
CSAPP:程式碼優化【矩陣運算】
程式設計除了使程式在所有可能的情況下都正確工作,還需要考慮程式的執行效率,上一節主要介紹了關於讀寫的優化,本節將對運算的優化進行分析。讀寫優化
編寫高效程式需要做到以下兩點:
- 選擇一組合適的演算法和資料結構
- 編寫編譯器能夠有效優化以轉換成高效可執行程式碼的原始碼
第一點合適的演算法和資料結構往往是大家寫程式時會首先考慮到的,而第二點常被忽略。這裡我們就程式碼優化而言,主要討論如何編寫能夠被編譯器有效優化的原始碼,其中理解優化編譯器的能力和侷限性是很重要的。
除了讀寫與運算的區別,本節與上一節最大的不同的是:本次的優化示例會影響程式的可讀性。
但這也是程式設計中時常會遇到的情況,在沒有更好的優化手段,但又對程式有迫切的效能需求時,採取空間換時間,或降低程式碼可讀性換取執行效率的方法並非不可取。
當你編寫一個小工具臨時處理某種事務(也許以後並不重用),或者想驗證自己的某個想法是否可行時(比如測試某個演算法是否正確),若是編寫了一個可讀性不錯但執行很慢的程式,往往會浪費很多不必要的時間。這時候你就可以不需要那麼在乎程式碼的可讀性,而是去多關注當前程式的執行效能來更早獲得想要的結果。
以下我們將舉例對常見的矩陣運算進行程式碼優化。
目標函式:影象平滑處理
平滑操作要求:
- 修改影象矩陣的每個畫素點的值,
新值 = 以該畫素點為中心點所相鄰的九個畫素的平均值 - 影象矩陣的四個角點,只需要求角上四個畫素的平均值
- 影象矩陣的四條邊,只需要求當前點相鄰的六個畫素平均值
原理圖:
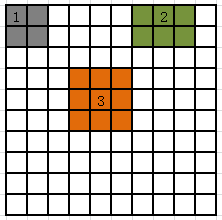
1、2、3處分別代表角點、邊緣點以及內部點的相鄰畫素
我們用以下結構體表示一張影象的畫素點:
typedef struct {
unsigned short red; /* R value */
unsigned short green; /* G value */
unsigned short blue; /* B value */
} pixel;red、green、blue分別表示一張彩色影象的紅綠藍三個通道。
原平滑函式如下:
static void accumulate_sum(pixel_sum *sum, pixel p) { sum->red += (int) p.red; sum->green += (int) p.green; sum->blue += (int) p.blue; sum->num++; return; } static void assign_sum_to_pixel(pixel *current_pixel, pixel_sum sum) { current_pixel->red = (unsigned short) (sum.red/sum.num); current_pixel->green = (unsigned short) (sum.green/sum.num); current_pixel->blue = (unsigned short) (sum.blue/sum.num); return; } static pixel avg(int dim, int i, int j, pixel *src) { int ii, jj; pixel_sum sum; pixel current_pixel; initialize_pixel_sum(&sum); for(ii = max(i-1, 0); ii <= min(i+1, dim-1); ii++) for(jj = max(j-1, 0); jj <= min(j+1, dim-1); jj++) accumulate_sum(&sum, src[RIDX(ii, jj, dim)]); assign_sum_to_pixel(¤t_pixel, sum); return current_pixel; } void naive_smooth(int dim, pixel *src, pixel *dst) { int i, j; for (i = 0; i < dim; i++) for (j = 0; j < dim; j++) dst[RIDX(i, j, dim)] = avg(dim, i, j, src); }
影象是標準的正方形,用一維陣列表示,第(i,j)個畫素表示為I[RIDX(i,j,n)],n為影象邊長。
引數:
- dim:影象的邊長
- src: 指向原始影象陣列首地址
- dst: 指向目標影象陣列首地址
優化目標:使平滑運算處理的更快
當前我們擁有一個driver.c檔案,可以對原函式和我們優化的函式進行測試,得到表示程式執行效能的CPE(每元素週期數)引數。
我們的任務就是實現優化程式碼,與原有程式碼同時執行進行引數的對比,檢視程式碼優化情況。
優化的主要方法
- 迴圈展開
- 平行計算
- 提前計算
- 分塊運算
- 避免複雜運算
- 減少函式呼叫
- 提高Cache命中率
迴圈主體只存在一條語句,該語句主要是進行大量的均值運算,而且呼叫了多層的函式,這樣執行時會出現多個函式棧的呼叫。
通過分析,本節的優化手段比上一節的矩陣讀寫要更直接。當前程式主要的效能瓶頸在於兩個方面:
- 多層函式呼叫:增加了不必要的函式棧處理開銷
- 大量重複運算:不同畫素點在進行均值運算時,很多運算都是重複且不必要的
本節的優化就是針對這兩點進行改進,
多層函式呼叫比較容易解決,只需要把被呼叫函式轉移在平滑函式中實現就行(原始碼降低了耦合度,但卻導致了效能的下降)。
下面主要分析重複運算的問題,如圖:
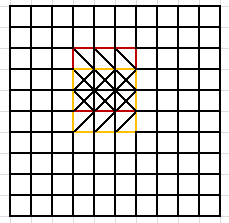
計算紅色區域平均值與黃色區域平均值時,有兩行是重複運算的。相應的優化策略是以1*3小矩陣為組計算和,這樣每次計算均值只需要3個已知的和相加除以9,減少了一定的運算量。
相應的優化程式碼如下:
int rsum[4096][4096];
int gsum[4096][4096];
int bsum[4096][4096];
void smooth(int dim, pixel *src, pixel *dst)
{
int dim2 = dim * dim;
for(int i = 0; i < dim; i++){
for(int j = 0; j < dim-2; j++){
int z = i*dim;
rsum[i][j] = 0, gsum[i][j] = 0, bsum[i][j] = 0;
for(int k = j; k < j + 3; k++){
rsum[i][j] += src[z+k].red;
gsum[i][j] += src[z+k].green;
bsum[i][j] += src[z+k].blue;
}
}
}
// 四個角
dst[0].red = (src[0].red + src[1].red + src[dim].red + src[dim+1].red) / 4;
