
go map資料結構和原始碼詳解
目錄
- 1. 前言
- 2. go map的資料結構
- 2.1 核心結體體
- 2.2 資料結構圖
- 3. go map的常用操作
- 3.1 建立
- 3.2 插入或更新
- 3.3 刪除
- 3.4 查詢
- 3.5 range迭代
- 3.5.1 初始化迭代器mapiterinit()
- 3.5.2 迭代過程mapiternext()
- 4. go map的擴容縮容
- 4.1 擴容縮容的基本原理
- 4.2 為什麼叫“偽縮容”?如何實現“真縮容”?
- 5 Q&A關鍵知識點
- 5.1 基本原理
- 5.2 時間複雜度和空間複雜度分析
1. 前言
本文以go1.12.5版本分析,map相關的原始碼在runtime包的map開頭的幾個檔案中,主要為map.go。
go的map底層實現方式是hash表(C++的map是紅黑樹實現,而C++ 11新增的unordered_map則與go的map類似,都是hash實現)。go map的資料被置入一個由桶組成的有序陣列中,每個桶最多可以存放8個key/value對。key的hash值(32位)的低階位用於在該陣列中定位到桶,而高8位則用於在桶中區分key/value對。
go map的hash表中的基本單位是桶,每個桶最多存8個鍵值對,超了,則會連結到額外的溢位桶。所以go map是基本資料結構是hash陣列+桶內的key-value陣列+溢位的桶連結串列
當hash表超過閾值需要擴容增長時,會分配一個新的陣列,新陣列的大小一般是舊陣列的2倍。這裡從舊陣列將資料遷移到新陣列,不會一次全量拷貝,go會在每次讀寫Map時以桶為單位做動態搬遷疏散。
2. go map的資料結構
我們先了解基本的資料結構,後面再看原始碼就簡單多了。
2.1 核心結體體
map主要由兩個核心的結構,即基礎結構和桶實現:
- hmap:map的基礎結構
- bmap:嚴格來說hmap.buckets指向桶組成的陣列,每個桶的頭部是bmap,之後是8個key,再是8個value,最後是1個溢位指標。溢位指標指向額外的桶連結串列,用於儲存溢位的資料
const ( // 關鍵的變數 bucketCntBits = 3 bucketCnt = 1 << bucketCntBits // 一個桶最多儲存8個key-value對 loadFactorNum = 13 // 擴散因子:loadFactorNum / loadFactorDen = 6.5。 loadFactorDen = 2 // 即元素數量 >= (hash桶數量(2^hmp.B) * 6.5 / 8) 時,觸發擴容 ) // map的基礎資料結構 type hmap struct { count int // map儲存的元素對計數,len()函式返回此值,所以map的len()時間複雜度是O(1) flags uint8 // 記錄幾個特殊的位標記,如當前是否有別的執行緒正在寫map、當前是否為相同大小的增長(擴容/縮容?) B uint8 // hash桶buckets的數量為2^B個 noverflow uint16 // 溢位的桶的數量的近似值 hash0 uint32 // hash種子 buckets unsafe.Pointer // 指向2^B個桶組成的陣列的指標,資料存在這裡 oldbuckets unsafe.Pointer // 指向擴容前的舊buckets陣列,只在map增長時有效 nevacuate