
騰訊新聞搶金達人活動node同構直出渲染方案的總結
我們的業務在展開的過程中,前端渲染的模式主要經歷了三個階段:服務端渲染、前端渲染和目前的同構直出渲染方案。
服務端渲染的主要特點是前後端沒有分離,前端寫完頁面樣式和結構後,再將頁面交給後端套資料,最後再一起聯調。同時前端的釋出也依賴於後端的同學;但是優點也很明顯:頁面渲染速度快,同時 SEO 效果好。
為了解決前後端沒有分離的問題,後來就出現了前端渲染的這種模式,路由選擇和頁面渲染,全部放在前端進行。前後端通過介面進行互動,各端可以更加專注自己的業務,釋出時也是獨立釋出。但缺點是頁面渲染慢,嚴重依賴 js 檔案的載入速度,當 js 檔案載入失敗或者 CDN 出現波動時,頁面會直接掛掉。我們之前大部分的業務都是前端渲染的模式,有部分的使用者反饋頁面 loading 時間長,頁面渲染速度慢,尤其是在老舊的 Android 機型上這個問題更加地明顯。
node同構直出渲染方案可以避免服務端渲染和前端渲染存在的缺點,同時前後端都是用 js 寫的,能夠實現資料、元件、工具方法等能實現前後端的共享。
1. 效果
首先來看下統計資料的結果,可以看到從前端渲染模式切換到 node 同構直出渲染模式後,整頁的載入耗時從 3500ms 降低到了 2100 毫秒左右,整體的載入速度提高了將近 40%。

但這個資料也不是最終的資料,因為當時要趕著上線的時間,很多東西還沒來及優化,在後續的優化完成後,可以看到整體的的載入耗時又下降到了 1600ms 左右,再次下降了 500ms 左右。

從 3500ms 降低到 1600ms,整整加快了 1900ms 的載入速度,整體提升了 54%。優化的手段在稍後也會講解到。
2. 遇到的挑戰
在進行同構直出渲染方案,也對目前存在的技術,並結合自身的技術棧,對整體的架構進行梳理。
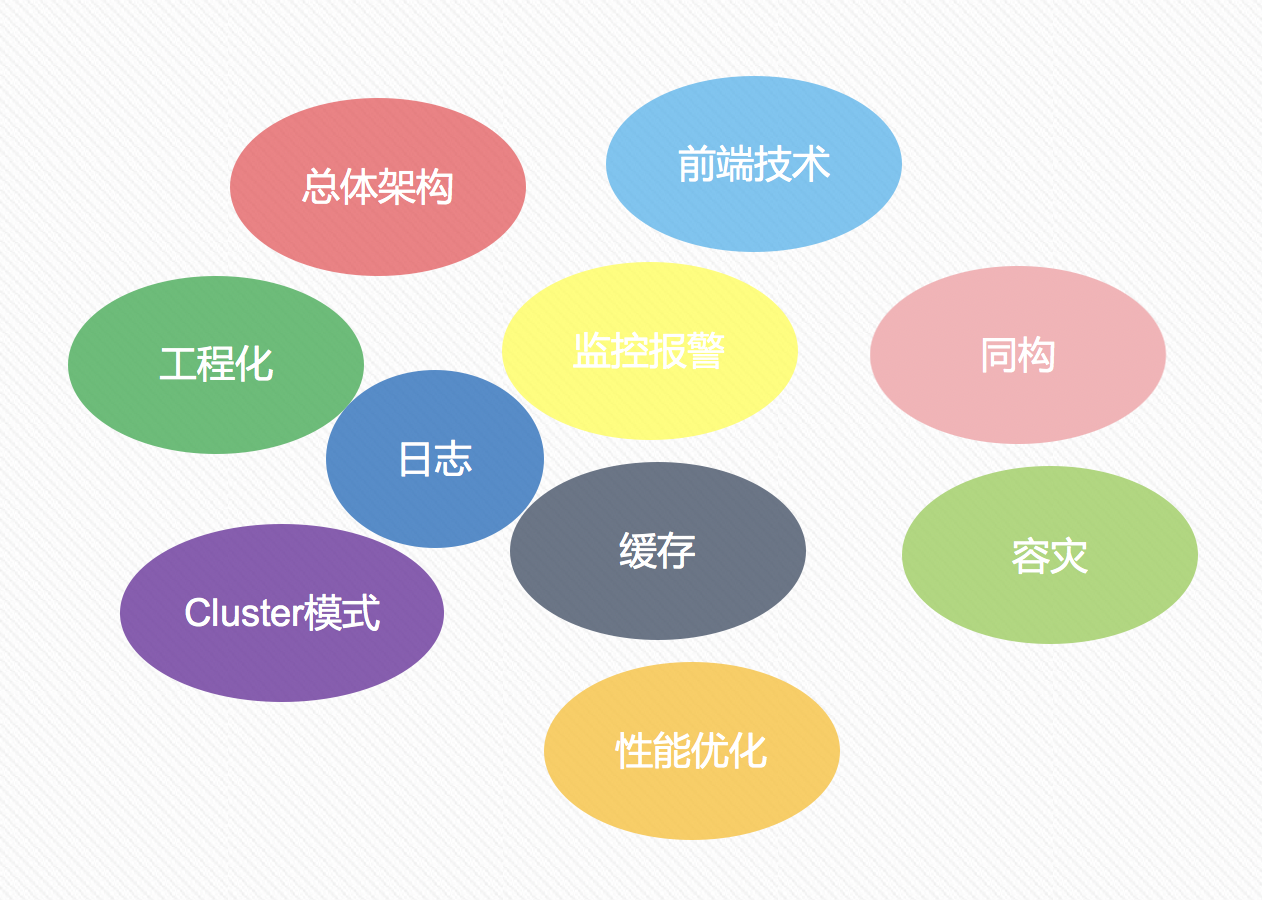
梳理出接下來存在的重點和難點:
- 如何保持資料、路由、狀態、基礎元件的同構共用?如何區分客戶端和服務端?
