
如何構建阿里小蜜演算法模型的迭代閉環?
阿新 • • 發佈:2020-02-24
導讀:伴隨著AI的興起,越來越多的智慧產品誕生,演算法鏈路也會變得越來越複雜,在工程實踐中面臨著大量演算法模型的從0到1快速構建和不斷迭代優化的問題,本文將介紹如何打通資料分析-樣本標註-模型訓練-監控迴流的閉環,為複雜算法系統提供強有力的支援。
新技術/實用技術點:
- 實時、離線場景下資料加工的方案選型
- 高維資料的視覺化互動
- 面對不同演算法,不同部署場景如何對流程進行抽象
01. 背景 - 技術背景及業務需求
小蜜系列產品是阿里巴巴為消費者和商家提供的智慧服務解決方案,分別在使用者助理、電商客服、導購等方面做了很多工作,雙十一當天提供了上億輪次的對話服務。其中用到了問答、預測、推薦、決策等多種演算法模型,工程和演算法同學在日常運維中會面臨著如何從0到1快速演算法模型並不斷迭代優化,接下來將從工程角度介紹如何打通資料->樣本->模型->系統的閉環,加速智慧產品的迭代週期。
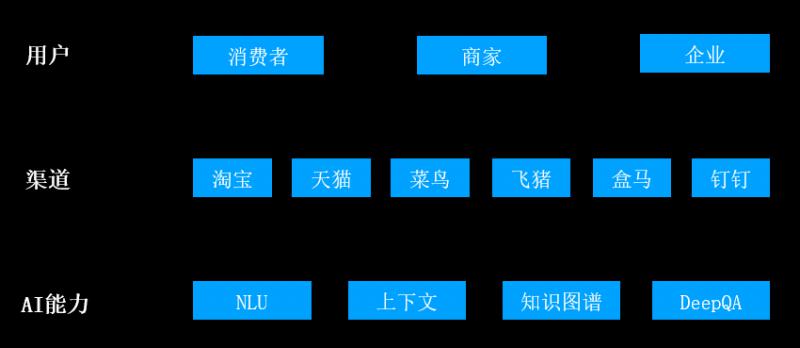
- 實現
實現這一過程分為2個階段:
0->1階段:
模型冷啟動,這一階段更多關注模型的覆蓋率。
實現步驟:
A. 抽取對話日誌作為資料來源
B. 做一次知識挖掘從日誌中挑出有價值的資料
C. 運營人員進行標註
