
資料量不足,MedicalNet 如何助力醫療影像 AI 突破瓶頸?
導讀 |近日,雲+社群技術沙龍“騰訊開源技術”圓滿落幕。本次沙龍邀請了多位騰訊技術專家,深度揭祕了騰訊開源專案TencentOS tiny、TubeMQ、Kona JDK、TARS以及MedicalNet。本文是陳思巨集老師關於致力於提供基於3D醫療影像大資料的預訓練模型MedicalNet的詳細介紹。
一、醫療影像AI概述
醫療影像 AI 實際上解決的是「患者看病難,醫生診斷累」的全球普遍問題。

由於培養投入大,週期長,醫護人員的數量在短時間內很難大幅度增加,而人工智慧技術可以輔助醫療工作,緩解當前醫護資源不足的狀況。
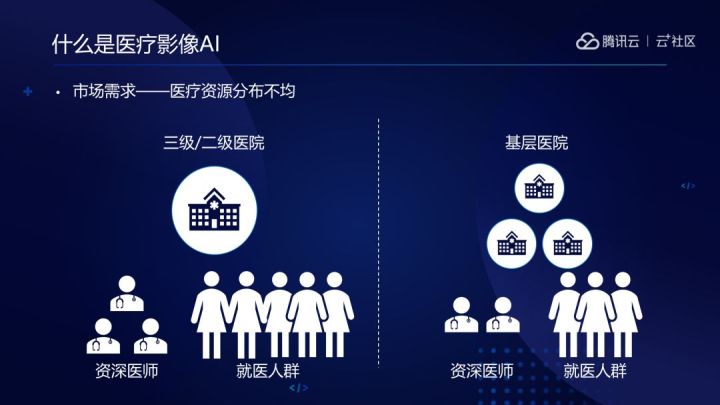
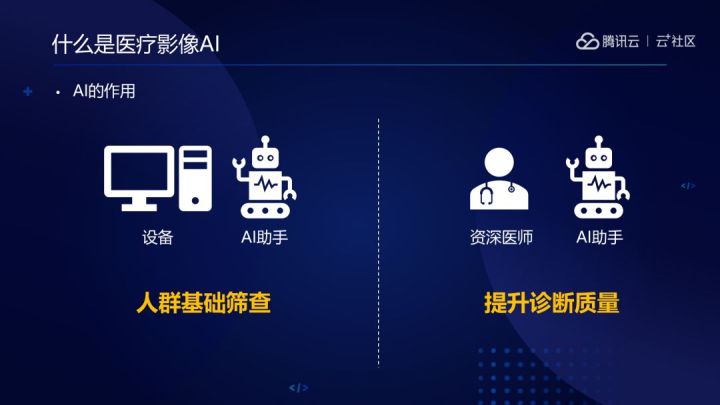
人工智慧對於醫療領域來說,主要有兩個作用,一個是進行人群基礎篩查,另一個是提升診斷質量。對於一些簡單的疾病,人工智慧能達到較高的診斷效能,用於人群疾病初篩的工作上,在一定程度上緩解缺乏醫護人員的問題。而一些治療難度較高的疾病,人工智慧可以為醫生診斷提供參考依據,起到提醒作用。
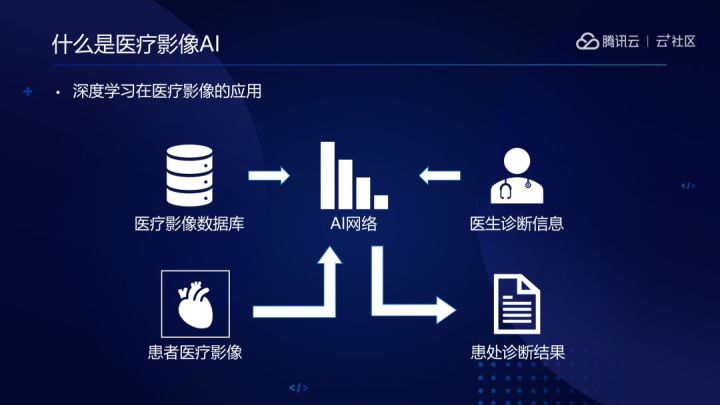
醫療影像包含豐富的診斷資訊,是醫療診斷中非常常見的手段。醫療影像AI的“製造”方法如下:收集標註資料,再通過這些資料來訓練人工智慧模型,最終實現在系統中輸入患者影像,獲得接近資深醫師的診斷結果。
二、MedicalNet與醫療影像AI發展的關係
