
CS231n課程筆記:影象分類筆記(下)

用於超引數調優的驗證集
k-NN分類器需要設定k值,那麼選擇哪個k值最合適的呢?我們可以選擇不同的距離函式,比如L1範數和L2範數等,那麼選哪個好?還有不少選擇我們甚至連考慮都沒有考慮到(比如:點積)。所有這些選擇,被稱為超引數(hyperparameter)。在基於資料進行學習的機器學習演算法設計中,超引數是很常見的。一般說來,這些超引數具體怎麼設定或取值並不是顯而易見的。
你可能會建議嘗試不同的值,看哪個值表現最好就選哪個。好主意!我們就是這麼做的,但這樣做的時候要非常細心。特別注意:決不能使用測試集來進行調優。當你在設計機器學習演算法的時候,應該把測試集看做非常珍貴的資源,不到最後一步,絕不使用它。如果你使用測試集來調優,而且演算法看起來效果不錯,那麼真正的危險在於:演算法實際部署後,效能可能會遠低於預期。這種情況,稱之為演算法對測試集過擬合。從另一個角度來說,如果使用測試集來調優,實際上就是把測試集當做訓練集,由測試集訓練出來的演算法再跑測試集,自然效能看起來會很好。這其實是過於樂觀了,實際部署起來效果就會差很多。所以,最終測試的時候再使用測試集,可以很好地近似度量你所設計的分類器的泛化效能(在接下來的課程中會有很多關於泛化效能的討論)。
測試資料集只使用一次,即在訓練完成後評價最終的模型時使用。
好在我們有不用測試集調優的方法。其思路是:從訓練集中取出一部分資料用來調優,我們稱之為驗證集(validation set)。以CIFAR-10為例,我們可以用49000個影象作為訓練集,用1000個影象作為驗證集。驗證集其實就是作為假的測試集來調優。下面就是程式碼:
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation 程式結束後,我們會作圖分析出哪個k值表現最好,然後用這個k值來跑真正的測試集,並作出對演算法的評價。
把訓練集分成訓練集和驗證集。使用驗證集來對所有超引數調優。最後只在測試集上跑一次並報告結果。
交叉驗證。有時候,訓練集數量較小(因此驗證集的數量更小),人們會使用一種被稱為交叉驗證的方法,這種方法更加複雜些。還是用剛才的例子,如果是交叉驗證集,我們就不是取1000個影象,而是將訓練集平均分成5份,其中4份用來訓練,1份用來驗證。然後我們迴圈著取其中4份來訓練,其中1份來驗證,最後取所有5次驗證結果的平均值作為演算法驗證結果。
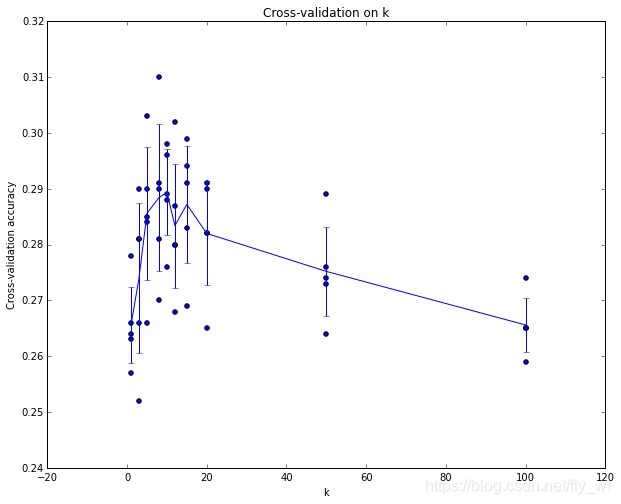
這就是5份交叉驗證對k值調優的例子。針對每個k值,得到5個準確率結果,取其平均值,然後對不同k值的平均表現畫線連線。本例中,當k=7的時演算法表現最好(對應圖中的準確率峰值)。如果我們將訓練集分成更多份數,直線一般會更加平滑(噪音更少)。
實際應用.在實際情況下,人們不是很喜歡用交叉驗證,主要是因為它會耗費較多的計算資源。一般直接把訓練集按照50%-90%的比例分成訓練集和驗證集。但這也是根據具體情況來定的:如果超引數數量多,你可能就想用更大的驗證集,而驗證集的數量不夠,那麼最好還是用交叉驗證吧。至於分成幾份比較好,一般都是分成3、5和10份。

