
Cassandra資料建模中最重要的事情:主鍵
Cassandra資料建模中要了解的最重要的事情:主鍵
使用關係資料建模,您可以從主鍵開始,但是RDBMS中的有效資料模型更多地是關於表之間的外來鍵關係和關係約束。由於Cassandra無法使用JOIN,因此建立資料模型的複雜性要低得多。Apache Cassandra的複雜性折衷在於提前瞭解您的查詢和資料訪問模式。
1.簡單主鍵:
例子: student_id是person的主鍵
create table person (student_id int primary key, fname text, lname text, dateofbirth timestamp, email text, phone text );
2.複合鍵
- C1:主鍵只有一個分割槽鍵,沒有群集鍵。
- (C1,C2):列C1是分割槽鍵,列C2是群集鍵。
- (C1,C2,C3,...):列C1是分割槽鍵,列C2,C3等構成叢集鍵。
- (C1,(C2,C3,…)):與3相同,即C1列是分割槽鍵,C2,C3…列構成叢集鍵。
- (((C1,C2,...),(C3,C4,...))):列C1,C2作分割槽鍵,列C3,C4,…作群集鍵。
重要的是要注意,當複合鍵為C1,C2,C3時,第一個鍵C1成為分割槽鍵,其餘鍵成為群集鍵的一部分。為了製作複合分割槽鍵,我們必須在括號中指定鍵,例如:((C1,C2),C3,C4)。在這種情況下,C1和C2是分割槽鍵的一部分,而C3和C4是群集鍵的一部分。
1.分割槽鍵
分割槽鍵的目的是識別儲存該行的群集中的分割槽或節點。從群集讀取或寫入資料時,將使用一個名為Partitioner的函式來計算分割槽鍵的雜湊值。該雜湊值用於確定包含該行的節點/分割槽。
例如,分割槽鍵值範圍在1000到1234之間的行可以駐留在節點A中,而分割槽鍵值範圍在1235到2000之間的行可以駐留在節點B中,如圖1所示。值為1233,則將其儲存在節點A中。
2.叢集鍵
叢集鍵的目的是按排序順序儲存行資料。資料的排序基於列,這些列包含在叢集鍵中。這種安排使使用聚類金鑰檢索資料變得高效。
例子1
CREATE TABLE user_videos ( userid uuid, added_date timestamp, videoid uuid, name text, preview_image_location text, PRIMARY KEY (userid, added_date, videoid) ) WITH CLUSTERING ORDER BY (added_date DESC, videoid ASC); 分割槽userid,叢集鍵排序方式:added_date DESC, videoid ASC SELECT * FROM user_videos WHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89 LIMIT 10;
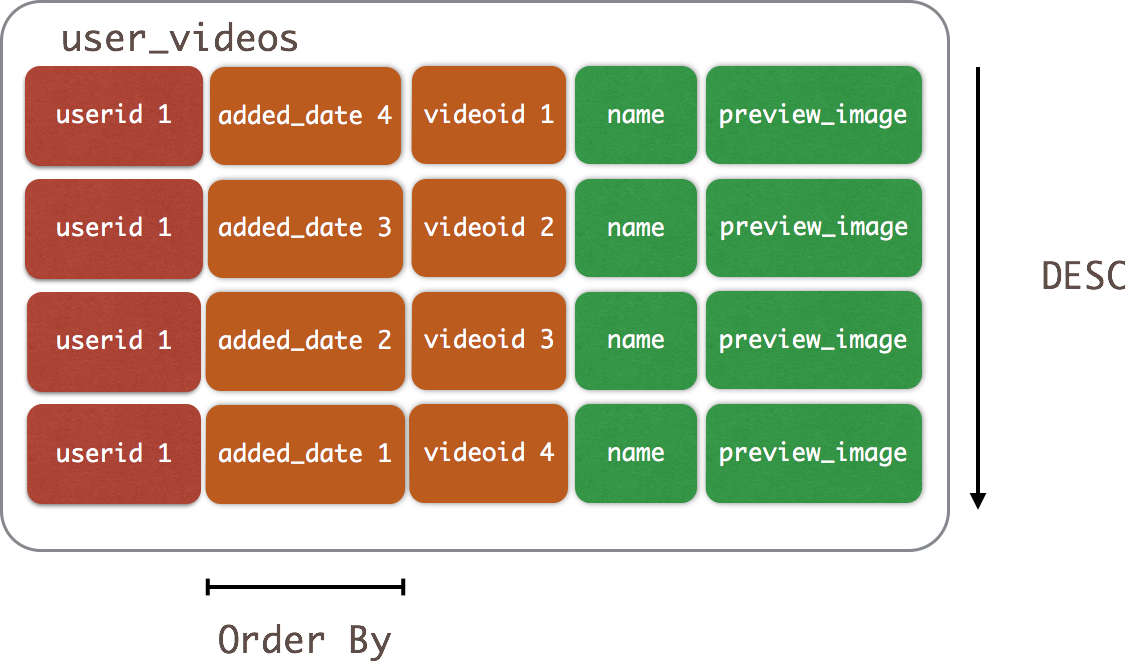
例子2
create table marks(stuid int,exam_date timestamp,marks float, exam_name text,
primary key (stuid,exam_date));分割槽stuid,預設exam_date升序排序
SELECT * FROM user_videos WHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89 LIMIT 10;
該查詢所要查詢的是“使用者上傳的最後10部視訊”,只需新增CLUSTERING ORDER BY子句即可實現非常快速,有用和高效的查詢。
這可能看起來像是預先優化的,但是此新增功能啟用的用例非常引人注目。
結論
Apache Cassandra的複雜性trade off在於提前瞭解您的查詢和資料訪問模式。(反模式的一種體現)
參考文章
https://dzone.com/articles/cassandra-data-modeling-primary-clustering-partiti
https://www.datastax.com/blog/2016/02/most-important-thing-know-cassandra-data-modeling-primary-