
Hadoop壓縮的圖文教程
近期由於Hadoop叢集機器硬碟資源緊張,有需求讓把 Hadoop 叢集上的歷史資料進行下壓縮,開始從網上查詢的都是關於各種壓縮機制的對比,很少有關於怎麼壓縮的教程(我沒找到。。),再此特記錄下本次壓縮的過程,方便以後查閱,利己利人。
本文涉及的所有 jar包、指令碼、native lib 見文末的相關下載 ~
我的壓縮版本:
Jdk 1.7及以上
Hadoop-2.2.0 版本
壓縮前環境準備:
關於壓縮演算法對比,網上資料很多,這裡我用的是 Bzip2 的壓縮方式,比較中庸,由於是Hadoop自帶的壓縮機制,也不需要額外下載別的東西,只需要在 Hadoop根目錄下 lib/native 檔案下有如下檔案即可:
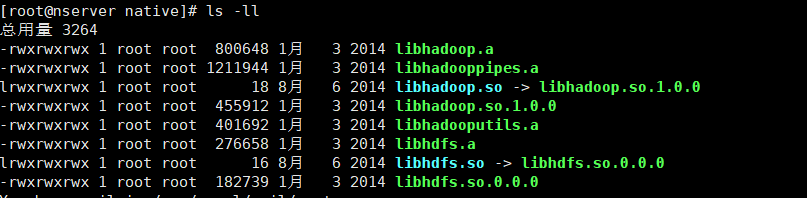
壓縮之前要檢查 Hadoop 叢集支援的壓縮演算法: hadoop checknative
每臺機器都要檢查一下,都顯示如圖 true 則說明 叢集支援 bzip2 壓縮,
如果顯示false 則需要將上圖的檔案下載拷貝到 Hadoop根目錄下 lib/native

壓縮程式介紹:
壓縮程式用到的類 getFileList(獲取檔案路徑) 、 FileHdfsCompress(壓縮類)、FileHdfsDeCompress(解壓縮類) ,只用到這三個類即可完成壓縮/解壓縮操作。
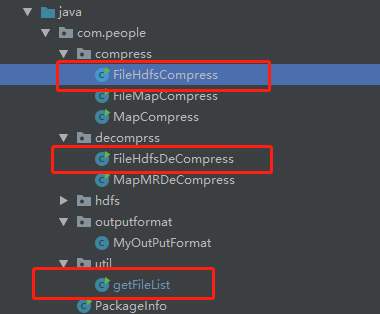
getFileList 作用:遞迴列印 傳入檔案目錄下檔案的根路徑,包括子目錄下的檔案。開始想直接輸出到檔案中,後來打包放到叢集上執行時,發現檔案沒有內容,可能是由於分散式執行的關係,所以就把路徑打印出來,人工在放到檔案中。
核心程式碼:
public static void listAllFiles(String path, List<String> strings) throws IOException {
FileSystem hdfs = getHdfs(path);
Path[] filesAndDirs = getFilesAndDirs(path);
for(Path p : filesAndDirs){
if(hdfs.getFileStatus(p).isFile()){
if(!p.getName().contains("SUCCESS")){
System.out.println(p);
}
}else{
listAllFiles(p.toString(),strings);
}
}
// FileUtils.writeLines(new File(FILE_LIST_OUTPUT_PATH), strings,true);
}
public static FileSystem getHdfs(String path) throws IOException {
Configuration conf = new Configuration();
return FileSystem.get(URI.create(path),conf);
}
public static Path[] getFilesAndDirs(String path) throws IOException {
FileStatus[] fs = getHdfs(path).listStatus(new Path(path));
return FileUtil.stat2Paths(fs);
}
FileHdfsCompress:壓縮程式非常簡單,對應程式裡的 FileHdfsCompress 類,(解壓縮是 FileHdfsDeCompress),採用的是Hadoop 原生API ,將Hadoop叢集上原檔案讀入作為輸入流,將壓縮路徑的輸入流作為輸出,再使用相關的壓縮演算法即,程式碼如下:
核心程式碼:
//指定壓縮方式
Class<?> codecClass = Class.forName(COMPRESS_CLASS_NAME);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec)ReflectionUtils.newInstance(codecClass, conf);
// FileSystem fs = FileSystem.get(conf);
FileSystem fs = FileSystem.get(URI.create(inputPath),conf);
//原檔案路徑 txt 用原本的輸入流讀入
FSDataInputStream in = fs.open(new Path(inputPath));
//建立 HDFS 上的輸出流,壓縮路徑
//通過檔案系統獲取輸出流
OutputStream out = fs.create(new Path(FILE_OUTPUT_PATH));
//對輸出流的資料壓縮
CompressionOutputStream compressOut = codec.createOutputStream(out);
//讀入原檔案 壓縮到HDFS上 輸入--普通流 輸出-壓縮流
IOUtils.copyBytes(in, compressOut, 4096,true);
以下是程式碼優化的過程,不涉及壓縮程式使用,不感興趣同學可以跳過 ~ :
在實際編碼中,我其實是走了彎路的,一開始並沒有想到用 Hadoop API 就能實現壓縮解壓縮功能,程式碼到此其實是經歷了優化迭代的過程。
最開始時壓縮的思路就是 將檔案讀進來,再壓縮出去,一開始使用了 MapReduce 的方式,在編碼過程中,由於對生成壓縮檔案的路徑還有要求,又在 Hadoop 輸出時自定義了輸出類來使的輸出檔案的名字符合要求,不是 part-r-0000.txt ,而是時間戳.txt 的格式,至此符合原線上路徑的要求。
而在實際執行過程中發現,MR 程式需要啟動 Yarn,並佔用Yarn 資源,由於壓縮時間較長,有可能會長時間佔用 叢集資源不釋放,後來發現 MR 程式的初衷是用來做平行計算的,而壓縮僅僅是 map 任務讀取一條就寫一條,不涉及計算,就是內容的簡單搬運。所以這裡放棄了使用 MR 想著可不可以就用簡單的 Hadoop API 就完成壓縮功能,經過一番嘗試後,發現真的可行! 使用了 Hadoop API 釋放了叢集資源,壓縮速度也還可以,這樣就把這個壓縮程式當做一個後臺程序跑就行了也不用考慮叢集資源分配的問題。
實測壓縮步驟:
1 將專案打包,上傳到hadoop 叢集任一節點即可,準備好相應的指令碼,輸入資料檔案,日誌檔案,如下圖:

