
寫了那麼久的Python,你應該學會使用yield關鍵字了
寫過一段時間程式碼的同學,應該對這一句話深有體會:程式的時間利用率和空間利用率往往是矛盾的,可以用時間換空間,可以用空間換時間,但很難同時提高一個程式的時間利用率和空間利用率。
但如果你嘗試使用生成器來重構你的程式碼,也許你會發現,在一定程度上,你可以既提高時間利用率,又提高空間利用率。
我們以一個數據清洗的簡單專案為例,來說明生成器如何讓你的程式碼執行起來更加高效。
在 Redis 中,有一個列表
datalist,裡面有很多的資料,這些資料可能是純阿拉伯數字,中文數字,字串"敏感資訊"。現在我們需要實現:從 Redis 中讀取所有的資料,把所有的字串敏感資訊全部丟掉,把所有中文數字全部轉換為阿拉伯數字,以{'num': 12345, 'date': '2019-10-30 18:12:14'}這樣的格式插入到 MongoDB 中。
示例資料如下:
41234213424
一九八八七二六三
8394520342
七二三六二九六六
敏感資訊
80913408120934
敏感資訊
敏感資訊
95352345345
三三七四六
999993232
234234234
三六八八七七
敏感資訊如下圖所示:

如果讓你來寫這個轉換程式,你可能會這樣寫:
import redis import datetime import pymongo client = redis.Redis() handler = pymongo.MongoClient().data_list.num CHINESE_NUM_DICT = { '一': '1', '二': '2', '三': '3', '四': '4', '五': '5', '六': '6', '七': '7', '八': '8', '九': '9' } def get_data(): datas = [] while True: data = client.lpop('datalist') if not data: break datas.append(data.decode()) return datas def remove_sensitive_data(datas): clear_data = [] for data in datas: if data == '敏感資訊': continue clear_data.append(data) return