
圖解 kubernetes scheduler 架構設計系列-初步瞭解
資源排程基礎
scheudler是kubernetes中的核心元件,負責為使用者宣告的pod資源選擇合適的node,同時保證叢集資源的最大化利用,這裡先介紹下資源排程系統設計裡面的一些基礎概念
基礎任務資源排程
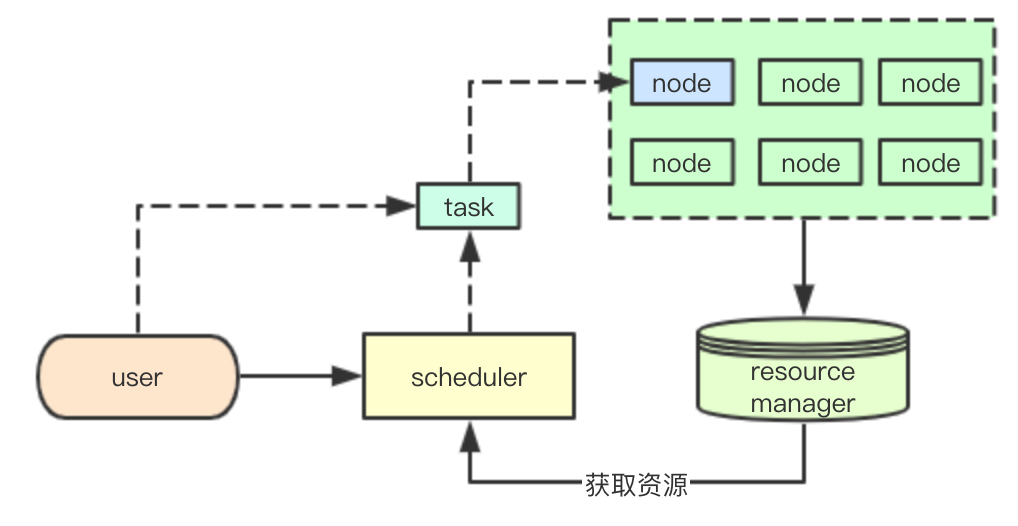
基礎的任務資源排程通常包括三部分:
| 角色型別 | 功能 |
|---|---|
| node | node負責具體任務的執行,同時對包彙報自己擁有的資源 |
| resource manager | 彙總當前叢集中所有node提供的資源,供上層的scheduler的呼叫獲取,同時根據node彙報的任務資訊來進行當前叢集資源的更新 |
| scheduler | 結合當前叢集的資源和使用者提交的任務資訊,選擇合適的node節點當前的資源,分配節點任務,儘可能保證任務的執行 |
通用的排程框架往往還會包含一個上層的叢集管理器,負責針對叢集中scheduler的管理和資源分配工作,同時負責scheduler叢集狀態甚至resource manager的儲存
資源排程設計的挑戰
資源:叢集資源利用的最大化與平均
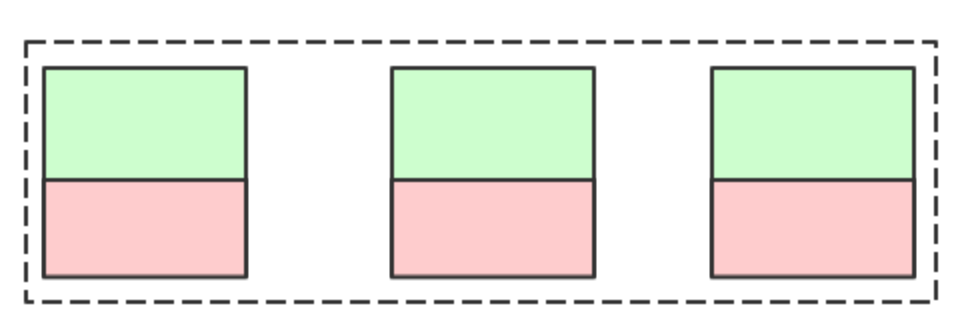
傳統的IDC叢集資源利用:
