
計算機組成原理筆記(三)
阿新 • • 發佈:2020-02-28
我的部落格 : https://www.luozhiyun.com/
## 超執行緒
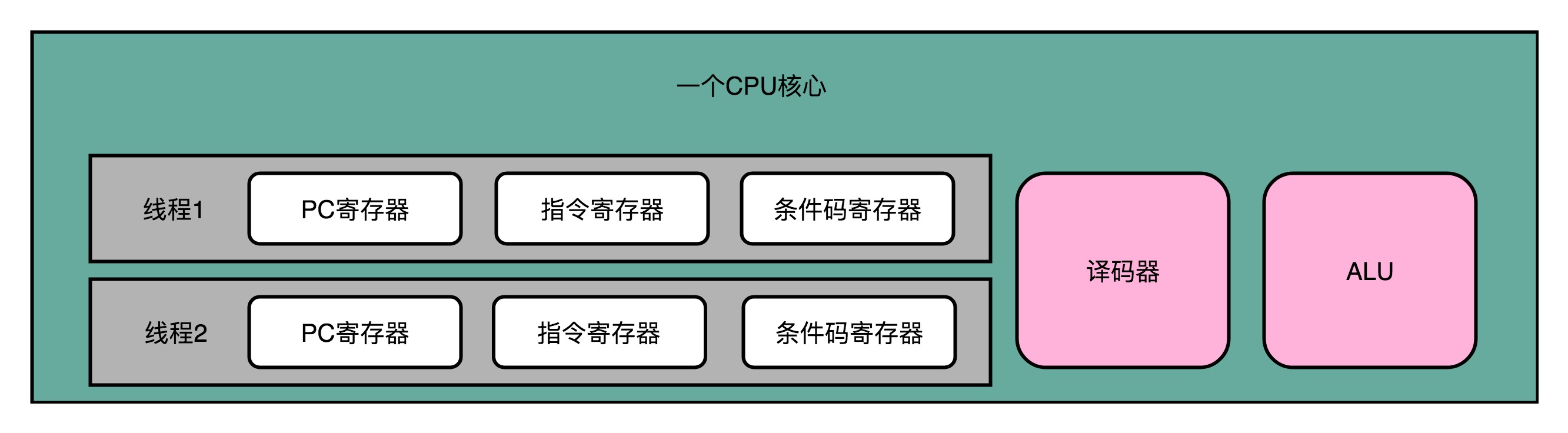
超執行緒的CPU,其實是把一個物理層面CPU核心,“偽裝”成兩個邏輯層面的CPU核心。這個CPU,會在硬體層面增加很多電路,使得我們可以在一個CPU核心內部,維護兩個不同執行緒的指令的狀態資訊。
比如,在一個物理CPU核心內部,會有雙份的PC暫存器、指令暫存器乃至條件碼暫存器。這樣,這個CPU核心就可以維護兩條並行的指令的狀態。
超執行緒並不是真的去同時執行兩個指令,超執行緒的目的,是在一個執行緒A的指令,在流水線裡停頓的時候,讓另外一個執行緒去執行指令。因為這個時候,CPU的譯碼器和ALU就空出來了,那麼另外一個執行緒B,就可以拿來幹自己需要的事情。這個執行緒B可沒有對於執行緒A裡面指令的關聯和依賴。
所以超執行緒只在特定的應用場景下效果比較好。一般是在那些各個執行緒“等待”時間比較長的應用場景下。比如,我們需要應對很多請求的資料庫應用,就很適合使用超執行緒。各個指令都要等待訪問記憶體資料,但是並不需要做太多計算。
## SIMD加速矩陣乘法
**SIMD**,中文叫作**單指令多資料流**(Single Instruction Multiple Data)。
下面是兩段示例程式,一段呢,是通過迴圈的方式,給一個list裡面的每一個數加1。另一段呢,是實現相同的功能,但是直接呼叫NumPy這個庫的add方法。
```
$ python
>>> import numpy as np
>>> import timeit
>>> a = list(range(1000))
>>> b = np.array(range(1000))
>>> timeit.timeit("[i + 1 for i in a]", setup="from __main__ import a", number=1000000)
32.82800309999993