uintptr // 計數器,標示擴容後搬遷的進度 extra *mapextra // 儲存溢位桶的連結串列和未使用的溢位桶陣列的首地址 } // 桶的實現結構 type bmap struct { // tophash儲存桶內每個key的hash值的高位元組 // tophash[0] < minTopHash表示桶的疏散狀態 // 當前版本bucketCnt的值是8,一個桶最多儲存8個key-value對 tophash [bucketCnt]uint8 // 特別注意: // 實際分配記憶體時會申請一個更大的記憶體空間A,A的前8位元組為bmap // 後面依次跟8個key、8個value、1個溢位指標 // map的桶結構實際指的是記憶體空間A } // map.go裡很多函式的第1個入參是這個結構,從成員來看很明顯,此結構標示了鍵值對和桶的大小等必要資訊 // 有了這個結構的資訊,map.go的程式碼就可以與鍵值對的具體資料型別解耦 // 所以map.go用記憶體偏移量和unsafe.Pointer指標來直接對記憶體進行存取,而無需關心key或value的具體型別 type maptype struct { typ _type key *_type elem *_type bucket *_type // internal type representing a hash bucket keysize uint8 // size of key slot valuesize uint8 // size of value slot bucketsize uint16 // size of bucket flags uint32 }
C++使用模板可以根據不同的型別生成map的程式碼。
golang則通過上述maptype結構體傳遞鍵值對的型別大小等資訊,從而map.go直接用指標操作對應大小的記憶體來實現全域性一份map程式碼同時適用於不同型別的鍵值對。這點上可以認為相比C++用模板實現map的方式,go map的目標檔案的程式碼量會更小。
2.2 資料結構圖
map底層建立時,會初始化一個hmap結構體,同時分配一個足夠大的記憶體空間A。其中A的前段用於hash陣列,A的後段預留給溢位的桶。於是hmap.buckets指向hash陣列,即A的首地址;hmap.extra.nextOverflow初始時指向記憶體A中的後段,即hash陣列結尾的下一個桶,也即第1個預留的溢位桶。所以當hash衝突需要使用到新的溢位桶時,會優先使用上述預留的溢位桶,hmap.extra.nextOverflow依次往後偏移直到用完所有的溢位桶,才有可能會申請新的溢位桶空間。
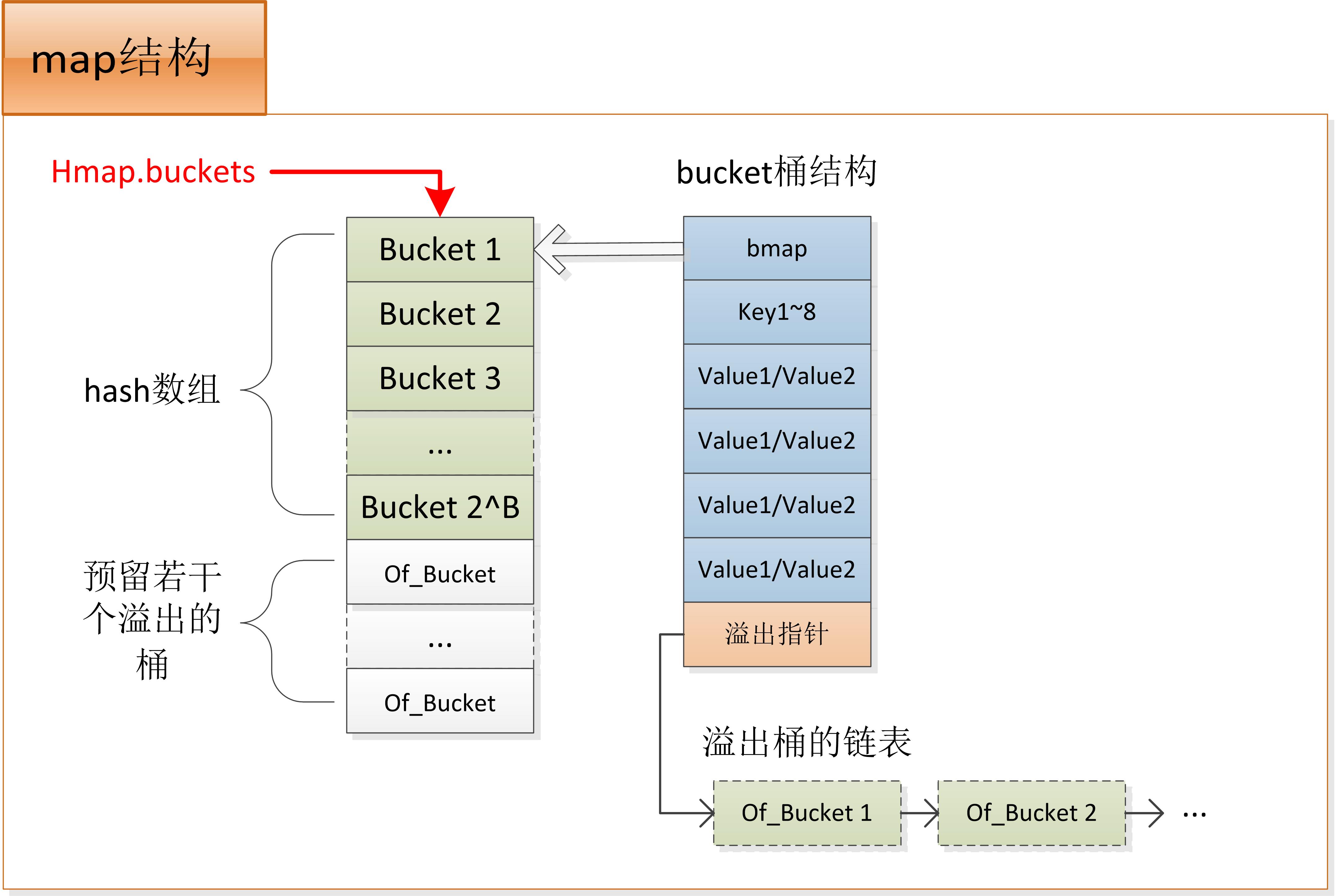
上圖中,當需要分配一個溢位桶時,會優先從預留的溢位桶數組裡取一個出來連結到連結串列後面,這時不需要再次申請記憶體。但當預留的桶被用完了,則需要申請新的記憶體給溢位桶。
3. go map的常用操作
3.1 建立
使用make(map[k]v, hint)建立map時會呼叫makemap()函式,程式碼邏輯比較簡單。
值得注意的是,makemap()建立的hash陣列,陣列的前面是hash表的空間,當hint >= 4時後面會追加2^(hint-4)個桶,之後再記憶體頁幀對齊又追加了若干個桶(參見2.2章節結構圖的hash陣列部分)
所以建立map時一次記憶體分配既分配了使用者預期大小的hash陣列,又追加了一定量的預留的溢位桶,還做了記憶體對齊,一舉多得。
