
圖解Elasticsearch的核心概念
本文講解大綱,分8個核心概念講解說明:
- NRT
- Cluster
- Node
- Document&Field
- Index
- Type
- Shard
- Replica
Near Realtime(NRT)近實時
Elasticsearch的核心優勢就是(Near Real Time NRT)近乎實時,我們稱之為近實時。
NRT有兩個意思,下面舉例說明下:
- 從寫入索引資料到資料可以被搜尋到有一個小延遲(大概1秒);
舉個例子:電商平臺新上架一個新商品,1秒後用戶就可搜尋到這個商品資訊,這就是近實時。
- 基於Elasticsearch執行搜尋和分析可以達到秒級查詢
也舉個例子說明,比如我現在想查詢我在淘寶,最近一年都買過幾件商品,總共花了多少錢,最貴的商品多少錢,哪個月買到東西最多,什麼型別的商品買的最多這樣的資訊,如果淘寶說,你要等待10分鐘才能出結果,你是不是很崩潰,這個延遲的時間就不是近實時,如果淘寶可以秒級別返回給你,就是近實時了。
下面畫一個圖,解釋下三個基本概念的

Cluster:叢集
包含多個節點,每個節點屬於哪個叢集是通過一個配置(叢集名稱,預設是elasticsearch)來決定的,對於中小型應用來說,剛開始一個叢集就一個節點很正常。叢集的目的為了提供高可用和海量資料的儲存以及更快的跨節點查詢能力。
Node:節點
叢集中的一個節點,節點也有一個名稱(預設是隨機分配的),節點名稱很重要(在執行運維管理操作的時候),預設節點會去加入一個名稱為“elasticsearch”的叢集,如果直接啟動一堆節點,那麼它們會自動組成一個elasticsearch叢集,當然一個節點也可以組成一個elasticsearch叢集
Document&field:文件和欄位
document 是es中的最小資料單元,一個document可以是一條客戶資料,一條商品分類資料,一條訂單資料,通常用JSON資料結構表示,每個index下的type中,都可以去儲存多個document。一個document裡面有多個field,每個field就是一個數據欄位。
相當於mysql裡的行,可以簡單這麼理解,舉個例子。一個商品的文件資料一條如下:
product document { "product_id": "1000", "product_name": "mac pro 2019 款筆記本", "product_desc": "高效能,高解析度,程式設計必備神器", "category_id": "2", "category_name": "電子產品" }
Index:索引
包含一堆有相似結構的文件資料,比如可以有一個客戶索引,商品分類索引,訂單索引,索引有一個名稱。
一個index包含很多document,一個index就代表了一類類似的或者相同的document。比如說建立一個product index,商品索引,裡面可能就存放了所有的商品資料,所有的商品document。
Type:型別
每個索引裡都可以有一個或多個type,type是index中的一個邏輯資料分類,一個type下的document,都有相同的field,比如部落格系統,有一個索引,可以定義使用者資料type,部落格資料type,評論資料type。
商品index,裡面存放了所有的商品資料,商品document
但是商品分很多種類,每個種類的document的field可能不太一樣,比如說電器商品,可能還包含一些諸如售後時間範圍這樣的特殊field;生鮮商品,還包含一些諸如生鮮保質期之類的特殊field