>>> timeit.timeit("np.add(1, b)", setup="from __main__ import np, b", number=1000000)
0.9787889999997788
>>>
```
兩個功能相同的程式碼效能有著巨大的差異,足足差出了30多倍。原因就是,NumPy直接用到了SIMD指令,能夠並行進行向量的操作。
使用迴圈來一步一步計算的演算法呢,一般被稱為**SISD**,也就是**單指令單資料**(Single Instruction Single Data)的處理方式。如果你手頭的是一個多核CPU呢,那麼它同時處理多個指令的方式可以叫作**MIMD**,也就是**多指令多資料**(Multiple Instruction Multiple Dataa)。
Intel在引入SSE指令集的時候,在CPU裡面添上了8個 128 Bits的暫存器。128 Bits也就是 16 Bytes ,也就是說,一個暫存器一次性可以載入 4 個整數。比起迴圈分別讀取4次對應的資料,時間就省下來了。
在資料讀取到了之後,在指令的執行層面,SIMD也是可以並行進行的。4個整數各自加1,互相之前完全沒有依賴,也就沒有冒險問題需要處理。只要CPU裡有足夠多的功能單元,能夠同時進行這些計算,這個加法就是4路同時並行的,自然也省下了時間。
所以,對於那些在計算層面存在大量“資料並行”(Data Parallelism)的計算中,使用SIMD是一個很划算的辦法。
## 異常和中斷
### 異常
關於異常,它其實是一個硬體和軟體組合到一起的處理過程。異常的前半生,也就是異常的發生和捕捉,是在硬體層面完成的。但是異常的後半生,也就是說,異常的處理,其實是由軟體來完成的。
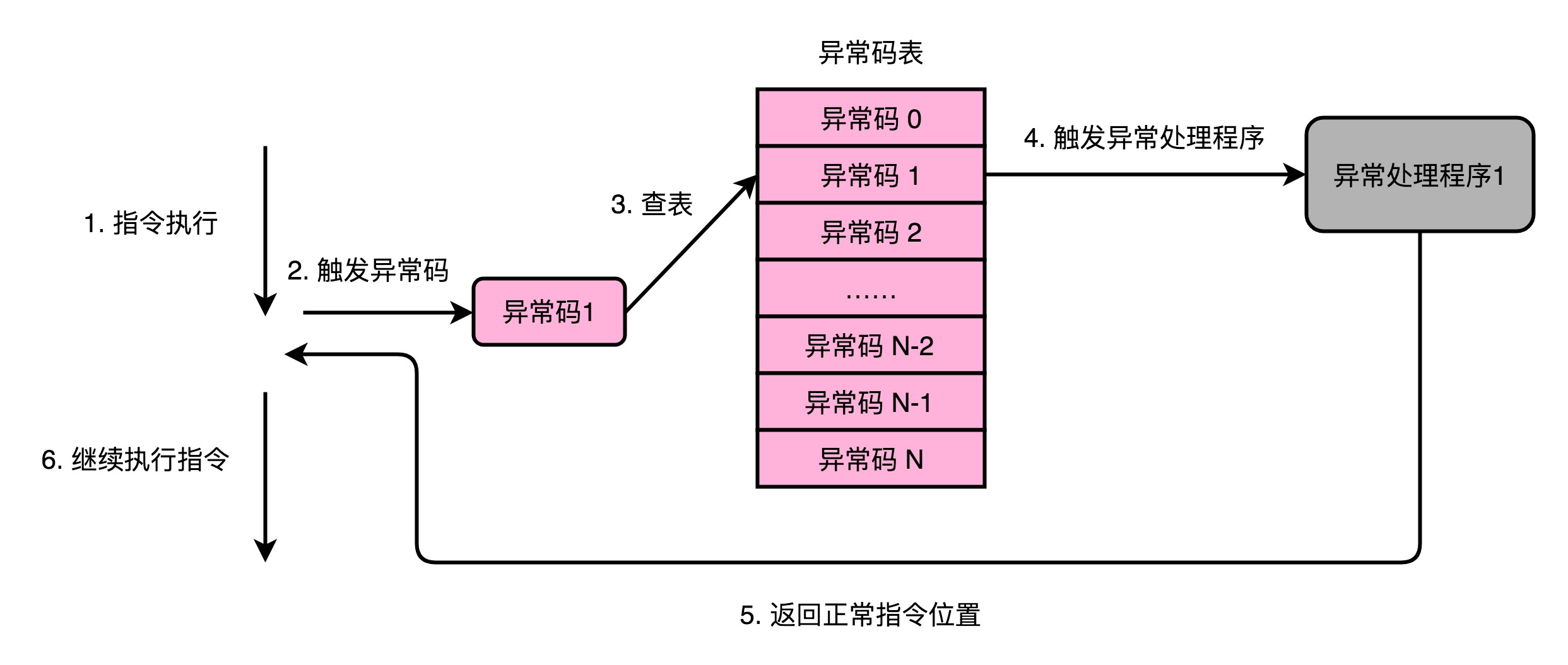
計算機會為每一種可能會發生的異常,分配一個異常程式碼(Exception Number)。有些教科書會把異常程式碼叫作中斷向量(Interrupt Vector)。
異常發生的時候,通常是CPU檢測到了一個特殊的訊號。這些訊號呢,在組成原理裡面,我們一般叫作發生了一個事件(Event)。CPU在檢測到事件的時候,其實也就拿到了對應的異常程式碼。
這些異常程式碼裡,I/O發出的訊號的異常程式碼,是由作業系統來分配的,也就是由軟體來設定的。而像加法溢位這樣的異常程式碼,則是由CPU預先分配好的,也就是由硬體來分配的。
拿到異常程式碼之後,CPU就會觸發異常處理的流程。計算機在記憶體裡,會保留一個異常表(Exception Table)。我們的CPU在拿到了異常碼之後,會先把當前的程式執行的現場,儲存到程式棧裡面,然後根據異常碼查詢,找到對應的異常處理程式,最後把後續指令執行的指揮權,交給這個異常處理程式。
### 異常的分類:中斷、陷阱、故障和中止
第一種異常叫中斷(Interrupt)。顧名思義,自然就是程式在執行到一半的時候,被打斷了。
第二種異常叫陷阱(Trap)。陷阱,其實是我們程式設計師“故意“主動觸發的異常。就好像你在程式裡面打了一個斷點,這個斷點就是設下的一個"陷阱"。
第三種異常叫故障(Fault)。比如,我們在程式執行的過程中,進行加法計算髮生了溢位,其實就是故障型別的異常。
最後一種異常叫中止(Abort)。與其說這是一種異常型別,不如說這是故障的一種特殊情況。當CPU遇到了故障,但是恢復不過來的時候,程式就不得不中止了。
### 異常的處理:上下文切換
在實際的異常處理程式執行之前,CPU需要去做一次“儲存現場”的操作。有了這個操作,我們才能在異常處理完成之後,重新回到之前執行的指令序列裡面來。
因為異常情況往往發生在程式正常執行的預期之外,比如中斷、故障發生的時候。所以,除了本來程式壓棧要做的事情之外,我們還需要把CPU內當前執行程式用到的所有暫存器,都放到棧裡面。最典型的就是條件碼暫存器裡面的內容。
像陷阱這樣的異常,涉及程式指令在使用者態和核心態之間的切換。對應壓棧的時候,對應的資料是壓到核心棧裡,而不是程式棧裡。
## 虛擬機器技術
### 解釋型虛擬機器
我們把原先的作業系統叫作宿主機(Host),把能夠有能力去模擬指令執行的軟體,叫作模擬器(Emulator),而實際執行在模擬器上被“虛擬”出來的系統呢,我們叫客戶機(Guest VM)。
例如在windows上跑的Android模擬器,或者能在Windows下執行的遊戲機模擬器。
這種解釋執行方式的最大的優勢就是,模擬的系統可以跨硬體。比如,Android手機用的CPU是ARM的,而我們的開發機用的是Intel X86的,兩邊的CPU指令集都不一樣,但是一樣可以正常執行。
缺陷:
第一個是,我們做不到精確的“模擬”。很多的老舊的硬體的程式執行,要依賴特定的電路乃至電路特有的時鐘頻率,想要通過軟體達到100%模擬是很難做到的。
第二個是這種解釋執行的方式,效能實在太差了。因為我們並不是直接把指令交給CPU去執行的,而是要經過各種解釋和翻譯工作。
### Type-1和Type-2虛擬機器
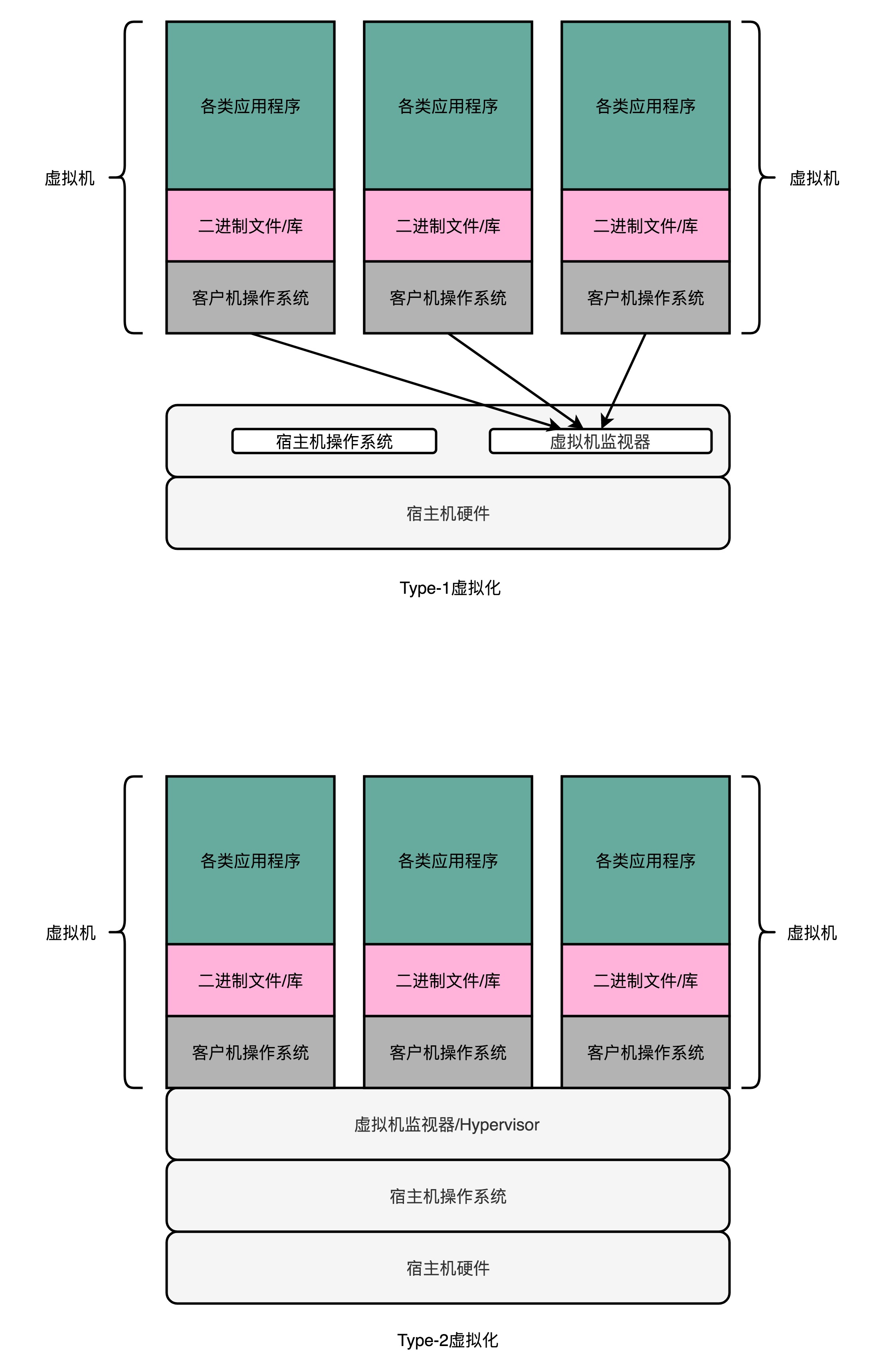
如果我們需要一個“全虛擬化”的技術,可以在現有的物理伺服器的硬體和作業系統上,去跑一個完整的、不需要做任何修改的客戶機作業系統(Guest OS),有一個很常用的一個解決方案,就是加入一箇中間層。在虛擬機器技術裡面,這個中間層就叫作虛擬機器監視器,英文叫VMM(Virtual Machine Manager)或者Hypervisor。
#### Type-2虛擬機器
在Type-2虛擬機器裡,我們上面說的虛擬機器監視器好像一個執行在作業系統上的軟體。你的客戶機的作業系統呢,把最終到硬體的所有指令,都發送給虛擬機器監視器。而虛擬機器監視器,又會把這些指令再交給宿主機的作業系統去執行。
#### Type-1虛擬機器
在資料中心裡面用的虛擬機器,我們通常叫作Type-1型的虛擬機器。客戶機的指令交給虛擬機器監視器之後呢,不再需要通過宿主機的作業系統,才能呼叫硬體,而是可以直接由虛擬機器監視器去呼叫硬體。
在Type-1型的虛擬機器裡,我們的虛擬機器監視器其實並不是一個作業系統之上的應用層程式,而是一個嵌入在作業系統核心裡面的一部分。
### Docker
在我們實際的物理機上,我們可能同時運行了多個的虛擬機器,而這每一個虛擬機器,都運行了一個屬於自己的單獨的作業系統。多執行一個作業系統,意味著我們要多消耗一些資源在CPU、記憶體乃至磁碟空間上。
在伺服器領域,我們開發的程式都是跑在Linux上的。其實我們並不需要一個獨立的作業系統,只要一個能夠進行資源和環境隔離的“獨立空間”就好了。
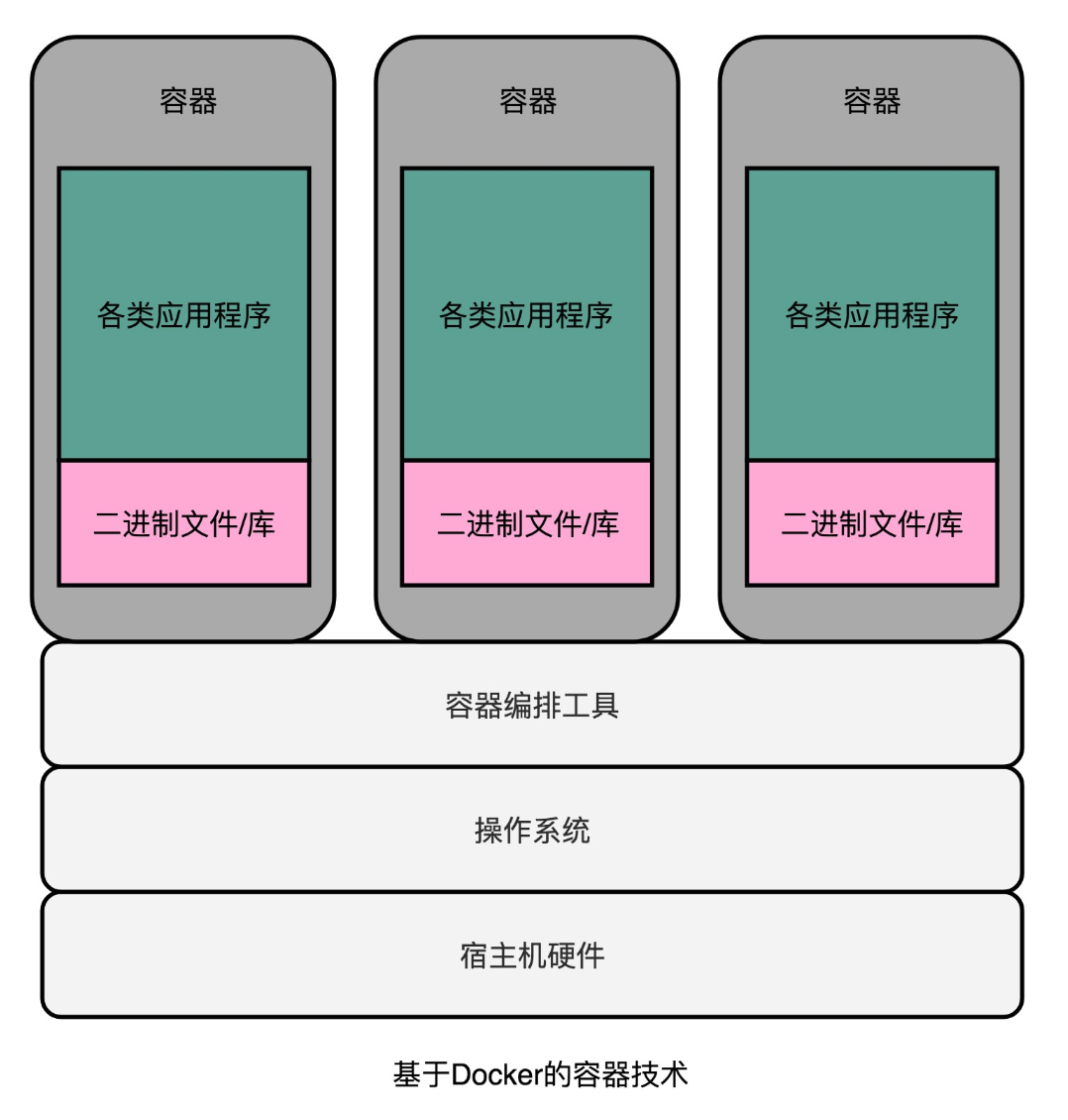
通過Docker,我們不再需要在作業系統上再跑一個作業系統,而只需要通過容器編排工具,比如Kubernetes或者Docker Swarm,能夠進行各個應用之間的環境和資源隔離就好了。
## 儲存器
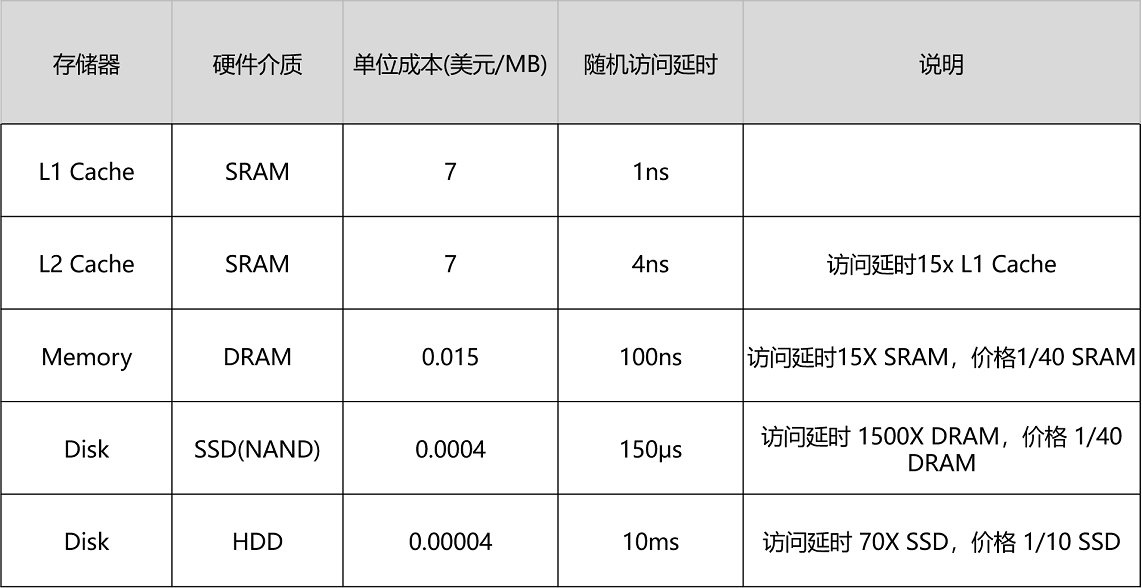
### SRAM
SRAM(Static Random-Access Memory,靜態隨機存取儲存器),被用在CPU Cache中。
SRAM之所以被稱為“靜態”儲存器,是因為只要處在通電狀態,裡面的資料就可以保持存在。而一旦斷電,裡面的資料就會丟失了。在SRAM裡面,一個位元的資料,需要6~8個電晶體。所以SRAM的儲存密度不高。同樣的物理空間下,能夠儲存的資料有限。不過,因為SRAM的電路簡單,所以訪問速度非常快。
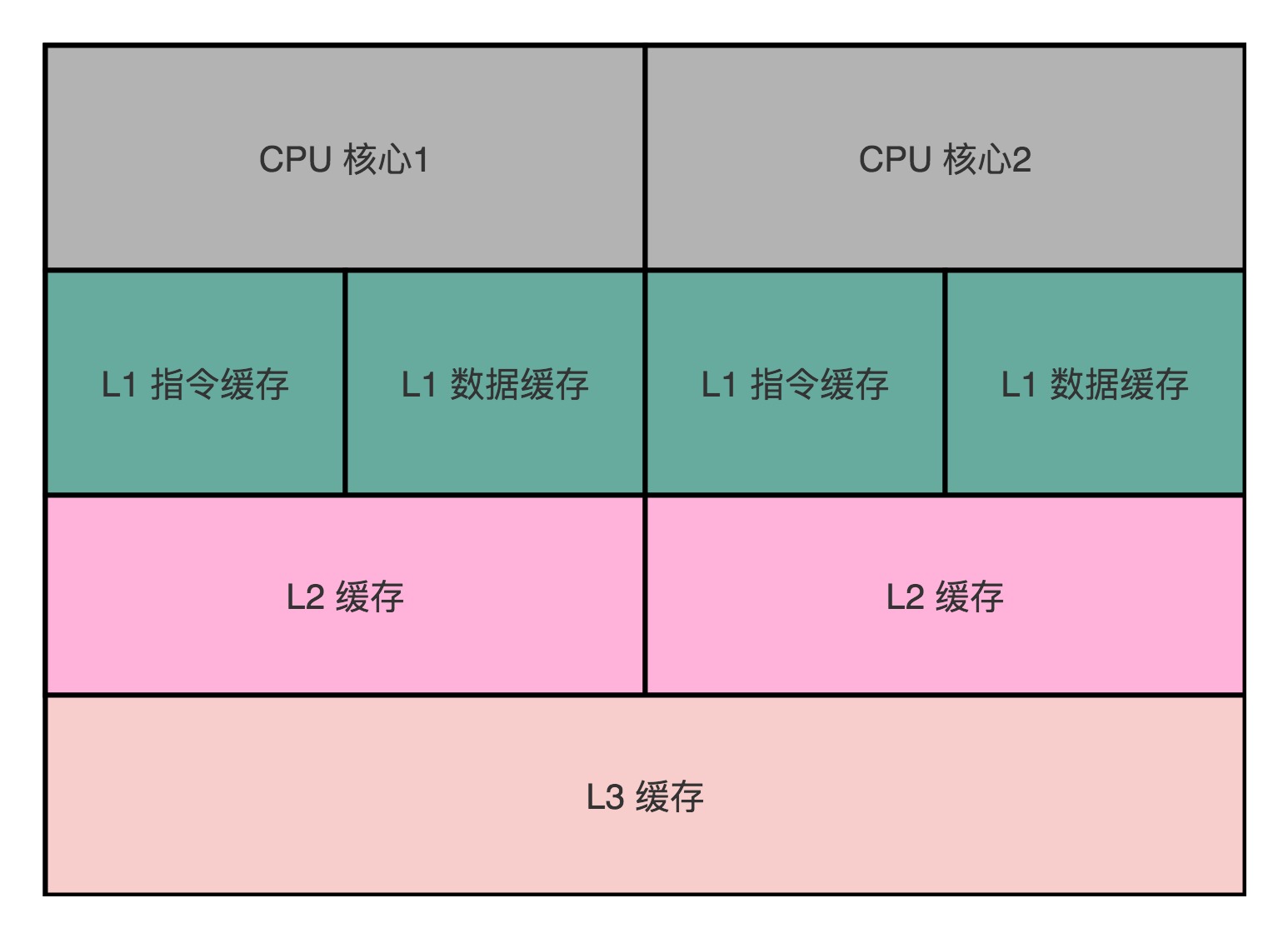
在CPU裡,通常會有L1、L2、L3這樣三層快取記憶體。每個CPU核心都有一塊屬於自己的L1快取記憶體。
L2的Cache同樣是每個CPU核心都有的,不過它往往不在CPU核心的內部。所以,L2 Cache的訪問速度會比L1稍微慢一些。
L3 Cache,則通常是多個CPU核心共用的,尺寸會更大一些,訪問速度自然也就更慢一些。
### DRAM
記憶體用的晶片是一種叫作DRAM(Dynamic Random Access Memory,動態隨機存取儲存器)的晶片,比起SRAM來說,它的密度更高,有更大的容量,而且它也比SRAM晶片便宜不少。
DRAM被稱為“動態”儲存器,是因為DRAM需要靠不斷地“重新整理”,才能保持資料被儲存起來。DRAM的一個位元,只需要一個電晶體和一個電容就能儲存。所以,DRAM在同樣的物理空間下,能夠儲存的資料也就更多,也就是儲存的“密度”更大。
## CPU Cache
目前看來,一次記憶體的訪問,大約需要120個CPU Cycle,這也意味著,在今天,CPU和記憶體的訪問速度已經有了120倍的差距。
為了彌補兩者之間的效能差異,我們能真實地把CPU的效能提升用起來,而不是讓它在那兒空轉,我們在現代CPU中引入了快取記憶體。
CPU從記憶體中讀取資料到CPU Cache的過程中,是一小塊一小塊來讀取資料的,而不是按照單個數組元素來讀取資料的。這樣一小塊一小塊的資料,在CPU Cache裡面,我們把它叫作Cache Line(快取塊)。
在我們日常使用的Intel伺服器或者PC裡,Cache Line的大小通常是64位元組。
### 直接對映Cache(Direct Mapped Cache)
對於讀取記憶體中的資料,我們首先拿到的是資料所在的記憶體塊(Block)的地址。而直接對映Cache採用的策略,就是確保任何一個記憶體塊的地址,始終對映到一個固定的CPU Cache地址(Cache Line)。而這個對映關係,通常用mod運算(求餘運算)來實現。
比如說,我們的主記憶體被分成0~31號這樣32個塊。我們一共有8個快取塊。使用者想要訪問第21號記憶體塊。如果21號記憶體塊內容在快取塊中的話,它一定在5號快取塊(21 mod 8 = 5)中。
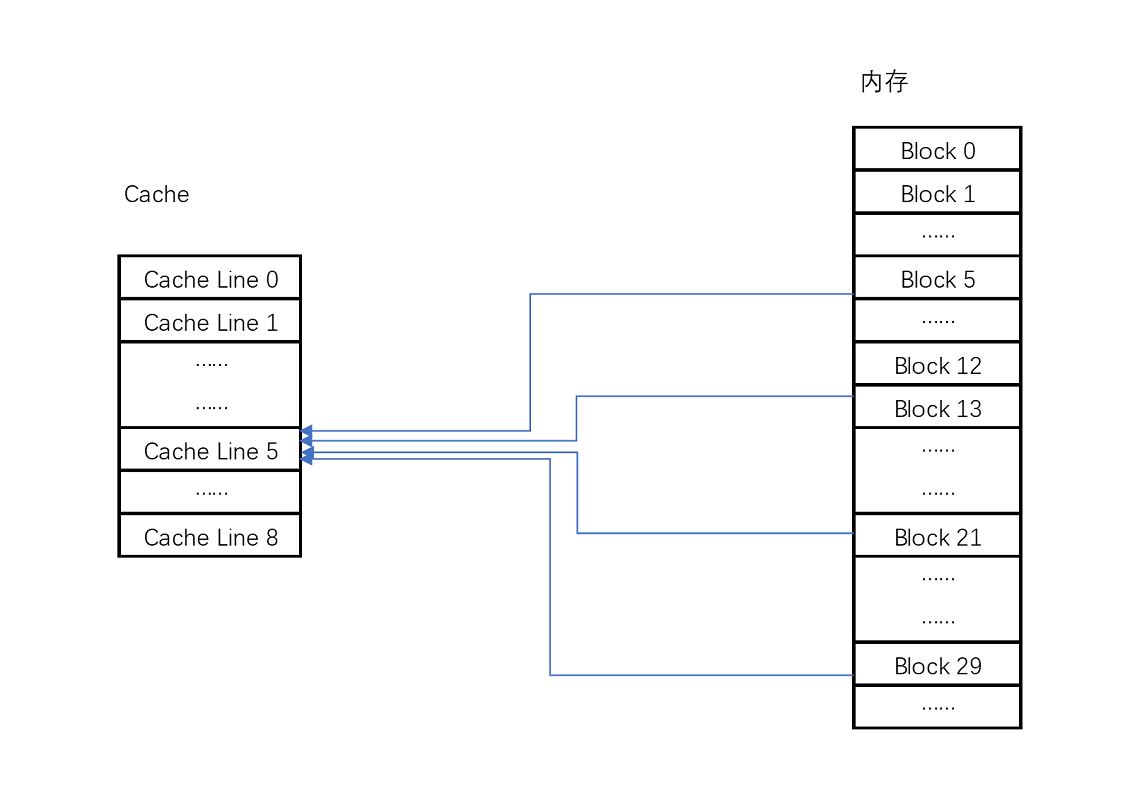
在對應的快取塊中,我們會儲存一個組標記(Tag)。這個組標記會記錄,當前快取塊記憶體儲的資料對應的記憶體塊,而快取塊本身的地址表示訪問地址的低N位。
除了組標記資訊之外,快取塊中還有兩個資料。一個自然是從主記憶體中載入來的實際存放的資料,另一個是**有效位**(valid bit)。啥是有效位呢?它其實就是用來標記,對應的快取塊中的資料是否是有效的,確保不是機器剛剛啟動時候的空資料。如果有效位是0,無論其中的組標記和Cache Line裡的資料內容是什麼,CPU都不會管這些資料,而要直接訪問記憶體,重新載入資料。
CPU在讀取資料的時候,並不是要讀取一整個Block,而是讀取一個他需要的整數。這樣的資料,我們叫作CPU裡的一個字(Word)。具體是哪個字,就用這個字在整個Block裡面的位置來決定。這個位置,我們叫作偏移量(Offset)。
**一個記憶體的訪問地址,最終包括高位代表的組標記、低位代表的索引,以及在對應的Data Block中定位對應字的位置偏移量。**
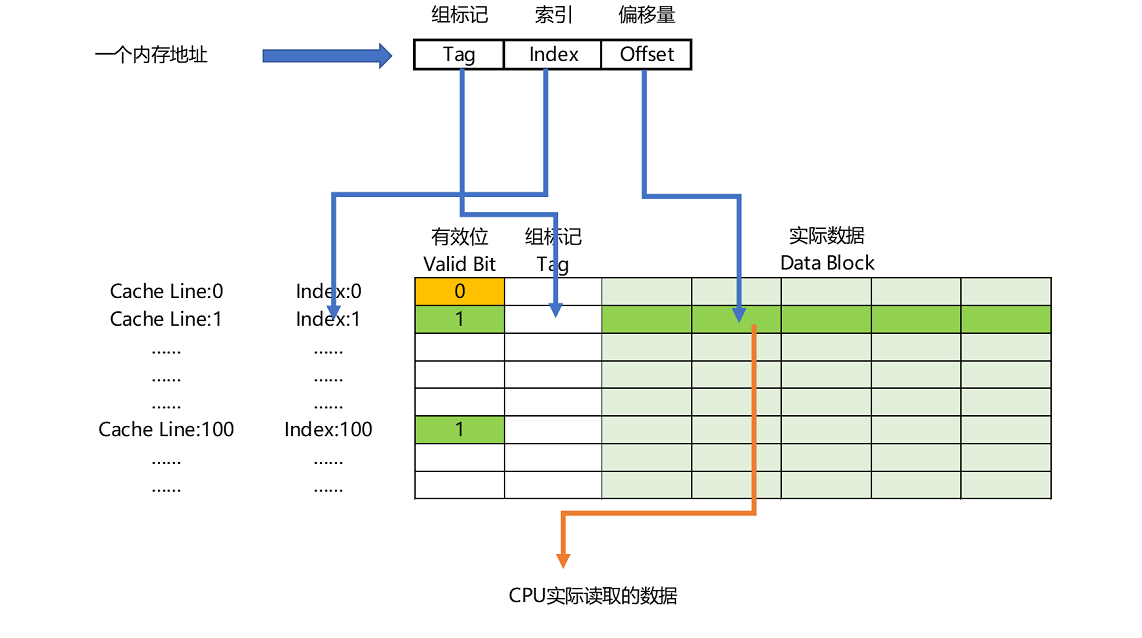
如果記憶體中的資料已經在CPU Cache裡了,那一個記憶體地址的訪問,就會經歷這樣4個步驟:
1. 根據記憶體地址的低位,計算在Cache中的索引;
2. 判斷有效位,確認Cache中的資料是有效的;
3. 對比記憶體訪問地址的高位,和Cache中的組標記,確認Cache中的資料就是我們要訪問的記憶體資料,從Cache Line中讀取到對應的資料塊(Data Block);
4. 根據記憶體地址的Offset位,從Data Block中,讀取希望讀取到的字。
### CPU快取記憶體的寫入
每一個CPU核裡面,都有獨立屬於自己的L1、L2的Cache,然後再有多個CPU核共用的L3的Cache、主記憶體。
#### 寫直達(Write-Through)
最簡單的一種寫入策略,叫作寫直達(Write-Through)。在這個策略裡,每一次資料都要寫入到主記憶體裡面。在寫直達的策略裡面,寫入前,我們會先去判斷資料是否已經在Cache裡面了。如果資料已經在Cache裡面了,我們先把資料寫入更新到Cache裡面,再寫入到主記憶體裡面;如果資料不在Cache裡,我們就只更新主記憶體。
這個策略很慢。無論資料是不是在Cache裡面,我們都需要把資料寫到主記憶體裡面。
#### 寫回(Write-Back)
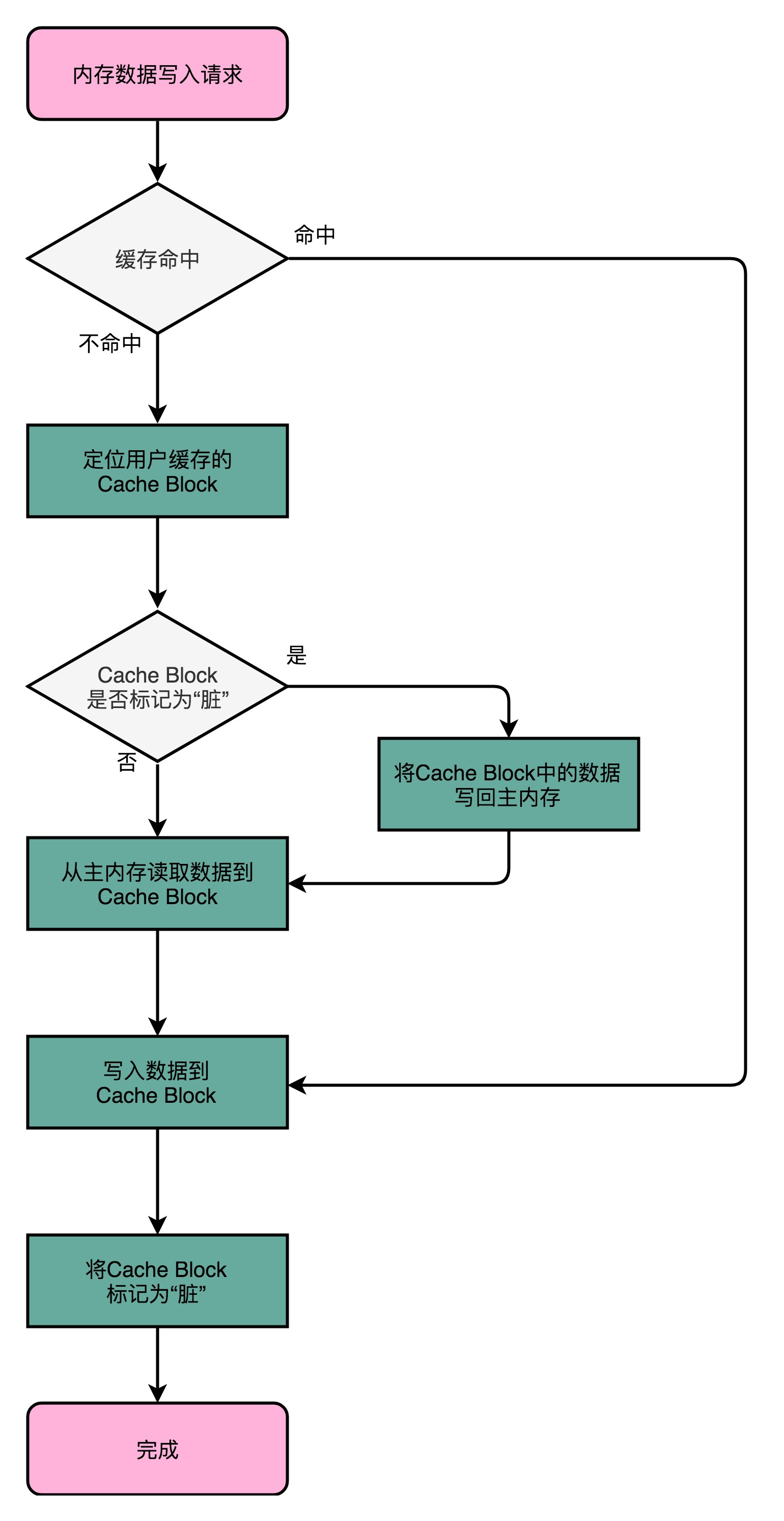
如果發現我們要寫入的資料,就在CPU Cache裡面,那麼我們就只是更新CPU Cache裡面的資料。同時,我們會標記CPU Cache裡的這個Block是髒(Dirty)的。所謂髒的,就是指這個時候,我們的CPU Cache裡面的這個Block的資料,和主記憶體是不一致的。
如果我們發現,我們要寫入的資料所對應的Cache Block裡,放的是別的記憶體地址的資料,那麼我們就要看一看,那個Cache Block裡面的資料有沒有被標記成髒的。如果是髒的話,我們要先把這個Cache Block裡面的資料,寫入到主記憶體裡面。
然後,再把當前要寫入的資料,寫入到Cache裡,同時把Cache Block標記成髒的。如果Block裡面的資料沒有被標記成髒的,那麼我們直接把資料寫入到Cache裡面,然後再把Cache Block標記成髒的就好了。