D. 演算法對模型進行訓練
E. 運營人員和演算法端統一對模型做評測
F. 模型釋出

1->100階段:
badcase反饋和修復階段,主要目標是提升模型的準確率。
實現步驟:
A. 運營端根據業務反饋(頂踩按鈕)、使用者不滿意會話(如:轉人工)收集badcase資訊
B. 進行資料分析,將分析結果給到不同的模型模組、規則模組
C. 演算法端對以上模型分別進行訓練
D. 最終釋出到線上生效
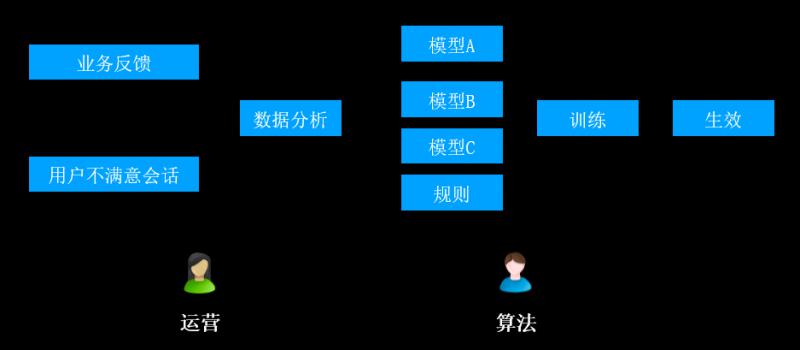
- 痛點
在以上過程中,會遇到如下幾個痛點:
A. 不同演算法需要不同的標註互動形式,如何快速支援
B. 運營方的標註憑藉個人感覺,缺少指導,無法保障質量
C. 線上badcase如何快速發現和修復
D. 機器人中部署了上百個演算法模型,日常維護需要佔用工程師大量的精力
E. 資料樣本在業務和演算法之間來回傳遞,有安全隱患
02. 閉環迭代模型的產生 - 模型訓練閉環
基於以上的痛點,阿里小蜜團隊構建了模型訓練閉環。該閉環系統主要包括對話系統層、資料層、樣本層和模型層這4個部分。
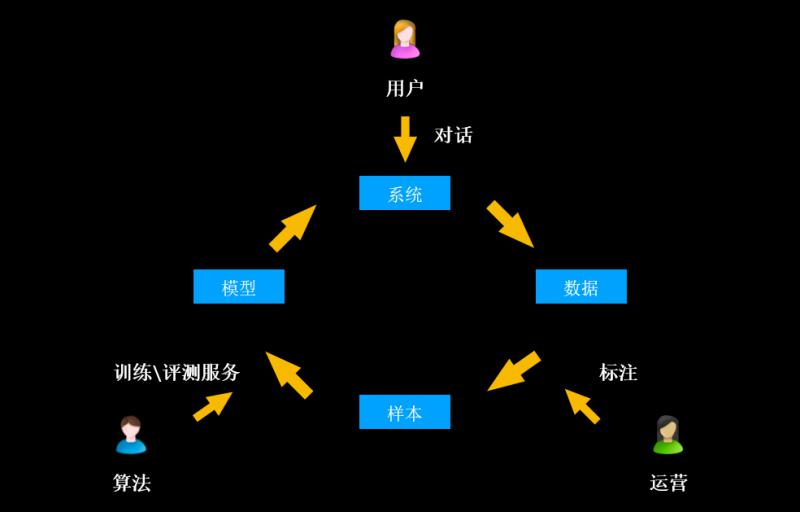
彼此之間的關係、流程如下:
A. 對話系統層:使用者端會跟機器人系統進行對話
B. 對話產生的日誌經過數倉埋點進入到資料層
C. 資料層由運營人員做標註