- 如何進行資料請求,是否存在跨域的請求?在服務端、瀏覽器端和新聞客戶端內都是怎樣進行資料請求的,各自都有什麼特點,是否可以封裝一下?
- 工程化:如何區分開發環境、測試環境、預釋出環境和正式環境?單元測試如何執行?是否可以自動化釋出?
- 專案的頁面有什麼特點,頁面、介面資料、元件等是否可以快取?如何進行快取?是否存在個性化的資料?
- 如何記錄日誌,上報專案的效能資料,如請求量、前端頁面載入的整頁耗時、錯誤率、後端耗時等資料?如何在 node 服務出現異常時(如負載過高、記憶體洩露)進行告警?
- 如何進行容災處理,當出現異常情況時如何降級,並告知開發者快速的修復!
- node 是單執行緒執行,如何充分利用多核?
- 效能優化:預載入、圖片懶載入、使用 service worker、延遲載入 js、IntersectionObserver 延遲載入元件等
針對我們專案初期的規劃中,可能出現的問題一一進行解決,最終我們的專案也能夠實現的差不離了,某些比較大的模組我可能需要單獨拿出來寫一篇文章進行總結。
3. 功能實現
3.1 前後端的同構
使用 node 服務端同構指出渲染方案,最主要的是資料等結構能夠實現前後端的同構共享。
同構方面主要是實現:資料同構、狀態同構、元件同構和路由同構等。
資料同構:對於相同的虛擬 DOM 元素,在服務端使用 renderToNodeStream 把渲染結果以“流“的形式塞給 response 物件,這樣就不用等到 html 都渲染出來才能給瀏覽器端返回結果,“流”的作用就是有多少內容給多少內容,能夠進一步改進了“第一次有意義的渲染時間”。同時,在瀏覽器端,使用 hydrate 把虛擬 dom 渲染為真實的 DOM 元素。若瀏覽器端對比服務端渲染的元件數,若發生不一致的情況時,不再直接丟掉全部的內容,而是進行區域性的渲染。因此在使用服務端的渲染過程中,要保證前後端元件資料的一致性。這裡將服務端請求的資料,插入到 js 的全域性變數中,隨著 html 一起渲染到瀏覽器端(脫水);這是在瀏覽器端,就可以拿到脫水的資料來初始化元件,新增互動等等(注水)。
狀態同構方面:我們這裡使用mobx為每個使用者建立一個全域性的狀態管理,這樣資料可以進行統一的管理,而不用元件之間衣岑層傳遞。
元件同構:編寫的基礎元件或其他元件可以在服務端和客戶端都能使用,同時使用typeof window==='undefined'或process.browser來判斷當前是客戶端還是服務端,以此來遮蔽某端不支援的操作。
路由統一:客戶端使用BrowserRouter,服務端使用StaticRouter。
在同構的過程中,最開始時還沒太理解這個概念,在編碼階段就遇到了這樣的問題。例如我們有個小輪播,這個輪播是將陣列打亂隨機展示的,我將從服務端請求到的資料打亂後渲染到頁面上,結果除錯視窗中輸出一條錯誤資訊(我們這裡用個樣例資料來代替):
const list = ['勳章', '答題卡', '達人榜', '紅包', '公告'];在render()中隨機輸出:
{
list.sort(() => (Math.random() < 0.5 ? 1 : -1)).map(item => (
<p key={item}>{item}</p>
));
}結果在控制檯輸出了警告資訊,同時最終展示出來的資訊並不是打亂排序:
Warning: Text content did not match. Server: "紅包" Client: "答題卡"
輸出的警告資訊是因為客戶端發現當前與服務端的資料不一致後,客戶端重新進行了渲染,並給出了警告資訊。我們在渲染的時候才把陣列打亂順序,服務端是按照打亂順序後的資料渲染的,但是傳遞給客戶端的資料還是原始資料,造成了前後端資料不一致的問題。
如果真的想要隨機排序,可以在獲取服務端的資料後,直接先排好序,然後再渲染,這樣服務端和客戶端的資料就會保持一致。在 nextjs 中就是getInitialProps中操作。
3.2 如何進行資料請求
基於我們專案主要是在新聞客戶端內執行的特點,我們要考慮多種資料請求的方式:服務端、瀏覽器端、新聞客戶端內,是否跨域等特點,然後形成一個完整的統一的多終端資料請求體系。
- 服務端:使用 http 模組或者 axios 等第三方元件發起 http 請求,並透傳 ua 和 cookie 給介面;
- 新聞客戶端:使用新聞客戶端提供的 jsapi 發起介面請求,注意 iOS 和 Android 不同 APP 中請求方式的差異;
- 瀏覽器端跨域請求:建立一個 script 標籤發起介面請求,並設定超時時間;
- 瀏覽器端同域請求:優先使用
fetch,然後使用XMLHttpRequest發起介面請求。