在IDC環境中我們通常希望機器利用率能夠平均,讓機器保持在某個平均利用率,然後根據資源的需要預留足夠的buffer, 來應對叢集的資源利用高峰,畢竟採購通常都有周期,我們既不能讓機器空著,也不能讓他跑滿(業務無法彈性)
雲環境下的資源利用:
而云環境下我們可以按需分配,而且雲廠商通常都支援秒級交付,那其實下面的這種資源利用率其實也可以
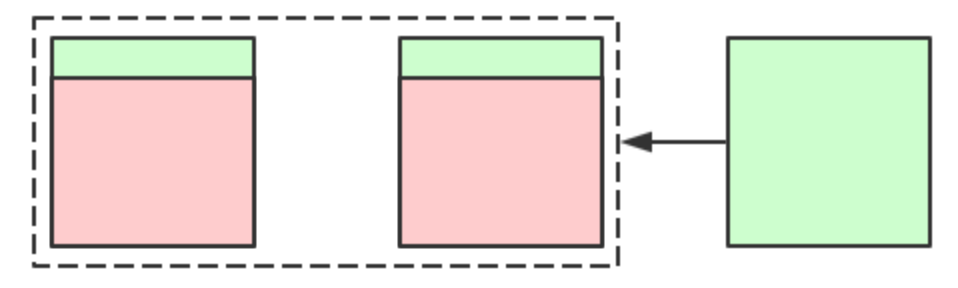
可以看到僅僅是環境的不一致,就可能會導致不同的排程結果,所有針對叢集資源利用最大化這個目標,其實會有很多的不同
排程: 任務最少等待時間與優先順序
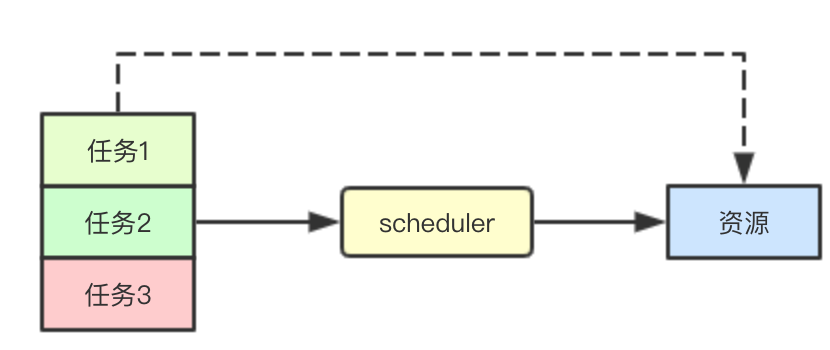
在叢集任務繁忙的時候,可能會導致叢集資源部足以分配給當前叢集中的所有任務,在讓所有任務都能夠儘快完成的同時,我們還要保證高優先順序的任務優先被完成
排程: 任務本地性
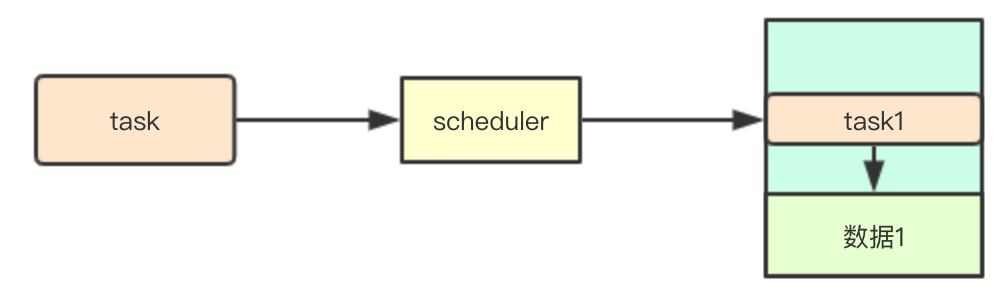
本地性是指在大資料處理中常用的一種機制,其核心是儘可能將任務分配到包含其任務執行資源的節點上,避免資料的複製
叢集: 高可用性
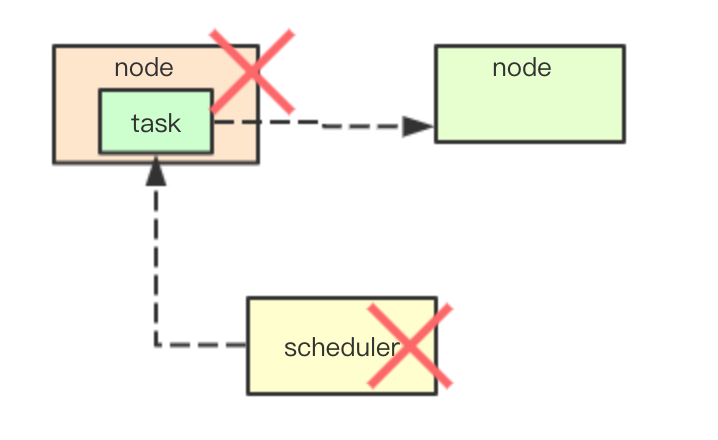
在排程過程中可能由於硬體、系統或者軟體導致任務的不可用,通常會由需要一些高可用機制,來保證當前叢集不會因為部分節點宕機而導致整個系統不可用
系統: 可擴充套件性
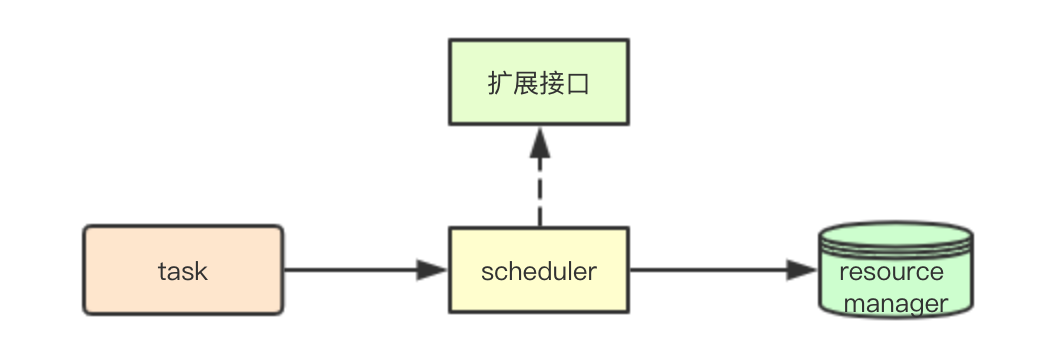
