
BERT論文解讀
本文儘量貼合BERT的原論文,但考慮到要易於理解,所以並非逐句翻譯,而是根據筆者的個人理解進行翻譯,其中有一些論文沒有解釋清楚或者筆者未能深入理解的地方,都有放出原文,如有不當之處,請各位多多包含,並希望得到指導和糾正。
論文標題
- Bert:Bidirectional Encoder Representations from Transformers
一種從Transformers模型得來的雙向編碼表徵模型。
論文地址
- https://arxiv.org/pdf/1810.04805
Abstract
BERT的設計是通過在所有層中對左右上下文進行聯合調節,來預先訓練來自未標記文字的深層雙向表示。
預訓練的BERT模型可以通過fine-tuned 在廣泛的任務中創造新的最佳記錄,比如問答任務,語言推理任務等,而不需要對BERT本身架構做實質性的修改。
1 Introduction
BERT是一個概念上簡單,實踐結果強大的模型。其在11項自然語言處理任務中創造了新的最佳記錄。
ELMo是基於feature-based【註解2】的方法應用pre-trained language representations的。
OpenAI GPT是基於fine-tuning【註解3】 的方法應用pre-trained language representations的。
上面兩個方法在與訓練階段,共享相同的目標函式,它們使用單項語言模型來學習通用語言表徵。
作者認為對於句子來說,單向注意力是次優的,對於token級別的任務,比如問答任務來說,就會帶來不好的作用。因為在類似問答任務中,基於兩個方向的上下文的結合非常重要。
本論文,作者通過提出BERT模型,來改善基於fine-tuning的方法。
BERT:Bidirectional Encoder Representations from Transformers.
BERT受到完型填空任務的啟發,通過使用一個“masked language model”(MLM)預訓練目標來減輕上面提到的單向約束問題。
MLM隨機masks掉input中的一些tokens,目標是從這些tokens的上下文中預測出它們在原始詞彙表中的id。不想left-to-right 的預訓練語言模型,MLM目標使得表徵融合了left和right的上下文資訊,這允許作者預訓練一個深度雙向的Transformer模型。除了MLM,作者還使用了一個“next sentence prediction”任務,連帶的預訓練text-pair表徵。本篇論文的貢獻如下:
展示了雙向預訓練語言表徵的重要性。BERT使用MLM使得模型可以預訓練深度雙向表徵;GPT在預訓練上使用單向語言模型;ELMo使用分別訓練好的left-to-right 和right-to-left表徵,然後僅僅是簡單的串聯在一起。
- 顯示了預訓練表徵可以減少對許多工程繁重的特定任務架構的需求。BERT是首個在巨大量級的句子和詞級別的任務上達到最佳表現的基於fine-tuning的表徵模型。
BERT 打破了11項NLP任務的最佳記錄。程式碼和預訓練模型可以從這裡獲取 。
2 Related Work
預訓練通用語言表徵已經有相當長的歷史了。本節簡略看一下使用最廣泛的預訓練通用語言表徵的方法。
2.1 Unsupervised Feature-based Approaches
數十年來,學習廣泛適用的單詞表示形式一直是一個活躍的研究領域,包括非神經領域和神經領域的方法。預訓練詞嵌入是現代NLP系統的主要部分,提供了從零開始學習詞嵌入的顯著改進。為了預訓練詞嵌入向量,人們使用過left-to-right語言建模目標,以及從左右上下文中區分出正確和不正確的單詞的建模目標。
這些方法已經推廣到更粗的粒度,比如句子嵌入,或段落嵌入。為了訓練句子表徵,之前的工作已經用過這些目標:下個候選句子排名;給定上一個句子的表徵,left-to-right生成下一個句子;從自動編碼器去噪。
ELMo和它的前身從不同的維度概括了傳統的詞嵌入研究。它們從left-to-right和right-to-left語言模型中提取上下文敏感的特徵。每個token(單詞、符號等)的上下文表徵是通過串聯left-to-right和right-to-left的表徵得到的。在將上下文詞嵌入和已有的特定任務的架構結合後,ELMo在幾個主要NLP基準測試(包括:問答,情感分析,命名實體識別)上取得了最佳記錄。Melamud等人在2016年提出了使用LSTMs模型通過一個預測單詞左右上下文的任務來學習上下文表徵。與ELMo類似,他們的模型也是基於feature-based方法,並且沒有深度雙向(註解1)。Fedus等人在2018年展示了完型填空任務可以用來改善文字生成模型的魯棒性。
2.2 Unsupervised Fine-tuning Approaches
與feature-based方法一樣,該方向剛開始只是在未標記的文字上預訓練詞嵌入引數(無監督學習)。