D. 完成標註的資料作為樣本,藉助演算法團隊提供的訓練/評測服務,進入到模型層
E. 模型釋出到系統中,形成訓練閉環
- 系統 => 資料
① 多維資料查詢
這一部分講述如何從系統層到達資料層,這裡會涉及到“多維資料查詢”這樣一個概念。前面提到,資料來源的渠道是多種多樣的;這些資料會具備多種多樣的屬性,例如:行業屬性、使用者型別屬性等。不同業務的對話日誌帶有各自的業務屬性。
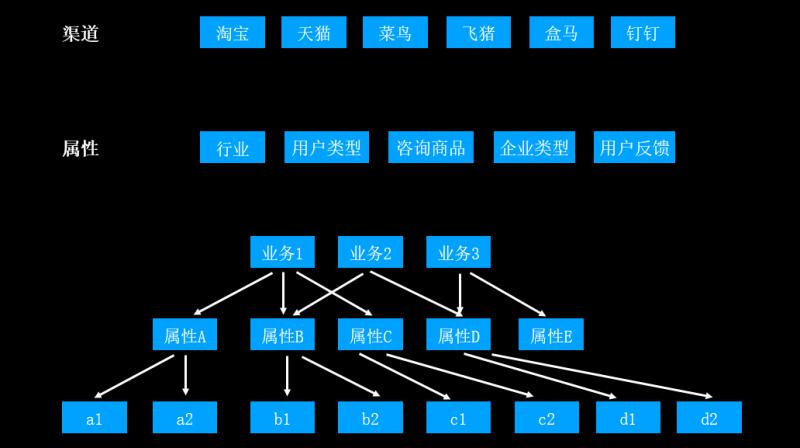
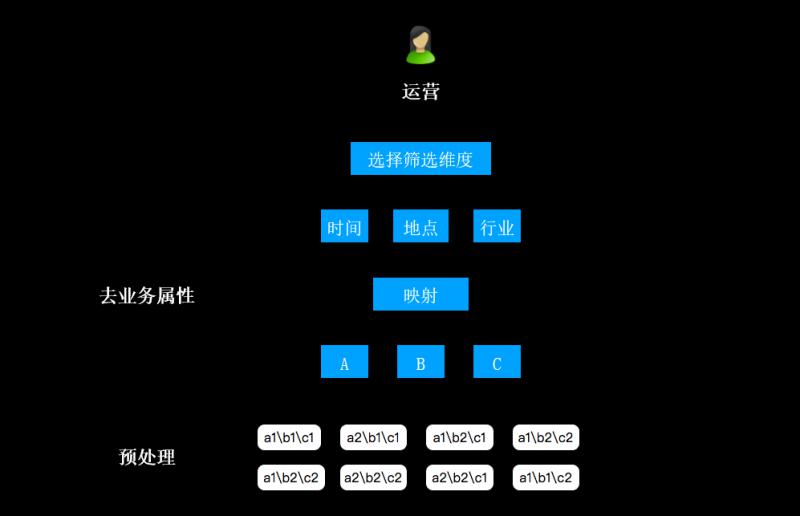
在應用多維資料查詢的過程中,難點是屬性相交等問題。平臺的第一項工作就是資料預處理,遍歷出所有的業務-屬性組合;運營人員取資料的時候,先選擇業務維度;接著從業務維度到資料維度進行一層對映,從而去掉其業務屬性(例如,時間、地點、行業等維度分別對映成A、B、C)
② OLAP與“資料立方體”
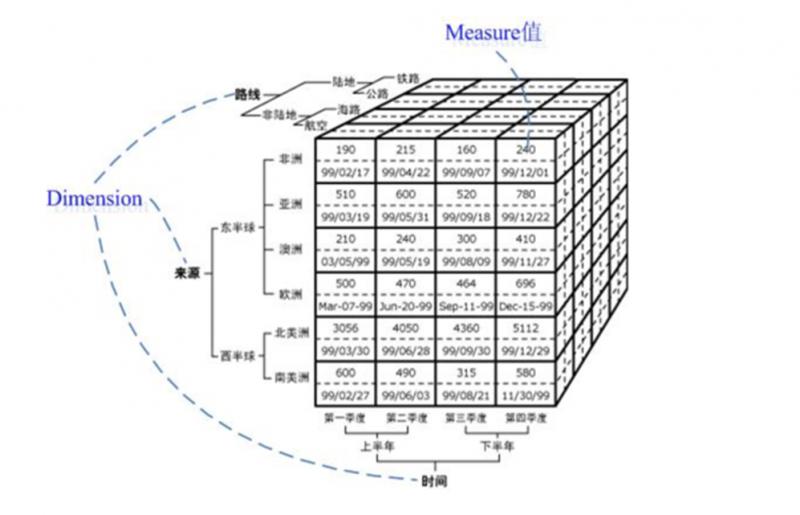
這裡用到了聯機分析處理(OLAP ,On-Line Analytical Processing,一種資料動態分析模型)技術。首先會構造“資料立方體”這樣一種資料結構,將資料分成多種維度,包括:來源維度、路線維度、時間維度。