近年來,影象與視訊識別軟體的發展,為醫療影像 AI 提供了很大幫助。但醫護人員資源有限,標註資料成為了困難,導致可用於訓練的同分布標註資料非常少,與資料驅動的深度學習形成矛盾,這就是目前醫療影像 AI 的發展瓶頸所在。

因此對於醫療影像 AI 的研究來說,亟需找到大規模資料集以及相應的模型,為大部分小資料醫療影像AI應用提供資訊支援,而這也正是開發 MedicalNet 的動機。儘管每個同分布的醫療3D公開資料集資料量小,但多個醫療場景的資料集集合起來能形成較大規模資料集,MedicalNet 開發團隊就將這些場景的資料集收集起來,用來訓練不同的預訓練模型,再開源相關預訓練模型。這樣一來,當有使用者需要訓練一個新模型時,就可以直接用 MedicalNet 模型進行遷移學習,即便新應用中資料量較小,使用者最終仍舊可以訓練出模型。

三、MedicalNet的技術實現
在 MedicalNet 的實現過程中,有不少難題需要通過技術來解決。其中包括畫素含義不一,範圍差異大,偽影頻繁,成像質量低,邊界模糊,對比度低;不同源資料,標註缺失;同一組織解析度不一致,不同組織尺度差異大等等問題。
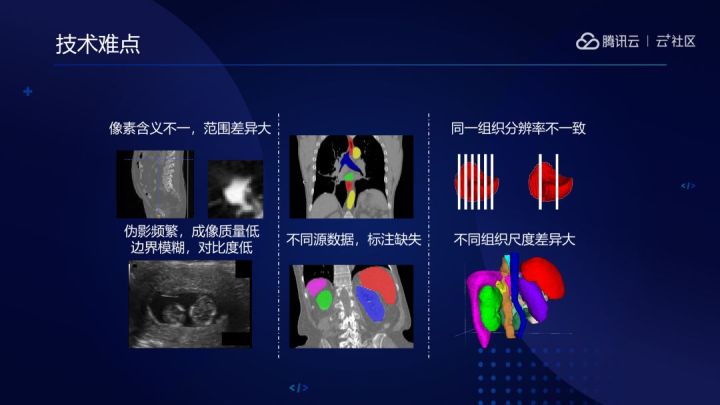
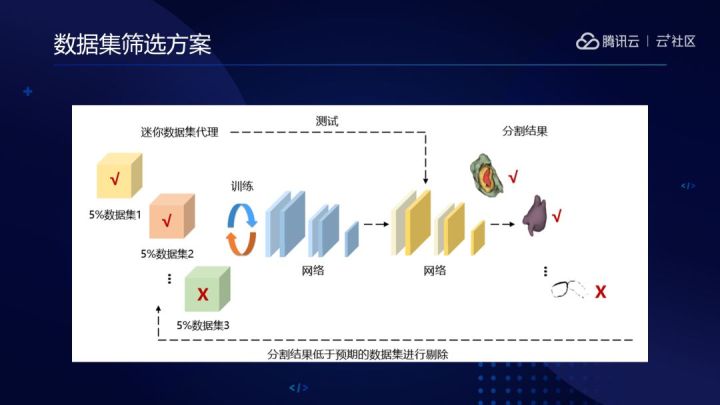
MedicalNet 開發團隊主要通過兩個方案來解決這些難題。首先是資料集篩選方案,主要目的是找出具備共通知識的資料集。具體做法如下:從每種場景的資料集中挑選少量資料,形成迷你資料集代理,通過代理快速訓練成小網路,最後根據迷你資料集分割預測結果的好壞判斷哪些資料集能夠保留下來。