這裡將多終端的資料進行封裝,對外提供統一而穩定的呼叫方式,業務層無需關心當前的請求從哪個終端發起。
// 發起介面請求
// @params {string} url 請求的地址
// @params {object} opts 請求的引數
const request = (url: string, opts: any): Promise<any> => {};同時,我們也在請求介面的方法中新增上監控處理,如監控介面的請求量、耗時、失敗率等資訊,做到詳細的資訊記錄,快速地進行定位和相應。
3.3 工程化
工程化是一個很大的概念,我們這裡僅僅從幾個小點上進行說明。
我們的專案目前都是部署在 skte 上,通過設定不同的環境變數來區分當前是測試環境、預釋出環境和正式環境。
同時,因為我們的業務主要是在新聞客戶端內訪問的特點,很多的單元測試無法完全覆蓋,只能進行部分的單元測試,確保基礎功能的正常運作。
現在接入了完全自動化的 CI(持續整合)/CD(持續部署),基於 git 分支的方式進行釋出構建,當開發者完成編碼工作後,推送到 test/pre/master 分支後,進行單元測試的校驗,通過後就會自動整合和部署。
3.4 快取
快取的優點自不必多說:
- 加快了瀏覽器載入網頁的速度;
- 減少了冗餘的資料傳輸,節省網路流量和頻寬;
- 減少伺服器的負擔,大大提高了網站的效能。
但同時增加快取,整體專案的複雜度也會增加,我們需要評估下專案是否適合快取、適用於哪種快取機制、快取失效時如何處理。
快取的機制主要有:
- 瀏覽器強快取或 nginx 快取:快取固定的時長,例如 30ms 的時間,在這 30ms 的時間內讀取快取中的資料,這種快取的缺點是資料無法及時更新,必須等到快取時間到後才能更新;
- 狀態快取或全域性快取:這適用於路由之間多次切換或者快取使用者個性化的資料,只在單次訪問的過程中有效;
- 記憶體快取:將快取儲存於記憶體中,無需額外的 I/O 開銷,讀寫速度快;但缺點是資料容易失效,一旦程式出現異常時快取直接丟失,同時記憶體快取無法達到程序之間的共享。這裡當我們使用瀏覽器的協商快取時,即根據生成的內容產生
ETag值,若 etag 值相同則使用快取,否則請求伺服器的資料,這就會造成不同程序之間快取的資料可能不一樣,etag 多次失效的問題。記憶體快取尤其要注意記憶體洩露的問題 - 分散式快取:使用獨立的第三方快取,如 Redis 或 Memcached,好處時多個程序之間可以共享,同時減少專案本身對快取淘汰演算法的處理
不同的專案或者不同的頁面採用不同的快取策略。
- 不常更新資料的頁面如首頁、排行榜頁面等,可以使用瀏覽器強快取或者介面快取;
- 使用者頭像、暱稱、個性化等資料使用狀態管理;
- 介面資料可以使用第三方快取
在對介面的資料快取時,尤其要注意的是介面正常返回時,才快取資料,否則交給業務層處理。
同時,在使用快取的過程中,還注意快取失效的問題。
| 快取失效 | 含義 | 解決方案 |
|---|---|---|
| 快取雪崩 | 所有的快取同一時間失效 | 設定隨機的快取時間 |
| 快取穿透 | 快取中不存在,資料庫中也不存在 | 快取中設定一個空值,且快取時間較短 |
| 隨機 key 請求 | 惡意地使用隨機 key 請求,導致無法命中快取 | 布隆過濾器,未在過濾器中的資料直接攔截 |
| 為快取的 key | 快取中沒有但資料庫中有 | 請求成功後,快取資料,並將資料返回 |
3.5 日誌記錄
詳細的日誌記錄能夠讓我們很方便地瞭解專案效果和排查問題。前後端的表現形式不一樣,我們也區分前後端進行日誌的上報。
前端主要上報頁面的效能資訊,服務端主要上報程式的異常、CPU 和記憶體的使用狀況等。
在前端方面,我們可以使用window.performance經過簡單的計算得到一些網頁的效能資料:
- 首次載入耗時: domLoading - fetchStart;
- 整頁耗時: loadEventEnd - fetchStart;
- 錯誤率: 錯誤日誌量/請求量;
- DNS 耗時: domainLookupEnd - domainLookupStart;
- TCP 耗時: connectEnd - connectStart;
- 後端耗時: responseStart - requestStart;
- html 耗時: responseEnd - responseStart;
- DOM 耗時: domContentLoadedEventEnd - responseEnd;
同時我們也需要捕獲前端程式碼中的一些報錯:
- 全域性捕獲,error:
window.addEventListener(
'error',