最近,句子和文件等生成上下文token表徵的編碼器已經從未標記的文字中預訓練出來,並且通過fine-tuned的方式用在下游任務中。這些方法的優勢在於很少需要從零開始學習引數。至少有部分是因為這個優點,OpenAI GPT之前在許多來自GLUE基準測試的句子級別的任務上達到了最佳水平。Left-to-right 語言建模和自動編碼器目標用於訓練這種模型。
2.3 Transfer Learning from Supervised Data
也有工作展示了從大資料集的監督任務的做遷移學習的有效性,就像自然語言推理(NLI),和機器翻譯。計算機視覺研究也展示了遷移學習的重要性,一個有效的技巧就是微調(fine-tune)ImageNet的預訓練模型。
3 BERT
本節介紹BERT的詳細實現。使用BERT有2個步驟:pre-training 和 fine-tuning。在預訓練期間,BERT模型在不同任務的未標記資料上進行訓練。微調的時候,BERT模型用預訓練好的引數進行初始化,並且是基於下游任務的有標籤的資料來訓練的。每個下游任務有自己的微調模型,儘管最初的時候都是用的預訓練好的BERT模型引數。圖1中,問答領域的例子作為本節一個執行示例。
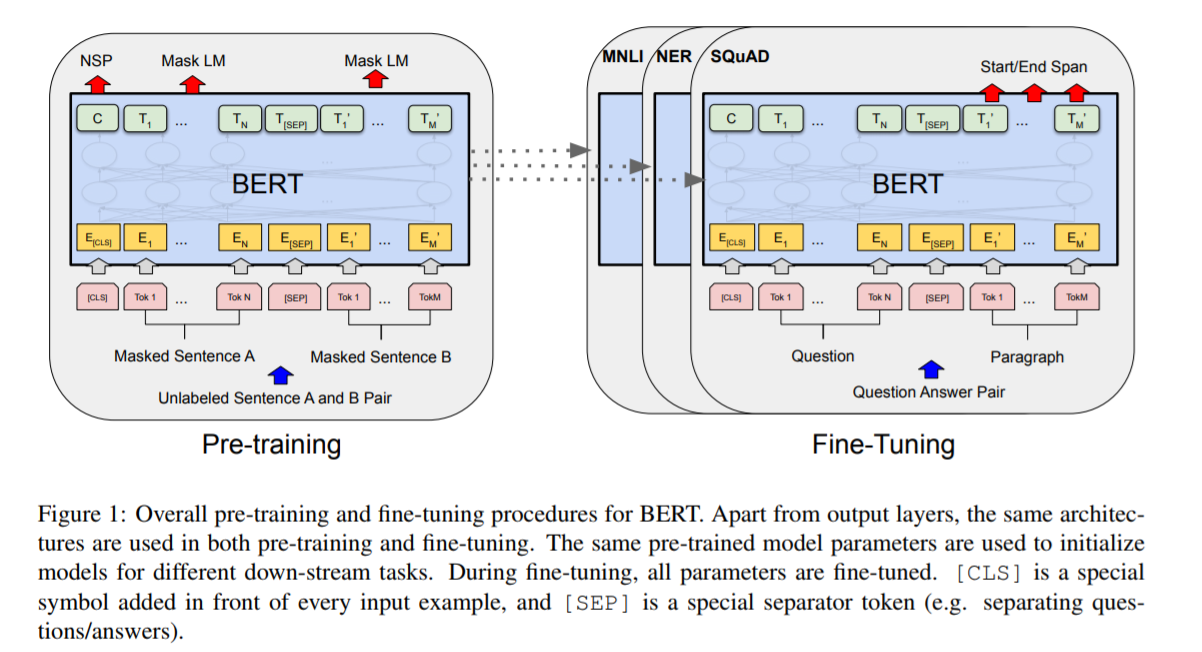
圖1:BERT的pre-training和fine-tuning執行過程。除了output層,這兩個階段的架構是一樣的。預訓練模型的引數會做為不同下游任務的模型的初始化引數。在fine-tuning時,所有引數參與微調。[CLS]時一個特別設定的符號,新增在每個輸入樣本的前面,表示這是一個輸入樣本的開始,[SEP]是特別設定的一個分隔標記。比如分隔questions/answers。
BERT的一個與眾不同的特性是它的跨任務的統一架構,即在預訓練架構和下游的架構之間的差異最小。
Model Architecture
BERT的模型架構是一個多層雙向Transformer編碼器,(關於Transformer可以看這篇文章)。因為Transformer的使用變得普遍,而且BERT的與Transformer相關的實現和原Tranformer幾乎一樣,所以本論文中不再詳述,推薦讀者去看原Transformer論文,以及“The Annotated Transformer”(這是對原論文中闡述的Transformer的一個極好的講解)。
這裡,作者指明L表示層數,H表示每個隱藏單元的維數大小,A表示self-attention頭數。BERT有2種大小的模型,分別是BERT(base,L=12, H=768, A=12, Total Parameters=110M)和BERT(large,L=24, H=1024, A=16, Total Parameters=340M)。
BERT(base)設定為和OpenAI GPT的模型大小相同,以便作比較。需要重點說明的是,BERT Transformer使用雙向self-attention,而GPT
Transformer 使用帶約束的self-attention,每個token只能注意到它左邊的上下文。
Input/Output Representations
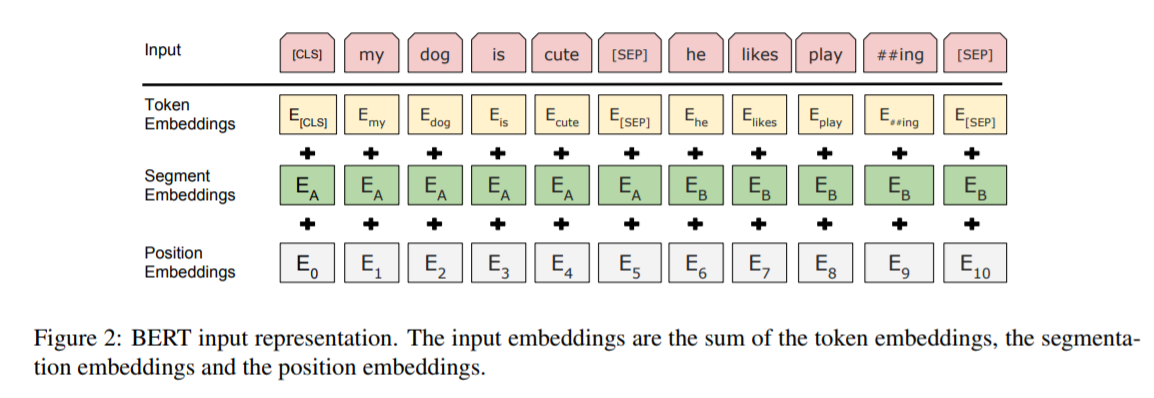
使用BERT做各種下游任務,輸入表徵可以在一個token序列裡清楚的表示一個句子或者一對句子(比如<Question,Answer>)。這裡的“句子”不是必須是語言句子,而可以是任意範圍的連續文字。“sequence”指BERT的輸入序列,可以是一個句子,也可以是兩個打包在一起的句子。
作者使用了WordPiece embeddings來做詞嵌入,對應的詞彙表有30000個token。每個序列的首個token總是一個特定的classification token([CLS])。這個token對應的最後的隱藏狀態被用作分類任務的聚合序列表徵。句子對打包成一個序列。有兩種區分句子對中的句子的方法。第一種,通過分隔符[SEP];第二種,模型架構中添加了一個經過學習的嵌入(learned embedding)到每個token,以表示它是屬於句子A或者句子B。如圖1中,E表示輸入的詞嵌入,C表示最後隱藏層的[CLS]的向量,Ti表示第i個輸入token在最後隱藏層的向量。
對一個給定的token,其輸入表徵由對應的token,segment和position embeddings的相加來構造。如圖2。
3.1 Pre-training BERT
Task 1:Masked LM
直觀上來說,作者有理由相信,一個深度雙向模型確實會比單向或者淺度雙向模型要強大。
可惜,標準的條件語言模型只能從按照left-to-right或者right-to-left的方式訓練,直至雙向條件可以允許每個詞間接的“see itself”,並且可以在多層上下文中預測目標單詞。
Unfortunately, standard conditional language models can only be trained left-to-right or right-to-left, since bidirectional conditioning would allow each word to indirectly “see itself”, and the model could trivially predict the target word in a multi-layered context.(原句)