常用的資料分割模式。給出訓練集和測試集後,訓練集一般會被均分。這裡是分成5份。前面4份用來訓練,黃色那份用作驗證集調優。如果採取交叉驗證,那就各份輪流作為驗證集。最後模型訓練完畢,超引數都定好了,讓模型跑一次(而且只跑一次)測試集,以此測試結果評價演算法。
Nearest Neighbor分類器的優劣
現在對Nearest Neighbor分類器的優缺點進行思考。首先,Nearest Neighbor分類器易於理解,實現簡單。其次,演算法的訓練不需要花時間,因為其訓練過程只是將訓練集資料儲存起來。然而測試要花費大量時間計算,因為每個測試影象需要和所有儲存的訓練影象進行比較,這顯然是一個缺點。在實際應用中,我們關注測試效率遠遠高於訓練效率。其實,我們後續要學習的卷積神經網路在這個權衡上走到了另一個極端:雖然訓練花費很多時間,但是一旦訓練完成,對新的測試資料進行分類非常快。這樣的模式就符合實際使用需求。
Nearest Neighbor分類器的計算複雜度研究是一個活躍的研究領域,若干Approximate Nearest Neighbor (ANN)演算法和庫的使用可以提升Nearest Neighbor分類器在資料上的計算速度(比如:FLANN)。這些演算法可以在準確率和時空複雜度之間進行權衡,並通常依賴一個預處理/索引過程,這個過程中一般包含kd樹的建立和k-means演算法的運用。
Nearest Neighbor分類器在某些特定情況(比如資料維度較低)下,可能是不錯的選擇。但是在實際的影象分類工作中,很少使用。因為影象都是高維度資料(他們通常包含很多畫素),而高維度向量之間的距離通常是反直覺的。下面的圖片展示了基於畫素的相似和基於感官的相似是有很大不同的:
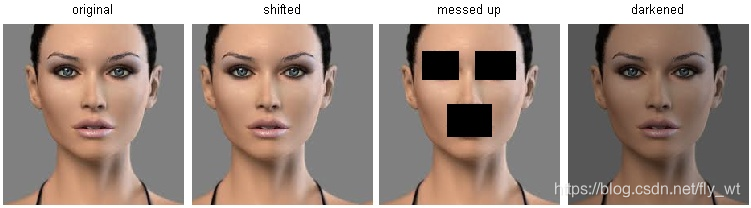
在高維度資料上,基於畫素的的距離和感官上的非常不同。上圖中,右邊3張圖片和左邊第1張原始圖片的L2距離是一樣的。很顯然,基於畫素比較的相似和感官上以及語義上的相似是不同的。
這裡還有個視覺化證據,可以證明使用畫素差異來比較影象是不夠的。z這是一個叫做t-SNE的視覺化技術,它將CIFAR-10中的圖片按照二維方式排布,這樣能很好展示圖片之間的畫素差異值。在這張圖片中,排列相鄰的圖片L2距離就小。

上圖使用t-SNE的視覺化技術將CIFAR-10的圖片進行了二維排列。排列相近的圖片L2距離小。可以看出,圖片的排列是被背景主導而不是圖片語義內容本身主導。
——————————————————————————————————————————
具體說來,這些圖片的排布更像是一種顏色分佈函式,或者說是基於背景的,而不是圖片的語義主體。比如,狗的圖片可能和青蛙的圖片非常接近,這是因為兩張圖片都是白色背景。從理想效果上來說,我們肯定是希望同類的圖片能夠聚集在一起,而不被背景或其他不相關因素干擾。為了達到這個目的,我們不能止步於原始畫素比較,得繼續前進。
小結
簡要說來:
- 介紹了影象分類問題。在該問題中,給出一個由被標註了分類標籤的影象組成的集合,要求演算法能預測沒有標籤的影象的分類標籤,並根據演算法預測準確率進行評價。
- 介紹了一個簡單的影象分類器:最近鄰分類器(Nearest Neighbor classifier)。分類器中存在不同的超引數(比如k值或距離型別的選取),要想選取好的超引數不是一件輕而易舉的事。
- 選取超引數的正確方法是:將原始訓練集分為訓練集和驗證集,我們在驗證集上嘗試不同的超引數,最後保留表現最好那個。
- 如果訓練資料量不夠,使用交叉驗證方法,它能幫助我們在選取最優超引數的時候減少噪音。
- 一旦找到最優的超引數,就讓演算法以該引數在測試集跑且只跑一次,並根據測試結果評價演算法。
- 最近鄰分類器能夠在CIFAR-10上得到將近40%的準確率。該演算法簡單易實現,但需要儲存所有訓練資料,並且在測試的時候過於耗費計算能力。
- 最後,我們知道了僅僅使用L1和L2範數來進行畫素比較是不夠的,影象更多的是按照背景和顏色被分類,而不是語義主體分身。
在接下來的課程中,我們將專注於解決這些問題和挑戰,並最終能夠得到超過90%準確率的解決方案。該方案能夠在完成學習就丟掉訓練集,並在一毫秒之內就完成一張圖片的分類。
小結:實際應用k-NN
如果你希望將k-NN分類器用到實處(最好別用到影象上,若是僅僅作為練手還可以接受),那麼可以按照以下流程:
- 預處理你的資料:對你資料中的特徵進行歸一化(normalize),讓其具有零平均值(zero mean)和單位方差(unit variance)。在後面的小節我們會討論這些細節。本小節不討論,是因為影象中的畫素都是同質的,不會表現出較大的差異分佈,也就不需要標準化處理了。
- 如果資料是高維資料,考慮使用降維方法,比如PCA(wiki ref, CS229ref, blog ref)或隨機投影。
- 將資料隨機分入訓練集和驗證集。按照一般規律,70%-90% 資料作為訓練集。這個比例根據演算法中有多少超引數,以及這些超引數對於演算法的預期影響來決定。如果需要預測的超引數很多,那麼就應該使用更大的驗證集來有效地估計它們。如果擔心驗證集數量不夠,那麼就嘗試交叉驗證方法。如果計算資源足夠,使用交叉驗證總是更加安全的(份數越多,效果越好,也更耗費計算資源)。
- 在驗證集上調優,嘗試足夠多的k值,嘗試L1和L2兩種範數計算方式。
- 如果分類器跑得太慢,嘗試使用Approximate Nearest Neighbor庫(比如FLANN)來加速這個過程,其代價是降低一些準確率。
- 對最優的超引數做記錄。記錄最優引數後,是否應該讓使用最優引數的演算法在完整的訓練集上執行並再次訓練呢?因為如果把驗證集重新放回到訓練集中(自然訓練集的資料量就又變大了),有可能最優引數又會有所變化。**在實踐中,不要這樣做。**千萬不要在最終的分類器中使用驗證集資料,這樣做會破壞對於最優引數的估計。直接使用測試集來測試用最優引數設定好的最優模型,得到測試集資料的分類準確率,並以此作為你的kNN分類器在該資料上的效能表現。