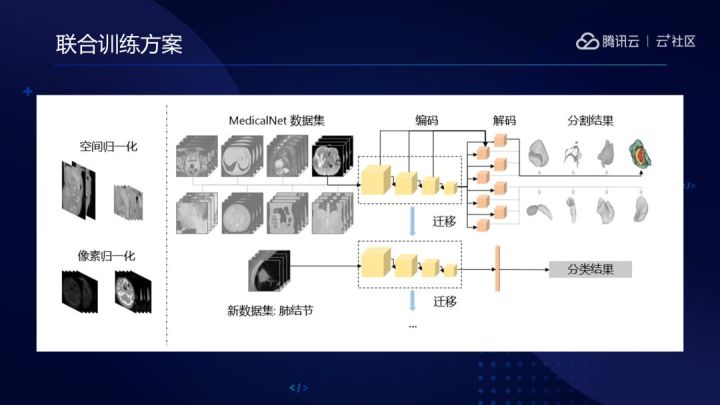
篩選完資料集之後,採用聯合訓練方案進行訓練。先對資料進行空間和畫素歸一化預處理。為了獲取更多標註資訊,MedicalNet全部採用分割資料集。MedicalNet由編碼和解碼部分組成,編碼部分為開源的模型。為了將更多的資訊集中在編碼部分,所以就把大部分引數都集中在了編碼中。為解決資料集與資料集之間標註不統一的問題,在解碼部分使用多工形式對多個場景的標註資料進行隔離。在訓練過程中,不同的skip-connection組合用於緩解梯度消失問題。訓練完成後,編碼部分可遷移到任意分割、分類以及檢測等多種任務的模型中。
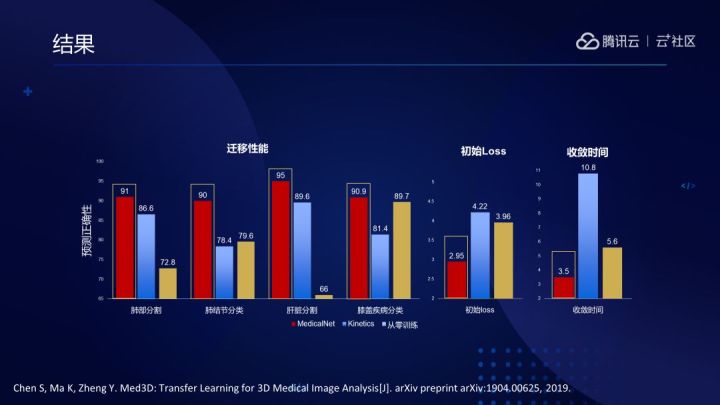
最終的實驗結果證明,在3D醫療影像應用中,MedicalNet能幫助小資料場景的網路加快收斂速度,提升預測效能。
四、Q&A
Q:MedicalNet使用程式碼是否已開源?MedicalNet有無用到醫院的某個功能上?A:MedicalNet相關程式碼已開源,詳見https://github.com/Tencent/MedicalNet,MedicalNet目前也已經用於多個落地模組中。
講師介紹

陳思巨集,騰訊視覺演算法高階研究員,14年起著手醫療影像AI相關工作,在MICCAI、TMI等頂級會議期刊發表過論文。主要致力於深度學習在醫療視訊影像和3D影像的研發與應用。
相關推薦
資料量不足,MedicalNet 如何助力醫療影像 AI 突破瓶頸?
