
[ch04-03] 用神經網路解決線性迴歸問題
系列部落格,原文在筆者所維護的github上:https://aka.ms/beginnerAI,
點選star加星不要吝嗇,星越多筆者越努力。
4.3 神經網路法
在梯度下降法中,我們簡單講述了一下神經網路做線性擬合的原理,即:
- 初始化權重值
- 根據權重值放出一個解
- 根據均方差函式求誤差
- 誤差反向傳播給線性計算部分以調整權重值
- 是否滿足終止條件?不滿足的話跳回2
一個不恰當的比喻就是穿糖葫蘆:桌子上放了一溜兒12個紅果,給你一個足夠長的竹籤子,選定一個角度,在不移動紅果的前提下,想辦法用竹籤子穿起最多的紅果。
最開始你可能會任意選一個方向,用竹籤子比劃一下,數數能穿到幾個紅果,發現是5個;然後調整一下竹籤子在桌面上的水平角度,發現能穿到6個......最終你找到了能穿10個紅果的的角度。
4.3.1 定義神經網路結構
我們是首次嘗試建立神經網路,先用一個最簡單的單層單點神經元,如圖4-4所示。
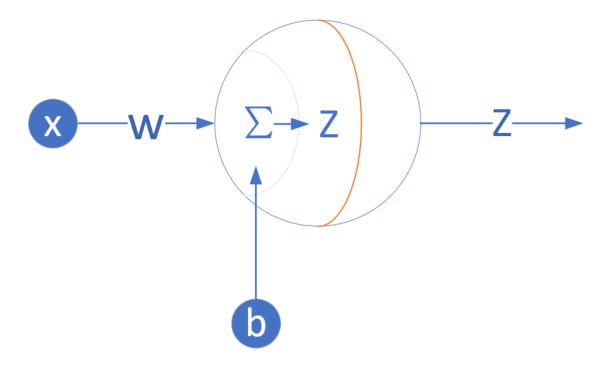
圖4-4 單層單點神經元
下面,我們用這個最簡單的線性迴歸的例子,來說明神經網路中最重要的反向傳播和梯度下降的概念、過程以及程式碼實現。
輸入層
此神經元在輸入層只接受一個輸入特徵,經過引數w,b的計算後,直接輸出結果。這樣一個簡單的“網路”,只能解決簡單的一元線性迴歸問題,而且由於是線性的,我們不需要定義啟用函式,這就大大簡化了程式,而且便於大家循序漸進地理解各種知識點。
嚴格來說輸入層在神經網路中並不能稱為一個層。
權重w/b
因為是一元線性問題,所以w/b都是一個標量。
輸出層
輸出層1個神經元,線性預測公式是:
\[z_i = x_i \cdot w + b\]
z是模型的預測輸出,y是實際的樣本標籤值,下標 \(i\) 為樣本。
損失函式
因為是線性迴歸問題,所以損失函式使用均方差函式。
\[loss(w,b) = \frac{1}{2} (z_i-y_i)^2\]
4.3.2 反向傳播
由於我們使用了和上一節中的梯度下降法同樣的數學原理,所以反向傳播的演算法也是一樣的,細節請檢視4.2.2。
計算w的梯度
\[ {\partial{loss} \over \partial{w}} = \frac{\partial{loss}}{\partial{z_i}}\frac{\partial{z_i}}{\partial{w}}=(z_i-y_i)x_i \]
計算b的梯度
\[ \frac{\partial{loss}}{\partial{b}} = \frac{\partial{loss}}{\partial{z_i}}\frac{\partial{z_i}}{\partial{b}}=z_i-y_i \]
為了簡化問題,在本小節中,反向傳播使用單樣本方式,在下一小節中,我們將介紹多樣本方式。
4.3.3 程式碼實現
其實神經網路法和梯度下降法在本質上是一樣的,只不過神經網路法使用一個嶄新的程式設計模型,即以神經元為中心的程式碼結構設計,這樣便於以後的功能擴充。
在Python中可以使用面嚮物件的技術,通過建立一個類來描述神經網路的屬性和行為,下面我們將會建立一個叫做NeuralNet的class,然後通過逐步向此類中新增方法,來實現神經網路的訓練和推理過程。
定義類
class NeuralNet(object):
def __init__(self, eta):
self.eta = eta
self.w = 0
self.b = 0NeuralNet類從object類派生,並具有初始化函式,其引數是eta,也就是學習率,需要呼叫者指定。另外兩個成員變數是w和b,初始化為0。
前向計算
def __forward(self, x):
z = x * self.w + self.b
return z這是一個私有方法,所以前面有兩個下劃線,只在NeuralNet類中被呼叫,不對外公開。
反向傳播
下面的程式碼是通過梯度下降法中的公式推導而得的,也設計成私有方法:
def __backward(self, x,y,z):
dz = z - y
db = dz
dw = x * dz
return dw, dbdz是中間變數,避免重複計算。dz又可以寫成delta_Z,是當前層神經網路的反向誤差輸入。
梯度更新
def __update(self, dw, db):
self.w = self.w - self.eta * dw
self.b = self.b - self.eta * db每次更新好新的w和b的值以後,直接儲存在成員變數中,方便下次迭代時直接使用,不需要在全域性範圍當作引數內傳來傳去的。
訓練過程
只訓練一輪的演算法是:
for 迴圈,直到所有樣本資料使用完畢:
- 讀取一個樣本資料
- 前向計算
- 反向傳播
- 更新梯度
def train(self, dataReader):
for i in range(dataReader.num_train):
# get x and y value for one sample
x,y = dataReader.GetSingleTrainSample(i)
# get z from x,y
z = self.__forward(x)
# calculate gradient of w and b
dw, db = self.__backward(x, y, z)
# update w,b
self.__update(dw, db)
# end for推理預測
def inference(self, x):
return self.__forward(x)推理過程,實際上就是一個前向計算過程,我們把它單獨拿出來,方便對外介面的設計,所以這個方法被設計成了公開的方法。
主程式
if __name__ == '__main__':
# read data
sdr = SimpleDataReader()
sdr.ReadData()
# create net
eta = 0.1
net = NeuralNet(eta)
net.train(sdr)
# result
print("w=%f,b=%f" %(net.w, net.b))
# predication
result = net.inference(0.346)
print("result=", result)
ShowResult(net, sdr)4.3.4 執行結果視覺化
列印輸出結果:
w=1.716290,b=3.196841
result= [3.79067723]最終我們得到了W和B的值,對應的直線方程是\(y=1.71629x+3.196841\)。推理預測時,已知有346臺伺服器,先要除以1000,因為橫座標是以K(千臺)伺服器為單位的,代入前向計算函式,得到的結果是3.74千瓦。
結果顯示函式:
def ShowResult(net, dataReader):
......對於初學神經網路的人來說,視覺化的訓練過程及結果,可以極大地幫助理解神經網路的原理,Python的Matplotlib庫提供了非常豐富的繪圖功能。
在上面的函式中,先獲得所有樣本點資料,把它們繪製出來。然後在[0,1]之間等距設定10個點做為x值,用x值通過網路推理方法net.inference()獲得每個點的y值,最後把這些點連起來,就可以畫出圖4-5中的擬合直線。
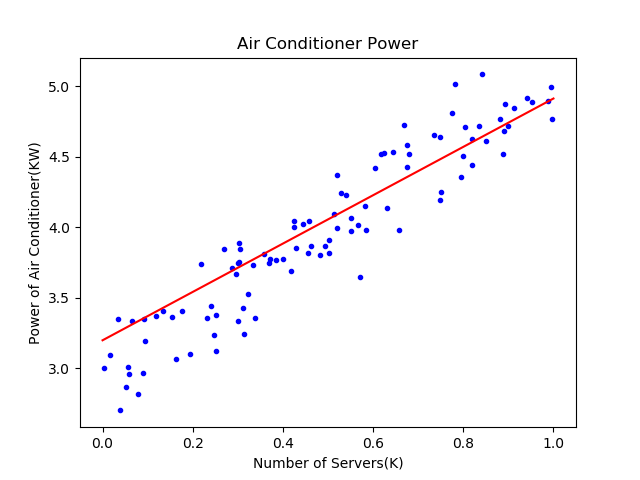
圖4-5 擬合效果
可以看到紅色直線雖然穿過了藍色點陣,但是好像不是處於正中央的位置,應該再逆時針旋轉幾度才會達到最佳的位置。我們後面小節中會講到如何提高訓練結果的精度問題。
4.3.5 工作原理
就單純地看待這個線性迴歸問題,其原理就是先假設樣本點是呈線性分佈的,注意這裡的線性有可能是高維空間的,而不僅僅是二維平面上的。但是高維空間人類無法想象,所以我們不妨用二維平面上的問題來舉例。
在4.2的梯度下降法中,首先假設這個問題是個線性問題,因而有了公式\(z=xw+b\),用梯度下降的方式求解最佳的\(w、b\)的值。
在本節中,用神經元的程式設計模型把梯度下降法包裝了一下,這樣就進入了神經網路的世界,從而可以有成熟的方法論可以解決更復雜的問題,比如多個神經元協同工作、多層神經網路的協同工作等等。
如圖4-5所示,樣本點擺在那裡,位置都是固定的了,神經網路的任務就是找到一根直線(注意我們首先假設這是線性問題),讓該直線穿過樣本點陣,並且所有樣本點到該直線的距離的平方的和最小。
可以想象成每一個樣本點都有一根橡皮筋連線到直線上,連線點距離該樣本點最近,所有的橡皮筋形成一個合力,不斷地調整該直線的位置。該合力具備兩種調節方式:
- 如果上方的拉力大一些,直線就會向上平移一些,這相當於調節b值;
- 如果側方的拉力大一些,直線就會向側方旋轉一些,這相當於調節w值。
直到該直線處於平衡位置時,也就是線性擬合的最佳位置了。
如果樣本點不是呈線性分佈的,可以用直線擬合嗎?
答案是“可以的”,只是最終的效果不太理想,誤差可以做到線上性條件下的最小,但是誤差值本身還是比較大的。比如一個半圓形的樣本點陣,用直線擬合可以達到誤差值最小為1.2(不妨假設這個值的單位是釐米),已經盡力了但能力有限。如果用弧線去擬合,可以達到誤差值最小為0.3。
所以,當使用線性迴歸的效果不好時,即判斷出一個問題不是線性問題時,我們會用第9章的方法來解決。
程式碼位置
ch04, Level3
思考和練習
- 請把上述程式碼中的dw和db也改成私有屬性,然後試著執行程式。