擴充套件機制主要是指的,系統如何如何應對業務需求的變化,提供的一種可擴充套件機制,在叢集預設排程策略不滿足業務需求時,通過擴充套件介面,來進行系統的擴充套件滿足業務需求
Pod排程場景的挑戰
Pod排程場景其實可以看做一類特殊的任務,除了上面資源排程的挑戰,還有一些針對pod排程這個具體的場景(有些是共同的,這裡通過pod來描述會比較清晰)
親和與反親和
在kubernetes中的親和性主要體現pod和node兩種資源,主要體現在兩個方面:
1.親和性: 1)pod之間的親和性 2)pod與node之間的親和性
2.反親和: 1)pod之間的反親和性 2)pod與node之間的反親和
簡單舉例:
1.pod之間的反親和: 為了保證高可用我們通常會將同一業務的多個節點分散在不通的資料中心和機架
2.pod與node親和性: 比如某些需要磁碟io操作的pod,我們可以排程到具有ssd的機器上,提高IO效能
多租戶與容量規劃
多租戶通常是為了進行叢集資源的隔離,在業務系統中,通常會按照業務線來進行資源的隔離,同時會給業務設定對應的容量,從而避免單個業務線資源的過度使用影響整個公司的所有業務
Zone與node選擇
zone通常是在業務容災中常見的概念,通過將服務分散在多個數據中心,避免因為單個數據中心故障導致業務完全不可用
因為之前親和性的問題,如何在多個zone中的所有node中選擇出一個合適的節點,則是一個比較大的挑戰
多樣化資源的擴充套件
