive查詢效能進行了對比測試,總體來看,使用Hawq內部表比Hive快的多(4-50倍)。 原文連結:https://blog.csdn.net/wzy0623/article/details/71479539
Spark SQL
SparkSQL的前身是Shark,它將 SQL 查詢與 Spark 程式無縫整合,可以將結構化資料作為 Spark 的 RDD 進行查詢。SparkSQL作為Spark生態的一員繼續發展,而不再受限於Hive,只是相容Hive。
Spark SQL在整個Spark體系中的位置如下:

SparkSQL的架構圖如下:
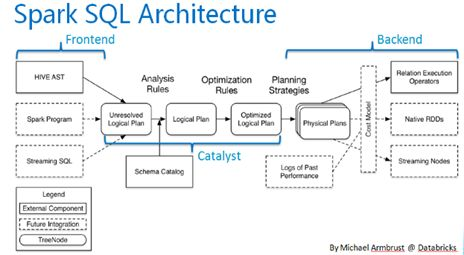
Spark SQL對熟悉Spark的同學來說,很容易理解並上手使用: 相比於Spark RDD API,Spark SQL包含了對結構化資料和在其上運算的更多資訊,Spark SQL使用這些資訊進行了額外的優化,使對結構化資料的操作更加高效和方便。 SQL提供了一個通用的方式來訪問各式各樣的資料來源,包括Hive, Avro, Parquet, ORC, JSON, and JDBC。 Hive相容性極好。
Presto
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto allows querying data where it lives, including Hive, Cassandra, relational databases or even proprietary data stores. A single Presto query can combine data from multiple sources, allowing for analytics across your entire organization.
Presto is targeted at analysts who expect response times ranging from sub-second to minutes. Presto breaks the false choice between having fast analytics using an expensive commercial solution or using a slow "free" solution that requires excessive hardware.
這是Presto官方的簡介。Presto 是由 Facebook 開源的大資料分散式 SQL 查詢引擎,適用於互動式分析查詢,可支援眾多的資料來源,包括 HDFS,RDBMS,KAFKA 等,而且提供了非常友好的介面開發資料來源聯結器。
Presto支援標準的ANSI SQL,包括複雜查詢、聚合(aggregation)、連線(join)和視窗函式(window functions)。作為Hive和Pig(Hive和Pig都是通過MapReduce的管道流來完成HDFS資料的查詢)的替代者,Presto 本身並不儲存資料,但是可以接入多種資料來源,並且支援跨資料來源的級聯查詢。