為了訓練一個深度雙向表徵,作者簡單的隨機mask一些百分比的輸入tokens,然後預測那些被mask掉的tokens。這一步稱為“masked LM”(MLM),儘管在文獻中它通常被稱為完型填空任務(Cloze task)。
mask掉的tokens對應的最後的隱藏層向量餵給一個輸出softmax,像在標準的LM中一樣。在實驗中,作者為每個序列隨機mask掉了15%的WordPiece tokens。和 denoising auto-encoders相比,BERT的做法是隻預測被mask掉的詞,而不是重建完整的輸入。
儘管這允許作者獲得雙向預訓練模型,其帶來的負面影響是在預訓練和微調模型之間創造了不匹配,因為[MASK]符號不會出現在微調階段。所以要想辦法讓那些被mask掉的詞的原本的表徵也被模型學習到,所以這裡作者採用了一些策略,具體參見:附錄 A.1。
Task 2:Next Sentence Prediction (NSP)
許多下游任務,比如問答,自然語言推理等,需要基於對兩個句子之間的關係的理解,而這種關係不能直接通過語言建模來獲取到。為了訓練一個可以理解句子間關係的模型,作者為一個二分類的下一個句子預測任務進行了預訓練,這些句子對可以從任何單語言的語料中獲取到。特別是,當為每個預測樣例選擇一個句子對A和B,50%的時間B是A後面的下一個句子(標記為IsNext), 50%的時間B是語料庫中的一個隨機句子(標記為NotNext)。圖1中,C用來預測下一個句子(NSP)。儘管簡單,但是該方法QA和NLI任務都非常有幫助。5.1節對此有展示。
NSP任務和 Jernite et al. (2017) and Logeswaran and Lee (2018)中的表示學習的目標密切相關。任務,先前的工作中,只將句子嵌入轉移到了下游任務中,而BERT轉移了所有引數來初始化終端任務模型的引數。
Pre-training data 預訓練過程很大程度上參考了已有的語言模型預訓練文獻。預訓練語料方面,作者使用了BooksCorpus(800M words),English Wikipedia(2500M words) 。作者只提取Wikipedia的文字段落,忽略列表,表格和標題。為了提取長連續序列,關鍵是使用文件級語料庫,而不是像十億詞基準(Chelba et al., 2013)這樣的無序的句子級語料庫。
3.2 Fine-tuning BERT
微調很簡單,因為Transformer中的self-attention機制允許BERT通過交換合適的輸入和輸出來為許多下游任務建模——無論是單個文字還是文字對。對於涉及到文字對的應用,常見的模式是分辨編碼文字對中的文字,然後應用雙向交叉的注意力。BERT使用self-attention機制統一了這兩個步驟,BERT使用self-attention編碼一個串聯的文字對,其過程中就包含了2個句子之間的雙向交叉注意力。
輸入端,句子A和句子B可以是:(1)釋義句子對(2)假設條件句子對(3)問答句子對 (4)文字分類或序列標註中的text-∅對。
輸出端,對於,token表徵餵給一個針對token級別的任務的輸出層,序列標註和問答是類似的,[CLS]表徵餵給一個分類器輸出層,比如情感分析。
微調的代價要比預訓練小的多。論文中的很多結果都從一個完全相同的預訓練模型開始,在TPU上只要花費1小時的時間就可以復現,GPU上也只要幾個小時。更多細節可以檢視附錄 A.5
4 Experiments
本節展示了BERT在11項NLP任務上的fine-tuning結果。
4.1 GLUE (General Lanuage Understanding Evaluation)
GLUE基準測試是一系列不同的自然語言理解任務。GLUE資料集的詳細描述在附錄B.1中。
GLUE上的fine-tune,作者使用第3節描述的句子和句子對,用最後的隱藏向量C作為表徵,C對應首個輸入token([CLS])。分類器層的權重係數矩陣W (形狀:K×H),K是類別的個數。 作者使用C和W計算標準的分類損失,比如log(softmax(C·W )).
在所有的GLUE任務上,作者使用了batch-size=32,epochs=3。對於每個任務,都通過開發集的驗證來選擇了最佳的微調學習率(在5e- 5,4e - 5,3e -5和2e-5之間)。另外,對於BERT的large模型,作者發現微調有時候在小資料集上不穩定,所以隨機重啟了幾次,並選擇了開發集上表現最佳的模型。With random restarts, we use the same pre-trained checkpoint but perform different fine-tuning data shuffling and classifier layer initialization.9(?)
