
廣告行業中那些趣事系列7:實戰騰訊開源的文字分類專案NeuralClassifier

摘要:本篇主要分享騰訊開源的文字分類專案NeuralClassifier。雖然實際專案中使用BERT進行文字分類,但是在不同的場景下我們可能還需要使用其他的文字分類演算法,比如TextCNN、RCNN等等。通過NeuralClassifier開源專案我們可以方便快捷的使用這些模型。本篇並不會重點剖析某個演算法,而是從整體的角度使用NeuralClassifier開源工程,更多的是以演算法庫的方式根據不同的業務場景為我們靈活的提供文字分類演算法。
目錄
01 不僅僅是BERT
02 騰訊開源文字分類專案NeuralClassifier
03 第一步先跑通它
04 改造成我們的基於中文的多分類任務
總結
01 不僅僅是BERT
之前說過BERT是NLP領域中具有里程碑意義的成果,具有效果好和應用範圍廣的優點。雖然實際專案中我們主要使用BERT來做文字分類任務,但是在不同的場景下我們可能還需要使用其他的文字分類演算法。除此之外,我們不能僅僅只會用BERT,還需要掌握一些BERT出現之前的文字分類演算法,能更好的幫助我們瞭解文字分類任務背景下模型的發展歷史。
BERT之前主要用於文字分類的模型有TextCNN、RCNN、FastText等,這些模型也擁有各自的優點。充分了解這些模型各自的優缺點,才能在不同的場景下更好的使用這些模型。
之前看到騰訊開源了一個文字分類開源專案NeuralClassifier,裡面集成了很多演算法,其中就包括上面說的TextCNN、RCNN、FastText等。所以想基於該開源專案進行二次開發以便後續用於實際專案中。
02 騰訊開源文字分類專案NeuralClassifier
本篇的重點是講解NeuralClassifier開源專案, 專案的github地址如下:
https://github.com/Tencent/NeuralNLP-NeuralClassifier
1. 專案整體架構
專案整體架構如下圖所示:
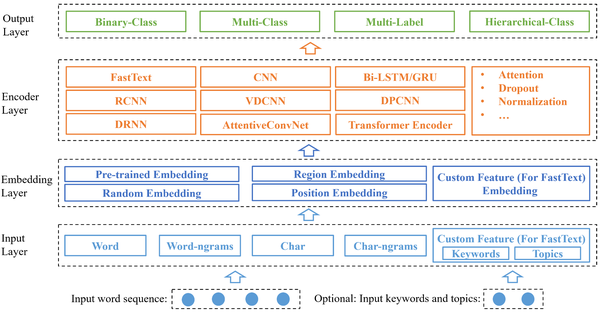 圖1 專案整體架構圖
圖1 專案整體架構圖
從下往上依次檢視,最下面是輸入的語句,因為原始專案中主要是針對英文分類,所以輸入的句子序列是一系列詞,這是主要識別的文字,所以是必須要有的。可選的輸入是文字是否有關鍵詞或者主題;
然後是Input Layer,這裡可能是詞、詞的組合、字元和字元的組合等。如果有關鍵詞或者主題也會作為特徵進入模型;
接著是Embedding Layer,這裡可以使用不同的Embedding方式,包括預訓練編碼、隨機編碼、位置編碼等等;
然後是Encoder Layer,這裡主要使用不同的演算法,比如FastText、CNN、RCNN、Transformer等等;
最後就是Output Layer,根據不同的任務型別輸出不同的結果。
2. 專案支援的任務型別
專案支援的任務型別主要有:
- Binary-class text classifcation:二分類任務
- Multi-class text classification:多分類任務
- Multi-label text classification:多標籤任務
- Hiearchical (multi-label) text classification (HMC):多層多標籤任務
