
HBase匯入資料同時與Phoenix實現同步對映
1.HDFS上資料準備
2019-03-24 09:21:57.347,869454021315519,8,1 2019-03-24 22:07:15.513,867789020387791,8,1 2019-03-24 21:43:34.81,357008082359524,8,1 2019-03-24 16:05:32.227,860201045831206,8,1 2019-03-24 18:11:18.167,866676040163198,8,1 2019-03-24 22:01:24.877,868897026713230,8,1 2019-03-24 12:34:23.377,863119033590062,8,1 2019-03-24 20:16:32.53,862505041870010,8,1 2019-03-24 09:10:55.18,864765037658468,8,1 2019-03-24 16:18:41.503,869609023903469,8,1 2019-03-24 10:44:52.027,869982033593376,8,1 2019-03-24 20:00:08.007,866798025149107,8,1 2019-03-24 10:25:18.1,863291034398181,2,3 2019-03-24 10:33:48.56,867557030361332,8,1 2019-03-24 16:42:15.057,869841022390535,8,1 2019-03-24 10:08:00.277,867574031105048,8,1
注意: 分隔符是‘,’
2. HBase上建立表
create 'ALLUSER','INFO';3. 在Phoenix中建立相同的表名以實現與hbase表的對映
create table if not exists ALLUSER(
firsttime varchar primary key,
INFO.IMEI varchar,
INFO.COID varchar,
INFO.NCOID varchar
)注意:
- 除主鍵外,Phoenix表的表名和欄位欄位名要和HBase表中相同,包括大小寫
- Phoneix中的column必須以HBase的columnFamily開頭
4. 通過importtsv.separator指定分隔符,否則預設的分隔符是tab鍵
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.columns=HBASE_ROW_KEY,INFO:IMEI,INFO:IMEI,INFO:NCOID \
-Dimporttsv.separator=, -Dimporttsv.bulk.output=/warehouse/temp/alluser ALLUSER /user/hive/warehouse/toutiaofeedback.db/newuser/000001_05. 將生成的HFlie匯入到HBase
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /warehouse/temp/alluser ALLUSER6. 檢視HBase,Phoenix
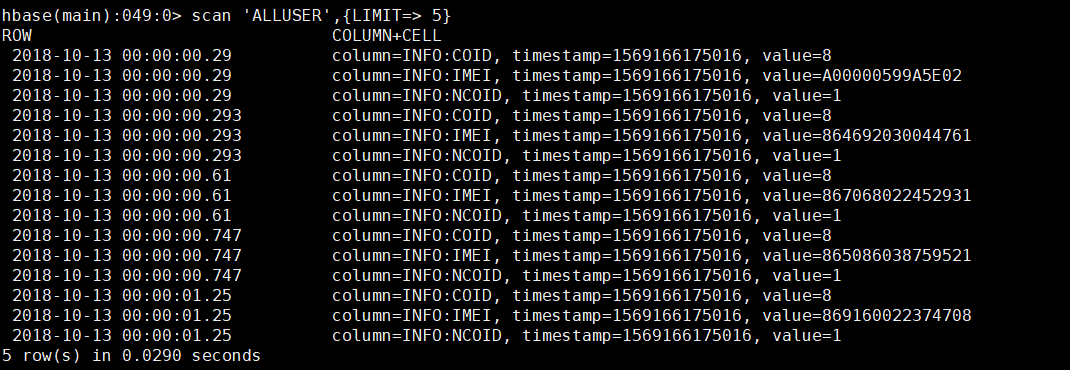
檢視HBase
檢視Phoenix

相關推薦
HBase匯入資料同時與Phoenix實現同步對映
1.HDFS上資料準備 2019-03-24 09:21:57.347,869454021315519,8,1 2019-03-24 22:07:15.513,867789020387791,8,1 2019-03-24 21:43:34.81,357008082359524,8,1 2019-03-24 1
往HBase匯入資料的幾種操作
HBase作為Hadoop DataBase,除了使用put進行資料匯入之外,還有以下幾種匯入資料的方式: (1)使用importTsv功能將csv檔案匯入HBase; (2)使用import功能,將資料匯入HBase; (3)使用BulkLoad功能將資料匯入HBase。 接下
python實現Phoenix批量匯入資料
官網文件: Phoenix provides two methods for bulk loading data into Phoenix tables: Single-threaded client loading tool for CSV formatted data
mysql中的資料匯入到hbase中,並關聯phoenix
1.在hbase上建立表: hbase>create 'ES','f1' 2.phoenix上建立表: jdbc:phoenix:es01> create table ES(ids varchar primary key ,"f1"."class_name" va
Phoenix通過MapReduce對HBase批量匯入資料
在用該方法之前,請確保hadoop、hbase、phoenix已經啟動。 在phoenix的安裝目錄下使用以下程式碼,啟動MR HADOOP_CLASSPATH=/opt/hbase-0.98.
資料匯入終章:如何將HBase的資料匯入HDFS?
