
人臉檢測和人臉識別原理
一、MTCNN的原理
搭建人臉識別系統的第一步是人臉檢測,也就是在圖片中找到人臉的位置。在這個過程中,系統的輸入是一張可能含有人臉的圖片,輸出是人臉位置的矩形框,如下圖所示。一般來說,人臉檢測應該可以正確檢測出圖片中存在的所有人臉,不能用遺漏,也不能有錯檢。

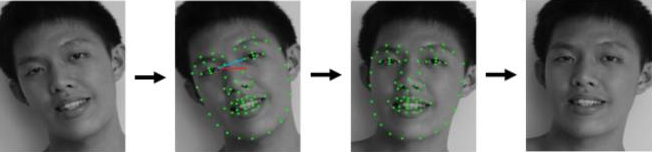
獲得包含人臉的矩形框後,第二步要做的就是人臉對齊(Face Alignment)。原始圖片中人臉的姿態、位置可能較大的區別,為了之後統一處理,要把人臉“擺正”。為此,需要檢測人臉中的關鍵點(Landmark),如眼睛的位置、鼻子的位置、嘴巴的位置、臉的輪廓點等。根據這些關鍵點可以使用仿射變換將人臉統一校準,以儘量消除姿勢不同帶來的誤差,人臉對齊的過程如下圖所示。
這裡介紹一種基於深度卷積神經網路的人臉檢測和人臉對齊方法----MTCNN,它是基於卷積神經網路的一種高精度的實時人臉檢測和對齊技術。MT是英文單詞Multi-task的縮寫,意思就是這種方法可以同時完成人臉檢測的人臉對齊兩項任務。相比於傳統方法,MTCNN的效能更好,可以更精確的定位人臉,此外,MTCNN也可以做到實時的檢測。
MTCNN由三個神經網路組成,分別是P-Net、R-Net、O-Net。在使用這些網路之前,首先要將原始圖片縮放到不同尺度,形成一個“影象金字塔”,如下圖所示。
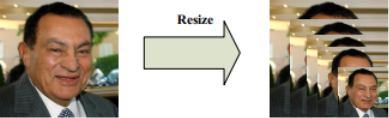
接著會對每個尺度的圖片通過神經網路計算一遍。這樣做的原因在於:原始圖片中的人臉存在不同的尺度,如有的人臉比較大,有的人臉比較小。對於比較小的人臉,可以在放大後的圖片上檢測;對於比較大的人臉,可以在縮小後的圖片上進行檢測。這樣,就可以在統一的尺度下檢測人臉了。
現在再來討論第一個網路P-Net的結構,如下圖所示
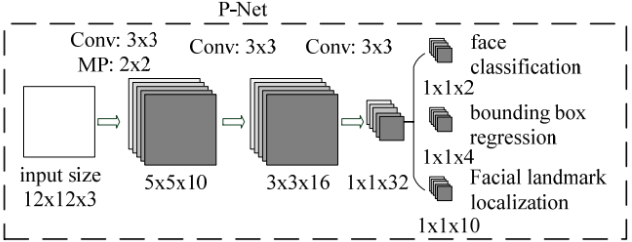
P-Net的輸入是一個寬和高皆為12畫素,同時是3通道的RGB影象,該網路要判斷這個12x12的影象中是否含有人臉,並且給出人臉框和關鍵點的位置。因此對應的輸出應該由3部分組成:
(1)第一個部分要判斷該影象是否是人臉(上圖中的face classification),輸出向量的形狀為1x1x2,也就是兩個值,分別為該影象是人臉的概率,以及該影象不是人臉的概率。這兩個值加起來應該嚴格等1。之所以使用兩個值來表示,是為了方便定義交叉熵損失。
(2)第二個部分給出框的精確位置(上圖中的bounding box regression),一般稱之為框迴歸。P-Net輸入的12x12的影象塊可能並不是完美的人臉框的位置,如有的時候人臉並不正好為方形,有的時候12x12的影象塊可能偏左或偏右,因此需要輸出當前框位置相對於完美的人臉框位置的偏移。這個偏移由四個變數組成。一般地,對於影象中的框,可以用四個數來表示它的位置:框左上角的橫座標、框左上角的縱座標、框的寬度、框的高度。因此,框迴歸輸出的值是:框左上角的橫座標的相對偏移、框左上角的縱座標的相對偏移、框的寬度的誤差、框的 高度的誤差。輸出向量的形狀就是上圖中的1x1x4。
上面的介紹大致就是P-Net的結構了。在實際計算中,通過P-Net中第一層卷積的移動,會對影象中每一個12x12的區域做一次人臉檢測,得到的結構如下圖所示:
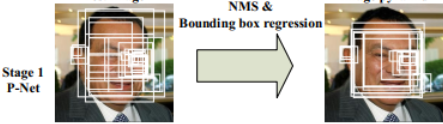
圖中框的大小各有不同,除了框迴歸的影響外,主要是因為將圖片金字塔的各個尺度都使用P-Net計算了一遍,因此形成了大小不同的人臉框。P-Net的結果還是比較粗糙的,所以接下來又使用R-Net進一步調優。R-Net的網路結構如下圖所示。
