
為什麼一個Http Header中的空格會被駭客利用 - HTTP request smuggling
導讀:本文通過一個Netty的一個issue來學習什麼是 "http request smuggling"、它產生的原因與解決方法,從而對http協議有進一步瞭解。
前言
前陣子在Netty的issue裡有人提了一個問題 http request smuggling, cause by obfuscating TE header ,描述了一個Netty的http解碼器一直以來都存在的問題:沒有正確地分割http header field名稱,可能導致被駭客利用。
引起問題的那段code很簡單,它的作用是從一個字串中分割出header field-name:
for (nameEnd = nameStart; nameEnd < length; nameEnd ++) {char ch = sb.charAt(nameEnd);
if (ch == ':' || Character.isWhitespace(ch)) {
break;
}
}
這段有什麼問題呢?它不應該把空格也當成header field-name的終止符,這會導致Transfer-Encoding[空格]: chunked
Transfer-Encoding 而不是Transfer-Encoding[空格] 。
乍一看可能讓很多人迷惑,一個Header Field名稱識別錯了為什麼會被駭客攻擊呢?大不了就缺了一個Header嘛。但真實世界,卻沒這麼簡單。這事,還得從現代的web服務架構說起。
(注:本文所有的"Http協議"都指1.1版本以後)
起因
鏈式處理
通常現代的Web伺服器並非單體存在的,而是由一系列的程式組成(比如nginx -> tomcat),為了實現均衡負載、請求路由等等功能。這些系統都會解析Http協議來進行一系列處理,處理完後,會將對應的請求通過http協議分發鏈路中的下一個。
假設現在一個使用者的請求到達邏輯伺服器B的過程為: 使用者 -> A -> B 。通常會有許多個使用者連線到A,而為了減少連線建立的消耗,A到B的連線數實際上會少很多。如何用少量的連線服務於多個使用者呢?我們知道HTTP/1.1協議通常是一個請求發出一個響應回來,然後再發起下一個請求這樣序列處理的。實際上HTTP/1.1還有一個較少出現在公眾視野裡的HTTP pipelining的技術,可以批量傳送請求,然後再批量獲得響應(但是由於某些原因現代瀏覽器基本上沒有啟用這個功能)。A -> B 之間常用這種技術來獲得性能的提升。
所以多個使用者的請求往往會匯合在同一個連線中。
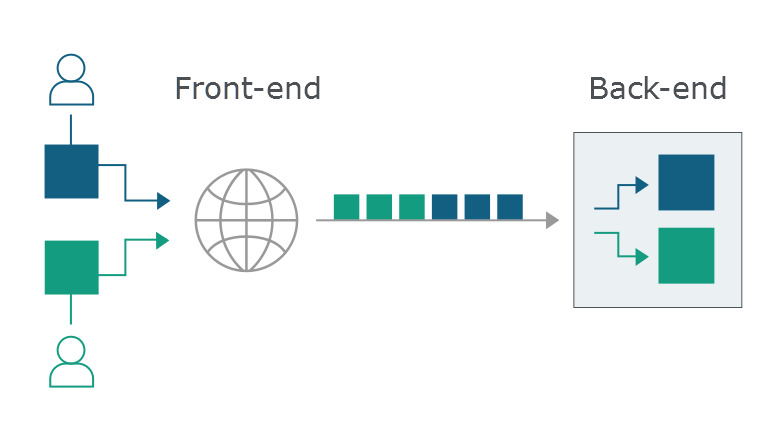
大家的請求都合在一起了,如何區分請求與請求之間的邊界呢?接下來我們再來看看Http協議中的Transfer-Encoding: chunked和Content-Length。
Transfer-Encoding: chunked和Content-Length
Http協議通過Transfer-Encoding: chunked(以下簡稱TE)或Content-Length(以下簡稱CL)來確定entity的長度。
TE表示將資料以一系列分塊的形式進行傳送,在每一個分塊的開頭需要添加當前分塊的長度,以十六進位制的形式表示,後面緊跟著 '\r\n' ,之後是分塊本身,後面也是'\r\n' 。終止塊是一個常規的分塊,不同之處在於其長度為0。