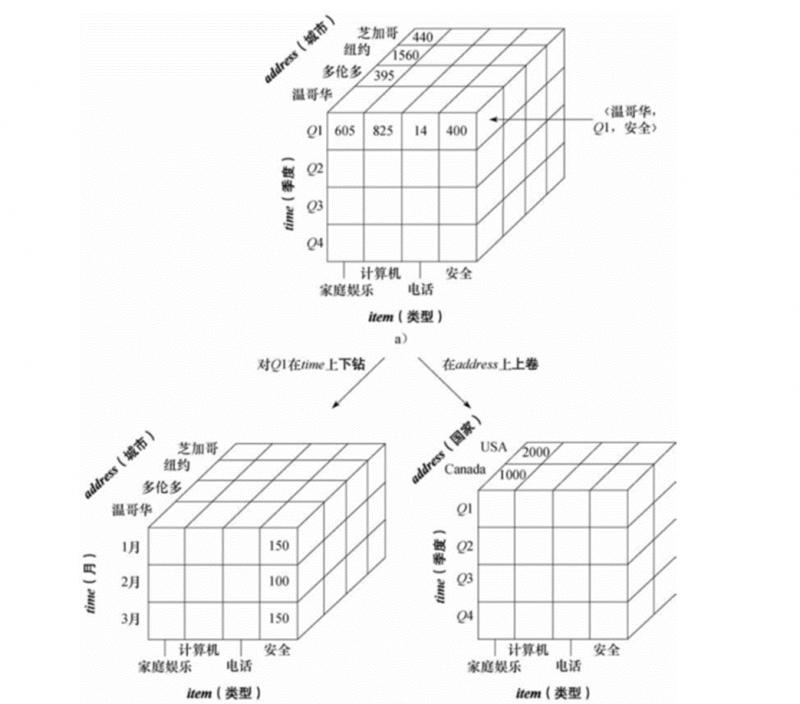
對資料立方體由上卷和下鑽這兩種基本操作,生成新的立方體。下圖中,右半部分是將城市維度進行了上卷操作,左半部分是將季度維度進行了下鑽操作。
資料立方體結構的不足:
A. 維度型別。對於商家這種百萬數量級的維度,搜尋起來效率低下。針對這種缺點,選擇對於重點商家重點維度進行儲存。
B. 多條件的or關係查詢,在這種立方體結構中無法實現。
C. 列舉數量和效率的平衡。需要根據具體覆蓋業務定義屬性等。 - 資料 => 樣本
① 標註元件
資料標註環節由“人工智慧訓練師”這個角色參與,標註形式會根據演算法的選擇而調整,包括:標籤、實體、屬性間關係等。
如下圖所示:
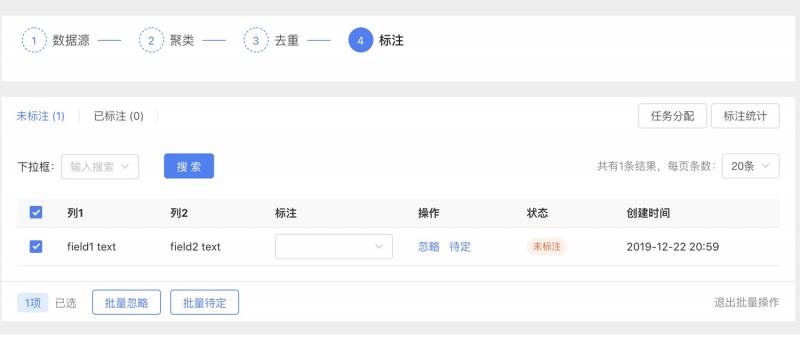
元件包括狀態列、搜尋框、表格(支援配置),可進行標註分類、文字型精選、排序型篩選、任務操作內容等多個模組(詳見下圖)。
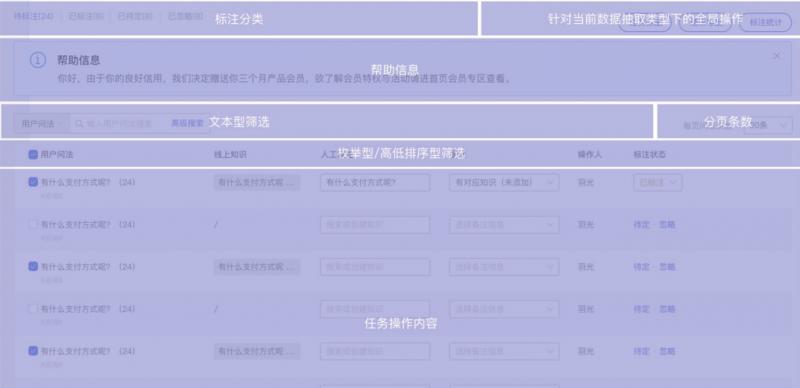
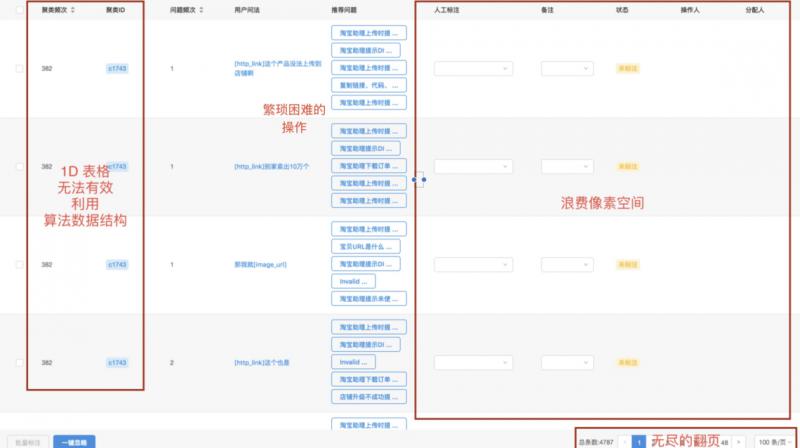
這樣的元件有如下的缺點:
A. 1D表格無法有效利用演算法資料結構
B. 操作繁瑣困難
C. 浪費畫素空間
D. 無盡的翻頁
② 高維資料視覺化
基於元件存在的以上種種缺點,我們選擇了將資料降維。
什麼是高維資料?