系統資源除了cpu、記憶體還包括網路、磁碟io、gpu等等,針對其餘資源的分配排程,kubernetes還需要提供額外的擴充套件機制來進行排程擴充套件的支援
資源混部
kubernetes初期是針對pod排程場景而生,主要其實是線上web業務,這類任務的特點大部分都是無狀態的,那如何針對離線場景的去支援離線的批處理計算等任務
kubernetes中的排程初識
中心化資料集中儲存
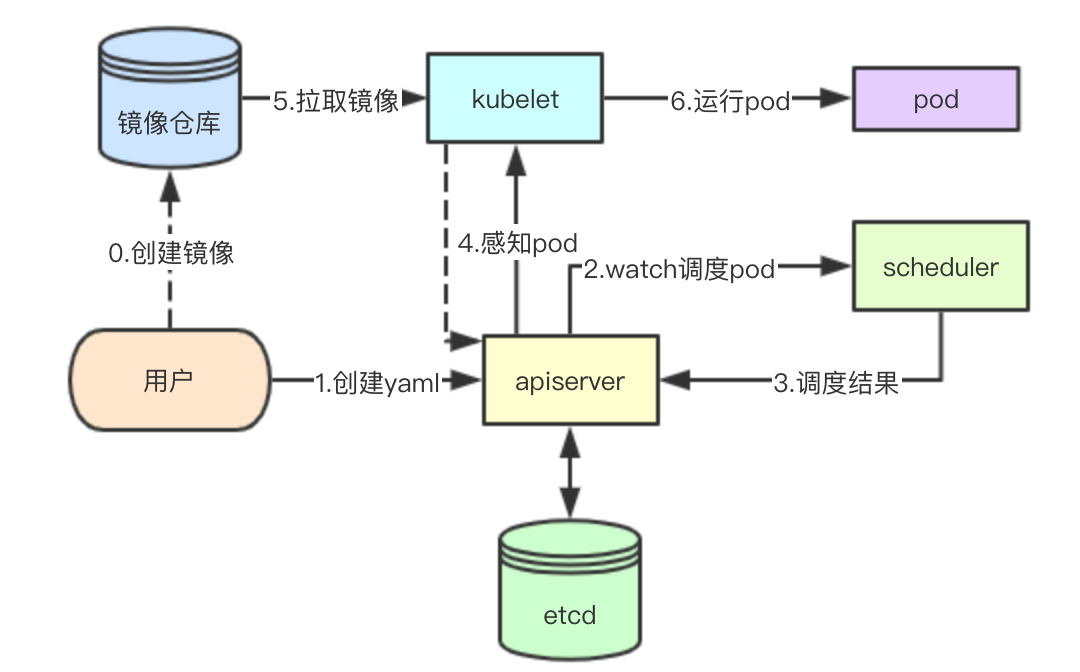
中心化的資料儲存
kubernetes是一個數據中心化儲存的系統,叢集中的所有資料都通過apiserver儲存到etcd中,包括node節點的資源資訊、節點上面的pod資訊、當前叢集的所有pod資訊,在這裡其實apiserver也充當了resource manager的角色,儲存所有的叢集資源和已經分配的資源
排程資料的儲存與獲取
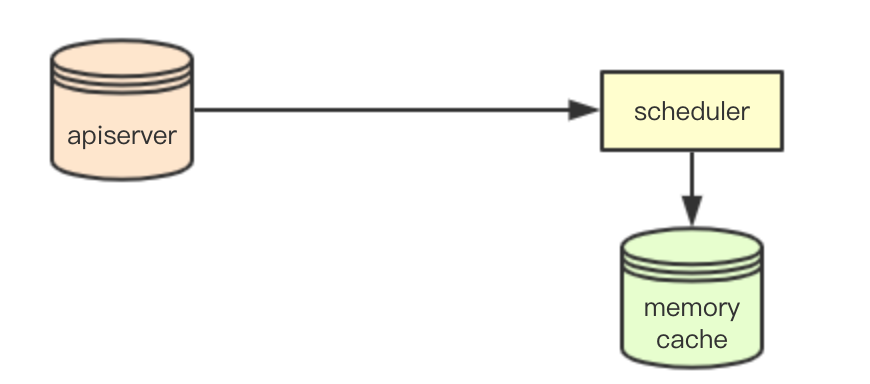
kubernetes中採用了一種list watch的機制,用於叢集中其他節點從apiserver感知資料,scheduler也採用該機制,通過在感知apiserver的資料變化,同時在本地memory中構建一份cache資料(資源資料),來提供排程使用,即SchedulerCache
scheduler的高可用
大多數系統的高可用機制都是通過類似zookeeper、etcd等AP系統實現,通過臨時節點或者鎖機制機制來實現多個節點的競爭,從而在主節點宕機時,能夠快速接管, scheduler自然也是這種機制,通過apiserver底層的etcd來實現鎖的競爭,然後通過apiserver的資料,就可以保證排程器的高可用