type,日化商品type,電器商品type,生鮮商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
電器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鮮商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一個type裡面,都會包含一堆document
{
"product_id": "2",
"product_name": "長虹電視機",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "電器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基圍蝦",
"product_desc": "純天然,冰島產",
"category_id": "4",
"category_name": "生鮮",
"eat_period": "7天"
}
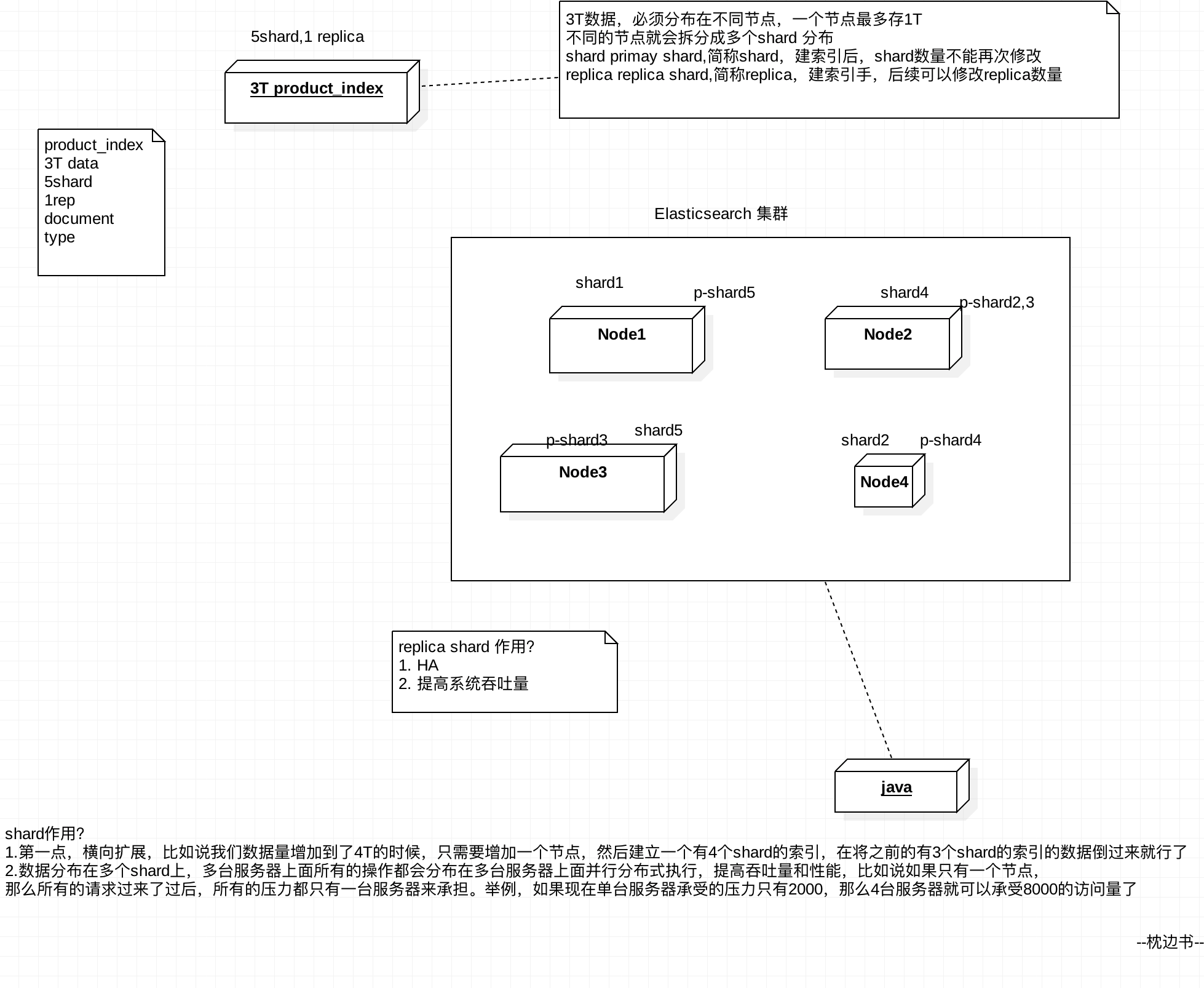
Shard 分片,也稱 Primary Shard
單臺機器無法儲存大量資料,es可以將一個索引中的資料切分為多個shard,分佈在多臺伺服器上儲存。有了shard就可以橫向擴充套件,儲存更多資料,讓搜尋和分析等操作分佈到多臺伺服器上去執行,提升吞吐量和效能。
每個shard都是一個lucene index。
Replica 副本,也稱 Replica Shard
任何一個伺服器隨時可能故障或宕機,此時shard可能就會丟失,因此可以為每個shard建立多個replica副本。replica可以在shard故障時提供備用服務,保證資料不丟失,多個replica還可以提升搜尋操作的吞吐量和效能。
primary shard(建立索引時一次設定,不能修改,預設5個),
replica shard(隨時修改數量,預設1個),
預設每個索引10個shard,5個primary shard,5個replica shard,最小的高可用配置,是2臺伺服器。
相關索引解釋說明:
- index包含多個shard
- 每個shard都是一個最小工作單元,承載部分資料,lucene例項,完整的建立索引和處理請求的能力
- 增減節點時,shard會自動在nodes中負載均衡
- primary shard和replica shard,每個document肯定只存在於某一個primary shard以及其對應的replica shard中,不可能存在於多個primary shard
- replica shard是primary shard的副本,負責容錯,以及承擔讀請求負載
- primary shard的數量在建立索引的時候就固定了,replica shard的數量可以隨時修改
- primary shard的預設數量是5,replica預設是1,預設有10個shard,5個primary shard,5個replica shard
- primary shard不能和自己的replica shard放在同一個節點上(否則節點宕機,primary shard和副本都丟失,起不到容錯的作用),但是可以和其他primary shard的replica shard放在同一個節點上
索引在叢集中分配圖:
本文由部落格一文多發平臺 OpenWrite 釋出!