
量化投資學習筆記18——迴歸分析:變數的選擇、多重共線性及迴歸分析的改進
如果模型包含了所有影響因素,稱為全模型。如果只包含部分影響因素,稱為選模型。
影響:①未選入的引數不全為0時,選模型的迴歸引數為有偏估計。②選模型的預測結果是有偏預測。③選模型的引數估計有較小的方差。④選模型的預測殘差有較小的方差。⑤選模型預測的均方誤差比全模型小。
自變數選擇的準則:
①殘差平方和SSE越小,決定係數R²越大越好。並非如此。
②自由度調整複決定係數達到最大。
③赤池資訊量(Akaike Information Criterion, AIC)達到最小:基於最大似然估計原理。
④統計量Cp達到最小。
下面用課程裡的一個數據集進行實操,有三個可選自變數,分別計算各種自變數選擇組合的R²,adjR²,AIC,Cp。
其中前三個指標都能直接用statsmodels獲得,而Cp沒找到如何獲得,就算前三個吧。
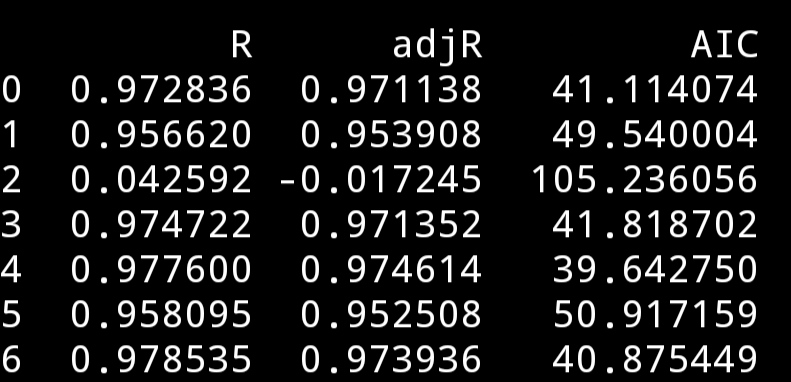
最後幾個都很好。
自變數選擇的方法
前進法:變數由少到多,逐個加入,直到沒有可引入的變數。
步驟:
①對所有m個自變數分別進行一元線性迴歸。②對迴歸方程計算F統計量,找出最大的一個。
③若其大於預先指定的檢驗水平,該變數入選。
④將該變數與剩餘的m-1個變數組合,分別進行建模,按照上面的過程選出F值最大的一個,如果大於檢驗水平,入選。
⑤重複上述步驟,直到沒有滿足條件的變數為止。
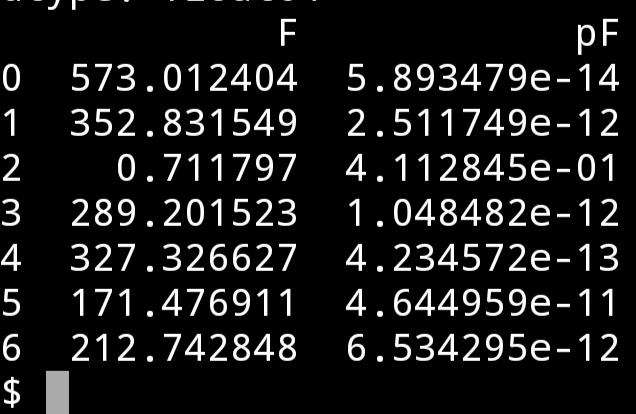
看實測的結果,除了第三個,即x3的方程,其餘都遠小於0.05。
前三個是單變數一元線性迴歸的,x1的方程的F值最大,入選。
然後看x1,x2和x1,x3的迴歸方程的F值。分別是上面的3,4行。x3入選。
最後看x2入選以後得F值,p仍小於0.05,也入選。因此三個變數均入選。
後退法:變數由多到少,逐個減少,直至沒有可以減少的變數。
方法,先對所有變數進行迴歸,然後看每個迴歸係數的F值,找到最小的,若小於檢驗閾值,將該變數去除。直至無法再去除。
兩種方法都有各自的優缺點。
逐步迴歸法:有進有出。一旦入選變數發生變化就對所有變數進行F檢驗。
多重共線性:模型的解釋變數之間存在精確或高度相關關係使模型估計失真或難以估計準確。
原因:多個自變數存在相同的趨勢。②引入了滯後的變數。③樣本資料的限制。
影響:引數估計失效;顯著性檢驗失效;模型無應用價值。
診斷:
直觀判斷:增加或剔除一個自變數,觀察模型,如果係數估計值變化很大,說明存在嚴重的多重共線性。重要的自變數顯著性檢驗沒有通過。一些自變數係數正負號與定性分析結果相反。自變數相關係數矩陣中相關係數較大。重要變數的迴歸係數標準誤差較大。
方差擴大因子法。
特徵根判定法。
消除方法:
①刪除不重要的解釋變數
②增大樣本量
③迴歸係數有偏估計
改進的迴歸方法:嶺迴歸(脊迴歸)、LASSO迴歸
迴歸分析就完了,接下來找個實際的資料集來實操一把吧。
本文程式碼: https://github.com/zwdnet/MyQuant/tree/master/17
我發文章的四個地方,歡迎大家在朋友圈等地方分享,歡迎點“在看”。
我的個人部落格地址:https://zwdnet.github.io
我的知乎文章地址: https://www.zhihu.com/people/zhao-you-min/posts
我的部落格園部落格地址: https://www.cnblogs.com/zwdnet/
我的微信個人訂閱號:趙瑜敏的口腔醫學學習園