// make(map[k]v, hint), hint即預分配大小
// 不傳hint時,如用new建立個預設容量為0的map時,makemap只初始化hmap結構,不分配hash陣列
func makemap(t *maptype, hint int, h *hmap) *hmap {
// 省略部分程式碼
// 隨機hash種子
h.hash0 = fastrand()
// 2^h.B 為大於hint*6.5(擴容因子)的最小的2的冪
B := uint8(0)
// overLoadFactor(hint, B)只有一行程式碼:return hint > bucketCnt && uintptr(hint) > loadFactorNum*(bucketShift(B)/loadFactorDen)
// 即B的大小應滿足 hint <= (2^B) * 6.5
// 一個桶能存8對key-value,所以這就表示B的初始值是保證這個map不需要擴容即可存下hint個元素對的最小的B值
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 這裡分配hash陣列
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// makeBucketArray()會在hash陣列後面預分配一些溢位桶,
// h.extra.nextOverflow用來儲存上述溢位桶的首地址
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
// 分配hash陣列
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b) // base代表使用者預期的桶的數量,即hash陣列的真實大小
nbuckets := base // nbuckets表示實際分配的桶的數量,>= base,這就可能會追加一些溢位桶作為溢位的預留
if b >= 4 {
// 這裡追加一定數量的桶,並做記憶體對齊
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
// 後面的程式碼就是申請記憶體空間了,此處省略
// 這裡大家可以思考下這個陣列空間要怎麼分配,其實就是n*sizeof(桶),所以:
// 每個桶前面是8位元組的tophash陣列,然後是8個key,再是8個value,最後放一個溢位指標
// sizeof(桶) = 8 + 8*sizeof(key) + 8*sizeof(value) + 8
return buckets, nextOverflow
}3.2 插入或更新
go map的插入操作,呼叫mapassign()函式。
同學們或許在某些資料上了解過:
- go map需要初始化才能使用,對空map插入會panic。hmap指標傳遞的方式,決定了map在使用前必須初始化
- go map不支援併發讀寫,會panic。如果一定要併發,請用sync.Map或自己解決衝突
上述兩個限制,在mapassign()函式開頭能找到答案:
- 引數合法性檢測,計算hash值
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 不熟悉指標操作的同學,用指標傳參往往會踩空指標的坑
// 這裡大家可以思考下,為什麼h要非空判斷?