BERT base版本的模型架構和OpenAI GPUT除了attention masking以外,幾乎相同。
BERT large 版本明顯比base版本要表現的更好。關於模型大小的影響,在5.2節有更深入的探討。
4.2 SQuAD v1.1 (Stanford Question Answering Dataset)
這是一個100k的問答對集合。給定一個問題和一篇短文,以及對應的答案,任務是預測出短文中的答案文字span(the answer text span in the passage)。
圖1所示,在問答任務中,作者將輸入問題和短文表示成一個序列,其中,使用A嵌入表示問題,B嵌入表示短文。在微調的時候,作者引入一個start向量S,和一個end向量E,維數都為H。answer span的起始詞word i的概率計算公式:
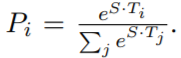
答案末尾詞的概率表示原理一樣。
位置i到位置j的候選span的分數定義如下:
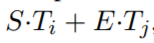
並將滿足j>i的最大得分的span最為預測結果。訓練目標是正確的開始和結束位置的對數似然估計的和。
作者微調了3個epochs,學習率設定為5e-5,batch-size設定為32。
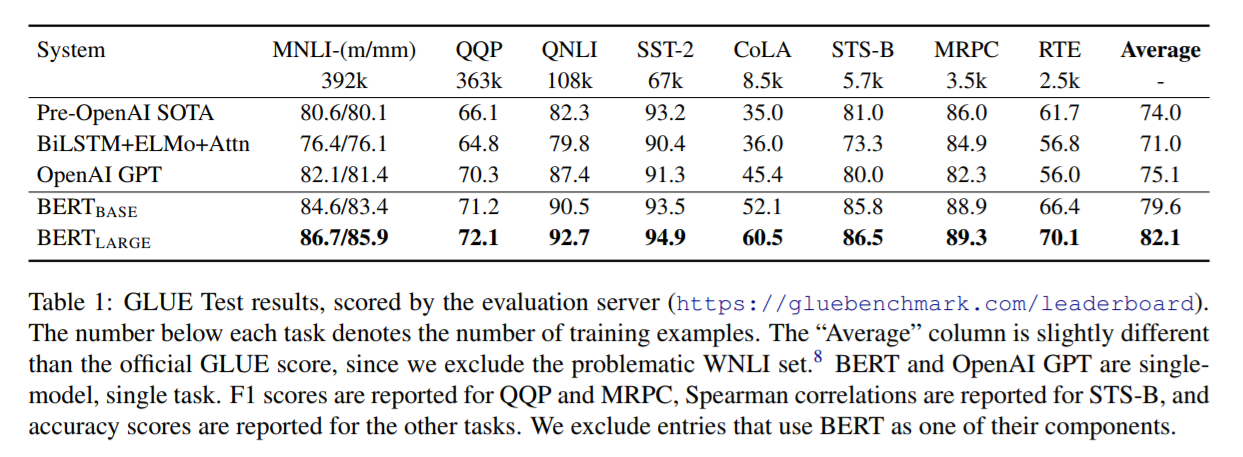
Table2 顯示了頂級排行耪和結果。其中SQuAD排行耪中的公共系統描述沒有最新的,並且允許使用任何公開資料訓練各自的網路。
因此,作者在系統中使用適度的資料增強,首先對TriviaQA進行微調(Joshi et al., 2017),然後再對SQuAD進行微調。
4.3 SQuAD v2.0
We treat questions that do not have an answer as having an answer span with start and end at the [CLS] token. The probability space for the start and end answer span positions is extended to include the position of the [CLS] token. For prediction, we compare the score of the no-answer span: snull = S·C + E·C to the score of the best non-null span
sˆi,j = maxj≥i S·Ti + E·Tj . We predict a non-null answer when sˆi,j > snull + τ , where the threshold τ is selected on the dev set to maximize F1. We did not use TriviaQA data for this model. We fine-tuned for 2 epochs with a learning rate of 5e-5 and a batch size of 48.
4.4 SWAG
The Situations With Adversarial Generations (SWAG)資料集包含113k個句子對完整示例,用於評估基於常識的推理。給定一個句子,任務是從四個選項中選擇出最有可能是對的的continuation(延續/擴充套件)。
在微調的時候,作者構造了4個輸入序列,每個包含給定句子A的序列和continuation(句子B)。引入的唯一特定於任務的引數是一個向量,它與[CLS]token做點積,得到每個選項的分數,該分數會通過一個softmax層來歸一化。
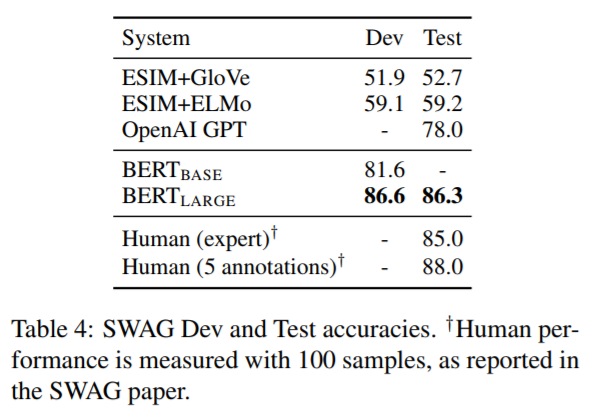
作者微調的時候,使用了3個epochs,lr設定為2e-5,batch-size設定為16。Table4中有對應的結果,BERT在該領域的表現接近人類。
5 Ablation Studies 消融研究
本節通過在BERT的各方面做消融實驗,來理解相對重要的部分。
5.1 Effect of Pre-training Tasks
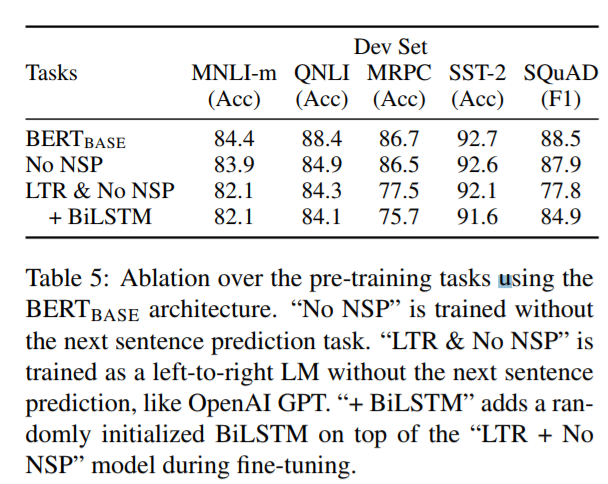
通過去掉NSP後,對比BERT的雙向表徵和Left-to-Right表徵,作者得證明了有NSP更好,且雙向表徵更有效。
通過引入一個雙向的LSTM,作者證明了BILSTM比Left-to-Right能得到更好的結果,但是仍然沒有BERT的base版本效果好。
具體對比結果如圖:
另外,關於ELMo那樣的分別訓練LTR和RTL的方式,作者也給出了其不如BERT的地方:
- this is twice as expensive as a single bidirectional model;
- this is non-intuitive for tasks like QA, since the RTL model would not be able to condition the answer on the question;
- this it is strictly less powerful than a deep bidirectional model, since it can use both left and right context at every layer.
5.2 Effect of Model Size
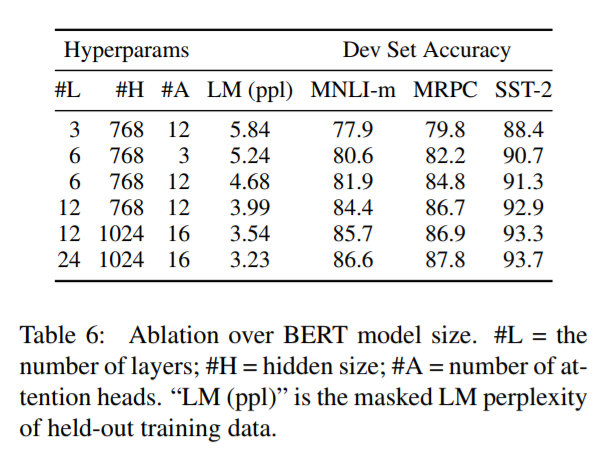
本節介紹模型大小對任務表現的影響。作者訓練了一些不同層數、隱藏單元數、注意力頭的BERT模型,但使用相同的超引數和訓練過程。
Table6展示了對比結果。大模型帶來更好的表現。
For example,
the largest Transformer explored in Vaswani et al. (2017) is (L=6, H=1024, A=16) with 100M parameters for the encoder, the largest Transformer we have found in the literature is (L=64, H=512, A=2) with 235M parameters (Al-Rfou et al., 2018). By contrast,
BERT(base) contains 110M parameters
BERT(large) contains 340M parameters.