dst[0].green = (src[0].green + src[1].green + src[dim].green + src[dim+1].green) / 4;
dst[0].blue = (src[0].blue + src[1].blue + src[dim].blue + src[dim+1].blue) / 4;
dst[dim-1].red = (src[dim-2].red + src[dim-1].red + src[dim+dim-2].red + src[dim+dim-1].red) / 4;
dst[dim-1].green = (src[dim-2].green + src[dim-1].green + src[dim+dim-2].green + src[dim+dim-1].green) / 4;
dst[dim-1].blue = (src[dim-2].blue + src[dim-1].blue + src[dim+dim-2].blue + src[dim+dim-1].blue) / 4;
dst[dim2-dim].red = (src[dim2-dim-dim].red + src[dim2-dim-dim+1].red + src[dim2-dim].red + src[dim2-dim+1].red) / 4;
dst[dim2-dim].green = (src[dim2-dim-dim].green + src[dim2-dim-dim+1].green + src[dim2-dim].green + src[dim2-dim+1].green) / 4;
dst[dim2-dim].blue = (src[dim2-dim-dim].blue + src[dim2-dim-dim+1].blue + src[dim2-dim].blue + src[dim2-dim+1].blue) / 4;
dst[dim2-1].red = (src[dim2-dim-2].red + src[dim2-dim-1].red + src[dim2-2].red + src[dim2-1].red) / 4;
dst[dim2-1].green = (src[dim2-dim-2].green + src[dim2-dim-1].green + src[dim2-2].green + src[dim2-1].green) / 4;
dst[dim2-1].blue = (src[dim2-dim-2].blue + src[dim2-dim-1].blue + src[dim2-2].blue + src[dim2-1].blue) / 4;
// 四條邊
for(int j = 1; j < dim-1; j++){
dst[j].red = (rsum[0][j-1]+rsum[1][j-1]) / 6;
dst[j].green = (gsum[0][j-1]+gsum[1][j-1]) / 6;
dst[j].blue = (bsum[0][j-1]+bsum[1][j-1]) / 6;
}
for(int i = 1; i < dim-1; i++){
int a = (i-1)*dim, b = (i-1)*dim+1, c = i*dim, d = i*dim+1, e = (i+1)*dim, f = (i+1)*dim+1;
dst[c].red = (src[a].red + src[b].red + src[c].red + src[d].red + src[e].red + src[f].red) / 6;
dst[c].green = (src[a].green + src[b].green + src[c].green + src[d].green + src[e].green + src[f].green) / 6;
dst[c].blue = (src[a].blue + src[b].blue + src[c].blue + src[d].blue + src[e].blue + src[f].blue) / 6;
}
for(int i = 1; i < dim-1; i++){
int a = i*dim-2, b = i*dim-1, c = (i+1)*dim-2, d = (i+1)*dim-1, e = (i+2)*dim-2, f = (i+2)*dim-1;
dst[d].red = (src[a].red + src[b].red + src[c].red + src[d].red + src[e].red + src[f].red) / 6;
dst[d].green = (src[a].green + src[b].green + src[c].green + src[d].green + src[e].green + src[f].green) / 6;
dst[d].blue = (src[a].blue + src[b].blue + src[c].blue + src[d].blue + src[e].blue + src[f].blue) / 6;
}
for(int j = 1; j < dim-1; j++){
dst[dim2-dim+j].red = (rsum[dim-1][j-1]+rsum[dim-2][j-1]) / 6;
dst[dim2-dim+j].green = (gsum[dim-1][j-1]+gsum[dim-2][j-1]) / 6;
dst[dim2-dim+j].blue = (bsum[dim-1][j-1]+bsum[dim-2][j-1]) / 6;
}
// 中間部分
for(int i = 1; i < dim-1; i++){
int k = i*dim;
for(int j = 1; j < dim-1; j++){
dst[k+j].red = (rsum[i-1][j-1]+rsum[i][j-1]+rsum[i+1][j-1]) / 9;
dst[k+j].green = (gsum[i-1][j-1]+gsum[i][j-1]+gsum[i+1][j-1]) / 9;
dst[k+j].blue = (bsum[i-1][j-1]+bsum[i][j-1]+bsum[i+1][j-1]) / 9;
}
}
}執行效率如下:
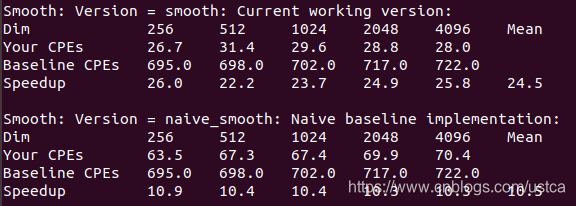
- Dim:影象大小
- Your CPEs:對應函式CPE
- Baseline CPEs:參考基線CPE
- Speedup:加速比 = Baseline CPEs / Your CPEs
原函式加速比為10.5,優化後加速比提升到24.5,雖然一定程度上損失了些程式碼的可讀性,但提升了我們想要的執行效率。
優化在一定程度上減少了重複的運算,但並沒有完全消除重複運算,如果有更好的優化方法歡迎交流。
轉載請註明出處:https://www.cnblogs.com/ustca/p/11796896.h