(message, filename, lineNo, colNo, stackError) => {
console.log(message); // 錯誤資訊的描述
console.log(filename); // 錯誤所在的檔案
console.log(lineNo); // 錯誤所在的行號
console.log(colNo); // 錯誤所在的列號
console.log(stackError); // 錯誤的堆疊資訊
}
);- 全域性捕獲,unhandledrejection:
當 Promise 被 reject 且沒有 reject 處理器的時候,會觸發 unhandledrejection 事件;這可能發生在 window 下,但也可能發生在 Worker 中。 這對於除錯回退錯誤處理非常有用。
window.addEventListener('unhandledrejection', event => {
console.log(event);
});- 介面非同步請求時
這裡可以對fetch和XMLHttpRequest進行重新的封裝,既不影響正常的業務邏輯,也可以進行錯誤上報。
XMLHttpRequest 的封裝:
const xmlhttp = window.XMLHttpRequest;
const _oldSend = xmlhttp.prototype.send;
xmlhttp.prototype.send = function() {
if (this['addEventListener']) {
this['addEventListener']('error', _handleEvent);
this['addEventListener']('load', _handleEvent);
this['addEventListener']('abort', _handleEvent);
} else {
var _oldStateChange = this['onreadystatechange'];
this['onreadystatechange'] = function(event) {
if (this.readyState === 4) {
_handleEvent(event);
}
_oldStateChange && _oldStateChange.apply(this, arguments);
};
}
return _oldSend.apply(this, arguments);
};fetch 的封裝:
const oldFetch = window.fetch;
window.fetch = function() {
return _oldFetch
.apply(this, arguments)
.then(res => {
if (!res.ok) {
// True if status is HTTP 2xx
// 上報錯誤
}
return res;
})
.catch(error => {
// 上報錯誤
throw error;
});
};服務端的日誌根據嚴重程度,主要可以分為以下的幾個類別:
- error: 錯誤,未預料到的問題;
- warning: 警告,出現了在預期內的異常,但是專案可以正常執行,整體可控;
- info: 常規,正常的資訊記錄;
- silly: 不明原因造成的;
我們針對可能出現的異常程度進行不同類別(level)的上報,這裡我們採用了兩種記錄策略,分別使用網路日誌boss和本地日誌winston分別進行記錄。boss 日誌裡記錄較為簡單的資訊,方便通過瀏覽器進行快速地排查;winston 記錄詳細的本地日誌,當通過簡單的日誌資訊無法定位時,則使用更為詳細的本地日誌進行排查。
使用winston進行服務端日誌的上報,按照日期進行分類,上報的主要資訊有:當前時間、伺服器、程序 ID、訊息、堆疊追蹤等:
// https://github.com/winstonjs/winston
logger = createLogger({
level: 'info',
format: combine(label({ label: 'right meow!' }), timestamp(), myFormat), // winston.format.json(),
defaultMeta: { service: 'user-service' },
transports: [
new transports.File({
filename: `/data/log/question/answer.error.${date.getFullYear()}-${date.getMonth() +
1}-${date.getDate()}.log`,