本節作者最後給出的結論如下:
we hypothesize that when the model is fine-tuned directly on the downstream tasks and uses only a very small number of randomly initialized additional parameters, the taskspecific models can benefit from the larger, more expressive pre-trained representations even when downstream task data is very small.
大致意思是,通過微調,下游任務即使能提供的資料量非常小,依然可以利用預訓練模型得到不錯的訓練效果。
5.3 Feature-based Approach with BERT
相比於上面一直在說的fine-tuning的方式,feature-based的方式也有著其關鍵的優勢。
首先,不是所有的任務都可以輕易的表示成Trasformer encoder 架構,所以會有需要新增一個基於特定任務的模型架構的需求。
其次,預先計算一次訓練資料的昂貴表示,然後在此表示之上使用更便宜的模型執行許多實驗,這對計算有很大的好處。
本節,作者在BERT的命名實體識別應用上比較了fine-tuning和feature-based方式。
在BERT的輸入中,使用了一個保留大小寫的單詞模型,幷包含了資料提供的最大文件上下文。按照標準實踐,作者將其表示為標記任務,但在輸出中不使用CRF層。作者使用第一個sub-token的表徵,作為token-level的NER分類器的輸入。
為了和fine-tuning方法做消融實驗,作者以從沒有微調任何引數的一層或多層提取activations的方式應用feature-based方法。這些上下文的嵌入用做一個隨機初始化的兩層768維BiLSTM的輸入,然後送入分類器層。
Table 7顯示了實驗結果:
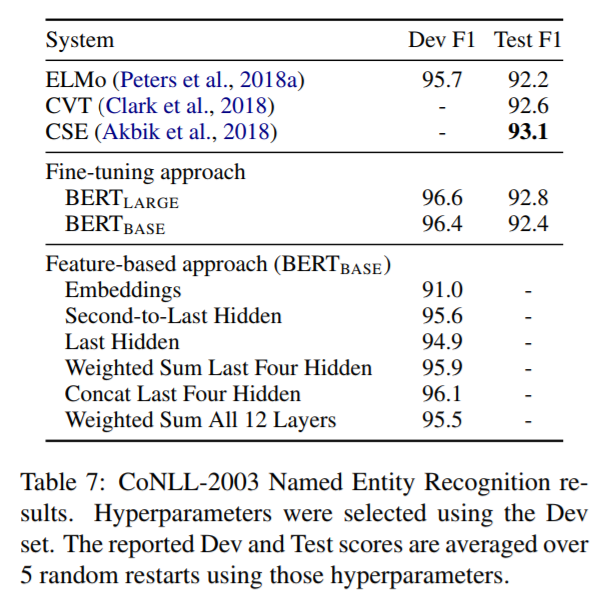
可以看到,feature-based方法中,拼接最後4個隱藏層的方式,可以達到96.1的F1分數,僅比BERT(base)少了0.3。
實驗結果表明,BERT的2種應用方法都是有效的。
6 Conclusion
近來通過遷移學習改善模型學習的例子表明了豐富的,無監督的預訓練是許多語言理解系統的重要組成部分。特別是,這些結果使得即使是低資源的任務也可以從深層單向架構中獲益。
BERT的主要貢獻是進一步將這些發現推廣到深層雙向架構,使得相同的預訓練模型可以成功應對一組廣泛的NLP任務。
附錄A Additional Details for BERT
A.1 Illustration of the Pre-training Tasks
作者在這裡提供了預訓練的樣例。
Masked LM and the Masking Procedure 假設原句子是“my dog is hairy”,作者在3.1節 Task1中提到,會隨機選擇句子中15%的tokens位置進行mask,假設這裡隨機選到了第四個token位置要被mask掉,也就是對hairy進行mask,那麼mask的過程可以描述如下:
- 80% 的時間:用[MASK]替換目標單詞,例如:my dog is hairy --> my dog is [MASK] 。
- 10% 的時間:用隨機的單詞替換目標單詞,例如:my dog is hairy --> my dog is apple 。
- 10% 的時間:不改變目標單詞,例如:my dog is hairy --> my dog is hairy 。 (這樣做的目的是使表徵偏向於實際觀察到的單詞。)
上面的過程,需要結合訓練過程的epochs來理解,每個epoch表示學完了一遍所有的樣本,所以每個樣本在多個epochs過程中是會重複輸入到模型中的,知道了這個概念,上面的80%,10%,10%就好理解了,也就是說在某個樣本每次餵給模型的時候,用[MASK]替換目標單詞的概率是80%;用隨機的單詞替換目標單詞的概率是10%;不改變目標單詞的概率是10%。
有的介紹BERT的文章中,講解MLM過程的時候,將這裡的80%,10%,10%解釋成替換原句子被隨機選中的15%的tokens中的80%用[MASK]替換目標單詞,10%用隨機的單詞替換目標單詞,10%不改變目標單詞。這個理解是不對的。
然後,作者在論文中談到了採取上面的mask策略的好處。大致是說採用上面的策略後,Transformer encoder就不知道會讓其預測哪個單詞,或者說不知道哪個單詞會被隨機單詞給替換掉,那麼它就不得不保持每個輸入token的一個上下文的表徵分佈(a distributional contextual representation)。也就是說如果模型學習到了要預測的單詞是什麼,那麼就會丟失對上下文資訊的學習,而如果模型訓練過程中無法學習到哪個單詞會被預測,那麼就必須通過學習上下文的資訊來判斷出需要預測的單詞,這樣的模型才具有對句子的特徵表示能力。另外,由於隨機替換相對句子中所有tokens的發生概率只有1.5%(即15%的10%),所以並不會影響到模型的語言理解能力。對此,本論文的C.2節做了對此過程影響的評估。
相比標準的語言模型訓練,masked LM在每個batch中僅對tokens的15%的部分進行預測,所以模型收斂需要更多的預訓練步驟。C.1節演示了MLM比left-to-right模型(會對每個token進行預測)收斂的稍慢,但是學習效果的改善遠遠超過了增加的訓練成本。
Next Sentence Prediction
”下個句子預測“的任務的例子:
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNextA.2 Pre-training Procedure 預訓練過程
本節首先介紹了下一句預測任務的樣本獲取策略,大致是從語料庫文字中選取2個span,這裡的span可以理解為一個完整話。然後,2個span分別對應句子A和句子B。其中,50%的情況下,句子B是句子A的下一句,而50%的情況下,B不是A的下一句。並且,句子A和B組合起來的長度要<=512個tokens。
然後介紹了LM的分詞情況:
The LM masking is applied after WordPiece tokenization with a uniform masking rate of 15%, and no special consideration given to partial word pieces.?
