
目標檢測 1 : 目標檢測中的Anchor詳解
鹹魚了半年,年底了,把這半年做的關於目標的檢測的內容總結下。
本文主要有兩部分:
- 目標檢測中的邊框表示
- Anchor相關的問題,R-CNN,SSD,YOLO 中的anchor
目標檢測中的邊框表示
目標檢測中,使用一個矩形的邊框來表示。在影象中,可以基於影象座標系使用多種方式來表示矩形框。
- 最直接的方式,使用矩形框的左上角和右下角在影象座標系中的座標來表示。

使用絕對座標的\((x_{min},y_{min},x_{max},y_{max})\)。 但是這種絕對座標的表示方式,是以原始影象的畫素值為基礎的,這就需要知道影象的實際尺度,如果影象進行縮放,這種表示就無法準確的進行定位了。
- 對影象的尺寸進行歸一化,使用歸一化後的座標矩形框

座標進行歸一化,這樣只要知道影象的scale就能夠很容易在當前尺度下使用矩形框定位。
- 中心座標的表示方式
使用中心座標和矩形框的寬和高的形式表示矩形框。

\((c_x,c_y,w,h)\)這種方式很明確的指出來矩形框的大小。
在目標檢測中,訓練資料的額標籤通常是基於絕對座標的表示方式的,而在訓練的過程中通常會有尺度的變換這就需要將邊框座標轉換為歸一化後的形式。
在計算損失值時,為了平衡尺寸大的目標和尺寸小的目標對損失值的影響,就需要將矩形框表示為中心座標的方式,以方便對矩形框的寬和高新增權重。
最後,要將歸一化後的中心座標形式轉換為檢測影象的原始尺度上。
Anchor Box
預定義邊框就是一組預設的邊框,在訓練時,以真實的邊框位置相對於預設邊框的偏移來構建
訓練樣本。 這就相當於,預設邊框先大致在可能的位置“框“出來目標,然後再在這些預設邊框的基礎上進行調整。
為了儘可能的框出目標可能出現的位置,預定義邊框通常由上千個甚至更多,在深度學習之前,通常使用各種形狀的“滑動視窗”,在原影象滑動,來產不同位置不同形狀的預設邊框。
到了深度學習時期,由於對影象特徵提取技術的進步,可以使用Anchor Box在影象的不同位置生成邊框,並且能夠方便的提取邊框對應區域的特徵,用於邊框位置的迴歸。
一個Anchor Box可以由:邊框的縱橫比和邊框的面積(尺度)來定義,相當於一系列預設邊框的生成規則,根據Anchor Box,可以在影象的任意位置,生成一系列的邊框。
由於Anchor box 通常是以CNN提取到的Feature Map 的點為中心位置,生成邊框,所以一個Anchor box不需要指定中心位置。
總結來說就是:在一幅影象中,要檢測的目標可能出現在影象的任意位置,並且目標可能是任意的大小和任意形狀。
- 使用CNN提取的Feature Map的點,來定位目標的位置。
- 使用Anchor box的Scale來表示目標的大小
- 使用Anchor box的Aspect Ratio來表示目標的形狀
常用的Anchor Box定義
- Faster R-CNN 定義三組縱橫比
ratio = [0.5,1,2]和三種尺度scale = [8,16,32],可以組合處9種不同的形狀和大小的邊框。 - YOLO V2 V3 則不是使用預設的縱橫比和尺度的組合,而是使用
k-means聚類的方法,從訓練集中學習得到不同的Anchor - SSD 固定設定了5種不同的縱橫比
ratio=[1,2,3,1/2,1/3],由於使用了多尺度的特徵,對於每種尺度只有一個固定的scale