clear_data def tranfer_chinese_num(datas): number_list = [] for data in datas: try: num = int(data) except ValueError: num = ''.join(CHINESE_NUM_DICT[x] for x in data) number_list.append(num) return number_list def save_data(number_list): for number in number_list: data = {'num': number, 'date': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')} handler.insert_one(data) raw_data = get_data() safe_data = remove_sensitive_data(raw_data) number_list = tranfer_chinese_num(safe_data) save_data(number_list)
執行效果如下圖所示:
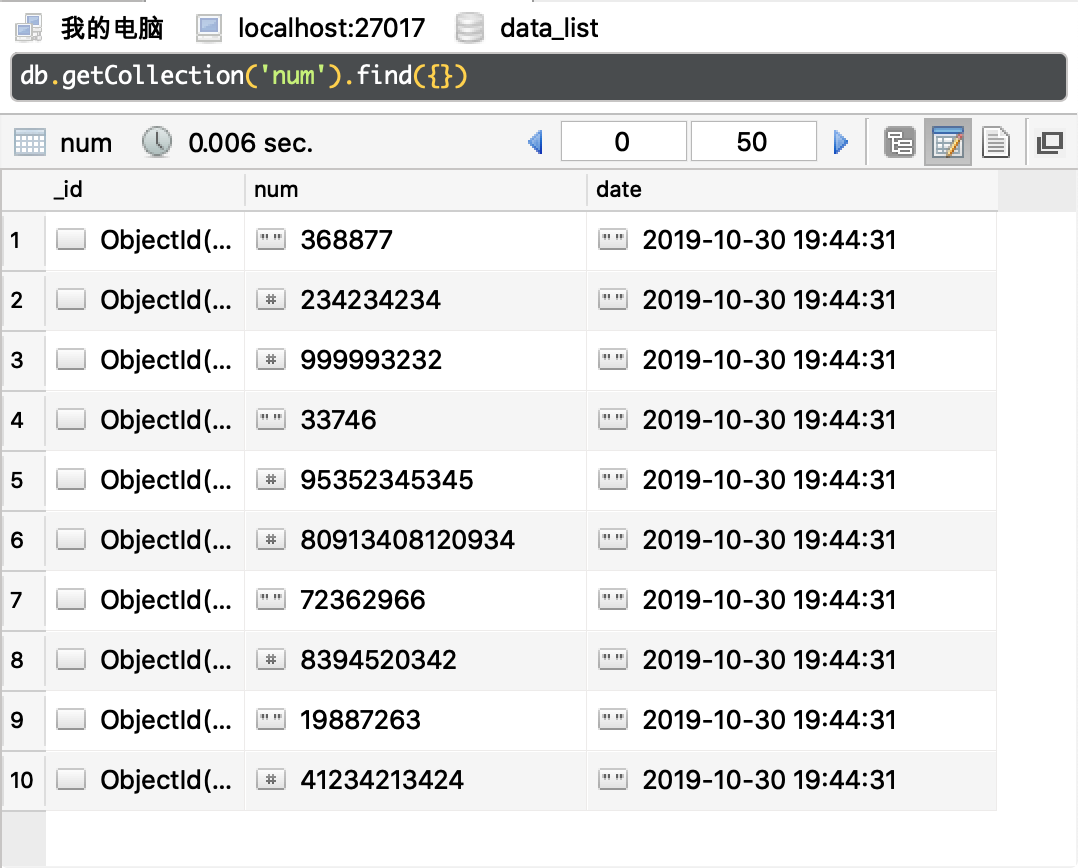
這段程式碼,看起來很 Pythonic,一個函式只做一件事,看起來也滿足編碼規範。最後執行結果也正確。能有什麼問題?
問題在於,這段程式碼,每個函式都會建立一個列表存放處理以後的資料。如果 Redis 中的資料多到超過了你當前電腦的記憶體怎麼辦?對同一批資料多次使用 for 迴圈,浪費了大量的時間,能不能只迴圈一次?
也許你會說,你可以把移除敏感資訊,中文數字轉阿拉伯數字的邏輯全部寫在get_data函式的 while迴圈中,這樣不就只迴圈一次了嗎?
可以是可以,但是這樣一來,get_data就做了不止一件事情,程式碼也顯得非常混亂。如果以後要增加一個新的資料處理邏輯:
轉換為數字以後,檢查所有奇數位的數字相加之和與偶數位數字相加之和是否相等,丟棄所有相等的數字。
那麼你就要修改get_data的程式碼。
在開發軟體的時候,我們應該面向擴充套件開放,面向修改封閉,所以不同的邏輯,確實應該分開,所以上面把每個處理邏輯分別寫成函式的寫法,在軟體工程上沒有問題。但是如何做到處理邏輯分開,又不需要對同一批資料進行多次 for 迴圈呢?