level: 'error'
})
]
});同時 nodejs 服務本身的監控機制也充分利用上,例如包括 http 狀態碼,記憶體佔用(process.memoryUsage)等。
在日誌的統計過程中,加入告警機制,當告警數量或者數值超過一定的範圍,則向開發者的微信和郵箱發出告警資訊和裝置。例如其中的一條告警規則是:當頁面的載入時間小於 10ms 或者超過 6000ms 則發出告警資訊,小於 10ms 時說明頁面掛掉了,大於 6000ms 說明伺服器可能出現異常,導致資源載入時間過長。
同時也要及時地關注使用者反饋平臺,若產生了一個使用者的反饋,必然是有更多的使用者存在這樣的問題。
3.6 容災處理
日誌記錄和告警等都是事故發生後才產生的行為,我們應當如何保證在我們看到日誌資訊並修復問題之前的這段時間裡,服務至少能夠還是是正常執行的,而不是白屏或者 5xx 等資訊。這裡我們要做的就是線上服務的容災處理。
| 可能存在的問題 | 容災措施 |
|---|---|
| 後端介面異常 | 使用預設資料,並及時告知介面方 |
| 瞬時流量高、CPU 負載率過高 | 自動擴容,並告警 |
| node 服務異常,如 4xx,5xx 等 | nginx 自動將服務轉向靜態頁面,並告警轉發的次數 |
| 靜態資源導致的樣式異常 | 將首屏或者首頁的樣式嵌入到頁面中 |
容災處理與日誌資訊的記錄,保障我們專案能夠正常地在線上執行。
3.7 cluster 模組
nodejs 作為一種單執行緒、單程序執行的程式,如果只是簡單的使用的話(node app.js),存在著如下一些問題:
- 無法充分利用多核 cpu 機器的效能,
- 服務不穩定,一個未處理的異常都會導致整個程式退出
- 沒有成熟的日誌管理方案、
- 沒有服務/程序監控機制
所幸,nodejs 為我們提供了cluster模組,什麼是cluster:
簡單的說,
- 在伺服器上同時啟動多個程序。
- 每個程序裡都跑的是同一份原始碼(好比把以前一個程序的工作分給多個程序去做)。
- 更神奇的是,這些程序可以同時監聽一個埠(Cluster 實現原理)。
其中:
- 負責啟動其他程序的叫做 Master 程序,他好比是個『包工頭』,不做具體的工作,只負責啟動其他程序。
- 其他被啟動的叫 Worker 程序,顧名思義就是幹活的『工人』。它們接收請求,對外提供服務。
- Worker 程序的數量一般根據伺服器的 CPU 核數來定,這樣就可以完美利用多核資源。
cluster 模組可以建立共享伺服器埠的子程序。這裡舉一個著名的官方案例:
const cluster = require('cluster');
const http = require('http');
const os = require('os');
if (cluster.isMaster) {
// 當前為主程序
console.log(`主程序 ${process.pid} 正在執行`);
// 啟動子程序
for (let i = 0, len = os.cpus().length; i < len; i++) {
cluster.fork();
}
cluster.on('exit', worker => {
console.log(`子程序 ${worker.process.pid} 已退出`);
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`子程序 ${process.pid} 已啟動`);
}當有程序退出時,則會觸發exit事件,例如我們 kill 掉 69030 的程序時:
> kill -9 69030
子程序 69030 已退出我們嘗試 kill 掉某個程序,發現子程序是不會自動重新建立的,這裡我可以修改下exit事件,當觸發這個事件後重新建立一個子程序:
cluster.on('exit', worker => {
console.log(`子程序 ${worker.process.pid} 已退出`);
// log日誌記錄
cluster.fork();
});主程序與子程序之間的通訊:每個程序之間是相互獨立的,可是每個程序都可以與主程序進行通訊。這樣就能把很多需要每個子程序都需要處理的問題,放到主程序裡處理,例如日誌記錄、快取等。我們在 3.4 快取小節中也有講“記憶體快取無法達到程序之間的共享”,可是我們可以把快取提高到主程序中進行快取。
if (cluster.isMaster) {
Object.values(cluster.workers).forEach(worker => {
// 向所有的程序都發布一條訊息
worker.send({ timestamp: Date.now() });