Anchor 的意義
Anchor Box的生成是以CNN網路最後生成的Feature Map上的點為中心的(映射回原圖的座標),以Faster R-CNN為例,使用VGG網路對對輸入的影象下采樣了16倍,也就是Feature Map上的一個點對應於輸入影象上的一個\(16 \times 16\)的正方形區域(感受野)。根據預定義的Anchor,Feature Map上的一點為中心 就可以在原圖上生成9種不同形狀不同大小的邊框,如下圖:
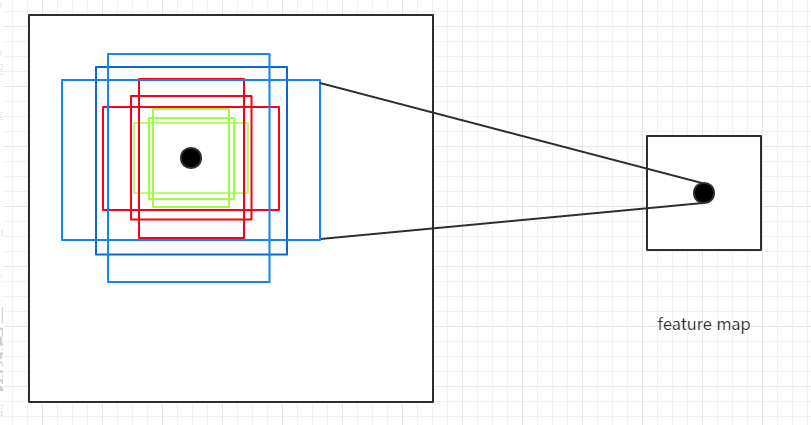
從上圖也可以看出為什麼需要Anchor。根據CNN的感受野,一個Feature Map上的點對應於原圖的\(16 \times 16\)的正方形區域,僅僅利用該區域的邊框進行目標定位,其精度無疑會很差,甚至根本“框”不到目標。 而加入了Anchor後,一個Feature Map上的點可以生成9中不同形狀不同大小的框,這樣“框”住目標的概率就會很大,就大大的提高了檢查的召回率;再通過後續的網路對這些邊框進行調整,其精度也能大大的提高。
Faster R-CNN的Anchor Box
Faster R-CNN中的Anchor有3種不同的尺度\({128\times 128,256 \times 256,512 \times 512}\),3種形狀也就是不同的長寬比\(W:H = {1:1,1:2,2:1}\),這樣Feature Map中的點就可以組合出來9個不同形狀不同尺度的Anchor Box。
Faster R-CNN進行Anchor Box生成的Feature Map是原圖下采樣16倍得到的,這樣不同的長寬比實際上是將面積為\(16 \times 16\)的區域,拉伸為不同的形狀,如下圖:
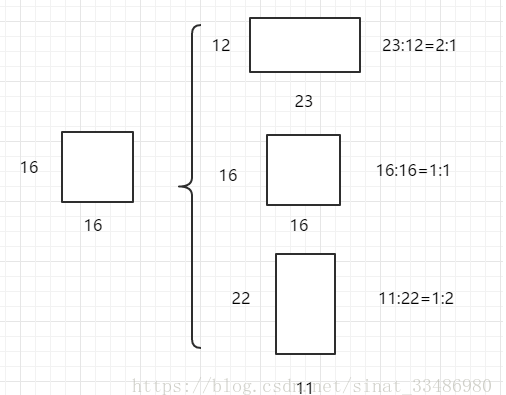
不同的ratio生成的邊框的面積是相同的,具有相同的大小。三種不同的面積(尺度),實際上是將上述面積為\(16 \times 16\)的區域進行放大或者縮小。
\(128 \times 128\)是\(16 \times 16\)放大8倍;\(256 \times 256\)是放大16倍;\(512 \times 512\)則是放大32倍。如下圖:
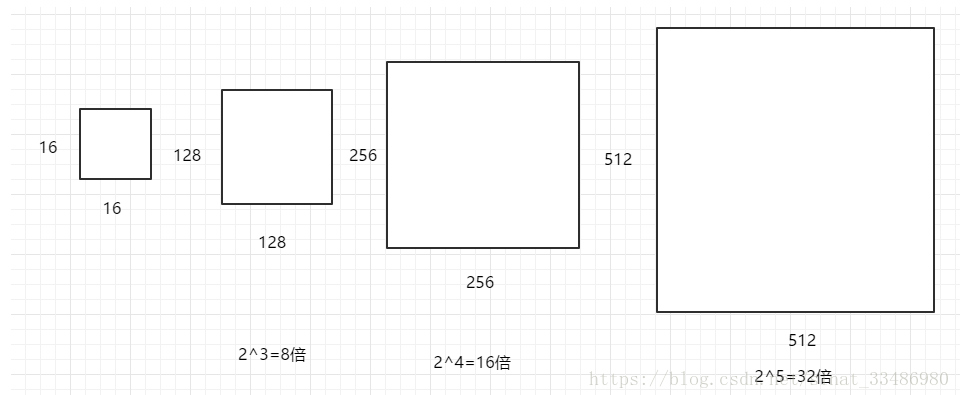
上圖引用自: https://blog.csdn.net/sinat_33486980/article/details/81099093
Anchor 計算
這裡先計算每個Anchor的長和寬,至於其中心位置是Feature Map的每個點在原圖上的對映,是固定,可以先不考慮。
從上面可以知道,任意的形狀和大小的Anchor的寬和高都可以從最基礎的寬和高\(16 \times 16\)變換而來。首先看三種ratio的變換。
設矩形框的面積\(s = 16 \times 16\),矩形框的寬\(w\),高為\(h\),則有:
\[
\left \{
\begin{array}{c}
w \times h = s\\ \frac{w}{h} = ratio
\end{array}
\right. =>
\left\{ \begin{array}{c}
w = ratio \cdot h \\ ratio \times h^2 = s
\end{array} \right.