// 如果一定要在這裡支援空map並檢測到map為空時自動初始化,應該怎麼寫?
// 提示:指標的指標
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// 在這裡做併發判斷,檢測到併發寫時,拋異常
// 注意:go map的併發檢測是偽檢測,並不保證所有的併發都會被檢測出來。而且這玩意是在執行期檢測。
// 所以對map有併發要求時,應使用sync.map來代替普通map,通過加鎖來阻斷併發衝突
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
hash := alg.hash(key, uintptr(h.hash0)) // 這裡得到uint32的hash值
h.flags ^= hashWriting // 置Writing標誌,key寫入buckets後才會清除標誌
if h.buckets == nil { // map不能為空,但hash陣列可以初始是空的,這裡會初始化
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
...
}- 定位key在hash表中的位置
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B) // 這裡用hash值的低階位定位hash陣列的下標偏移量
if h.growing() {
growWork(t, h, bucket) // 這裡是map的擴容縮容操作,我們在第4章單獨講
}
// 通過下標bucket,偏移定位到具體的桶
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash) // 這裡取高8位用於在桶內定位鍵值對
...
}- 進一步定位key可以插入的桶及桶中的位置
- 兩輪迴圈,外層迴圈遍歷hash桶及其指向的溢位連結串列,內層迴圈則在桶內遍歷(一個桶最多8個key-value對)
- 有可能正好連結串列上的桶都滿了,這時inserti為nil,第4步會連結一個新的溢位桶進來
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
var inserti *uint8 // tophash插入位置
var insertk unsafe.Pointer // key插入位置
var val unsafe.Pointer // value插入位置
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
// 找到個空位,先記錄下tophash、key、value的插入位置
// 但要遍歷完才能確定要不要插入到這個位置,因為後面有可能有重複的元素
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop // 遍歷完整個溢位連結串列,退出迴圈
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !alg.equal(key, k) {
continue
}
// 走到這裡說明map裡找到一個重複的key,更新key-value,跳到第5步
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done // 更新Key後跳到第5步
}
ovf := b.overflow(t)
if ovf == nil {
break // 遍歷完整個溢位連結串列,沒找到能插入的空位,結束迴圈,下一步再追加一個溢位桶進來
}
b = ovf // 繼續遍歷下一個溢位桶
}
...
}- 插入key
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// 這裡判斷要不要擴容,我們第4章再講
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil { // inserti == nil說明上1步沒找到空位,整個連結串列是滿的,這裡新增一個新的溢位桶上去
newb := h.newoverflow(t, b) // 分配新溢位桶,優先用3.1章節預留的溢位桶,用完了則分配一個新桶記憶體
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
// 當key或value的型別大小超過一定值時,桶只儲存key或value的指標。這裡分配空間並取指標
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key) // 在桶中對應位置插入key
*inserti = top // 插入tophash,hash值高8位
h.count++ // 插入了新的鍵值對,h.count數量+1
...
}- 結束插入
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting // 釋放hashWriting標誌位
if t.indirectvalue() {
val = *((*unsafe.Pointer)(val))
}
return val // 返回value可插入位置的指標,注意,value還沒插入
}- 只插入了tophash和key,就結束了嗎?value還沒插入呢
- 是的,mapassign()只插入tophash和key,並返回val指標,編譯器會在呼叫mapassign()後用彙編往val插入value
- google大佬這麼騷氣的操作,是為了減少value值傳遞的次數嗎?