// 接收當前worker傳送的訊息
worker.on('message', msg => {
console.log(
`主程序接收到 ${worker.process.pid} 的訊息:` +
JSON.stringify(msg)
);
});
});
} else {
process.on('message', msg => {
console.log(`子程序 ${process.pid} 獲取資訊:${JSON.stringify(msg)}`);
process.send({
timestamp: msg.timestamp,
random: Math.random()
});
});
}不過若線上生產環境使用的話,我們需要給這套程式碼新增很多的邏輯。這裡可以使用pm2來維護我們的 node 專案,同時 pm2 也能啟用 cluster 模式。
pm2 的官網是http://pm2.keymetrics.io,github 是https://github.com/Unitech/pm2。主要特點有:
- 原生的叢集化支援(使用 Node cluster 叢集模組)
- 記錄應用重啟的次數和時間
- 後臺 daemon 模式執行
- 0 秒停機過載,非常適合程序升級
- 停止不穩定的程序(避免無限迴圈)
- 控制檯監控
- 實時集中 log 處理
- 強健的 API,包含遠端控制和實時的介面 API ( Nodejs 模組,允許和 PM2 程序管理器互動 )
- 退出時自動殺死程序
- 內建支援開機啟動(支援眾多 linux 發行版和 macos)
nodejs 服務的工作都可以託管給 pm2 處理。
pm2 以當前最大的 CPU 數量啟動 cluster 模式:
pm2 start server.js -i max不過我們的專案使用配置檔案來啟動的,ecosystem.config.js:
module.exports = {
apps: [
{
name: 'question',
script: 'server.js',
instances: 'max',
exec_mode: 'cluster',
autorestart: true,
watch: false,
max_memory_restart: '1G',
env_test: {
NEXT_APP_ENV: 'testing'
},
env_pre: {
NEXT_APP_ENV: 'pre'
},
env: {
NEXT_APP_ENV: 'production'
}
}
]
};然後啟動即可:
pm2 start ecosystem.config.js關於使用 node 來編寫 cluster 模式,還是用 pm2 來啟動 cluster 模式,還是要看專案的需要。使用 node 編寫時,自己可以控制各個程序之間的通訊,讓每個程序做自己的事情;而 pm2 來啟動的話,在整體健壯性上更好一些。
3.8 效能優化
我們應當首先保證首頁和首屏的載入,一個是首屏需要的樣式直接嵌入到頁面中載入,再一個是首屏和次屏的資料分開載入。我們在首頁的資料主要是瀑布流的方式載入,而瀑布流是需要 js 計算的,因此這裡我們先載入幾條資料,保證首屏是有資料的,然後接下來的資料使用 js 計算應當放在哪個位置。
再一個是使用 service worker 來本地快取 css 和 js 資源,更具體的使用,可以訪問service worker 在新聞紅包活動中的應用。
這裡我們使用 IntersectionObserver 封裝了通用的元件懶載入方案,因為在使用 scroll 事件中,我們可能還需要手動節流和防抖動,同時,因為圖片載入的快慢,導致需要多次獲取元素的 offsetTop 值。而 IntersectionObserver 就能完美地避免這些問題,同時,我們也能看到,這一屬性在高版本瀏覽器中也得到了支援,在低版本瀏覽器中,我可以使用 polyfill 的方式進行相容處理處理;
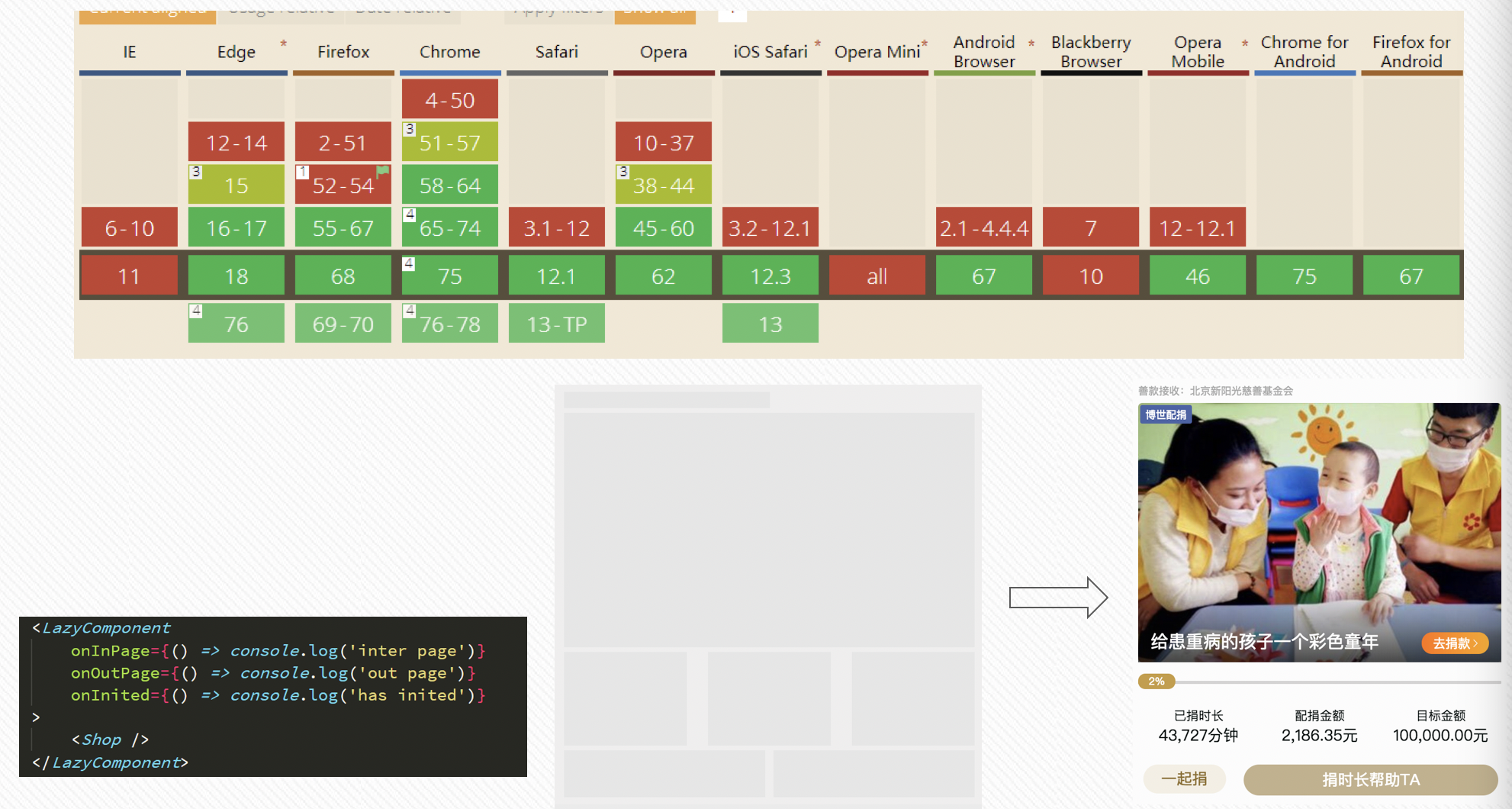
我將這個功能封裝為一個元件,對外提供幾個監聽方法,將需要懶載入的元件或者資源作為子元件,進行包裹,同時,我們這裡也建議建議使用者,使用預設的骨架屏撐起元素未渲染時的頁面。因為在直接使用懶載入渲染時,假如不使用骨架屏的話,使用者是先看到白屏,然後突然渲染內容,頁面給使用者一種強烈抖動的感覺。真實元件在最後真正展示出來時,需要一定的時間和空間,時間是從資源載入到渲染完畢需要時間;而空間指的是頁面佈局中需要給真實元件留出一定的問題,一個是為了避免頁面,再一個使用骨架屏後:
- 提升使用者的感知體驗
- 保證切換的一致性