排程器內部組成
排程佇列
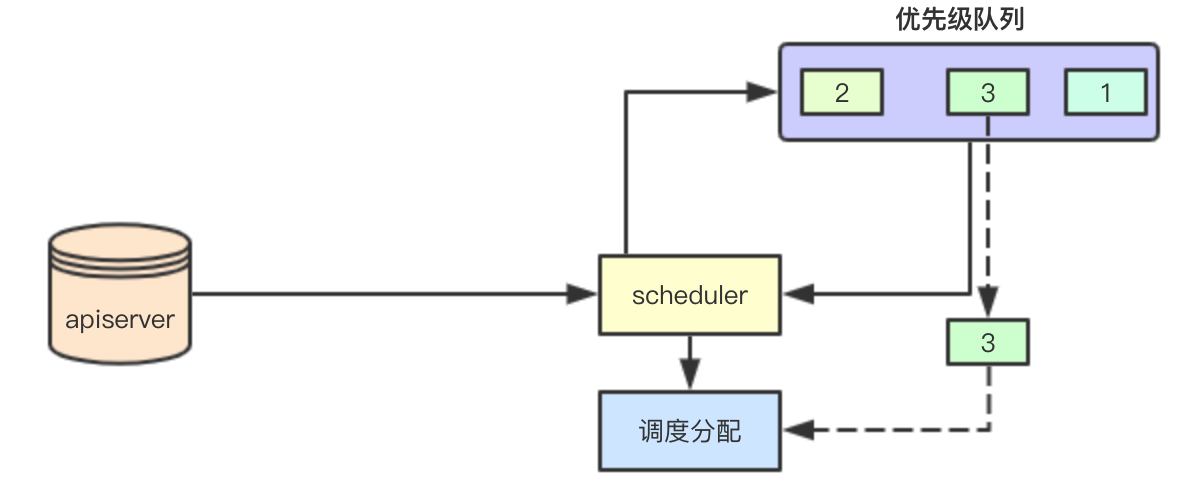
當從apiserver感知到要排程的pod的時候,scheduler會根據pod的優先順序,來講其加入到內部的一個優先順序佇列中,後續排程的時候,會先獲取優先順序比較高的pod來進行優先滿足排程
這裡還有一個點就是如果優先排程了優先順序比較低的pod,其實在後續的搶佔過程中,也會被驅逐出去
排程與搶佔排程
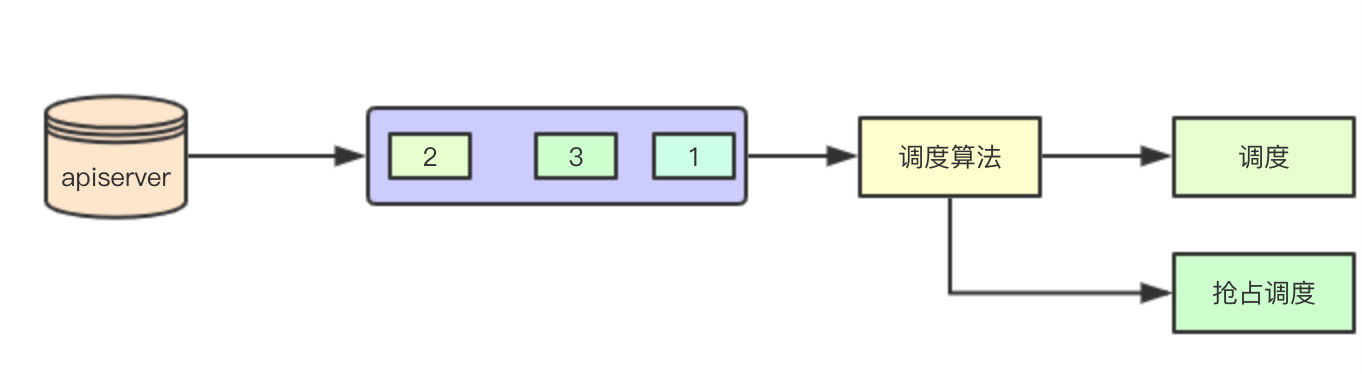
前面提到過搶佔,kubernetes預設會對所有的pod來嘗試進行排程,當叢集資源部滿足的時候,則會嘗試搶佔排程,通過搶佔排程,為高優先順序的pod來進行優先排程 其核心都是通過排程演算法實現即ScheduleAlgorithm
這裡的排程演算法實際上是一堆排程演算法和排程配置的集合
外部擴充套件機制
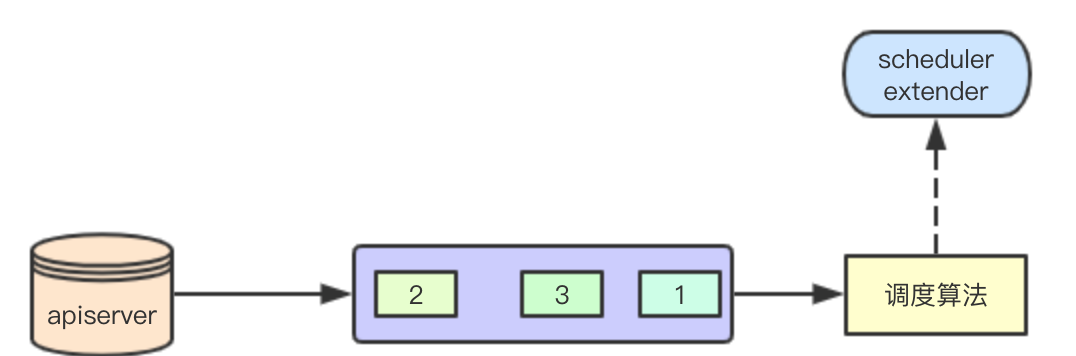
scheduler extender是k8s對排程器的一種擴充套件機制,我們可以定義對應的extender,在對應資源的排程的時候,k8s會檢查對應的資源,如果發現需要呼叫外部的extender,則將當前的排程資料傳送給extender,然後彙總排程資料,決定最終的排程結果
內部擴充套件機制
上面提到排程演算法是一組排程演算法和排程配置的集合,kubernetes scheduler framework是則是一個框架宣告對應外掛的介面,從而支援使用者編寫自己的plugin,來影響排程決策,個人感覺這並不是一種好的機制,因為要修改程式碼,或者通過修改kubernetes scheduler啟動來進行自定義外掛的載入
排程基礎架構
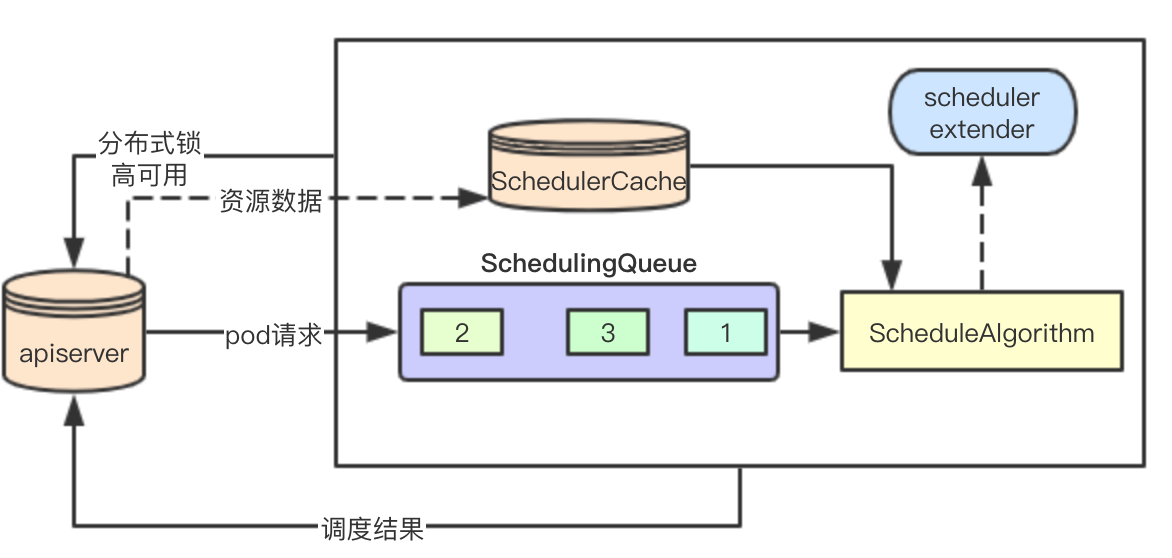
結合上面所說的就得到了一個最簡單的架構,主要排程流程分為如下幾部分:
0.通過apiserver來進行主節點選舉,成功者進行排程業務流程處理
1.通過apiserver感知叢集的資源資料和pod資料,更新本地schedulerCache
2.通過apiserver感知使用者或者controller的pod排程請求,加入本地排程佇列
3.通過排程演算法來進行pod請求的排程,分配合適的node節點,此過程可能會發生搶佔排程
4.將排程結果返回給apiserver,然後由kubelet元件進行後續pod的請求處理
這是一個最簡單的排程流程和基礎的元件模組,所以沒有原始碼,後續這個系列會詳細分析每個關鍵的排程資料結構和一些有趣的排程演算法的具體實現,祝我好運,good luck
微訊號:baxiaoshi2020

關注公告號閱讀更多原始碼分析文章
更多文章關注 www.sreguide.com
本文由部落格一文多發平臺 OpenWrite 釋出