\]
所以最終得到
\[
\left\{
\begin{array}{c}
h = \sqrt{s / ratio} \\
w = ratio \cdot h = \sqrt{s \cdot ratio}
\end{array}
\right.
\]
不同尺度的是在基礎的尺度上的縮放,設尺度為\(scale\),則縮放後的面積為\(scale \cdot s\)。當然也可以從寬高的縮放比例來看,基礎的面積為\(16 \times 16\),則尺度為$128 \times 128 \(則是相當於長寬高各放大了3倍。只是要注意數值的變換,從面積的角度看縮放因子為\)scale_{area} = (128 \times 128) / (16 \times 16)$,從寬高看的話,縮放因子為寬高的比值。
\[ \left\{ \begin{array}{c} h = \sqrt{scale \cdot s / ratio} \\ w = ratio \cdot h = \sqrt{scale \cdot s \cdot ratio} \end{array} \right. \]
通過上面的計算,實際只是得到了9種不同的可以放在任意位置矩形框(因為矩形框的中心位置還沒有確定)。 邊框的中心位置,是將Feature map上的點映射回原圖得到的,Feature map任一點對應的是原圖的一塊正方形區域,其中心位置就落在改區域的中心位置。以
以Feature map上\((0,0)\)點為例,其對應於原圖的\((0,0,15,15)\)(左上角座標,右下角座標),則在改點生成Anchor box的中心點就是原圖的\((7.5,7.5)\),Feature Map上其餘位置在原圖對應的中心點在此基礎上進行平移即可得到。例如Feature Map上(0,0)的點在原圖上對應區域的的中心點為(7.5,7.5),則(0,1)對應的中心點為(7.5,7.5 + 16),依次類推(x,y)對應的中心點為(x * 16 + 7.5 ,y * 16 + 7.5)。
如果是以(左上角座標,右下角座標)表示的矩形框,則將(左上角座標,右下角座標)平移相應的距離即可。
SSD的 default Prior box
SSD的Prior Box的三要素:
Feature Map
為了能夠更好的檢測小目標,SSD使用不同層的Feature Map(不同尺度)。具體就是:\(38 \times 38,19 \ times 19,10 \times 10 ,5 \times 5,3 \times 3,1\times 1\)- Scale
- 假設一個prior box的scale為\(s\),這就表示該prior box的面積是以\(s\)為邊長的正方形的面積。
- scale的值是以相對於原始影象的邊長比例來設定的。 例如$ s= 0.1\(,則表示實際\)s = 0.1 \cdot W_src$。
- SSD中使用了多個不同尺度的Feature Map。針對不同的Feature Map,設定不同的尺度。除了第一個Feature Map(\(38 \times 38\))的\(scale = 0.1\),剩餘各層的按照Feature Map的尺度從大大小排列,其scale按照下面的公式增大
\[ scale = s_{min} + \frac{s_{max} - s_{min}}{ m - 1} \cdot (k - 1), \]
其中,\(m = 5 ,k = 1,2,3,4,5,s_{min} = 0.2,s_{max} = 0.9\)
可以看到,尺度大的Feature Map其scale較小,利於小目標的檢測。
Aspect Ratio
每個尺度的Feature Map的prior box都有\((1:1,2:1,1:2)\)這三種aspect ratio。其中,\(19 \times 19,10 \times 10,5 \times 5\)這三個Feature Map則有額外的兩個aspect ratio \((1:3,3:1)\)。附加的prior box