3.3 刪除
- 刪除與插入類似,前面的步驟都是引數和狀態判斷、定位key-value位置,然後clear對應的記憶體。不展開說。以下是幾個關鍵點:
- 刪除過程中也會置hashWriting標誌
- 當key/value過大時,hash表裡儲存的是指標,這時候用軟刪除,置指標為nil,資料交給gc去刪。當然,這是map的內部處理,外層是無感知的,拿到的都是值拷貝
- 無論Key/value是值型別還是指標型別,刪除操作都隻影響hash表,外層已經拿到的資料不受影響。尤其是指標型別,外層的指標還能繼續使用
- 由於定位key位置的方式是查詢tophash,所以刪除操作對tophash的處理是關鍵:
- map首先將對應位置的tophash[i]置為emptyOne,表示該位置已被刪除
- 如果tophash[i]不是整個連結串列的最後一個,則只置emptyOne標誌,該位置被刪除但未釋放,後續插入操作不能使用此位置
- 如果tophash[i]是連結串列最後一個有效節點了,則把連結串列最後面的所有標誌為emptyOne的位置,都置為emptyRest。置為emptyRest的位置可以在後續的插入操作中被使用。
- 這種刪除方式,以少量空間來避免桶連結串列和桶內的資料移動。事實上,go 資料一旦被插入到桶的確切位置,map是不會再移動該資料在桶中的位置了。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
b.tophash[i] = emptyOne // 先標記刪除
// 如果b.tophash[i]不是最後一個元素,則暫時先佔著坑。emptyOne標記的位置暫時不能被插入新元素(見3.2章節插入函式)
if i == bucketCnt-1 {
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
for { // 如果b.tophash[i]是最後一個元素,則把末尾的emptyOne全部清除置為emptyRest
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break // beginning of initial bucket, we're done.
}
// Find previous bucket, continue at its last entry.
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
...
}3.4 查詢
查詢操作由mapaccess開頭的一組函式實現。前面的章節在插入和刪除之前都得先定位查詢到元素,邏輯是類似的,也比較簡單,就不細說了:
- mapaccess1():通過Key查詢,返回value指標,用於val := map[key]。未找到時返回value型別的0值。
- mapaccess2():通過key查詢,返回value指標,以及bool型別的是否查詢成功的標誌,用於val, ok := map[key]。未找到時返回value型別的0值。
- mapaccessK():通過key查詢,返回key和value指標,用於迭代器(range)。未找到時返回空指標
- mapaccess1_fat(),對mapaccess1()的封裝,區別是mapaccess1_fat()多了個zero引數,未找到時返回zero
- mapaccess2_fat(),也是對mapaccess1()的封裝。相比mapaccess1_fat(),本函式增加一個是否查詢成功的標誌
3.5 range迭代
map的迭代是通過hiter結構和對應的兩個輔助函式實現的。hiter結構由編譯器在呼叫輔助函式之前建立並傳入,每次迭代結果也由hiter結構傳回。下方的it即是hiter結構體的指標變數。
3.5.1 初始化迭代器mapiterinit()
mapiterinit()函式主要是決定我們從哪個位置開始迭代,為什麼是從哪個位置,而不是直接從hash陣列頭部開始呢?《go程式設計語言》好像提到過,hash表中資料每次插入的位置是變化的(其實是因為實現的原因,一方面hash種子是隨機的,這導致相同的資料在不同的map變數內的hash值不同;另一方面即使同一個map變數內,資料刪除再新增的位置也有可能變化,因為在同一個桶及溢位連結串列中資料的位置不分先後),所以為了防止使用者錯誤的依賴於每次迭代的順序,map作者乾脆讓相同的map每次迭代的順序也是隨機的。
迭代順序隨機的實現方式也簡單,直接從隨機的一個位置開始就行了:
- it.startBucket:這個是hash陣列的偏移量,表示遍歷從這個桶開始
- it.offset:這個是桶內的偏移量,表示每個桶的遍歷都從這個偏移量開始
於是,map的遍歷過程如下:
- 從hash陣列中第it.startBucket個桶開始,先遍歷hash桶,然後是這個桶的溢位連結串列。
- 之後hash陣列偏移量+1,繼續前一步動作。
- 遍歷每一個桶,無論是hash桶還是溢位桶,都從it.offset偏移量開始。(如果只是隨機一個開始的桶,range結果還是有序的;但每個桶都加it.offset偏移,這個輸出結果就有點撲朔迷離,大家可以親手試下,對同一個map多次range)
- 當迭代器經過一輪迴圈回到it.startBucket的位置,結束遍歷。
func mapiterinit(t *maptype, h *hmap, it *hiter) {
...