高維資料包括:
A. 機器人阿里小蜜的文字資料
B. 圖片
C. 語音資料
視覺化後的高維資料長什麼樣子?

視覺化前

視覺化後
上圖是對文字資料視覺化後的結果。實現步驟:
A. 對文字資料進行聚類,根據相似度變成平面結構
B. 用顏色區分類別
這種方式可以直觀看出線上的語料分佈,包括分佈類別、分佈集中趨勢等。
這裡用到的技術方案包括:
A. 降維:主要用PCA和T-SNE兩種降維方式
B. 向量化:資料拆分之後,將資料轉變為可比較的表示形式。對於文字,主要使用word2vec;而對於圖片,主要使用phash編碼。
C. 聚類:聚類主要使用k-means。

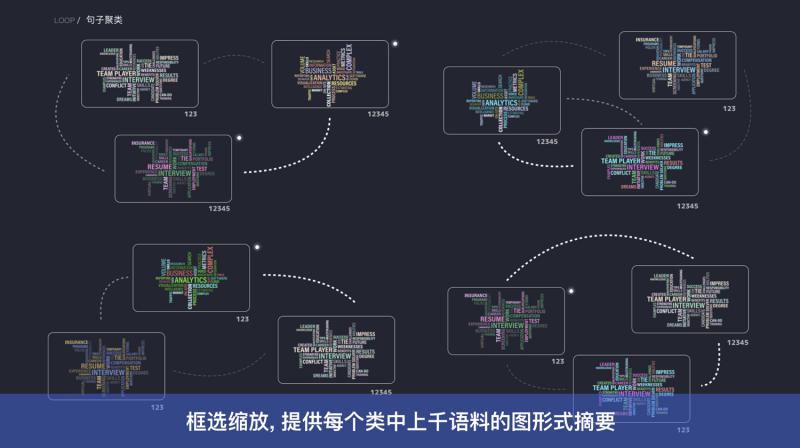
③ 散點圖塌縮及其互動
下圖中的左圖是聚類後的效果圖。聚類完成後,每一類圖片的每一類都會分佈到一起;再通過散點圖塌縮演算法,將每一個類壓縮成一個散點,通過顏色區分類別種類。
利用這種方式,可以找出badcase中佔比最高的一類,從而進行修復。

在對類的互動中,有一些特殊的操作,例如:框選。上圖右圖的散點圖中,可以通過框選的方式抽取每一類的關鍵詞。
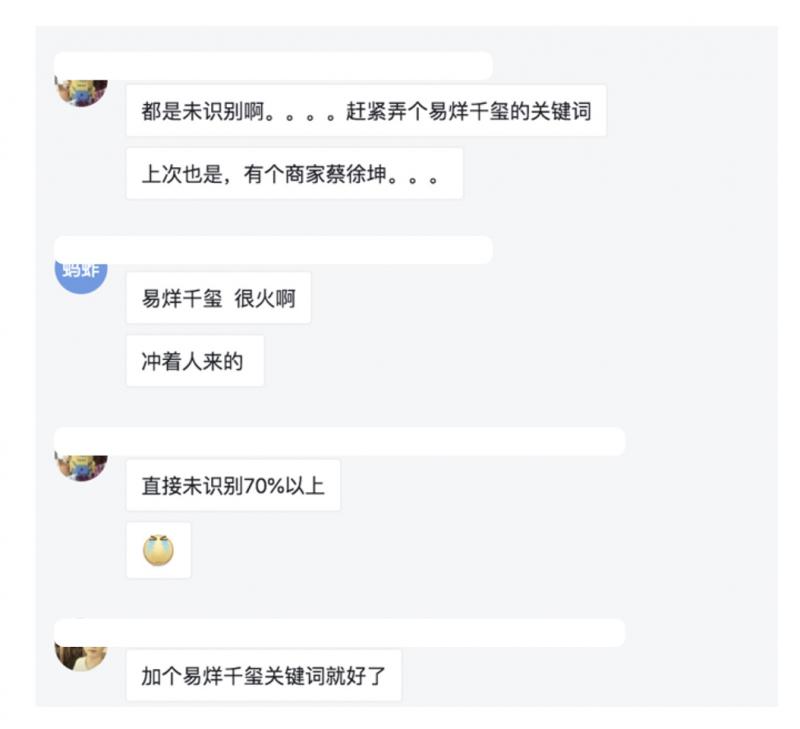
03. 實時佈防 - 語料關鍵詞的識別與新增