導讀 |近日,雲+社群技術沙龍“騰訊開源技術”圓滿落幕。本次沙龍邀請了多位騰訊技術專家,深度揭祕了騰訊開源專案TencentOS tiny、TubeMQ、Kona JDK、TARS以及MedicalNet。本文是陳思巨集老師關於致力於提供基於3D醫療影像大資料的預訓練模型MedicalNet的詳細介紹。 一
百億資料量下,掌握這些Redis技巧你大概就穩住了全場
今天將會跟大家討論一些Redis在大資料中的使用,包括一些Redis的使用技巧和其他的一些內容。 首先給大家個地址: https://github.com/NewLifeX/NewLife.Redis 原始碼以及例項都在裡面,當然今天的內容也是按照裡面的例項來進行的,大家可以先進行下載。 這裡也附上R
轉:百億資料量下,掌握這些Redis技巧你大概就穩住了全場
原文:https://www.douban.com/note/699241909/ 一、Redis封裝架構講解 實際上NewLife.Redis是一個完整的Redis協議功能的實現,但是Redis的核心功能並沒有在這裡面,而是在NewLife.Core裡面。 這裡可以開啟看一下,NewLife.Core
mysql主從複製,資料量大, 高併發時,出現數據不一致
mysql5.7的並行複製就可以解決資料延遲的問題。 MySQL 5.7並行複製時代 眾所周知,MySQL的複製延遲是一直被詬病的問題之一,然而在Inside君之前的兩篇部落格中(1,2)中都已經提到了MySQL 5.7版本已經支援“真正”的並行複製功能,官方稱為
vue + Echarts 填坑記(Echarts資料量大,導致瀏覽器卡頓)
最近使用vue + Echarts 實現vue專案的資料視覺化功能的時候,發現隨著元件的增多,元件裡Echarts繪圖的增多,頁面操作越來越卡頓,點選資料比較大的元件時,Echarts繪圖渲染頁面的速度倒是挺快,但是當我點選切換其他元件統計圖時,出現了讓人難以忍受的卡頓,有
ASP.NET MVC匯出excel(資料量大,非常耗時的,非同步匯出)
要在ASP.NET MVC站點上做excel匯出功能,但是要匯出的excel檔案比較大,有幾十M,所以匯出比較費時,為了不影響對介面的其它操作,我就採用非同步的方式,後臺開闢一個執行緒將excel匯出到指定目錄,然後提供下載。匯出的excel涉及到了多個sheet(工作簿),表格合併,格式設定等,所以採用了N
為什麼說Volley適合資料量小,通訊頻繁的網路操作
前言 網路程式設計對於客戶端來說是一塊及其重要的地方,使用高效的網路請求框架將為你的系統產生很大的影響。而Volley作為谷歌的一個開源專案,炙手可熱。有很多中小型公司的安卓移動客戶端的網路程式都是基於volley的。 Volley的優點很多,光可擴充套件性
加入醫療影像AI公司的一些感受
本文由Markdown語法編輯器編輯完成。 不知不覺,在新的公司已經工作了兩週多。由於剛入職公司,所以在業務方面還是有一些不太熟悉,導致近期加班比較多,也沒有很多的時間來思考和撰寫部落格。在即將來到的中秋假期,可以稍微放下一點手頭的工作,記錄一下這兩週來加入新公
醫療影像AI學習路線
醫學影像AI學習主要內容1. 計算機基礎方面Python(卷積神經網路)、C++、COpenCV(影象預處理)Linux系統CUDA程式設計(GPU)2. 常用演算法線性分類、決策樹、貝葉斯、聚類分析3. 主要深度學習模型CNN類模型(影象識別)、RNN類模型、S
資料獲取成本對醫療影像AI產業化的影響
AI應用,三架馬車快慢不一? 人臉識別、語音識別、疾病檢測稱得上是這一次人工智慧創新創業大潮中的三架馬車。但觀察我們身邊生活會發現,三架馬車快慢不一。有的已經飛入尋常百姓家,有的則還是陽春白雪。 入住賓館時前臺刷臉,乘坐高鐵時進站刷臉。在手機上發文字訊息,不再動手
GitChat·人工智慧 | 腫瘤醫療影像 AI 識別技術實踐
GitChat 作者:王曉明 更多IT技術分享,盡在微信公眾號:GitChat 前言 醫學影像與人工智慧的結合,是數字醫療領域較新的分支和產業熱點。醫學影像的解讀需要長時間專業經驗的積累,醫生的培養週期相對較長,很多程度上,深度學習和醫生的學習
mysql innodb引擎 長時間使用後,資料檔案遠大於實際資料量,導致空間不足。
近期我碰到了一個令人頭疼的事情。就是我的mysql伺服器使用了很久之後,發現/data 目錄的空間佔滿了我係統的整個空間,馬上就要滿了。下面是我的分析。 在網上查看了這2個方法,但是執行後發現沒有解決。系統空間沒有變小。 1.optimize table table.n
o(1), o(n), o(logn), o(nlogn) 隨資料量的增大,耗時的增大-轉載
在描述演算法複雜度時,經常用到o(1), o(n), o(logn), o(nlogn)來表示對應演算法的時間複雜度, 這裡進行歸納一下它們代表的含義: 這是演算法的時空複雜度的表示。不僅僅用於表示時間複雜度,也用於表示空間複雜度。 O後面的括號中有一個函式,指明某個演算法的
POI操作大資料量Excel時,new SXSSFWorkbook(1000)例項化失敗問題解決
專案上使用POI匯出資料庫大資料量為Excel時,發現程式碼執行時 例項化工作簿 失敗! SXSSFWorkbook workbook = new SXSSFWorkbook(100); trycatch問題程式碼後,在debug中也並未進入異常處理,而是直接進入了finally 最後
Hadoop學習筆記—4.初識MapReduce 一、神馬是高大上的MapReduce MapReduce是Google的一項重要技術,它首先是一個程式設計模型,用以進行大資料量的計算。對於大資料
Hadoop學習筆記—4.初識MapReduce 一、神馬是高大上的MapReduce MapReduce是Google的一項重要技術,它首先是一個程式設計模型,用以進行大資料量的計算。對於大資料量的計算,通常採用的處理手法就是平行計算。但對許多開發
php通過手機號查詢歸屬地,使用免費介面,資料量6W+以上
函式名稱:get_mobile_area 引數列表:$mobile表示需要查詢的手機號 具體實現: function get_mobile_area($mobile){ &n
mysql去重,3億多資料量
差不多3億6千萬資料,需要去重。因為資料量太大,所以: 將資料load data infile到大表裡,不進行任何去重操作,沒有任何約束。然後將資料分成幾十個小表,用這幾十個小表去對比大表去重。得到去重後的小表。去重以後的小表,根據欄位進行hash算出後兩位數字,重新建好新表,將去重後小表的資料
主要是解決,作為一個數據共享的資料庫,存在的資料庫統計,然後將計算的資料量輸出到自己使用的資料庫,進行主頁面展示。
1、主要是解決,作為一個數據共享的資料庫,存在的資料庫統計,然後將計算的資料量輸出到自己使用的資料庫,進行主頁面展示。 1 1、第一步,可以查詢自己作為目標表的資料表的資料量。方便做條件過濾,如果資料量大於0,那麼查詢出所有欄位,然後將is_sync標識位標為1。 2 select co
Volley---適合場景:適合資料量小、頻率高的請求,為什麼?
一、簡介 Volley請求網路 是基於請求佇列的,只要把請求放入請求佇列就可以了。 Voller底層封裝的是HttpUrlConnection,支援圖片載入,網路請求排序,優先順序處理,快取,與Activity生命週期聯動。擴充套件性好,支援httpclient,HttpUrlConne
結合生成式與判別式方法,Petuum新研究助力醫療診斷
在過去一年中,我們看到了很多某種人工智慧演算法在某個醫療檢測任務中「超越」人類醫生的研究和報道,例如面板癌、肺炎診斷等。如何解讀這些結果?他們是否真正抓住醫療實踐中的痛點、解決醫生和病人的實際需要? 這些演算法原型如何落地部署於資料高度複雜、碎片化、異質性嚴重且隱