https://blog.csdn.net/u012535605/article/details/83857079 Presto沒有使用MapReduce,它是通過一個定製的查詢和執行引擎來完成的。它的所有的查詢處理是在記憶體中,這也是它的效能很高的一個主要原因。Presto和Spark SQL有很大的相似性,這是它區別於Hive的最根本的區別。
但Presto由於是基於記憶體的,而hive是在磁碟上讀寫的,因此presto比hive快很多,但是由於是基於記憶體的計算當多張大表關聯操作時易引起記憶體溢位錯誤。
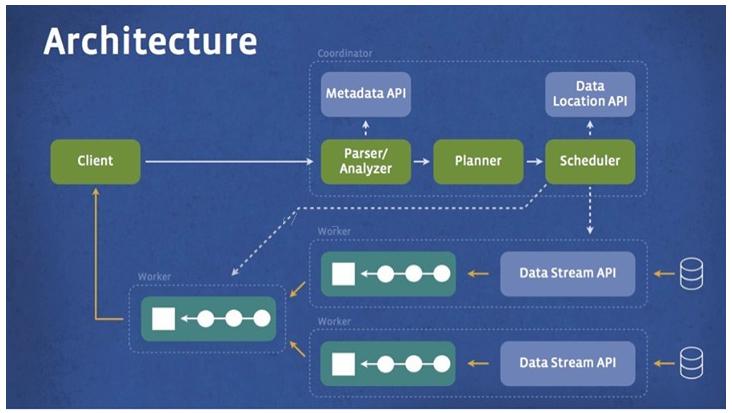 https://www.cnblogs.com/tgzhu/p/6033373.html
https://www.cnblogs.com/tgzhu/p/6033373.html
Kylin
http://kylin.apache.org/cn/ https://www.infoq.cn/article/kylin-apache-in-meituan-olap-scenarios-practice/ 提到Kylin就不得不說說ROLAP和MOLAP。
-
傳統OLAP根據資料儲存方式的不同分為ROLAP(relational olap)以及MOLAP(multi-dimension olap)
-
ROLAP 以關係模型的方式儲存用作多為分析用的資料,優點在於儲存體積小,查詢方式靈活,然而缺點也顯而易見,每次查詢都需要對資料進行聚合計算,為了改善短板,ROLAP使用了列存、並行查詢、查詢優化、點陣圖索引等技術。
-
MOLAP 將分析用的資料物理上儲存為多維陣列的形式,形成CUBE結構。維度的屬性值對映成多維陣列的下標或者下標範圍,事實以多維陣列的值儲存在陣列單元中,優勢是查詢快速,缺點是資料量不容易控制,可能會出現維度爆炸的問題。
而Kylin自身就是一個MOLAP系統,多維立方體(MOLAP Cube)的設計使得使用者能夠在Kylin裡為百億以上資料集定義資料模型並構建立方體進行資料的預聚合。
Apache Kylin™是一個開源的分散式分析引擎,提供Hadoop/Spark之上的SQL查詢介面及多維分析(OLAP)能力以支援超大規模資料,最初由eBay Inc. 開發並貢獻至開源社群。它能在亞秒內查詢巨大的Hive表。
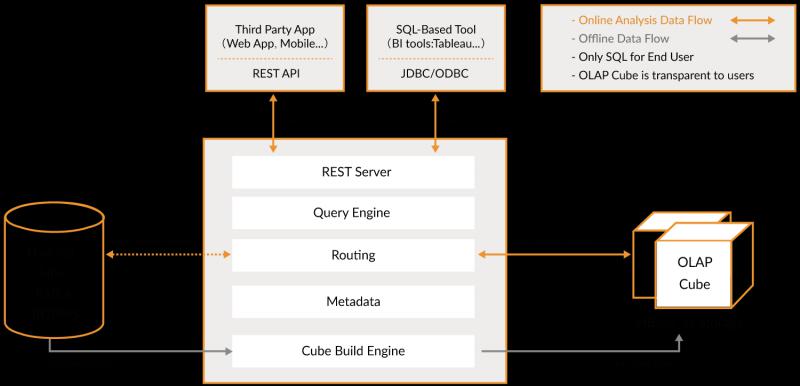
Kylin的優勢有:
- 提供ANSI-SQL介面
- 互動式查詢能力
- MOLAP Cube 的概念
- 與BI工具可無縫整合
所以適合Kylin的場景包括:
- 使用者資料存在於Hadoop HDFS中,利用Hive將HDFS檔案資料以關係資料方式存取,資料量巨大,在500G以上
- 每天有數G甚至數十G的資料增量匯入
- 有10個以內較為固定的分析維度
簡單來說,Kylin中資料立方的思想就是以空間換時間,通過定義一系列的緯度,對每個緯度的組合進行預先計算並存儲。有N個緯度,就會有2的N次種組合。所以最好控制好緯度的數量,因為儲存量會隨著緯度的增加爆炸式的增長,產生災難性後果。
Impala
Impala也是一個SQL on Hadoop的查詢工具,底層採用MPP技術,支援快速互動式SQL查詢。與Hive共享元資料儲存。Impalad是核心程序,負責接收查詢請求並向多個數據節點分發任務。statestored程序負責監控所有Impalad程序,並向叢集中的節點報告各個Impalad程序的狀態。catalogd程序負責廣播通知元資料的最新資訊。
Impala的架構圖如下:
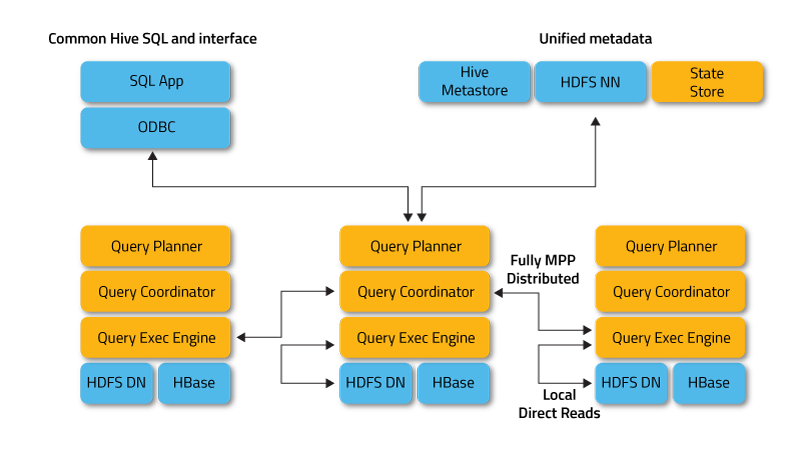
Impala的特性包括:
- 支援Parquet、Avro、Text、RCFile、SequenceFile等多種檔案格式
- 支援儲存在HDFS、HBase、Amazon S3上的資料操作
- 支援多種壓縮編碼方式:Snappy、Gzip、Deflate、Bzip2、LZO
- 支援UDF和UDAF
- 自動以最有效的順序進行表連線
- 允許定義查詢的優先順序排隊策略
- 支援多使用者併發查詢
- 支援資料快取
- 提供計算統計資訊(COMPUTE STATS)
- 提供視窗函式(聚合 OVER PARTITION, RANK, LEAD, LAG, NTILE等等)以支援高階分析功能
- 支援使用磁碟進行連線和聚合,當操作使用的記憶體溢位時轉為磁碟操作
- 允許在where子句中使用子查詢
- 允許增量統計——只在新資料或改變的資料上執行統計計算
- 支援maps、structs、arrays上的複雜巢狀查詢
- 可以使用impala插入或更新HBase
同樣,Impala經常會和Hive、Presto放在一起做比較,Impala的劣勢也同樣明顯:
- Impala不提供任何對序列化和反序列化的支援。
- Impala只能讀取文字檔案,而不能讀取自定義二進位制檔案。
- 每當新的記錄/檔案被新增到HDFS中的資料目錄時,該表需要被重新整理。這個缺點會導致正在執行的查詢sql遇到重新整理會掛起,查詢不動。
Druid
https://druid.apache.org/ https://blog.csdn.net/warren288/article/details/80629909
Druid 是一種能對歷史和實時資料提供亞秒級別的查詢的資料儲存。Druid 支援低延時的資料攝取,靈活的資料探索分析,高效能的資料聚合,簡便的水平擴充套件。適用於資料量大,可擴充套件能力要求高的分析型查詢系統。
Druid解決的問題包括:資料的快速攝入和資料的快速查詢。 所以要理解Druid,需要將其理解為兩個系統,即輸入系統和查詢系統。
Druid的架構如下:
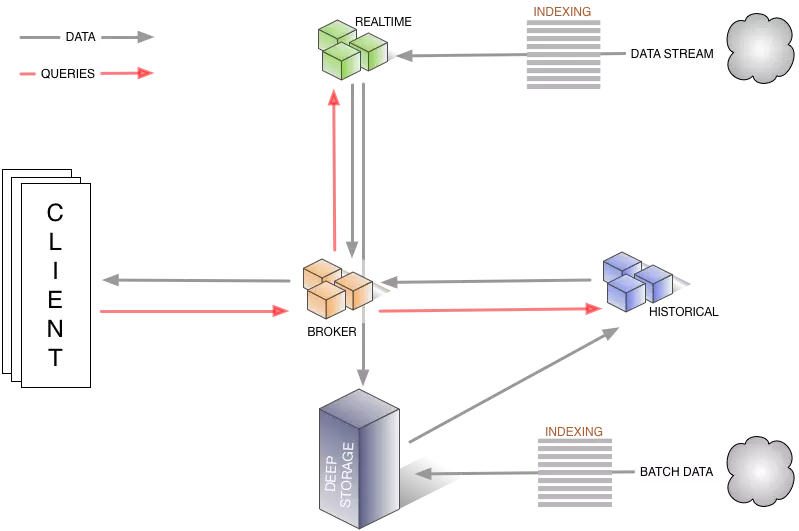
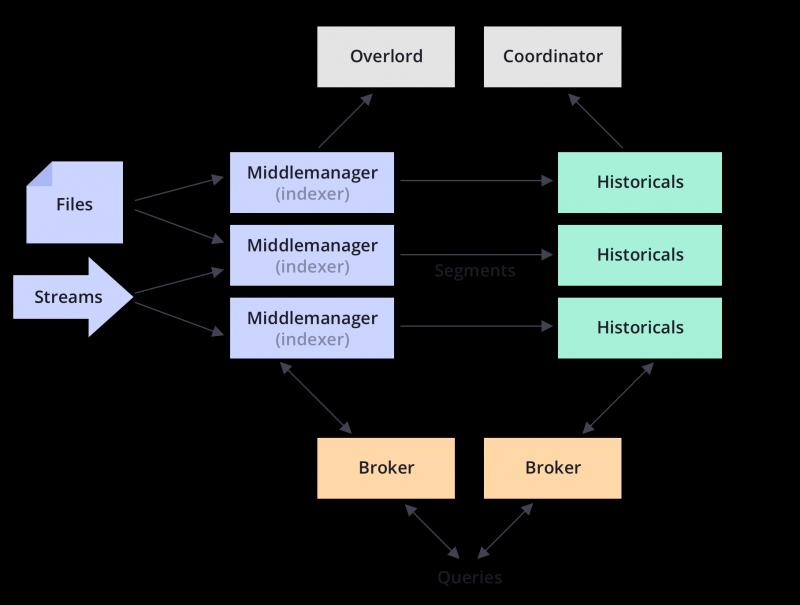
Druid的特點包括:
- Druid實時的資料消費,真正做到資料攝入實時、查詢結果實時
- Druid支援 PB 級資料、千億級事件快速處理,支援每秒數千查詢併發
- Druid的核心是時間序列,把資料按照時間序列分批儲存,十分適合用於對按時間進行統計分析的場景
- Druid把資料列分為三類:時間戳、維度列、指標列
- Druid不支援多表連線
- Druid中的資料一般是使用其他計算框架(Spark等)預計算好的低層次統計資料
- Druid不適合用於處理透視維度複雜多變的查詢場景
- Druid擅長的查詢型別比較單一,一些常用的SQL(groupby 等)語句在druid裡執行速度一般
- Druid支援低延時的資料插入、更新,但是比hbase、傳統資料庫要慢很多
與其他的時序資料庫類似,Druid在查詢條件命中大量資料情況下可能會有效能問題,而且排序、聚合等能力普遍不太好,靈活性和擴充套件性不夠,比如缺乏Join、子查詢等。
我個人對Druid的理解在於,Druid保證資料實時寫入,但查詢上對SQL支援的不夠完善(不支援Join),適合將清洗好的記錄實時錄入,然後迅速查詢包含歷史的結果,在我們目前的業務上沒有實際應用。
Druid的應用可以參考: 《Druid 在有讚的使用場景及應用實踐》https://blog.csdn.net/weixin_34273481/article/details/89238947
Greeplum
https://blog.csdn.net/yongshenghuang/article/details/84925941 https://www.jianshu.com/p/b5c85cadb362
Greenplum是一個開源的大規模並行資料分析引擎。藉助MPP架構,在大型資料集上執行復雜SQL分析的速度比很多解決方案都要快。
GPDB完全支援ANSI SQL 2008標準和SQL OLAP 2003 擴充套件;從應用程式設計介面上講,它支援ODBC和JDBC。完善的標準支援使得系統開發、維護和管理都大為方便。支援分散式事務,支援ACID。保證資料的強一致性。做為分散式資料庫,擁有良好的線性擴充套件能力。GPDB有完善的生態系統,可以與很多企業級產品整合,譬如SAS,Cognos,Informatic,Tableau等;也可以很多種開源軟體整合,譬如Pentaho,Talend 等。
GreenPulm的架構如下:
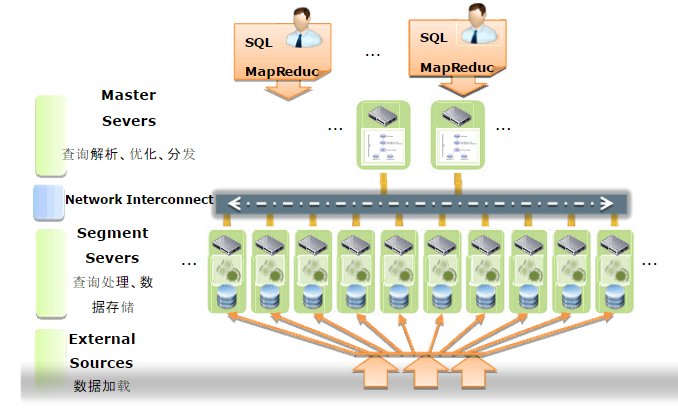
GreenPulm的技術特點如下:
- 支援海量資料儲存和處理
- 支援Just In Time BI:通過準實時、實時的資料載入方式,實現資料倉庫的實時更新,進而實現動態資料倉庫(ADW),基於動態資料倉庫,業務使用者能對當前業務資料進行BI實時分析(Just In Time BI)
- 支援主流的sql語法,使用起來十分方便,學習成本低
- 擴充套件性好,支援多語言的自定義函式和自定義型別等
- 提供了大量的維護工具,使用維護起來很方便
- 支援線性擴充套件:採用MPP並行處理架構。在MPP結構中增加節點就可以線性提供系統的儲存容量和處理能力
- 較好的併發支援及高可用性支援除了提供硬體級的Raid技術外,還提供資料庫層Mirror機制保護,提供Master/Stand by機制進行主節點容錯,當主節點發生錯誤時,可以切換到Stand by節點繼續服務
- 支援MapReduce
- 資料庫內部壓縮
一個重要的資訊:Greenplum基於Postgresql,也就是說GreenPulm和TiDB的定位類似,想要在OLTP和OLAP上進行統一。
ClickHouse
https://clickhouse.yandex/ https://clickhouse.yandex/docs/zh/development/architecture/ http://www.clickhouse.com.cn/ https://www.jianshu.com/p/a5bf490247ea