// 隨機一個偏移量來開始
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
...
mapiternext(it) // 初始化迭代器的同時也返回第1對key/value
}3.5.2 迭代過程mapiternext()
上一節迭代迴圈的過程很清晰了,這裡我們說明幾個重要的引數:
- it.startBucket:開始的桶
- it.offset:每個桶開始的偏移量
- it.bptr:當前遍歷的桶
- it.i:it.bptr已經遍歷的鍵值對數量,i初始為0,當i=8時表示這個桶遍歷完了,將it.bptr移向下一個桶
- it.key:每次迭代的結果
- it.value:每次迭代的結果
此外,迭代還需要關注擴容縮容的情況:
- 如果是在迭代開始後才growing,這種情況當前的邏輯沒處理,迭代有可能異常。呃,go map不支援併發。
- 如果是先growing,再開始迭代,這是有可能的。這種情況下,會先到舊hash表中檢查key對應的桶有沒有被疏散,未疏散則遍歷舊桶,已疏散則遍歷新hash表裡對應的桶。
4. go map的擴容縮容
4.1 擴容縮容的基本原理
go map的擴容縮容都是grow相關的函式,這裡擴容是真的,縮容是偽縮容,後面我會解釋。我們先看下觸發條件:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
...
}
// overLoadFactor()返回true則觸發擴容,即map的count大於hash桶數量(2^B)*6.5
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
// tooManyOverflowBuckets(),顧名思義,溢位桶太多了觸發縮容
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}map只在插入元素即mapassign()函式中對是否擴容縮容進行觸發,條件即是上面這段程式碼:
- 條件1:當前不處在growing狀態
- 條件2-1:觸發擴容:map的資料量count大於hash桶數量(2^B)*6.5。注意這裡的(2^B)只是hash陣列大小,不包括溢位的桶
- 條件2-2:觸發縮容:溢位的桶數量noverflow>=32768(1<<15)或者>=hash陣列大小。
仔細觀察觸發的程式碼,擴容和縮容是同一個函式,這是怎麼做到的呢?在hashGrow()開始,會先判斷是否滿足擴容條件,如果滿足就表明這次是擴容,不滿足就一定是縮容條件觸發了。擴容和縮容剩下的邏輯,主要區別就在於容量變化,就是hmap.B引數,擴容時B+1則hash表容量擴大1倍,縮容時hash表容量不變。
- h.oldbuckets:指向舊的hash陣列,即當前的h.buckets
- h.buckets:指向新建立的hash陣列
到這裡觸發的主要工作已經完成,接下來就是怎麼把元素搬遷到新hash表裡了。如果現在就一次全量搬遷過去,顯然接下來會有比較長的一段時間map被佔用(不支援併發)。所以搬遷的工作是非同步增量搬遷的。
在插入和刪除的函式內都有下面一段程式碼用於在每次插入和刪除操作時,執行一次搬遷工作:
if h.growing() { // 當前處於搬遷狀態
growWork(t, h, bucket) // 呼叫搬遷函式
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 將當前需要處理的桶搬遷
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() { // 再多搬遷一個桶
evacuate(t, h, h.nevacuate)
}
}- 每執行一次插入或刪除,都會呼叫growWork搬遷0~2個hash桶(有可能這次需要搬遷的2個桶在此之前都被搬過了)
- 搬遷是以hash桶為單位的,包含對應的hash桶和這個桶的溢位連結串列
- 被delete掉的元素(emptyone標誌)會被捨棄(這是縮容的關鍵)
4.2 為什麼叫“偽縮容”?如何實現“真縮容”?