### MESI協議:讓多核CPU的快取記憶體保持一致
MESI協議,是一種叫作寫失效(Write Invalidate)的協議。在寫失效協議裡,只有一個CPU核心負責寫入資料,其他的核心,只是同步讀取到這個寫入。在這個CPU核心寫入Cache之後,它會去廣播一個“失效”請求告訴所有其他的CPU核心。其他的CPU核心,只是去判斷自己是否也有一個“失效”版本的Cache Block,然後把這個也標記成失效的就好了。
MESI協議對Cache Line的四個不同的標記,分別是:
* M:代表已修改(Modified)
* E:代表獨佔(Exclusive)
* S:代表共享(Shared)
* I:代表已失效(Invalidated)
所謂的“已修改”,就是我們上一講所說的“髒”的Cache Block。Cache Block裡面的內容我們已經更新過了,但是還沒有寫回到主記憶體裡面。
所謂的“已失效“,自然是這個Cache Block裡面的資料已經失效了,我們不可以相信這個Cache Block裡面的資料。
在獨佔狀態下,對應的Cache Line只加載到了當前CPU核所擁有的Cache裡。其他的CPU核,並沒有載入對應的資料到自己的Cache裡。這個時候,如果要向獨佔的Cache Block寫入資料,我們可以自由地寫入資料,而不需要告知其他CPU核。
在獨佔狀態下的資料,如果收到了一個來自於匯流排的讀取對應快取的請求,它就會變成共享狀態。這個共享狀態是因為,這個時候,另外一個CPU核心,也把對應的Cache Block,從記憶體裡面載入到了自己的Cache裡來。
而**在共享狀態下**,因為同樣的資料在多個CPU核心的Cache裡都有。所以,當我們想要更新Cache裡面的資料的時候,**不能直接修改**,而是要先向所有的其他CPU核心廣播一個請求,要求先把其他CPU核心裡面的Cache,都變成無效的狀態,然後再更新當前Cache裡面的資料。這個廣播操作,一般叫作RFO(Request For Ownership),也就是獲取當前對應Cache Block資料的所