這個時候,就要依賴於我們的生成器了。
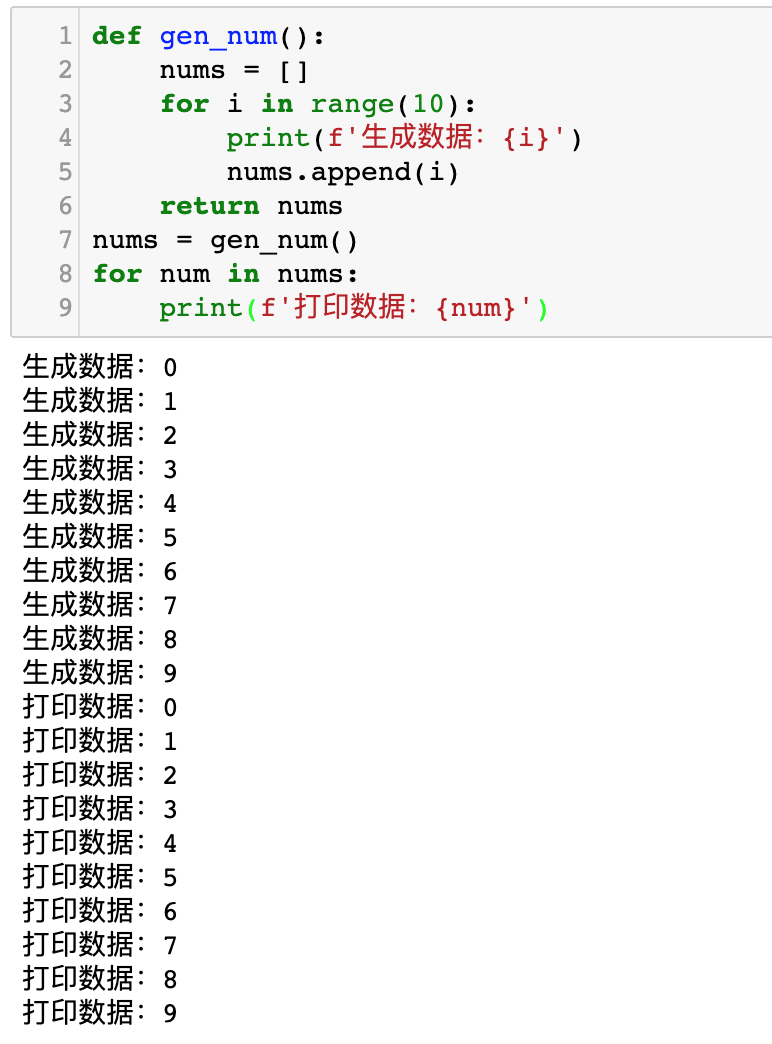
我們先來看看下面這一段程式碼的執行效果:
def gen_num():
nums = []
for i in range(10):
print(f'生成資料:{i}')
nums.append(i)
return nums
nums = gen_num()
for num in nums:
print(f'列印資料:{num}')執行效果如下圖所示:
現在,我們對程式碼做一下修改:
def gen_num():
for i in range(10):
print(f'生成資料:{i}')
yield i
nums = gen_num()
for num in nums:
print(f'列印資料:{num}')其執行效果如下圖所示:

大家對比上面兩張插圖。前一張插圖,先生成10個數據,然後再列印10個數據。後一張圖,生成一個數據,列印一個數據,再生成一個數據,再列印一個數據……
如果以程式碼的行號來表示執行執行邏輯,那麼程式碼是按照這個流程執行的:
1->5->6->2->3->4->6->7->6->2->3->4->6->7->6->2->3->4->6->7....大家可以把這段程式碼寫在 PyCharm 中,然後使用單步除錯來檢視它每一步執行的是哪一行程式碼。
程式執行到yield就會把它後面的數字丟擲到外面給 for 迴圈, 然後進入外面 for 迴圈的迴圈體,外面的 for 迴圈執行完成後,又會進入gen_num函式裡面的 yield i後面的一行,開啟下一次 for 迴圈,繼續生成新的數字……
整個過程中,不需要額外建立一個列表來儲存中間的資料,從而達到節約記憶體空間的目的。而整個過程中,雖然程式碼寫了兩個 for 迴圈,但是如果你使用單步除錯,你就會發現實際上真正的迴圈只有for i in range(10)。而外面的for num in nums僅僅是實現了函式內外的切換,並沒有新增迴圈。
回到最開始的問題,我們如何使用生成器來修改程式碼呢?實際上你幾乎只需要把return 列表改成yield 每一個元素即可:
import redis
import datetime
import pymongo
client = redis.Redis()