上圖是某一天貓商家的海報圖:某商家正在搞一個促銷活動,找易烊千璽作為代言人。由於機器人預先不知道會有這樣一個活動發生,模型中自然不包含這樣的關鍵詞。商家發現當天的未識別語料全部都和“易烊千璽”相關,但是機器人不識別這個關鍵詞(未識別率達70%以上)。怎樣快速幫商家解決這類問題呢?
- 實時佈防
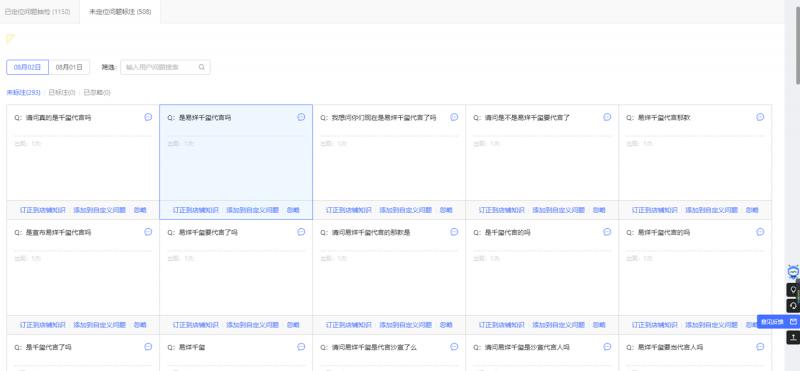
這類的AI能力如何做實時佈防呢?將這類問答、意圖等AI能力在自己的伺服器上以日誌的形式做埋點,伺服器會將日誌收集起來通過flink平臺做實時流式聚類,商家工作臺通過標註元件的形式展現當前時段的高頻問題,並通過互動式選項選擇如何修復(以上圖中的藍色選定區域為例),從而讓機器人能夠識別該語料。
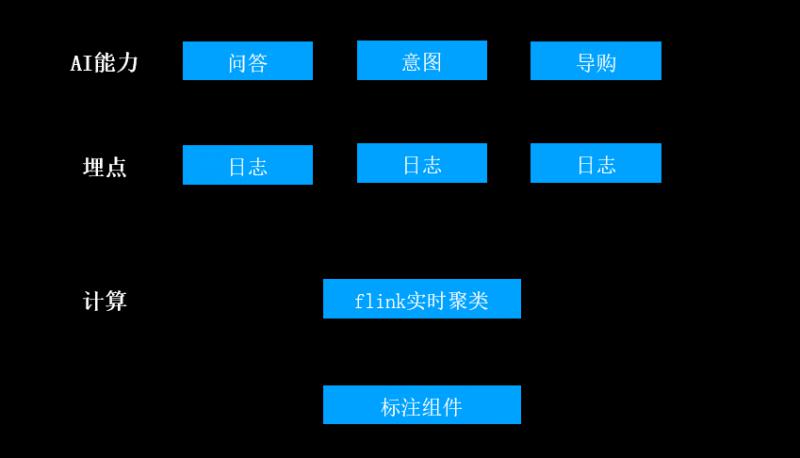
- 資料加工
從業務日誌中提取模型需要的語料需要進行一些基本的演算法加工,這些步驟除了面臨大資料的壓力,研發工程師還要考慮對這種加工能力的封裝和複用。
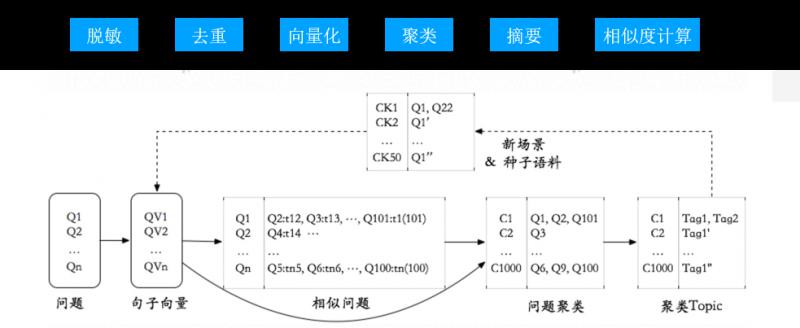
A. 首先,對日誌資料做脫敏:將日誌中的手機號、地址、人名等去掉,對單字型文字、語聊型文字的去除;
B. 接下來對資料做去重和向量化;
C. 下一步是對處理完成的資料做聚類;