2 使用獲取檔案路徑指令碼,列印路徑:
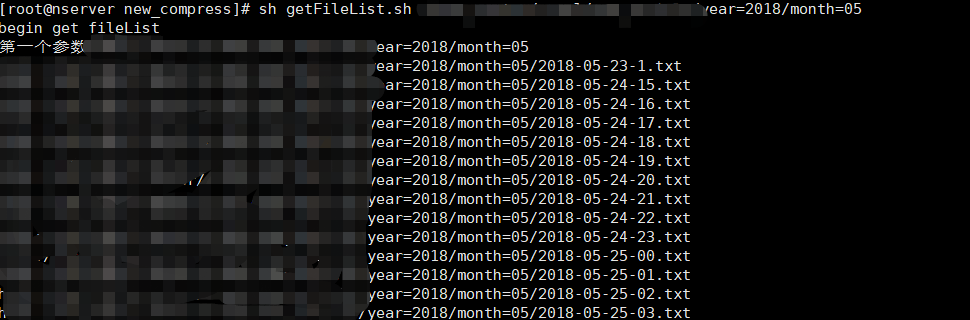
getFileLish.sh 指令碼內容如下,就是簡單呼叫,傳入引數為 hadoop叢集上 HDFS 上目錄路徑:
#!/bin/sh echo "begin get fileList" echo "第一個引數$1" if [ ! -n "$1" ]; then echo "check param!" fi #original file hadoop jar hadoop-compress-1.0.jar com.people.util.getFileList $1
3 將 列印的路徑 貼上到 compress.txt 中,第 2 步中會把目錄的檔案路徑包括子目錄路徑都打印出來,將其貼上進 compress.txt 中即可,注意 檔名可隨意定。
4 使用壓縮指令碼即可,sh compress.sh /data/new_compress/compress.txt ,加粗的部分是指令碼的引數意思是 第3步中檔案的路徑,注意:這裡只能是絕對路徑,不然可能報找不到檔案的異常。

compress.sh 指令碼內容如下,就是簡單呼叫,傳入引數為 第3步中檔案的絕對路徑:
#!/bin/sh echo "begin compress" echo "第一個引數$1" if [ ! -n "$1" ]; then echo "check param!" fi hadoop jar hadoop-compress-1.0.jar com.people.compress.FileHdfsCompress $1 >> /data/new_compress/compress.log 2>&1 &
5 檢視壓縮日誌,發現後臺程式已經開始壓縮了!,tail -f compress.log

6 如果感覺壓縮速度不夠,可以多臺機器執行指令碼,也可以一臺機器執行多個任務,因為這個指令碼任務是一個後臺程序,不會佔用叢集 Yarn 資源。
相關下載:
程式原始碼下載: [email protected]:fanpengyi/hadoop-compress.git
Hadoop 壓縮相關需要的 指令碼、jar包、lib 下載: 關注公眾號 “大資料江湖”,後臺回覆 “hadoop壓縮”,即可下載

長按即可關注
--- The End ---
&n