現在可以解釋為什麼我把map的縮容叫做偽縮容了:因為縮容僅僅針對溢位桶太多的情況,觸發縮容時hash陣列的大小不變,即hash陣列所佔用的空間只增不減。也就是說,如果我們把一個已經增長到很大的map的元素挨個全部刪除掉,hash表所佔用的記憶體空間也不會被釋放。
所以如果要實現“真縮容”,需自己實現縮容搬遷,即建立一個較小的map,將需要縮容的map的元素挨個搬遷過來:
// go map縮容程式碼示例
myMap := make(map[int]int, 1000000)
// 假設這裡我們對bigMap做了很多次插入,之後又做了很多次刪除,此時bigMap的元素數量遠小於hash表大小
// 接下來我們開始縮容
smallMap := make(map[int]int, len(myMap))
for k, v := range myMap {
smallMap[k] = v
}
myMap = smallMap // 縮容完成,原來的map被我們丟棄,交給gc去清理5 Q&A關鍵知識點
5.1 基本原理
- 底層是hash實現,資料結構為hash陣列 + 桶 + 溢位的桶連結串列,每個桶儲存最多8個key-value對
- 查詢和插入的原理:key的hash值(低階位)與桶數量相與,得到key所在的hash桶,再用key的高8位與桶中的tophash[i]對比,相同則進一步對比key值,key值相等則找到
- go map不支援併發。插入、刪除、搬遷等操作會置writing標誌,檢測到併發直接panic
- 每次擴容hash表增大1倍,hash表只增不減
- 支援有限縮容,delete操作只置刪除標誌位,釋放溢位桶的空間依靠觸發縮容來實現。
- map在使用前必須初始化,否則panic:已初始化的map是make(map[key]value)或make(map[key]value, hint)這兩種形式。而new或var xxx map[key]value這兩種形式是未初始化的,直接使用會panic。
5.2 時間複雜度和空間複雜度分析
時間複雜度,go map是hash實現,我們先不管具體原理,江湖套路hash實現的就叫它O(1)的時間複雜度:
- 正常情況,且不考慮擴容狀態,複雜度O(1):通過hash值定位桶是O(1),一個桶最多8個元素,合理的hash演算法應該能把元素相對均勻雜湊,所以溢位連結串列(如果有)也不會太長,所以雖然在桶和溢位連結串列上定位key是遍歷,考慮到數量小也可以認為是O(1)
- 正常情況,處於擴容狀態時,複雜度也是O(1):相比於上一種狀態,擴容會增加搬遷最多2個桶和溢位連結串列的時間消耗,當溢位連結串列不太長時,複雜度也可以認為是O(1)
- 極端情況,雜湊極不均勻,大部分資料被集中在一條雜湊連結串列上,複雜度退化為O(n)。
go採用的hash演算法應是很成熟的演算法,極端情況暫不考慮。所以綜合情況下go map的時間複雜度應為O(1)
空間複雜度分析:
首先我們不考慮因刪除大量元素導致的空間浪費情況(這種情況現在go是留給程式設計師自己解決),只考慮一個持續增長狀態的map的一個空間使用率:
由於溢位桶數量超過hash桶數量時會觸發縮容,所以最壞的情況是資料被集中在一條鏈上,hash表基本是空的,這時空間浪費O(n)。
最好的情況下,資料均勻雜湊在hash表上,沒有元素溢位,這時最好的空間複雜度就是擴散因子決定了,當前go的擴散因子由全域性變數決定,即loadFactorNum/loadFactorDen = 6.5。即平均每個hash桶被分配到6.5個元素以上時,開始擴容。所以最小的空間浪費是(8-6.5)/8 = 0.1875,即O(0.1875n)
結論:go map的空間複雜度(指除去正常儲存元素所需空間之外的空間浪費)是O(0.1875n) ~ O(n)之