我們的最終目標是將資料匯入Hadoop,在之前的章節中,我們介紹瞭如何將傳統關係資料庫的資料匯入Hadoop,本節涉及到了HBase。HBase是一種實時分散式資料儲存系統,通常位於與Hadoop叢集相同的硬體上,或者與Hadoop叢集緊密相連,能夠直接在MapReduce中使用HBase資料,或將
Hbase通過BulkLoad快速匯入資料
HBase是一個分散式的、面向列的開源資料庫,它可以讓我們隨機的、實時的訪問大資料。大量的資料匯入到Hbase中時速度回很慢,不過我們可以使用bulkload來匯入。 BulkLoad的過程主要有以下部分: 1. 從資料來源提取資料並上傳到HDFS中。 2. 使用MapReduce作
jfinal+hbase+eclipse開發web專案詳細步驟04---在web頁面實現對hbase資料庫資料的增刪查改功能
首先提醒大家,本節是在步驟01、步驟02、步驟03都成功的基礎上做進一步開發。如果在之前的任何一個步驟出現問題,那麼希望你先解決好問題之後,再做本次的開發。 步驟1:建表。 1、開啟我們虛擬機器,並且啟動hadoop、hbase start-all.sh start
hbase中的使用completebulkload匯入資料
completebulkload(十分重要,在實際開發中一般都是使用這樣的方式來載入資料到表中): file(csv)->hfile->load:這種方式是直接將file檔案轉換成hfile檔案,然後直接load到hbase中,因為自己載入資料到hbase中的時候,需要經過HLo
Hbase Import匯入資料異常處理-RetriesExhaustedWithDetailsException
CDH顯示 問題導致原因: hbase org.apache.hadoop.hbase.mapreduce.Import -Dmapred.job.queue.name=etl crawl:wechat_biz /hbase/test4 執行import時,短時間
C#解析Mysql的sql指令碼實現批量匯入資料
最近老大對我們做的資料匯入功能意見挺大,資料量一上來,匯入時間就很長,嚴重影響使用者體驗。因此,不得不花時間搗鼓了一下資料匯入的效能優化問題 原始程式碼: MySqlCommand command = new MySqlCommand(); command.Connection = conn
Java實現Excel批量匯入資料
Excel的批量匯入是很常見的功能,這裡採用 Jxl實現,資料量或樣式要求較高可以採用 poi 框架環境:Spring + SpringMvc(註解實現) 首先匯入依賴jar包 <dependency> <groupId>ne
MATLAB實現兩組不同資料的時間對齊/同步
兩組不同資料的時間同步 對兩組不同資料進行融合的過程中,需要保證兩組資料的時間標籤的完全對齊的。這裡利用MATLAB實現兩組資料的時間標籤對齊,其中要求資料Data1的取樣頻率大於資料Data2的取樣頻率。 function SynMatrix = TimeSy
在Linux上部署使用kettle實現資料的時間戳增量同步(超詳細)
之前公司的資料同步都是在windows平臺上做的,同事告訴我用windows做資料同步的問題在於他的電腦不能關機,並且spoon必須一直保持開啟狀態,但他的kettle總會自己莫名掉線。於是,把資料同步這項工作從windows轉移到linux上是不可避免的也是必須的。我實現的
HBase利用bulk load批量匯入資料
OneCoder只是一個初學者,記錄的只是自己的一個過程。不足之處還望指導。 看網上說匯入大量資料,用bulk load的方式效率比較高。bulk load可以將固定格式的資料檔案轉換為HFile檔案匯入,當然也可以直接匯入HFile檔案。所以
依賴POI實現EXCEL匯入資料並生成javaBean和EXCEL根據資料庫表匯出
首先是excel匯入匯出的工具類程式碼 public class ExportExcel { // 測試123 private ExportExcel() { } /*** * 工作簿 */
用java實現從txt文字檔案批量匯入資料至資料庫
今天同事讓我準備一個專案的測試資料,要向一個表中插入上千條記錄,並且保證每條記錄內容不同,如果用手工一條一條插入肯定是不可能,也不會有哪個SB去做這樣的事,我最開始想到了用迴圈,但要求插入的記錄內容不能相同,用迴圈實現比較麻煩,於是我想到了將記錄從文字檔案匯入至資料庫(其實
SpringCloud之實現上傳Excel檔案,初始化匯入資料至資料庫
1、頁面程式碼如下,彈出窗是用的layer: <input type="button" class="btn_default" style="width: 100px;" onclick="investigation();" value="匯入心理諮詢"/>
Hbase批量匯入資料,支援多執行緒同時操作
/** * HBase操作工具類:快取模式多執行緒批量提交作業到hbase * * @Auther: ning.zhang * @Email: [email protected] * @CreateDate: 2018/7/30 */ public c
阿里雲canal訂閱mysql的binlog日誌實現資料和表結構實時同步
1.開啟mysql binlog日誌 安裝路徑下的my.ini檔案新增配置log-bin=mysql-bin #開啟日誌binlog-format=ROW #選擇row模式server_id=1 開啟日誌需要重啟mysql服務後生效2.下載canal 地址:https://g