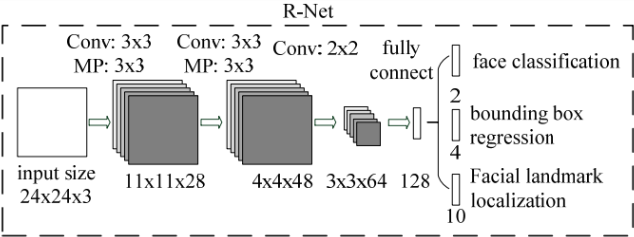
這個結構與之前的P-Net非常類似,P-Net的輸入是12x12x3的影象,R-Net是24x24x3的影象,也就是說,R-Net判斷24x24x3的影象中是否含有人臉,以及預測關鍵點的位置。R-Net的輸出和P-Net完全一樣,同樣有人臉判別、框迴歸、關鍵點位置預測三部分組成。
在實際應用中,對每個P-Net輸出可能為人臉的區域都放縮到24x24的大小,在輸入到R-Net中,進行進一步的判定。得到的結果如下圖所示:

顯然R-Net消除了P-Net中很多誤判的情況。
進一步把所有得到的區域縮放成48x48的大小,輸入到最後的O-Net中,O-Net的結構同樣與P-Net類似,不同點在於它的輸入是48x48x3的影象,網路的通道數和層數也更多了。O-Net的網路的結構如下圖所示:
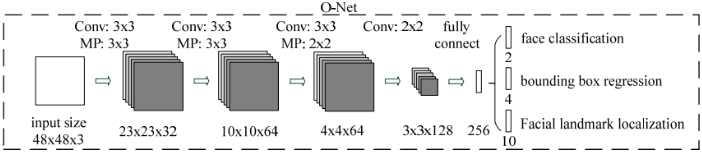
檢測結果如下圖所示:
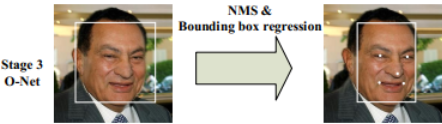
從P-Net到R-Net,最後再到O-Net,網路輸入的圖片越來越大,卷積層的通道數越來越多,內部的層數也越來越多,因此它們識別人臉的準確率應該是越來越高的。同時,P-Net的執行速度是最快的,R-Net的速度其次,O-Net的執行速度最慢。之所以要使用三個網路,是因為如果一開始直接對圖中的每個區域使用O-Net,速度會非常慢慢。實際上P-Net先做了一遍過濾,將過濾後的結果再交給R-Net進行過濾,最後將過濾後的結果交給效果最好但速度較慢的O-Net進行判別。這樣在每一步都提前減少了需要判別的數量,有效降低了處理時間。
最後介紹MTCNN的損失定義和訓練過程。MTCNN中每個網路都有三部分輸出,因此損失也由三部分組成。針對人臉判別部分,直接使用交叉熵損失,針對框迴歸和關鍵點判定,直接使用L2損失。最後這三部分損失各自乘以自身的權重再加起來,就形成最後的總損失了。在訓練P-Net和R-Net時,更關心框位置的準確性,而較少關注關鍵點判定的損失,因此關鍵點判定損失的權重很小。對於O-Net,關鍵點判定損失的權重較大。
二、使用深度卷積網路提取特徵
經過人臉檢測和人臉對齊兩個步驟,就獲得了包含人臉的區域影象,接下來就要進行人臉識別了。這一步一般是使用深度卷積網路,將輸入的人臉影象轉換為一個向量的表示,也就是所謂的“特徵”。
如何針對人臉來提取特徵?可以先來回憶VGG16的網路結構(見微調(Fine-tune)原理),輸入神經網路的是影象,經過一系列卷積計算後,全連線分類得到類別概率。
在通常的影象應用中,可以去掉全連線層,使用卷積層的最後一層當作影象的“特徵”。但如果對人臉識別問題同樣採用這種方法,即使用卷積層最後一層做為人臉的“向量表示”,效果其實是不好的。這其中的原因和改進方法是什麼?在後面會談到,這裡先談談希望這種人臉的“向量表示”應該具有哪些性質。
在理想的狀況下,希望“向量表示”之間的距離可以直接反映人臉的相似度:
對於同一個人的兩張人臉影象,對應的向量之間的歐幾里得距離應該比較小。對於不同人的兩張人臉影象,對應的向量之間的歐幾里得距離應該比較大。
例如,設人臉影象為$x_{1}$,$x_{2}$,對應的特徵為$f(x_{1})$,$f(x_{2})$,當$x_{1}$,$x_{2}$對應是同一個人的人臉時,$f(x_{1})$,$f(x_{2})$的距離$\left \| f(x_{1}),f(x_{2}) \right \|$2應該很小,而當$x_{1}$,$x_{2}$是不同人的人臉時,$f(x_{1})$,$f(x_{2})$的距離$\left \| f(x_{1}),f(x_{2}) \right \|$2應該很大。