作者預訓練的時候採用batch-size=256,也就是說每個batch由256*512=128000個tokens,總共訓練了1,000,000步,將近40個epochs,超過33億個單詞。梯度優化演算法採用Adam,學習率=1e-4,β1=0.9,β2=0.999,0.01的L2權重衰減,學習率在首個10000步進行warmup【註釋4】 ,然後進行線性衰減。作者在所有層使用了0.1概率的的dropout。在啟用函式上,作者選擇了gelu,而不是標準的relu,這個選擇跟隨了OpenAI GPT。The training loss is the sum of the mean masked LM likelihood and the mean next sentence prediction likelihood.(訓練損失是masked掉的語言模型的似然均值與下一句預測的似然均值之和。)
BERT base模型在4塊雲TPU上訓練(共16塊TPU晶片)。BERT large在16塊雲TPU上訓練(共64塊TPU晶片)。每個預訓練持續4天的時間完成。
由於注意力的計算複雜度是序列長度的平方,所以更長的序列所增加的成本是昂貴的。為了加速實驗中的預訓練過程,作者對90%的步驟使用128長度的序列預訓練,然後用512長度的序列訓練剩餘的10%的步驟,以便學習到位置嵌入(positional embeddings)。
A.3 Fine-tuning Procedure
在fine-tuning的時候,模型的大多數超引數和預訓練的時候是一樣的,除了batch-size,learning rate和epochs。dropout的概率始終保持在0.1。優化超引數的值是特定於任務來做的,但是作者提到了下面的可能的值的範圍,該範圍內的值在跨任務上也工作的很好:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 2, 3, 4
作者也觀察了10萬+的訓練樣本,超引數選擇的敏感度遠低於小資料集。Fine-tuning仍然非常快,所以簡單粗暴的在上面的引數上執行一個窮舉搜尋來選擇出可以讓模型在開發集上表現最好的那些引數的方式也是可以接受的。
A.4 BERT,ELMo,OpenAI GPT對比
圖3展示了這3個模型架構的對比:
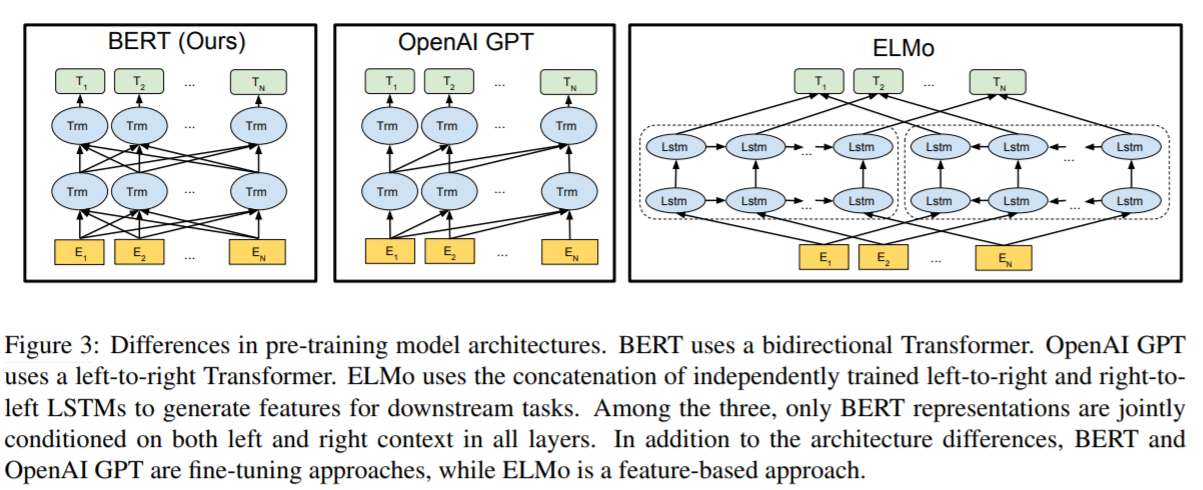
- BERT使用了雙向的Transformer架構
- OpenAI GPT使用了left-to-right的Transformer
- ELMo分別使用了left-to-right和right-to-left進行獨立訓練,然後將輸出拼接起來,為下游任務提供序列特徵
上面的三個模型架構中,只有BERT模型的表徵在每一層都聯合考慮到了左邊和右邊的上下文資訊。
除了架構不同,另外的區別在於BERT和OpenAI GPT是基於fine-tuning的方法,而ELMo是基於feature-based的方法。
除了MLM和NSP,BERT和GPT在訓練的時候還有如下幾處不同:
- GPT is trained on the BooksCorpus (800M words); BERT is trained on the BooksCorpus (800M words) and Wikipedia (2,500M words).
- GPT uses a sentence separator ([SEP]) and classifier token ([CLS]) which are only introduced at fine-tuning time; BERT learns [SEP], [CLS] and sentence A/B embeddings during pre-training.
- GPT was trained for 1M steps with a batch size of 32,000 words; BERT was trained for 1M steps with a batch size of 128,000 words.
- GPT used the same learning rate of 5e-5 for all fine-tuning experiments; BERT chooses a task-specific fine-tuning learning rate which performs the best on the development set.
作者為了證明BERT模型是因為2個預訓練任務和雙向的Transformer才比其他模型表現更好,所以在5.1節中闡述了他們做的消融實驗過程和結果。
A.5 不同任務下的Fine-tuning圖例
如圖4所示:
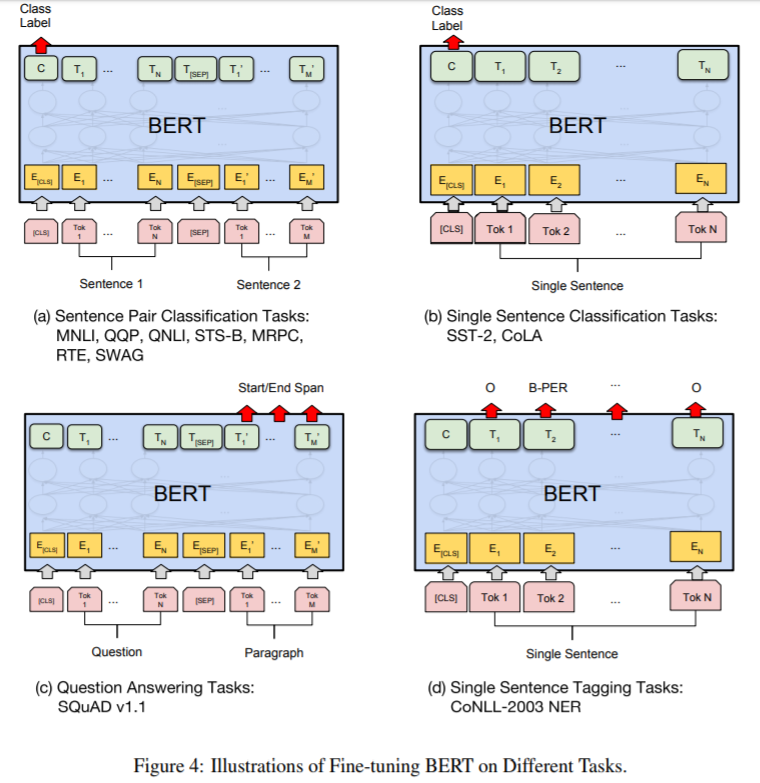
(a)和(b)是序列級別的任務;(c)和(d)是token級別的任務。
圖中的E表示輸入的詞嵌入,Ti表示第i個token的上下文表徵,[CLS]是分類輸出的特定符號,[SEP]是分隔非連續token序列的特定符號。
B 詳細的實驗配置
B.1 GLUE基準實驗的詳細描述
以下是模型訓練和評測使用的各種下游任務的資料集:
- MNLI 目標是預測第二個句子對於第一個句子是蘊含、矛盾還是中性的關係。
- QQP 目標是判斷兩個問題是否等價。
- QNLI 將標準問答資料集轉換成一個二分類任務。包含正確回答的句子對為正樣本,反之為負樣本。
- SST-2 對電影評論做情感分類。
- CoLA 預測一個句子是否符合語言學定義。
- STS-B 用1-5的分數表示2個句子的語義相似度。
- MRPC 判斷2個句子是否語義上等價。
- RTE 和MNLI類似,但是資料集小的多。
- WNLI 一個小型自然語言推理資料集。該資料集有一些問題,所以排除在評測之外。
C 其他消融研究
C.1 訓練步數的影響
圖5展示了在MNLI開發集上使用預訓練了k步的模型進行微調後得到的準確度。

通過此圖,就可以回答下面的問題了:
- BERT真的需要這麼巨大的預訓練量級嗎(128,000 words/batch * 1000,000 steps)?
是的。相對於500k的steps,準確度能提高1.0%
- MLM預訓練收斂速度比LTR慢嗎?因為每個batch中只有15%的單詞被預測,而不是所有單詞都參與。
確實稍稍有些慢。但是準確度因此而立刻超過了LTR模型,所以是值得的。
C.2 不同Masking過程的消融實驗
之前說過,mask策略的目的是減輕預訓練和微調之間的不匹配,因為[MASK]符號在微調的時候幾乎不會出現。Table8展示了基於Fine-tune和基於Feature-based的方式下,不同的MASK策略對結果的影響:
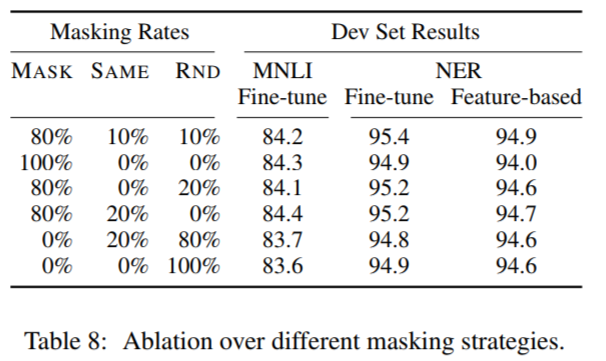
可以看到,Feature-based的方式下,MASK造成的不匹配的影響更大,因為模型在訓練的時候,特徵提取層沒有機會調整特徵表示(因為被凍結了)。
在feature-based方法中,作者將BERT的最後4層輸出拼接起來作為特徵,因為這樣的效果最好,具體見5.3節。
另外,我們還可以看到,fine-tuning方式在不同的mask策略下都具有驚人的魯棒性。然而,如作者所料,完全使用MASK的策略在feature-based方式下應用到NER領域是有問題的。有趣的是,全部使用隨機的策略也比第一行的策略差的多。
註解
- 深度雙向:深度雙向和淺度雙向的區別在於,後者僅僅是將分開訓練好的left-to-right和right-to-left的表徵簡單的串聯,而前者是一起訓練得到的。
- feature-based: 又稱feature-extraction 特徵提取。就是用預訓練好的網路在新樣本上提取出相關的特徵,然後將這些特徵輸入一個新的分類器,從頭開始訓練的過程。也就是說在訓練的過程中,網路的特徵提取層是被凍結的,只有後面的密集連結分類器部分是可以參與訓練的。
- fine-tuning: 微調。和feature-based的區別是,訓練好新的分類器後,還要解凍特徵提取層的頂部的幾層,然後和分類器再次進行聯合訓練。之所以稱為微調,就是因為在預訓練好的引數上進行訓練更新的引數,比預訓練好的引數的變化相對小,這個相對是指相對於不採用預訓練模型引數來初始化下游任務的模型引數的情況。也有一種情況,如果你有大量的資料樣本可以訓練,那麼就可以解凍所有的特徵提取層,全部的引數都參與訓練,但由於是基於預訓練的模型引數,所以仍然比隨機初始化的方式訓練全部的引數要快的多。對於作者團隊使用BERT模型在下游任務的微調時,就採用瞭解凍所有層,微調所有引數的方法。
- warmup:學習率熱身。規定前多少個熱身步驟內,對學習率採取逐步遞增的過程。熱身步驟之後,會對學習率採用衰減策略。這樣訓練初期可以避免震盪,後期可以讓loss降得更小。
ok,本篇就這麼多內容啦~,感謝閱讀O(∩_∩)O。

相關推薦
BERT論文解讀
本文儘量貼合BERT的原論文,但考慮到要易於理解,所以並非逐句翻譯,而是根據筆者的個人理解進行翻譯,其中有一些論文沒有解釋清楚或者筆者未能深入理解的地方,都有放出原文,如有不當之處,請各位多多包含,並希望得到指導和糾正。 論文標題 Bert:Bidirectional Encoder Represent
概率生成模型在驗證碼上的成果論文解讀
研究 輪廓 一般來說 分解 作用 nsh 級別 優秀 框架 摘要從少數樣本學習並泛化至截然不同的情況是人類視覺智能所擁有的能力,這種能力尚未被先進的機器學習模型所學習到。通過系統神經科學的啟示,我們引入了視覺的概率生成模型,其中基於消息傳送(message-passing)
《Playing hard exploration games by watching YouTube》論文解讀
cati 由於 表示 [1] array 大小 好的 log 循環 論文鏈接 油管鏈接 一、摘要 ??當環境獎勵特別稀疏的時候,強化學習方法通常很難訓練(traditionally struggle)。一個有效的方式是通過人類示範者(human demonstrator
An Analysis of Scale Invariance in Object Detection – SNIP 論文解讀
記錄 測試的 one zhang 不可 策略 correct 抽象 alt 前言 本來想按照慣例來一個overview的,結果看到一篇十分不錯而且詳細的介紹,因此copy過來,自己在前面大體總結一下論文,細節不做贅述,引用文章講得很詳細。 論文概述 引用文章 以下內容來自:
手勢識別論文解讀
Learning to Estimate 3D Hand Pose from Single RGB Images20173 主要流程 程式碼細節解讀 訓練流程解讀 Two-Stream Convolutional Networks for
MultiPoseNet論文解讀及復現
MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network. 原文連結 PRN網路 論文思路大致解讀 論文提出的網路結構大概分成三部分: 首先第一部分是Backbone網路
CTPN論文解讀
CTPN論文解讀 https://zhuanlan.zhihu.com/p/31915483 http://slade-ruan.me/2017/10/22/text-detection-ctpn/ 1. 區別 本文工作基於faster RCNN , 區別在於 改進了rpn
谷歌AI論文BERT雙向編碼器表徵模型:機器閱讀理解NLP基準11種最優(公號回覆“谷歌BERT論文”下載彩標PDF論文)
谷歌AI論文BERT雙向編碼器表徵模型:機器閱讀理解NLP基準11種最優(公號回覆“谷歌BERT論文”下載彩標PDF論文) 原創: 秦隴紀 資料簡化DataSimp 今天 資料簡化DataSimp導讀:谷歌AI語言組論文《BERT:語言理解的深度雙向變換器預訓練》,介紹一種新的語言表
MaskRCNN-ICCV2017 論文解讀
文章: MaskRCNN 作者: Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick 備註: FAIR, ICCV best paper 核心亮點 1) 提出了一個簡單,靈活,通用的例項分割模型框架 MaskRCNN
Optical Flow Guided Feature A Fast and Robust Motion Representation for Video Action Recognition論文解讀
Optical Flow Guided Feature A Fast and Robust Motion Representation for Video Action Recognition論文解讀 1. Abstract 2. 論文解讀 3
Playing Atari with Deep Reinforcement Learning論文解讀
1.Abstract We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using re
《2017-Dual Path Networks》論文解讀
解讀Dual Path Networks(DPN,原創) 動機 以前方法的不足 ResNet: 側重於特徵的再利用,但不善於發掘新的特徵; DenseNet: 側重於新特徵的發掘,但又會產生很多冗餘; 優點
論文解讀|【Densenet】密集連線的卷積網路(附Pytorch程式碼講解)
@[t oc] 1 簡單介紹 論文題目:Densely Connected Convolutional Networks 發表機構:康奈爾大學,清華大學,Facebook AI 發表時間:2018年1月 論文程式碼:https://github.com/Wang
MSCNN論文解讀-A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
多尺度深度卷積神經網路進行快速目標檢測: 兩階段目標檢測器,與faster-rcnn相似,分為an object proposal network and an accurate detection network. 文章主要解決的是目標大小不一致的問題,尤其是對小目標的檢測,通過多
discoGAN 論文解讀
一. Abstract task: discovering cross-domain relations(跨域關係) given unpaired data 使用發現的關係,作者成功提出從一個域到另一個域同時儲存關鍵屬性的網路傳輸方式,例如方向和臉部身份 二. Introduction di
論文解讀:記憶網路(Memory Network)
在瞭解vqa問題的論文時,發現有很多論文采用了記憶網路的思路,模擬推理過程,這篇文章主要總結關於記憶網路的三篇經典論文,目的是對記憶網路有個認識。分別是: MEMORY NETWORKS,End-To-End Memory Networks,Ask Me Anything: Dynami
論文解讀:Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for VQA
這是關於VQA問題的第五篇系列文章。本篇文章將介紹論文:主要思想;模型方法;主要貢獻。有興趣可以檢視原文:Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Ans
論文解讀:A Focused Dynamic Attention Model for Visual Question Answering
這是關於VQA問題的第四篇系列文章。本篇文章將介紹論文:主要思想;模型方法;主要貢獻。有興趣可以檢視原文:A Focused Dynamic Attention Model for Visual Question Answering。 1,主要思想: Focused Dynami
論文解讀:Stacked Attention Networks for Image Question Answering
這是關於VQA問題的第二篇系列文章,這篇文章在vqa領域是一篇比較有影響的文章。本篇文章將介紹論文:主要思想;模型方法;主要貢獻。有興趣可以檢視原文:Stacked Attention Networks for Image Question Answering。原論文中附有作者原始碼。
論文解讀:Ask Your Neurons: A Neural-based Approach to Answering Questions about Images
這是關於VQA問題的第三篇系列文章,這篇文章是一篇比較經典的文章,所以跟大家分享。本篇文章將介紹論文:主要思想;模型方法;主要貢獻。有興趣可以檢視原文:Ask Your Neurons: A Neural-based Approach to Answering Questions abo