D. 聚類後的資料做摘要,進而做相似度計算。
整個過程需要很多的演算法模組,每一個模組都會封裝成一個演算法元件,提供到不同的模型迭代中。上圖的下半部分就是語料經過了不同演算法模組的變化,從向量到聚類,進而抽取不同Topic。
下圖是以上過程抽象成的模板。
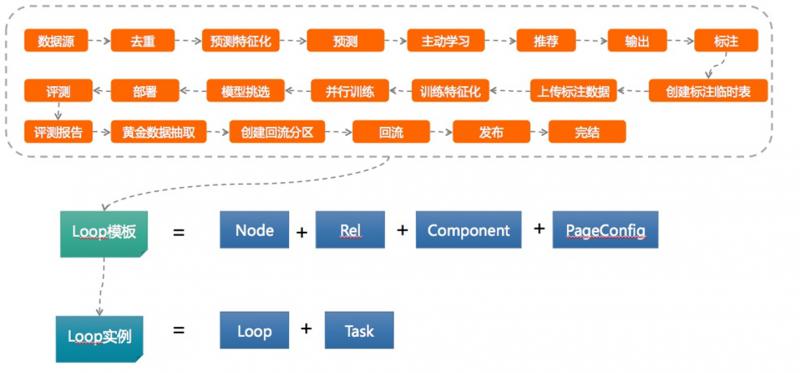
模板中包含了演算法元件、標註元件、訓練元件等不同的元件;運營人員在線上可以挑選不同元件配置模板來優化對應的模型。
在模板執行的過程中,可使用mapreduce元件、UDF元件以及Spark元件。Spark元件是目前通用性較強的元件,既可本地排程,又可遠端排程。 - 構建資料處理引擎
基於Spark構建資料處理引擎,分為客戶端和計算叢集兩個系統。客戶端包括元件庫、排程引擎,以及Spark Client Runner。

這種架構的好處:演算法可以在本地開發spark元件,直接整合到模板中;同時支援遠端叢集模式和本機輕量級排程,大小資料量都適用;同時spark擁有 SQL和spark mllib兩個元件庫,研發通過封裝可以直接開放給業務使用。
本次分享就到這裡,謝謝大家。
歡迎加入DataFunTalk交流群,跟同行零距離交流。如想進群,請加逃課兒同學的微信(微訊號:DataFunTalker),回覆:交流,逃課兒會自動拉你進群。