在原始的CNN模型中,使用的是Softmax損失。Softmax是類別間的損失,對於人臉來說,每一類就是一個人。儘管使用Softmax損失可以區別出每個人,但其本質上沒有對每一類的向量表示之間的距離做出要求。
舉個例子,使用CNN對MNIST進行分類,設計一個特殊的卷積網路,讓其最後一層的向量變為2維,此時可以畫出每一類對應的2維向量(圖中一種顏色對應一種類別),如下圖所示:
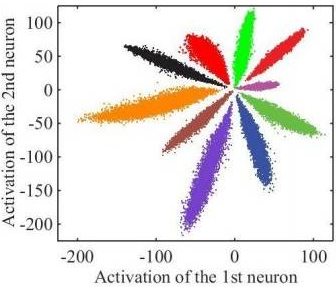
上圖是我們直接使用softmax訓練得到的結果,它就不符合我們希望特徵具有的特點:
(1)我們希望同一類對應的向量表示儘可能接近。但這裡同一類(如紫色),可能具有很大的類間距離;
(2)我們希望不同類對應的向量應該儘可能遠。但在圖中靠中心的位置,各個類別的距離都很近;
對於人臉影象同樣會出現類似的情況,對此,有很改進方法。這裡介紹其中兩種:一種是三元組損失函式(Triplet Loss),一種是中心損失函式。
三、三元組損失的定義
三元組損失函式的原理:既然目標是特徵之間的距離應該具備某些性質,那麼我們就圍繞這個距離來設計損失。具體的,我們每次都在訓練資料中抽出三張人臉影象,第一張影象記為$x_{i}^{a}$,第二張影象記為$x_{i}^{p}$,第三張影象記為$x_{i}^{n}$。在這樣的一個“三元組”中,$x_{i}^{a}$和$x_{i}^{p}$對應的是同一個人的影象,而$x_{i}^{n}$是另外一個不同的人的人臉影象。因此,距離$\left \| f(x_{i}^{a})-f(x_{i}^{p}) \right \|_{2}$應該較小,而距離$\left \| f(x_{i}^{a})-f(x_{i}^{n}) \right \|_{2}$應該較大。嚴格來說,三元組損失要求下面的式子成立:
$\left \| f(x_{i}^{a})- f(x_{i}^{p})\right \|_{2}^{2}+\alpha <\left \| f(x_{i}^{a})- f(x_{i}^{p})\right \|_{2}^{2}$
然後計算相同人臉之間與不同人臉之間距離的平方
$\left [ \left \| f(x_{i}^{a})-f(x_{i}^{p}) \right \|_{2}^{2}+\alpha -\left \| f(x_{i}^{a})-f(x_{i}^{n}) \right \|_{2}^{2} \right ]_{+}$
上式表達相同人臉間的距離平方至少要比不同人臉間的距離平方小α(取平方主要是為了方便求導),據此,上式實際上就是相當於一個損失函式。這樣的話,當三元組的距離滿足 $\left \| f(x_{i}^{a})- f(x_{i}^{p})\right \|_{2}^{2}+\alpha <\left \| f(x_{i}^{a})- f(x_{i}^{p})\right \|_{2}^{2}$時,不產生任何損失,此時$L_{i}=0$。當距離不滿足上述等式時,就會有值為$\left \| f(x_{i}^{a})-f(x_{i}^{p}) \right \|_{2}^{2}+\alpha -\left \| f(x_{i}^{a})-f(x_{i}^{n}) \right \|_{2}^{2}$的損失。此外,在訓練時會固定$\left \| f(x) \right \|_{2}=1$,以保證特徵不會無限地“遠離”。