- 提供可見性觀察的目標物件,為執行懶載入的元件保證可見性的區域
這裡實現的通用懶載入元件,對外提供了幾個回撥方法:onInPage, onOutPage, onInited 等。
這個通用的元件懶載入方案可以使用在如下的場景下:
- 懶載入的粒度可大可小,大到 1 個元件或者幾個元件,小到一個圖片即可;
- 頁面模組曝光率的資料上報,這樣可以計算模組從曝光到參與的一個漏斗資料;
- 長列表中的無限滾動:我們可以監聽頁面底部的一個透明元素,當這個透明元素即將可見時,載入並渲染下一頁的資料。
當然,長列表無限滾動的優先,不僅限於使用可見性代替滾動事件,也還有其他的優化手段。
4. 總結
雖然囉裡囉嗦了一大堆,但也這是我們同構直出渲染方案的開始,我們還有很長的路要走。應用型技術的難點不是在克服技術問題,而是在於能夠不斷的結合自身的產品體驗,發現其中存在的體驗問題,不斷使用更好的技術方案去優化使用者的體驗,為整個產品發展添磚加瓦。

蚊子的前端部落格連結: https://www.xiabingbao.com 。
歡迎關注我的微信公眾號: wenzichel

相關推薦
騰訊新聞搶金達人活動node同構直出渲染方案的總結
我們的業務在展開的過程中,前端渲染的模式主要經歷了三個階段:服務端渲染、前端渲染和目前的同構直出渲染方案。 服務端渲染的主要特點是前後端沒有分離,前端寫完頁面樣式和結構後,再將頁面交給後端套資料,最後再一起聯調。同時前端的釋出也依賴於後端的同學;但是優點也很明顯:頁面渲染速度快,同時 SEO 效果好。 為了解
騰訊搶金達人專案中的前後端協作
在前後端的協作過程中,通常都是並行開發的狀態,那麼在後端介面還沒有開發完畢時,前端的業務邏輯工作就很難展開。因此也就有很多模擬介面資料的方式,這些方式各有個的優缺點: 直接在程式碼中模擬介面資料:侵入業務邏輯,在後期需要刪除這些模擬資料; fiddler 替換檔案:頁面介面比較多時,需要替換的檔案比較多;
騰訊YOO視訊達人招募入駐條件辦法yoo視訊達人入駐流程
1、基本要求:擁有一定創作能力,作品優質,時長在15秒-5分鐘 2、補貼標準:通過平臺官方稽核,按賬號評級定價,每條視訊最高可補貼30000元。比如YOO平臺評估你的賬號每條視訊1萬元一條,你發的視訊通過基本人工考核都能拿到這個補貼,平臺前期考核簡單好賺錢你懂的. 3、入駐請
騰訊新聞構建高效能的 react 同構直出方案
在騰訊新聞搶金達人活動 node 同構直出渲染方案的總結文章中我們整體瞭解了下同構直出渲染方案在我們專案中的使用。正如我在上篇文章結尾所說的: 應用型技術的難點不是在克服技術問題,而是在於能夠不斷的結合自身的產品體驗,發現其中存在的體驗問題,不斷使用更好的技術方案去優化使用者的體驗,為整個產品發展添磚加瓦。
阿里雲和騰訊雲優惠對比阿里雲騰訊雲伺服器便宜優惠活動都在這
阿里雲和騰訊雲是使用者購買雲伺服器、雲資料庫、雲安全等產品的首選雲端計算服務商,阿里雲和騰訊雲的效能以及優惠幅度經常被大家拿來比較,阿里騰訊雲網為大家彙總了阿里雲和騰訊雲的最新優惠活動大全: 本文長期更新阿里雲和騰訊雲優惠活動,感謝關注,更新日期:2018年10月20日
【騰訊開源】LivePool:基於Node.js的跨平臺Web抓包替換工具
LivePool 是一個基於 NodeJS,類似 Fiddler 能夠支援抓包和本地替換的 Web 開發除錯工具,是Tencent AlloyTeam 在開發實踐過程總結出的一套的便捷的工作流以及除錯方案。 背景 在 Windows 平臺上,Fiddler 作為一款非常便捷好用的 Web 除錯工具
騰訊第一次種黃瓜,又長又直,還拿了獎
作者 | 非主流 出品 | AI科技大本營 看這一籃水靈的黃瓜,賣相也好,為啥貼著騰訊的標籤?難道騰訊要開始賣瓜? 其實,騰訊不是賣瓜,而是親自種了一次瓜。 緣起:AI 溫室種黃瓜比賽
騰訊AI開放平臺:AI賦能產業的一站式解決方案
文| 雷宇 來源|智慧相對論(ID:aixdlun) 幾乎每一項新興技術在真正成熟之前,都有一段曲折的經歷。技術經過不斷迭代,其經營模式,方法論經過幾代的演進,技術產生的利益與潛力才會最終被市場接受。人工智慧的發展歷程可分為三個階段,伴隨著網際網路時代積累起來的海量資
adb 坑之第三方手機管家如騰訊統一360 刷機助手導致開發出現嚴重問題解決方案
adb devices能看到裝置 adb shell unknown host service 甚至有的電腦還提示adb.exe已停止工作我的刷機精靈就是這樣。 端口占用根本檢查不到 netstat -ano |findstr "5037" 這時候只能看看電腦上是否有可疑
我從騰訊那“偷了”3000萬QQ使用者資料,出了份很有趣的獨家報告!
感謝部落格園! 轉載請註明部落格園地址,及作者[email protected]。 這是我近期使用C#寫的一個QQ空間蜘蛛網爬蟲程式。程式斷斷續續的運行了兩週,目前總共爬了3000萬QQ資料,其中有300萬包含使用者(QQ號,暱稱,空間名稱,頭像,最新
騰訊雲首推私有雲存儲,意欲搶占更多用戶市場
企業 高性能 海量數據 主機 雲服務 當前 單點 海量 stack 騰訊雲首推私有雲存儲,意欲搶占更多用戶市場 8月23日,騰訊雲於2017騰訊“雲+未來”峰會北京站,面向全球用戶,重磅推出了智能雲存儲新品系列。其中,為給各行業領域提供更多能滿足其私有存儲需求的公有雲服務,
小米才上市,騰訊音樂坐不住了,赴美上市估值或達300億美元
觀察者 list pre process shadow 播放器 num 獲得 -a 7月8日晚間,騰訊發布公告稱,已向港交所提交有關其在線音樂娛樂業務通過經註冊的公開發售在美國的認可證券交易所獨立上市的方式擬進行分拆(“建議分拆”)的建議。《國際金融報》的報道中,援引了最近
《2017全球人工智能人才白皮書》發布丨解讀世界頂級AI牛人的秘密——騰訊研究院
分享圖片 inf 大學 blank 也會 全球 秘密 白皮書 spa 《2017全球人工智能人才白皮書》發布丨解讀世界頂級AI牛人的秘密——騰訊研究院:下載鏈接:http://www.tisi.org/c16 這個報告寫的很好,排版布局,表格,色調,內容都值得一看,比清華
【 騰訊敏捷轉型No.4 】為什麽敏捷團隊不要超過15人
領導 原創 規模 數據 scrum 評審 是否 php 開發 早期,騰訊公司的架構是比較簡單的。從上至下分別是:公司——商業單元(BU)——部門——組——員工,每個部門基本上就是負責一個大的產品,每個組都是按照專業進行分工和管理,例如:產品組、終端組、後臺組、設計組、運維組
騰訊雲拼團活動
騰訊雲拼團活動開始了,這次為騰訊雲雙十一拼團,價格非常便宜。騰訊雲拼團活動時間為2018.11.1--2018.11.30 總共一個月的時間。在這一個月之內,無論任何一天參與騰訊雲拼團,都能以最低的價格購買騰訊雲產品。 這次的騰訊雲雙十一拼團的產品有各種配置的騰訊雲伺服器,cdn流量包,騰訊雲高防
阿里雲、騰訊雲、百度雲、華為雲伺服器雙十一活動價格對比
一、阿里雲 今年阿里雲對於新使用者的優惠力度比較大,跟團買價格能低到1折,1核2G記憶體1年的價格才99元,還可以一次買3年,可以說是十分優惠了。 活動時間:2018年10月29日——11月8日,每個新使用者限購一款。 活動連結:https://m.aliyun.com/act/team1111/#/s
金九銀十鐵12,講述一個收到騰訊、美團等五家大廠意向offer的大神
網際網路提前批基本告一段落,大大小小的offer也拿了一些,秉著回報社會,堅持中國特色社會主義,挽救新一程式碼農的思想,整理了下各個公司的麵筋、考點,希望能激勵各位搬磚工,起到鼓足幹勁,力爭上游的作用O(∩_∩)O 閒聊 本人北京985渣碩一枚,是真的渣,舍友商湯、曠世,出國留學,學校中各類
每日新聞:英特爾釋出第九代處理器;騰訊與英國公司用AI改善帕金森病;華為申請電池專利;中興為印度提供5G技術;微軟投資Grab...
關注中國軟體網 最新鮮的企業級乾貨聚集地 今日熱點 英特爾釋出第九代酷睿處理器:8核16執行緒 10月9日訊息 今天凌晨,英特爾推出了第九代智慧英特爾酷睿桌面級處理器,共有三款,分別是i5-9600K、i7-9700K 和 i9-9900K,官方稱最高擁有8核心和16執
騰訊十年Java架構師分享,會了這個知識點的人都去BAT了
架構師是一個充滿挑戰的職業,知識面的寬窄往往決定著一個架構師的架構能力。閱讀大量的技術書籍能夠提升知識面,但我希望你不要僅限於軟體相關的書籍,可以經常泡技術論壇,一方面可以結交朋友,一方面可以增加自己的知識面,還可以加入一下技術部落格。當然如果你的身邊有一位這方面的大神大牛給你指導或者教你經驗,那麼
騰訊搶佔區塊鏈市場!金貓kinmall:熊市或將迎來新拐點?
據南方日報近日報道,區塊鏈作為當下最熱門的新技術,預測將產生數十萬億以上的市場空間。11月29日,深圳區塊鏈產業聯盟正式成立,深圳市騰訊計算機系統有限公司在聯盟第一次全體會員大會上被選為聯盟理事長單位,並由騰訊區塊鏈總經理蔡弋戈出任聯盟理事長一職。 騰訊從賣QQ秀開始,藉助改開紅利,經歷20年發展成為了