而CL通過直接指定entity的位元組長度來完成同樣的使命。
那麼當它們兩個同時出現在Http Header裡時會發生什麼呢?實際上Http協議規範有明確定義,當這兩種確定長度的Header都存在時,應該優先使用TE,然後忽略CL。
看到這,結合上述那段不規範的header field-name解析程式碼,或許你想到了一些東西?假如一個包含了TE和CL的Http請求被處理了兩次會發生什麼?接下來,我們來看看具體的情況。
傳送攻擊請求
此時我們依舊使用 使用者 -> A -> B 的例子。 這裡我們假設B是存在問題的Netty,而A是一個正常的只識別CL的程式。一個包含了Transfer-Encoding[空格]: chunked 和Content-Length的Http請求來了
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 8
Transfer-Encoding[空格]: chunked
0
FOR
然後又來了一個正常的使用者請求
GET /my-info HTTP/1.1
Host: vulnerable-website.com
Content-Length: 0
A
A識別到了CL為8,並將這兩個請求合併到一個連線中一起傳給B
B
B識別到了Transfer-Encoding[空格],按照規則忽略了CL,此時B會怎麼分割這兩個請求呢:
請求1
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 8
Transfer-Encoding[空格]: chunked
0
請求2
FORGET /my-info HTTP/1.1
Host: vulnerable-website.com
Content-Length: 0
這就糟糕了:服務端報了一個錯,正常使用者獲得了一個400的響應。
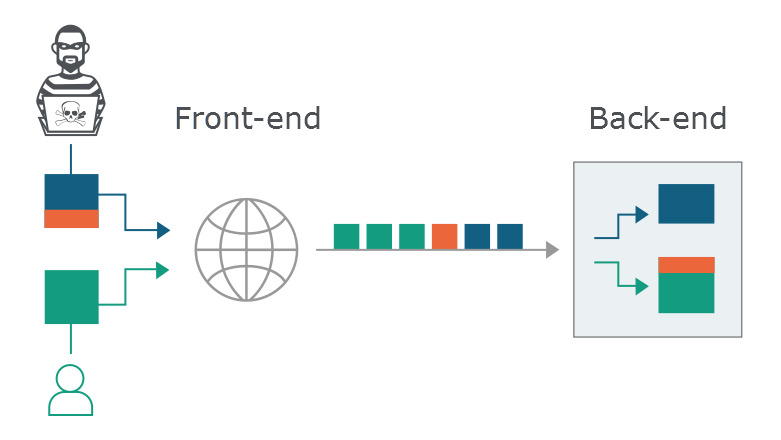
(任何上下游識別請求的分界不一致的情況都會出現這樣的問題)
如何避免這樣的漏洞
- 避免重用連線,當然不可取。
- 使用HTTP/2作為系統間協議,此協議避免了http header的混淆。
- 使用同一種伺服器作為上下游伺服器。
- 大家都按規範來,不出BUG。
其中我們展開了解一下為什麼HTTP/2可以避免這種情況
HTTP/2不會有含糊不清的Header
HTTP/2是一個二進位制協議,致力於避免不必要的網路流量以及提高TCP連線的利用率等等。
它對於常用的Header使用了一個靜態字典來壓縮。比如Content-Length使用28來表示;`
Transfer-Encoding`使用57來表示。這樣一來,各種實現就不會有歧義了。更多的定義詳見HTTP/2關於Header靜態表的定義
文獻
- Hypertext Transfer Protocol (HTTP/1.1)關於Http Header Field的解析定義
- Transfer-Encoding - HTTP | MDN
- Content-Length - HTTP | MDN
- What is HTTP request smuggling? Tutorial & Examples
- HTTP/1.x 的連線管理 - HTTP | MDN
- HTTP/2關於Header靜態表的定義