前面三個比較好理解,咱們重點講下第四個多層多標籤任務。
實際專案中我們已經不再是單純的多分類了,而是擁有一個比較複雜的類目體系,這個類目體系一般是以樹的形式展示。對應本專案就是data/rcv1.taxonomy檔案。詳細解讀下這個檔案,第一行表示存在四個一級類目,分別是CCAT、ECAT、GCAT、MCAT。第二行代表CCAT這個一級類目下擁有的二級類目。依次類推,第三行代表C15這個二級類目下還有兩個三級類目,第四行代表C151這個三級類目下還有兩個四級類目。下圖展示類目體系檔案並通過EXCEL的方式更好的展示下這個層級類目:
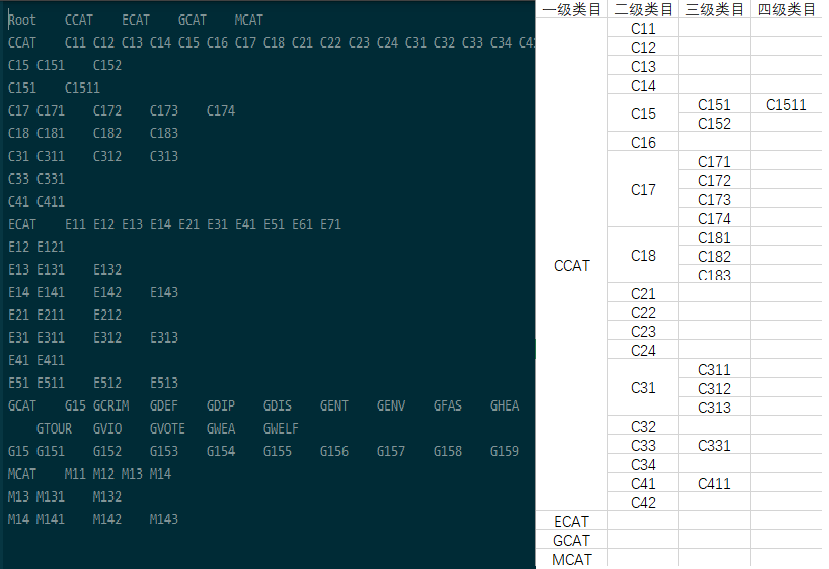 圖2 類目體系檔案和EXCEL展示類目體系
圖2 類目體系檔案和EXCEL展示類目體系
為了方便顯示,上圖EXCEL中只展示了rcv1.taxonomy檔案前9行的類目結構。這樣小夥伴們應該對這個類目體系有一定的瞭解。實際專案中一般是三到四級的類目體系,這個主要根據業務複雜程度來定。
這裡咱們舉一反三,如果現在需要做一個多分類任務的話,那麼我們這個類目體系的配置檔案只需要一行就夠了:Root label1 label2 label3…labelx
瞭解了類目體系,我們回過來說這個多層多標籤任務。拿data目錄下的訓練集rcv1_train.json第一條資料對應到類目體系中,這條資料既屬於CCAT一級類目,還屬於C31二級類目,並且還屬於C312三級類目。具體如下圖所示:
 圖3 訓練集資料抽樣和類目對應展示
圖3 訓練集資料抽樣和類目對應展示
通俗的說,就是多層多標籤任務會將這條文字資料的標籤以及該標籤的父級類目都加上。這點其實和我們在實際工作中的理解稍微有點不同。個人認為類目體系的層級結構一般是存在包含關係,比如C312是屬於CCAT這個一級大類的,那麼如果一條item打上了C312這個標籤,那麼應同時屬於它的二級目錄C31和一級目錄CCAT。item打標一般是標註在最低的層級。這裡的一個猜測是將標籤的層級結構也新增到模型訓練中可能有利於模型訓練。
2. 專案支援的演算法
 圖4 專案支援的演算法
圖4 專案支援的演算法
3. 專案需要的開發環境
- Python 3
- PyTorch 0.4+
- Numpy 1.14.3+
03 第一步先跑通它
複用一張前面講ALBERT時用到的圖片,以實用性為主的我一般都是先跑通專案。好處之前也說過,一方面可以增加自信心,另一方面也能快速應用到實際專案中。

通過github將專案下載到伺服器下。模型訓練通過以下命令:
python train.py conf/train.json
這裡需要著重講下train.json檔案,這個檔案是相關的任務配置資訊,包括任務型別、使用演算法、訓練集目錄、類目體系目錄以及模型訓練中的相關引數等。如果只是跑通樣例程式碼,那麼不用任何改動。原始配置中任務型別是多標籤任務("label_type": "multi_label"),具有層級結構("hierarchical": true),使用TextCNN演算法("model_name": "TextCNN"),並且在data目錄下配置了訓練集、驗證集和測試集。這是模型訓練流程最主要的幾個引數,其他更多的是模型內部的引數,這裡預設就好。
模型驗證和預測流程通過以下命令:
python eval.py conf/train.json
python predict.py conf/train.json data/predict.json