針對所有的Feature Map 都有一個附加的 prior box,其aspect ratio為\(1:1\),其尺度為當前Feature Map 和下一個Feature Map的幾何平均值,也就是\(\sqrt(scale_k \cdot scale_{k+1})\)
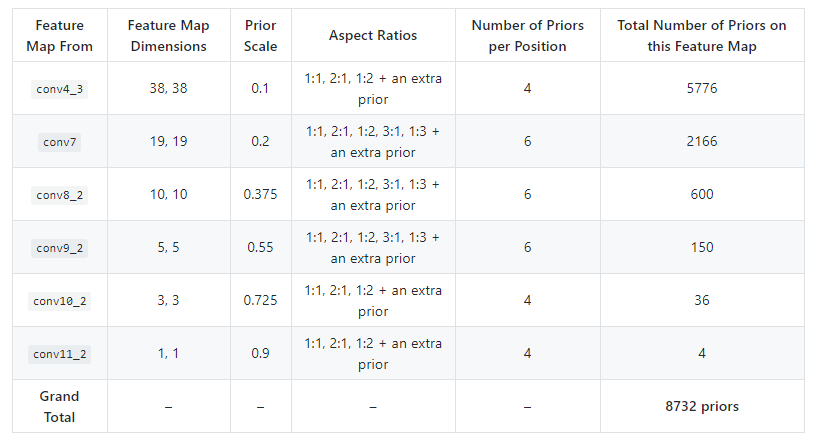
SSD的Prior box的總結如下:
YOLO 的Anchor Box
YOLO v2,v3的Anchor Box 的大小和形狀是通過對訓練資料的聚類得到的。 作者發現如果採用標準的k-means(即用歐式距離來衡量差異),在box的尺寸比較大的時候其誤差也更大,而我們希望的是誤差和box的尺寸沒有太大關係。這裡的意思是不能直接使用\(x,y,w,h\)這樣的四維資料來聚類,因為框的大小不一樣,這樣大的定位框的誤差可能更大,小的定位框誤差會小,這樣不均衡,很難判斷聚類效果的好壞。
所以通過IOU定義瞭如下的距離函式,使得誤差和box的大小無關:
\[
d(box,centroid) = 1 - IOU(box,centroid)
\]
官方的 V2,V3的Anchor
anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828 // yolo v2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 // yolo v3需要注意的是 anchor計算的尺度問題。 yolo v2的是相對最後一個Feature Map \((13 \times 13)\)來的,yolo v3則是相對於原輸入影象的\(416 \times 416\)的。 這也是在計算目標檢測中,邊框計算中需要注意的問題,就是計算的邊框究竟在相對於那個尺度得出的。
So YOLOv2 I made some design choice errors, I made the anchor box size be relative to the feature size in the last layer. Since the network was downsampling by 32 this means it was relative to 32 pixels so an anchor of 9x9 was actually 288px x 288px.
In YOLOv3 anchor sizes are actual pixel values. this simplifies a lot of stuff and was only a little bit harder to implement
總結
Anchor box 實際上就是用來生成一系列先驗框的規則,其生成的先驗框有以下三部分構成:
- CNN提取的Feature Map的點,來定位邊框的位置。
- Anchor box的Scale來表示邊框的大小
- Anchor box的Aspect Ratio來表示邊框的形狀
在one stage中的目標檢測,是直接在最後提取的Feature map上使用預定義的Anchor生成一系列的邊框,最後再對這些邊框進行迴歸。
而 two stage中的,提取的Feature map上使用預定義的Anchor生成一系列的邊框,這些邊框經過RPN網路,生成一些的ROI區域。將提取到的ROI輸入到後續網路中進行邊框迴歸,這就比one stage的方法多了一步,所以精度和耗時上都有所增加。
最後,在使用Anchor生成邊框的時候,要注意其定義在那種尺度上,最好將生成的邊框使用歸一化的座標表示,在使用的時候,乘以原影象的尺度就行了