handler = pymongo.MongoClient().data_list.num_yield
CHINESE_NUM_DICT = {
'一': '1',
'二': '2',
'三': '3',
'四': '4',
'五': '5',
'六': '6',
'七': '7',
'八': '8',
'九': '9'
}
def get_data():
while True:
data = client.lpop('datalist')
if not data:
break
yield data.decode()
def remove_sensitive_data(datas):
for data in datas:
if data == '敏感資訊':
continue
yield data
def tranfer_chinese_num(datas):
for data in datas:
try:
num = int(data)
except ValueError:
num = ''.join(CHINESE_NUM_DICT[x] for x in data)
yield num
def save_data(number_list):
for number in number_list:
data = {'num': number, 'date': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
handler.insert_one(data)
raw_data = get_data()
safe_data = remove_sensitive_data(raw_data)
number_list = tranfer_chinese_num(safe_data)
save_data(number_list)程式碼如下圖所示:
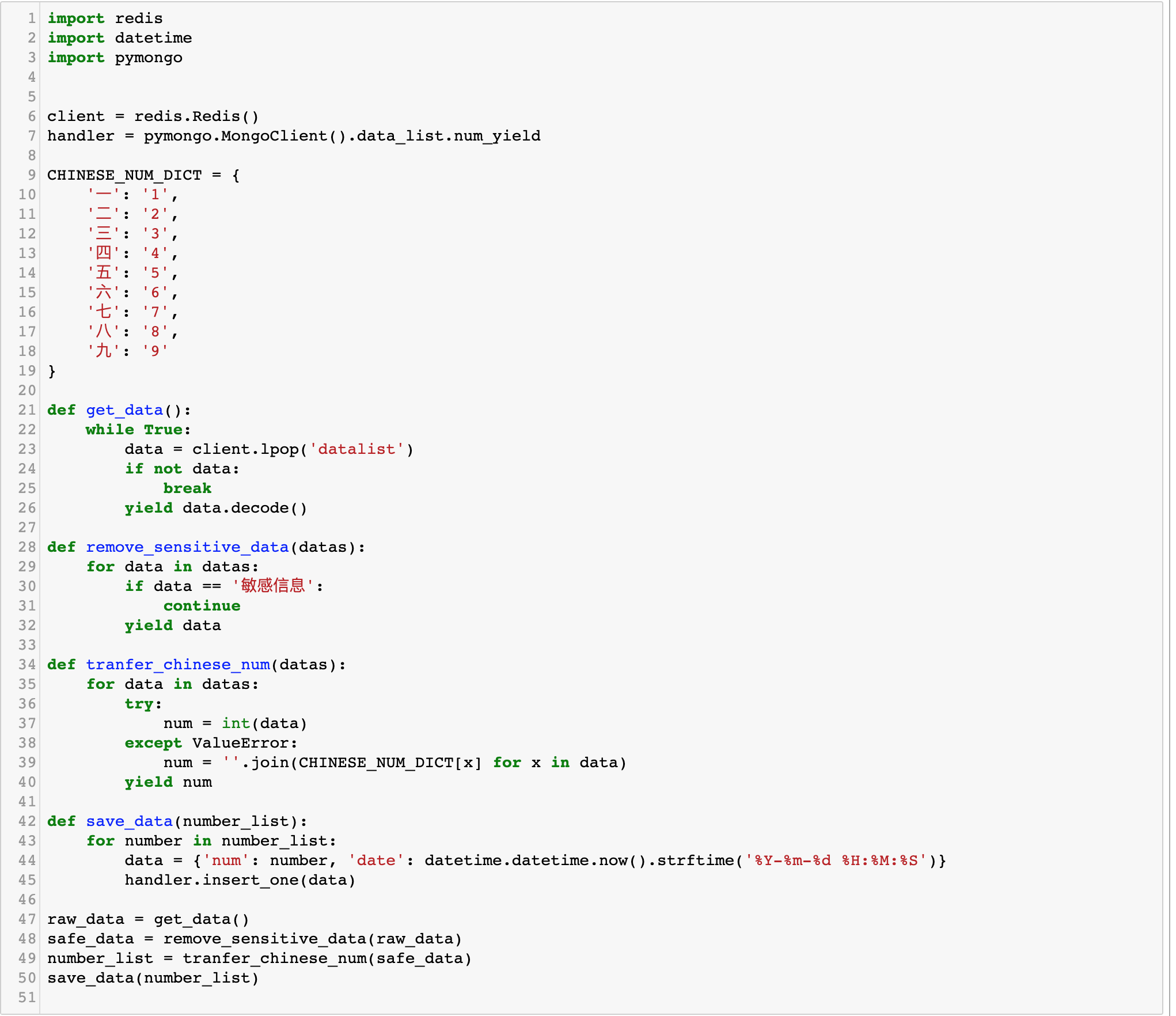
如果你開啟 PyCharm 除錯模式,你會發現,資料的流向是這樣的:
- 從 Redis 獲取1條資料
- 這一條資料傳給remove_sensitive_data
- 第2步處理以後的資料傳給tranfer_chinese_num
- 第3步處理以後,傳給 save_data
- 回到第1步
整個過程就像是一條流水線一樣,資料一條一條地進行處理和存檔。不需建立額外的列表,有多少條資料就迴圈多少次,不做多餘的迴圈。