官網對ClickHouse的介紹:
ClickHouse is an open source column-oriented database management system capable of real time generation of analytical data reports using SQL queries.
Clickhouse由俄羅斯yandex公司開發。專為線上資料分析而設計。Yandex是俄羅斯搜尋引擎公司。官方提供的文件表名,ClickHouse 日處理記錄數"十億級"。
特性:採用列式儲存;資料壓縮;支援分片,並且同一個計算任務會在不同分片上並行執行,計算完成後會將結果彙總;支援SQL;支援聯表查詢;支援實時更新;自動多副本同步;支援索引;分散式儲存查詢。
大家都Nginx不陌生吧,戰鬥民族開源的軟體普遍的特點包括:輕量級,快。
ClickHouse最大的特點就是快,快,快,重要的話說三遍! 與Hadoop、Spark這些巨無霸元件相比,ClickHouse很輕量級,其特點:
- 列式儲存資料庫,資料壓縮
- 關係型、支援SQL
- 分散式平行計算,把單機效能壓榨到極限
- 高可用
- 資料量級在PB級別
- 實時資料更新
- 索引
使用ClickHouse也有其本身的限制,包括:
- 缺少高頻率,低延遲的修改或刪除已存在資料的能力。僅能用於批量刪除或修改資料。
- 沒有完整的事務支援
- 不支援二級索引
- 有限的SQL支援,join實現與眾不同
- 不支援視窗功能
- 元資料管理需要人工干預維護
總結
上面給出了常用的一些OLAP引擎,它們各自有各自的特點,我們將其分組:
- Hive,Hawq,Impala - 基於SQL on Hadoop
- Presto和Spark SQL類似 - 基於記憶體解析SQL生成執行計劃
- Kylin - 用空間換時間,預計算
- Druid - 一個支援資料的實時攝入
- ClickHouse - OLAP領域的Hbase,單表查詢效能優勢巨大
- Greenpulm - OLAP領域的Postgresql
如果你的場景是基於HDFS的離線計算任務,那麼Hive,Hawq和Imapla就是你的調研目標; 如果你的場景解決分散式查詢問題,有一定的實時性要求,那麼Presto和SparkSQL可能更符合你的期望; 如果你的彙總維度比較固定,實時性要求較高,可以通過使用者配置的維度+指標進行預計算,那麼不妨嘗試Kylin和Druid; ClickHouse則在單表查詢效能上獨領風騷,遠超過其他的OLAP資料庫; Greenpulm作為關係型資料庫產品,效能可以隨著叢集的擴充套件線性增長,更加適合進行資料分析。
就像美團在調研Kylin的報告中所說的:
目前還沒有一個OLAP系統能夠滿足各種場景的查詢需求。 其本質原因是,沒有一個系統能同時在資料量、效能、和靈活性三個方面做到完美,每個系統在設計時都需要在這三者間做出取捨。
 歡迎掃碼關注我的公眾號,回覆【JAVAPDF】可以獲得一份200頁秋招
歡迎掃碼關注我的公眾號,回覆【JAVAPDF】可以獲得一份200頁秋招