三元組損失直接對距離進行優化,因此可以解決人臉的特徵表示問題。但是在訓練過程中,三元組的選擇非常地有技巧性。如果每次都是隨機選擇三元組,雖然模型可以正確的收斂,但是並不能達到最好的效能。如果加入"難例挖掘",即每次都選擇最難解析度的三元組進行訓練,模型又往往不能正確的收斂。對此,又提出每次都選擇那些"半難"(Semi-hard)的資料進行訓練,讓模型在可以收斂的同時也保持良好的效能。此外,使用三元組損失訓練人臉模型通常還需要非常大的人臉資料集,才能取得較好的效果。
四、中心損失的定義
與三元組損失不同,中心損失(Center Loss)不直接對距離進行優化,它保留了原有的分類模型,但又為每個類(在人臉模型中,一個類就對應一個人)指定了一個類別中心。同一類的影象對應的特徵都應該儘量靠近自己的類別中心,不同類的類別中心儘量遠離。與三元組損失函式相比,使用中心損失訓練人臉模型不需要使用特別的取樣方法,而且利用較少的影象就可以達到與單元組損失相似的效果。下面我們一起來學習中心損失的定義:
還是設輸入的人臉影象為$x_{i}$,該人臉對應的類別為$y_{i}$,對每個類別都規定一個類別中心,記作$c_{yi}$。希望每個人臉影象對應的特徵$f(x_{i})$都儘可能接近其中心$c_{yi}$。因此定義中心損失為:
$L_{i}=\frac{1}{2}\left \| f(x_{i})-c_{yi}\right \|_{2}^{2}$
多張影象的中心損失就是將它們的值加在一起:
$L_{center}=\sum\limits_{i}L_i$
這是一個非常簡單的定義。不過還有一個問題沒有解決,那就是如何確定每個類別的中心$c_{yi}$呢?從理論上來說,類別$y_{i}$的最佳中心應該是它對應的所有圖片的特徵的平均值。但如果採取這樣的定義,那麼在每一次梯度下降時,都要對所有圖片計算一次$c_{yi}$,計算複雜度就太高了。針對這種情況,不妨近似一處理下,在初始階段,先隨機確定$c_{yi}$,接著在每個batch內,使用$L_i=\|f(x_i)-c_{yi}\|_2^2$對當前batch內的$c_{yi}$ 也計算梯度,並使用該梯度更新$c_{yi}$ 。此外,不能只使用中心損失來訓練分類模型,還需要加入Softmax損失,也就是說,最終的損失由兩部分構成,即$L = L_{softmax}+\lambda L_{center}$,其中$\lambda $是一個超引數。
最後來總結使用中心損失來訓練人臉模型的過程。首先隨機初始化各個中心$c_{yi}$,接著不斷地取出batch進行訓練,在每個batch中,使用總的損失$L$,除了使用神經網路模型的引數對模型進行更新外,也對$c_{yi}$進行計算梯度,並更新中心的位置。
中心損失可以讓訓練處的特徵具有“內聚性”。還是以MNIST的例子來說,在未加入中心損失時,訓練的結果不具有內聚性。再加入中心損失後,得到的特徵如下圖所示。
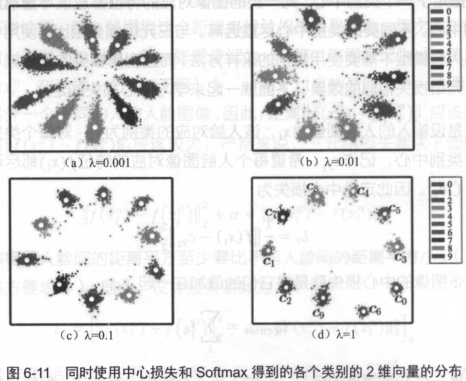
從圖中可以看出,當中心損失的權重λ越大時,生成的特徵就會具有越明顯的“內聚性” 。
五、使用特徵設計應用
當提取出特徵後,剩下的問題就非常簡單了。因為這種特徵已經具有了相同人對應的向量的距離小,不同人對應的向量距離大的特點,接下來,一般的應用有以下幾類:
- 人臉驗證(Face Identification)。就是檢測A、B是否屬於同一個人。只需要計算向量之間的距離,設定合適的報警閾值(threshold)即可。
- 人臉識別(Face Recognition)。這個應用是最多的,給定一張圖片,檢測資料庫中與之最相似的人臉。顯然可以被轉換為一個求距離的最近鄰問題。
- 人臉聚類(Face Clustering)。在資料庫中對人臉進行聚類,直接用K-means即可。
&n