小結下,這節咱們主要是跑通專案提供的例子,例子中是多層多標籤任務,使用TextCNN演算法,包括模型訓練、驗證和預測流程。
04 改造成我們的基於中文的多分類任務
這裡咱們通過一個實際專案改造,假如我們現在需要構建一個多分類模型。專案改造的github地址如下:https://github.com/wilsonlsm006/NeuralNLP-NeuralClassifier
原始專案中是英文的文字分類任務,對應到實際專案中主要是中文的文字分類,所以資料預處理方面要做兩個改造:
改造1:我們之前的模型輸入資料都是讀取csv檔案,欄位為item,label。而本專案中的資料是從json檔案讀取,資料格式是:
 圖6 資料標準輸入格式
圖6 資料標準輸入格式
其中doc_label和doc_token分別對應上面的label和item,都是必選項。doc_keyword和doc_topic可選,分別代表關鍵詞和主題。
改造2:原始專案中使用英文,而實際專案中使用的中文,所以涉及到中文分詞的問題。這裡主要使用目前比較火的jieba分詞和北大開源的pkuseg分詞。
上面的兩個改造程式碼都放在data_process.py檔案中,其中包括使用jieba和pkuseg分詞,還包括csv檔案轉換成模型標準輸入json檔案的的程式碼。程式碼有詳細的註釋,應該比較通俗易懂。如果小夥伴們遇到什麼問題可以隨時在公眾號裡滴滴我。
資料預處理改造完成後需要根據實際專案修改模型配置檔案。這裡因為我們是多分類任務,所以我們需要設定"label_type": "single_label"。因為不需要分層,所以設定"hierarchical": false。這裡還構造了一個我們自己的類目體系,因為不存在分層,所以標籤都在同一層級,類目體系只有一行,設定為Root 0 1。模型使用TextCNN演算法,所以"model_name":"TextCNN"。相關的訓練集、驗證集和測試集都存放在data2目錄下,這三個檔案是我們通過上面的資料處理器將csv檔案加工成json資料格式。
激動人心的時候到了,只需要通過以下命令就可以進行模型訓練:
python train.py conf/train2.json
小結下:本節主要通過一個多分類模型入手對原專案進行二次開發,第一步是將csv檔案抽取資料加工成模型標準的輸入格式json檔案。因為實際專案是對中文進行文字分類,而原專案主要是對英文,所以涉及到中文的分詞,主要使用目前比較火的jieba分詞和北大開源的pkuseg分詞。這樣咱們就完成了一個實際專案的改造。
總結
本篇主要分享騰訊開源的文字分類專案NeuralClassifier。雖然實際專案中使用BERT進行文字分類,但是在不同的場景下我們可能還需要使用其他的文字分類演算法,比如TextCNN、RCNN等等。通過NeuralClassifier開源專案我們可以方便快捷的使用這些模型。然後從專案架構、支援的任務型別、支援的文字分類演算法等方面重點講解開源專案NeuralClassifier。接著,根據專案說明跑通了專案例項。最後,從實際需求出發,新增資料預處理功能,將專案改造成多分類模型。本篇並不會重點剖析某個演算法,而是從整體的角度使用NeuralClassifier開源工程,更多的是以演算法庫的方式根據不同的業務場景為我們靈活的提供文字分類演算法。
 釋出於 10:
釋出於 10: