
新名詞|什麼是「電源」程式設計師?
什麼是計算機系統
計算機系統(A computer system) 是由硬體和軟體組成的,它們協同工作執行程式。不同的系統可能會有不同實現,但是核心概念是一樣的,通用的。
不同的系統有 Microsoft Windows、Apple Mac OS X、Linux 等。
所有的計算機系統都有相似的軟體和硬體組成,它們執行相似的功能。
你想要什麼
首先,問你一個問題,你想成為哪種程式設計師?
這是我最近搜尋到的一個很好的開源專案,它的路徑是 https://github.com/keithnull/TeachYourselfCS-CN/blob/master/TeachYourselfCS-CN.md

也就是

我也把它裡面涉及的中文/英文書籍都下載下來了,公眾號回覆 計算機基礎,即可領取。(圖中是馮·諾伊曼)
我一直想成為第一種工程師,即使我永遠成為不了,我也要越來越靠近它。
回到正題

沒錯,我就想成為一種電源程式設計師

一段簡單的程式
這次真的言歸正傳了,下面是一道很簡單的 C 程式(不要管我的名字是 Java建設者還是什麼,Java建設者就不能學習 C 了嗎?雖然飯碗是 Java,但是 C 才是爸爸啊。)
#include <stdio.h> int main(){ pritnf("hello, world\n"); return 0; }
這是用 C 語言輸出的一個 Hello,world 程式,儘管它是一個非常簡單的程式,但系統的每個部分都必須協同工作才能執行。
這段程式的生命週期就是程式設計師建立程式、在系統中執行這段程式、打印出一個簡單的訊息然後終止。
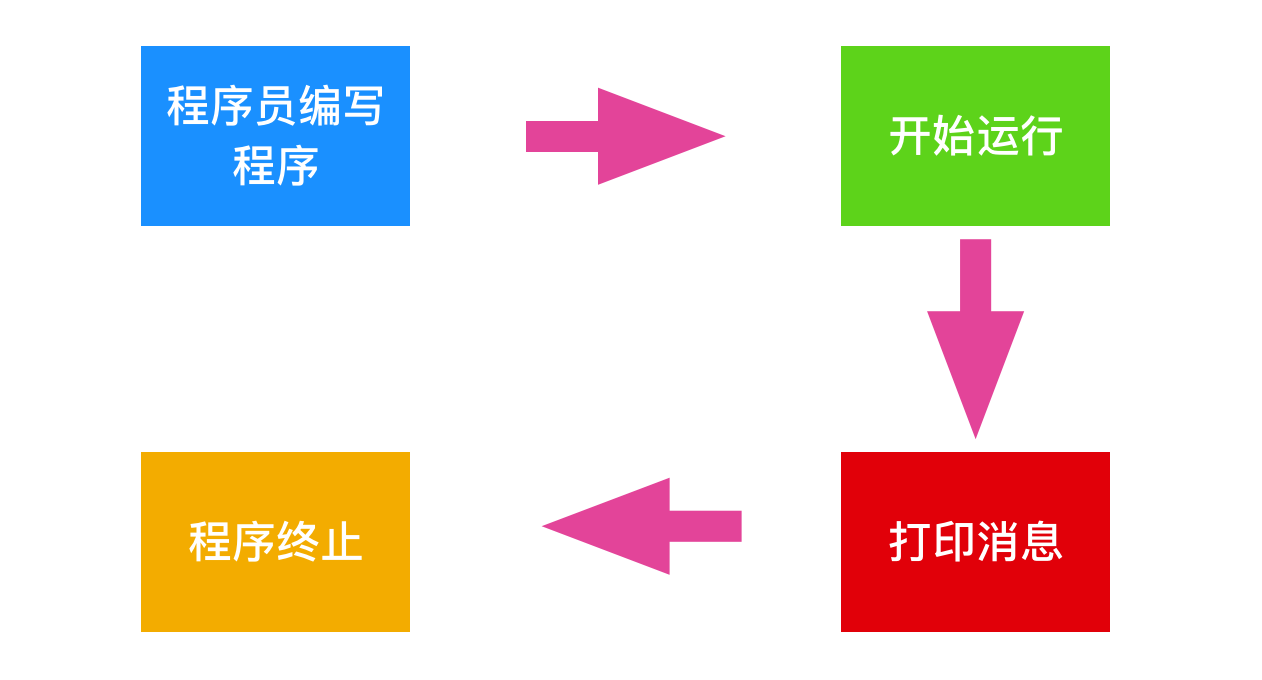
程式設計師首先在文字中建立這段程式碼,這個文字又被稱為原始檔或者源程式,然後儲存為 hello.c 檔案,源程式實際上就是一個由 0 和 1 組成的位(又稱為 位元,即 bit)。8 個 bit 成為一組,稱做 位元組。每個位元組又表示著一個文字字元,這些文字字元通常是由 ASCII 碼組成的,下面是 hello.c 程式的 ASCII 碼

hello.c 程式以位元組順序儲存在檔案中,每個位元組都對應一個整數值,也就是 8 位表示一個整數。比如第一個字元是 35,那這個 35 是從哪來的呢?這其實是有個 ASCII 碼的對照表(因為 ASCII 非常多,可以去 http://ascii.911cha.com/?year=%23 官網查詢,這裡只選取幾個作為參考哦)
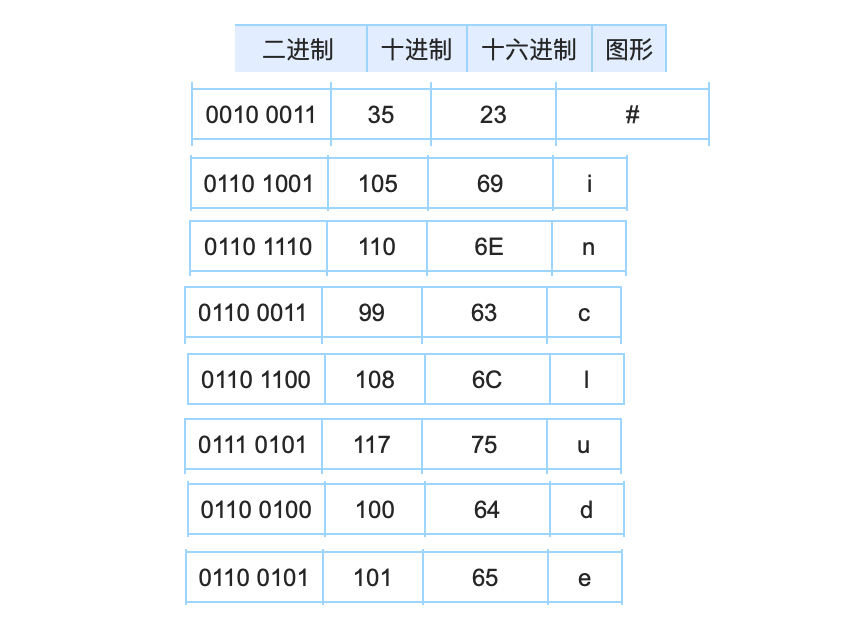
每行都以不可見的 \n 來結尾,它的 ASCII 碼值是 10。
注意;只由 ASCII 字元組成的諸如 hello.c 之類的檔案稱為文字檔案。 所有其他檔案稱為二進位制檔案。
hello.c 的表示方法說明了一個基本思想:系統中所有的資訊 --- 包括磁碟檔案、記憶體中的程式、記憶體中存放的資料以及網路上傳輸的資料,都是由一串位元表示的。區分不同資料物件的唯一方法是我們讀取物件時的上下文,比如,在不同的上下文中,一個同樣的位元組序列可能表示一個整數、浮點數、字串或者機器指令。
為什麼是 C
這裡插播一則新聞,為什麼我們要學 C 語言?學 Java 用不用懂 C 語言?這裡需要聊聊 C 語言的發家史了
C 語言起源於貝爾實驗室。美國國家標準學會 ANSI 在 1981 年頒佈了 ANSI C 的標準,後來 C 就被標準化了,這些標準定義了 C 語言和一系列函式庫,即所謂的
C 語言標準庫,那麼 C 語言有什麼特點呢?
- C 語言與 Unix 作業系統密切關聯。C 從一開始就被開發為 UNIX 系統的程式語言,大部分 UNIX 核心(作業系統和核心部分)和工具,動態庫都是使用 C 編寫的。UNIX 成為 1970 - 1980 年代最火的作業系統,而 C 成為最火的程式語言
- C 是一種非常小巧,簡單的語言。並且 C 語言的簡單使他移植性比較強。
- C 語言是為實踐目的設計的。
我們上面提到了 C 語言的各種優勢,但是 C 語言也並非所有程式設計師都能熟練掌握並運用的,C 語言的指標經常讓很多程式設計師頭疼,C 語言還缺乏對抽象的良好支援,例如類、物件,但是 C++ 和 Java 都解決了這些問題。
程式被其他程式翻譯成不同的形式
C 語言程式成為高階語言的原因是它能夠讀取並理解人們的思想。然而,為了能夠在系統中執行 hello.c 程式,則各個 C 語句必須由其他程式轉換為一系列低階機器語言指令。這些指令被打包作為可執行物件程式,儲存在二進位制磁碟檔案中。目標程式也稱為可執行目標檔案。
在 UNIX 系統中,從原始檔到物件檔案的轉換是由編譯器執行完成的。
gcc -o hello hello.cgcc 編譯器驅動從原始檔讀取 hello.c ,並把它翻譯成一個可執行檔案 hello。這個翻譯過程可用如下圖來表示

這就是一個完整的 hello world 程式執行過程,會涉及幾個核心元件:前處理器、編譯器、彙編器、聯結器,下面我們逐個擊破。
預處理階段(Preprocessing phase),前處理器會根據開始的#字元,修改源 C 程式。#include <stdio.h> 命令就會告訴前處理器去讀系統標頭檔案stdio.h中的內容,並把它插入到程式作為文字。然後就得到了另外一個 C 程式hello.i,這個程式通常是以.i為結尾。- 然後是
編譯階段(Compilation phase),編譯器會把文字檔案hello.i翻譯成文字hello.s,它包括一段組合語言程式(assembly-language program)。這個函式包含 main 函式的定義,如下
main:
subq $8, %rsp
movl $.LCO, %edi
call puts
movl &0, %eax
addq $8, %rsp
ret上面定義中的 2 - 7 描述了一種低階語言指令。組合語言是非常有用的,因為它能夠針對不同高階語言來提供自己的一套標準輸出語言。
- 編譯完成之後是
彙編階段(Assembly phase),這一步,彙編器 as會把 hello.s 翻譯成機器指令,把這些指令打包成可重定位的二進位制程式(relocatable object program)放在 hello.c 檔案中。它包含的 17 個位元組是函式 main 的指令編碼,如果我們在文字編輯器中開啟 hello.c 將會看到一堆亂碼。 - 最後一個是
連結階段(Linking phase),我們的 hello 程式會呼叫printf函式,它是 C 編譯器提供的 C 標準庫中的一部分。printf 函式位於一個叫做printf.o檔案中,它是一個單獨的預編譯好的目標檔案,而這個檔案必須要和我們的 hello.o 進行連結,聯結器(ld)會處理這個合併操作。結果是,hello 檔案,它是一個可執行的目標檔案(或稱為可執行檔案),已準備好載入到記憶體中並由系統執行。
你需要理解編譯系統做了什麼
對於上面這種簡單的 hello 程式來說,我們可以依賴編譯系統(compilation system)來提供一個正確和有效的機器程式碼。然而,對於我們上面講的程式設計師來說,編譯器有幾大特徵你需要知道
優化程式效能(Optimizing program performance),現代編譯器是一種高效的用來生成良好程式碼的工具。對於程式設計師來說,你無需為了編寫高質量的程式碼而去理解編譯器內部做了什麼工作。然而,為了編寫出高效的 C 語言程式,我們需要了解一些基本的機器碼以及編譯器將不同的 C 語句轉化為機器程式碼的過程。理解連結時出現的錯誤(Understanding link-time errors),在我們的經驗中,一些非常複雜的錯誤大多是由連結階段引起的,特別是當你想要構建大型軟體專案時。避免安全漏洞(Avoiding security holes),近些年來,緩衝區溢位(buffer overflow vulnerabilities)是造成網路和 Internet 服務的罪魁禍首,所以我們有必要去規避這種問題
處理器讀取、解釋記憶體中的指令
現在,我們的 hello.c 源程式已經被解釋成為了可執行的 hello 目標程式,它儲存在磁碟上。如果想要在 UNIX 作業系統中執行這個程式,我們需要在 shell 應用程式中輸入
cxuan $ ./hello
hello, world
cxuan $ 這裡解釋下什麼是 shell,shell 其實就是一個命令直譯器,它輸出一個字元,等待使用者輸入一條命令,然後執行這個命令。如果命令列的第一個詞不是 shell 內建的命令,那麼 shell 就會假設這是一個可執行檔案,它會載入並執行這個可執行檔案。
系統硬體組成
為了理解 hello 程式在執行時發生了什麼,我們需要首先對系統的硬體有一個認識。下面這是一張 Intel 系統產品的模型,我們來對其進行解釋
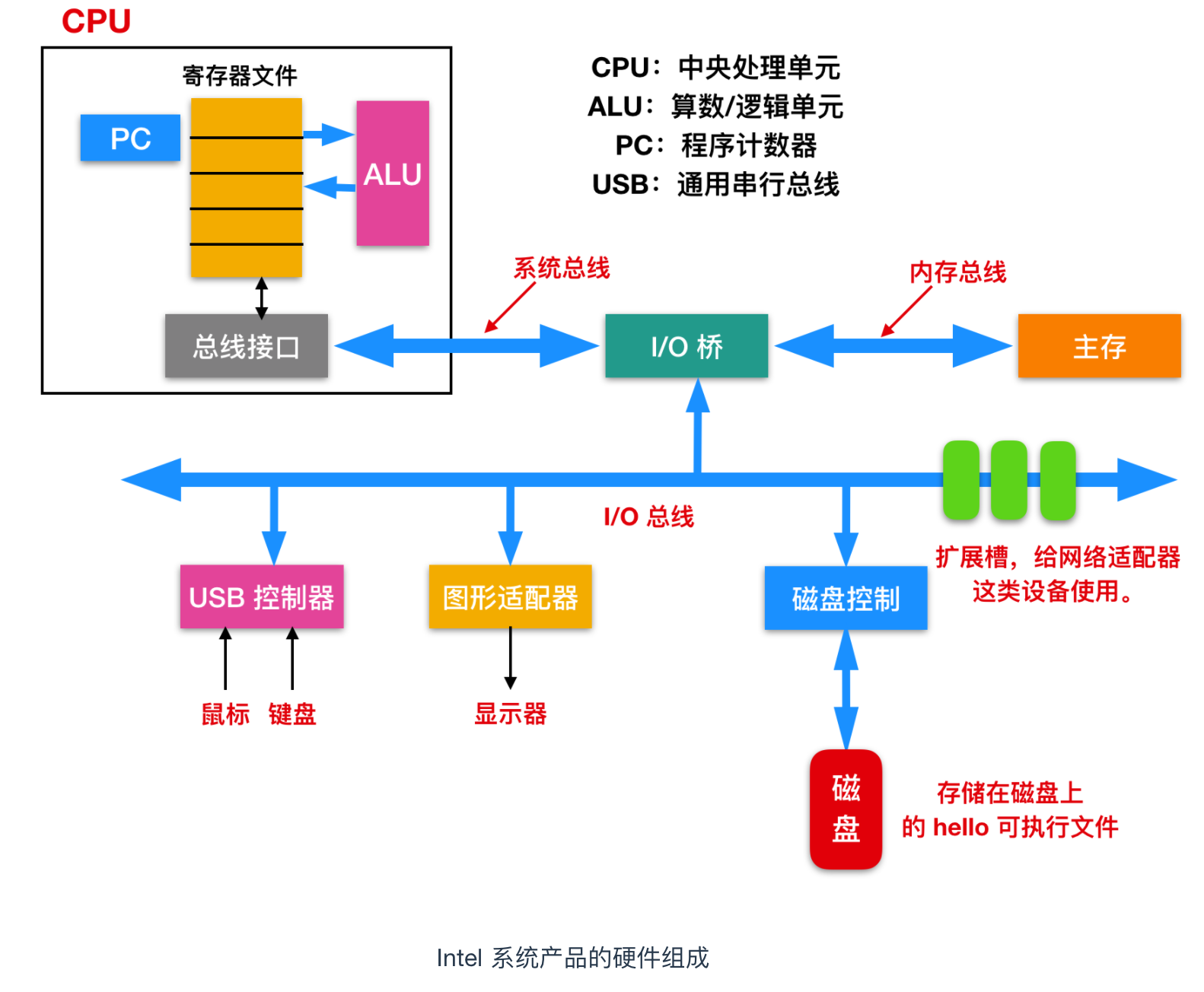
匯流排(Buses):在整個系統中執行的是稱為匯流排的電氣管道的集合,這些匯流排在元件之間來回傳輸位元組資訊。通常匯流排被設計成傳送定長的位元組塊,也就是字(word)。字中的位元組數(字長)是一個基本的系統引數,各個系統中都不盡相同。現在大部分的字都是 4 個位元組(32 位)或者 8 個位元組(64 位)。

I/O 裝置(I/O Devices):Input/Output 裝置是系統和外部世界的連線。上圖中有四類 I/O 裝置:用於使用者輸入的鍵盤和滑鼠,用於使用者輸出的顯示器,一個磁碟驅動用來長時間的儲存資料和程式。剛開始的時候,可執行程式就儲存在磁碟上。每個I/O 裝置連線 I/O 匯流排都被稱為
控制器(controller)或者是介面卡(Adapter)。控制器和介面卡之間的主要區別在於封裝方式。控制器是 I/O 裝置本身或者系統的主印製板電路(通常稱作主機板)上的晶片組。而介面卡則是一塊插在主機板插槽上的卡。無論組織形式如何,它們的最終目的都是彼此交換資訊。主存(Main Memory),主存是一個臨時儲存裝置,而不是永久性儲存,磁碟是永久性儲存的裝置。主存既儲存程式,又儲存處理器執行流程所處理的資料。從物理組成上說,主存是由一系列DRAM(dynamic random access memory)動態隨機儲存構成的集合。邏輯上說,記憶體就是一個線性的位元組陣列,有它唯一的地址編號,從 0 開始。一般來說,組成程式的每條機器指令都由不同數量的位元組構成,C 程式變數相對應的資料項的大小根據型別進行變化。比如,在 Linux 的 x86-64 機器上,short 型別的資料需要 2 個位元組,int 和 float 需要 4 個位元組,而 long 和 double 需要 8 個位元組。處理器(Processor),CPU(central processing unit)或者簡單的處理器,是解釋(並執行)儲存在主儲存器中的指令的引擎。處理器的核心大小為一個字的儲存裝置(或暫存器),稱為程式計數器(PC)。在任何時刻,PC 都指向主存中的某條機器語言指令(即含有該條指令的地址)。從系統通電開始,直到系統斷電,處理器一直在不斷地執行程式計數器指向的指令,再更新程式計數器,使其指向下一條指令。處理器根據其指令集體系結構定義的指令模型進行操作。在這個模型中,指令按照嚴格的順序執行,執行一條指令涉及執行一系列的步驟。處理器從程式計數器指向的記憶體中讀取指令,解釋指令中的位,執行該指令指示的一些簡單操作,然後更新程式計數器以指向下一條指令。指令與指令之間可能連續,可能不連續(比如 jmp 指令就不會順序讀取)
下面是 CPU 可能執行簡單操作的幾個步驟
載入(Load):從主存中拷貝一個位元組或者一個字到記憶體中,覆蓋暫存器先前的內容儲存(Store):將暫存器中的位元組或字複製到主儲存器中的某個位置,從而覆蓋該位置的先前內容操作(Operate):把兩個暫存器的內容複製到ALU(Arithmetic logic unit)。把兩個字進行算術運算,並把結果儲存在暫存器中,重寫暫存器先前的內容。
算術邏輯單元(ALU)是對數字二進位制數執行算術和按位運算的組合數位電子電路。
跳轉(jump):從指令中抽取一個字,把這個字複製到程式計數器(PC)中,覆蓋原來的值
剖析 hello 程式的執行過程
前面我們簡單的介紹了一下計算機的硬體的組成和操作,現在我們正式介紹執行示例程式時發生了什麼,我們會從巨集觀的角度進行描述,不會涉及到所有的技術細節
剛開始時,shell 程式執行它的指令,等待使用者鍵入一個命令。當我們在鍵盤上輸入了 ./hello 這幾個字元時,shell 程式將字元逐一讀入暫存器,再把它放到記憶體中,如下圖所示
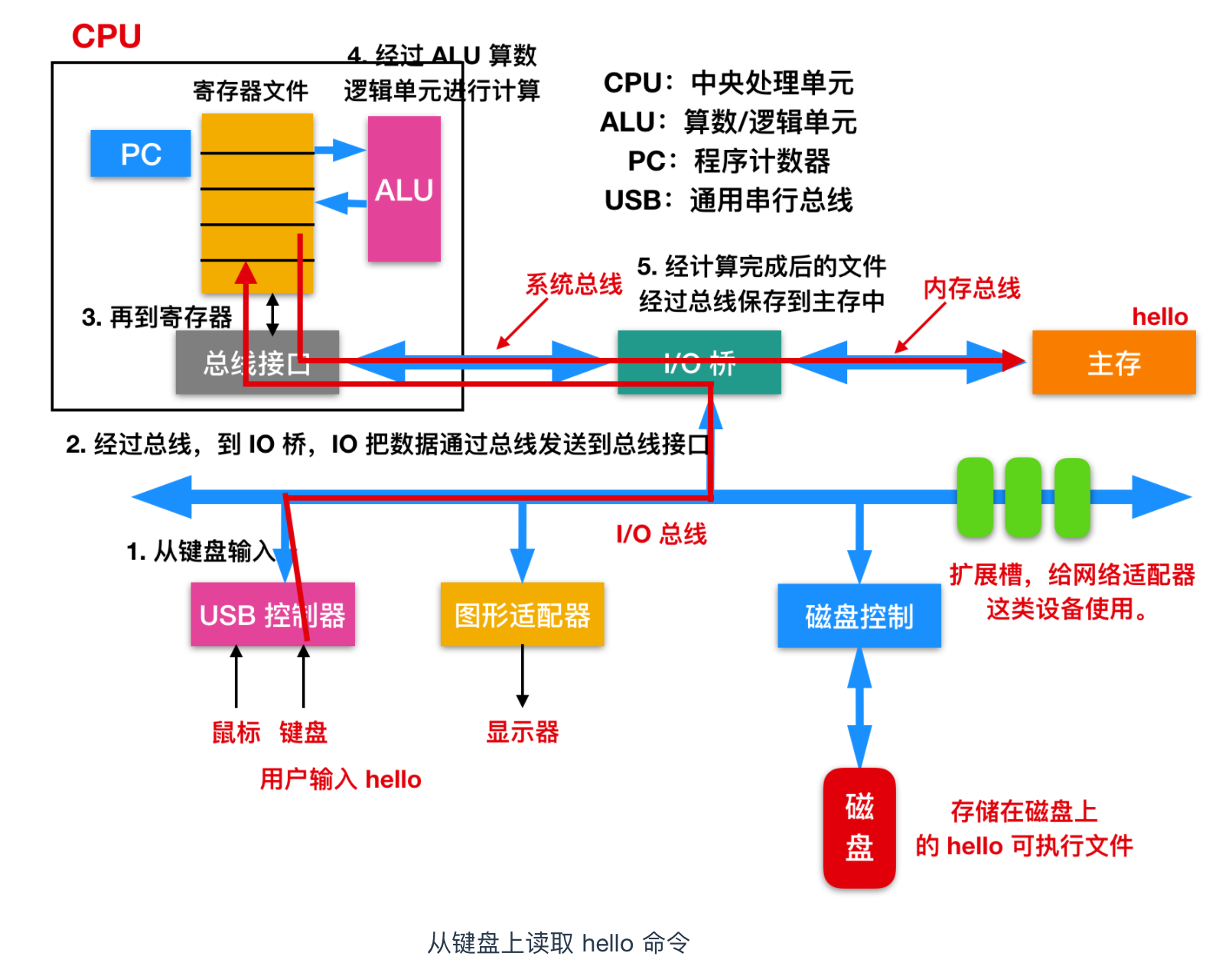
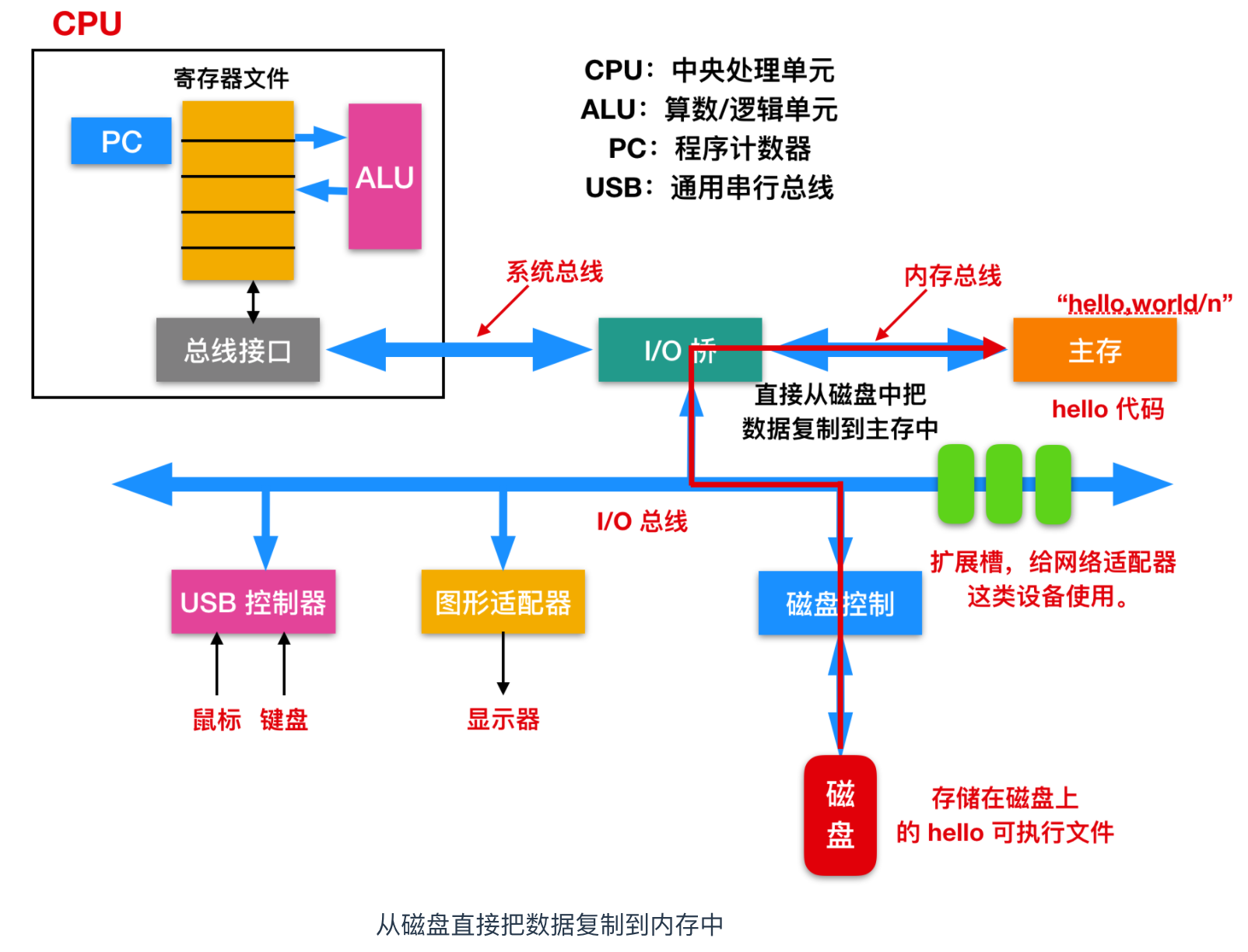
當我們在鍵盤上敲擊回車鍵的時候,shell 程式就知道我們已經結束了命令的輸入。然後 shell 執行一系列指令來載入可執行的 hello 檔案,這些指令將目標檔案中的程式碼和資料從磁碟複製到主存。
利用 DMA(Direct Memory Access) 技術可以直接將磁碟中的資料複製到記憶體中,如下
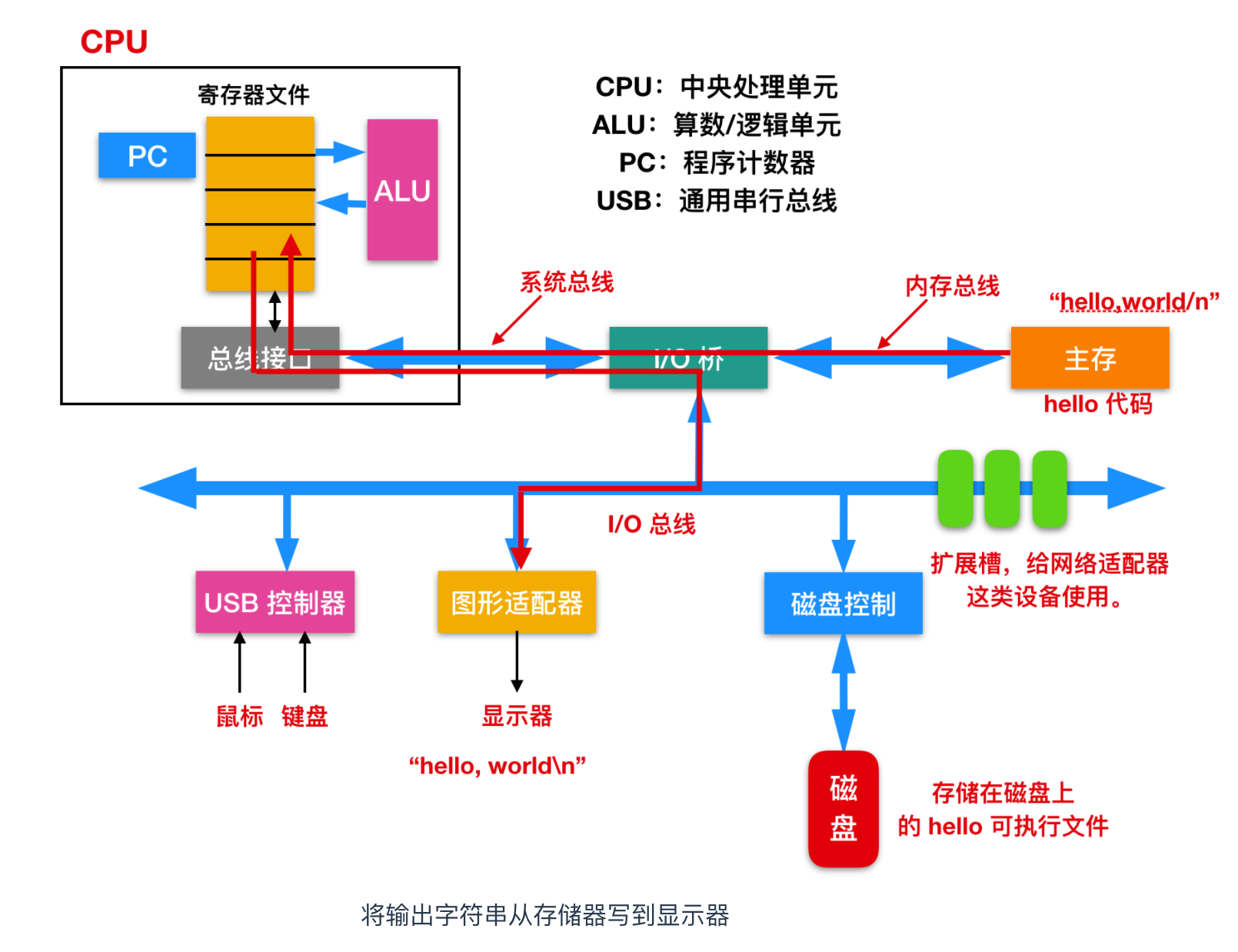
一旦目標檔案中 hello 中的程式碼和資料被載入到主存,處理器就開始執行 hello 程式的 main 程式中的機器語言指令。這些指令將 hello,world\n 字串中的位元組從主存複製到暫存器檔案,再從暫存器中複製到顯示裝置,最終顯示在螢幕上。如下所示
快取記憶體是關鍵
上面我們介紹完了一個 hello 程式的執行過程,系統花費了大量時間把資訊從一個地方搬運到另外一個地方。hello 程式的機器指令最初儲存在磁碟上。當程式載入後,它們會拷貝到主存中。當 CPU 開始執行時,指令又從記憶體複製到 CPU 中。同樣的,字串資料 hello,world \n 最初也是在磁碟上,它被複制到記憶體中,然後再到顯示器裝置輸出。從程式設計師的角度來看,這種複製大部分是開銷,這減慢了程式的工作效率。因此,對於系統設計來說,最主要的一個工作是讓程式執行的越來越快。
由於物理定律,較大的儲存裝置要比較小的儲存裝置慢。而由於暫存器和記憶體的處理效率在越來越大,所以針對這種差異,系統設計者採用了更小更快的儲存裝置,稱為快取記憶體儲存器(cache memory, 簡稱為 cache 快取記憶體),作為暫時的集結區域,存放近期可能會需要的資訊。如下圖所示

圖中我們標出了快取記憶體的位置,位於快取記憶體中的 L1快取記憶體容量可以達到數萬位元組,訪問速度幾乎和訪問暫存器檔案一樣快。容量更大的 L2 快取記憶體通過一條特殊的匯流排連結 CPU,雖然 L2 快取比 L1 快取慢 5 倍,但是仍比記憶體要哦快 5 - 10 倍。L1 和 L2 是使用一種靜態隨機訪問儲存器(SRAM) 的硬體技術實現的。最新的、處理器更強大的系統甚至有三級快取:L1、L2 和 L3。系統可以獲得一個很大的儲存器,同時訪問速度也更快,原因是利用了快取記憶體的 區域性性原理。
區域性性原理:在 cs 中,引用區域性性,也稱為區域性性原理,是 CPU 傾向於在短時間內重複訪問同一組記憶體的機制。
通過把經常訪問的資料存放在快取記憶體中,大部分對記憶體的操作直接在快取記憶體中就能完成。
儲存裝置層次結構
上面我們提到了L1、L2、L3 快取記憶體還有記憶體,它們都是用於儲存的目的,下面為你繪製了它們之間的層次結構
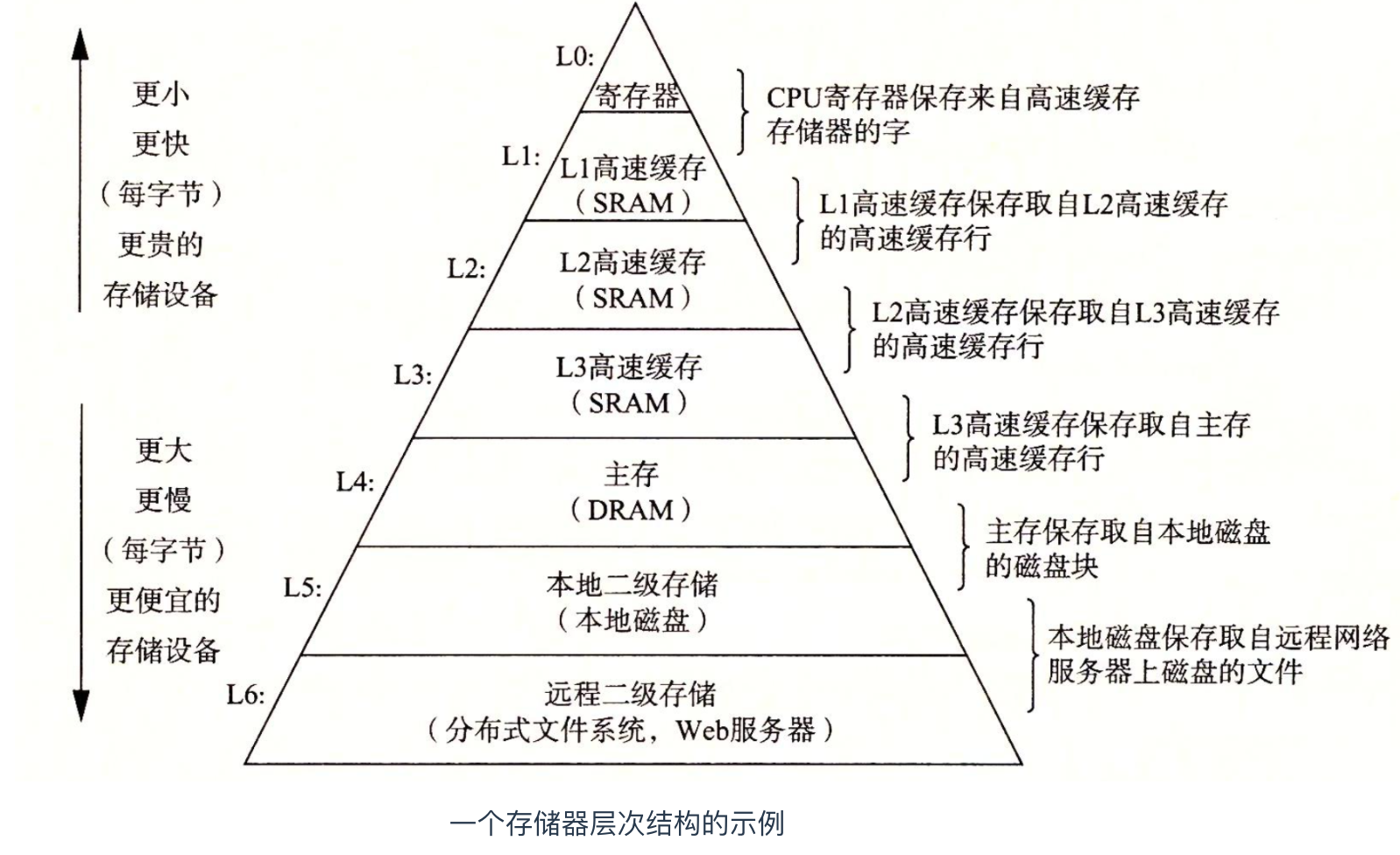
儲存器的主要思想就是上一層的儲存器作為低一層儲存器的快取記憶體。因此,暫存器檔案就是 L1 的快取記憶體,L1 就是 L2 的快取記憶體,L2 是 L3 的快取記憶體,L3 是主存的快取記憶體,而主存又是磁碟的快取記憶體。這裡簡單介紹一下儲存器裝置層次結構,具體的會在後面介紹。
作業系統如何管理硬體
再回到我們這個 hello 程式中,當 shell 載入並執行 hello 程式,以及 hello 程式輸出自己的訊息時,shell 和 hello 程式都沒有直接訪問鍵盤、顯示器、磁碟或者主存,相反,它們會依賴作業系統(operating System)做這項工作。作業系統是一種軟體,我們可以將作業系統視為介於應用程式和硬體之間的軟體層,所有想要直接對硬體的操作都會通過作業系統。
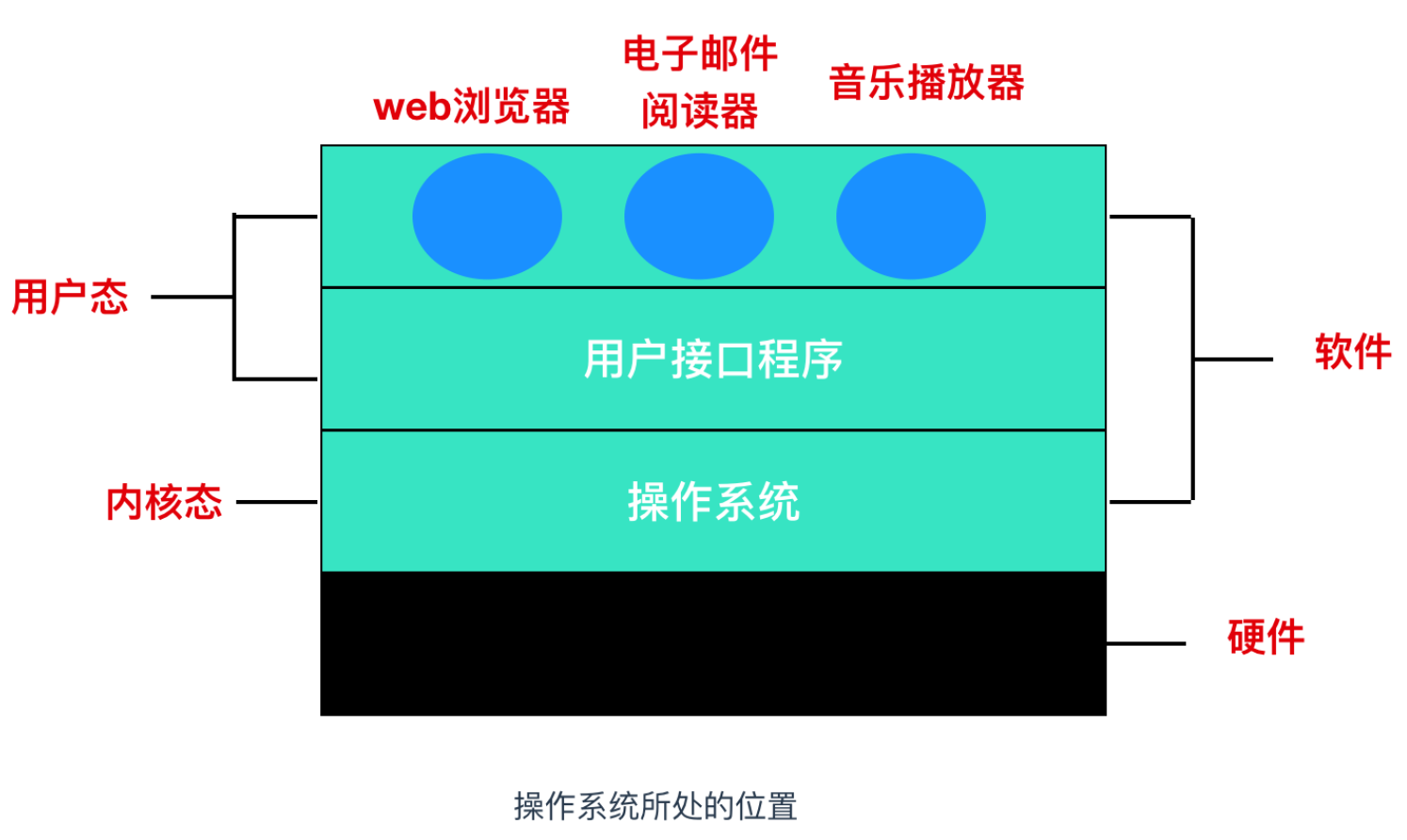
作業系統有兩項基本的功能:
- 作業系統能夠防止硬體被失控程式濫用
- 嚮應用程式提供簡單一致的機制來控制低階硬體裝置。
那麼作業系統是通過什麼實現對硬體的操作的呢?無非是通過 程序、虛擬記憶體、檔案 來實現這兩個功能。
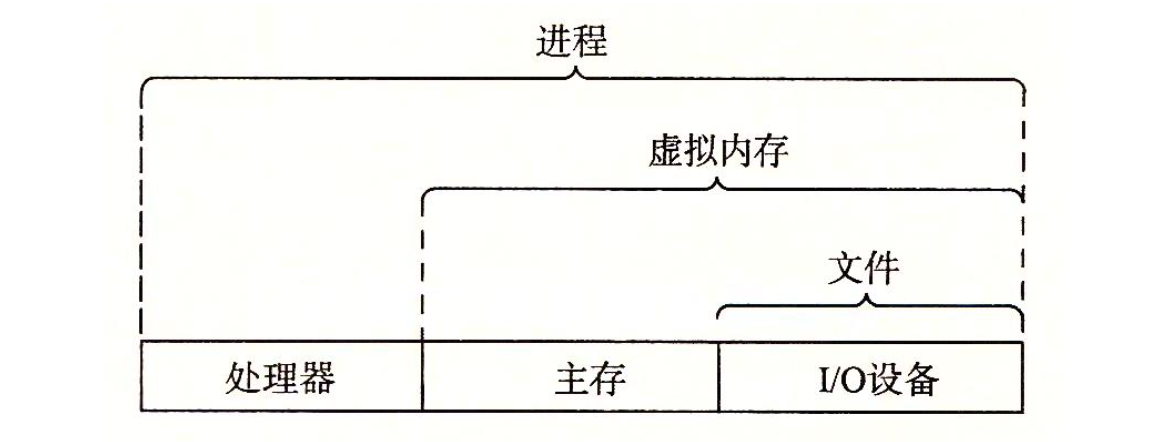
檔案是對 I/O 裝置的抽象表示,虛擬記憶體是對主存和磁碟 I/O 裝置的抽象表示,程序則是對處理器、主存和 I/O 裝置的抽象表示。下面我們依次來探討一下
程序
程序 是作業系統中的核心概念,程序是對正在執行中的程式的一個抽象。作業系統的其他所有內容都是圍繞著程序展開的。即使只有一個 CPU,它們也支援(偽)併發操作。它們會將一個單獨的 CPU 抽象為多個虛擬機器的 CPU。我們可以把程序抽象為一種程序模型。
在程序模型中,一個程序就是一個正在執行的程式的例項,程序也包括程式計數器、暫存器和變數的當前值。從概念上來說,每個程序都有各自的虛擬 CPU,但是實際情況是 CPU 會在各個程序之間進行來回切換。
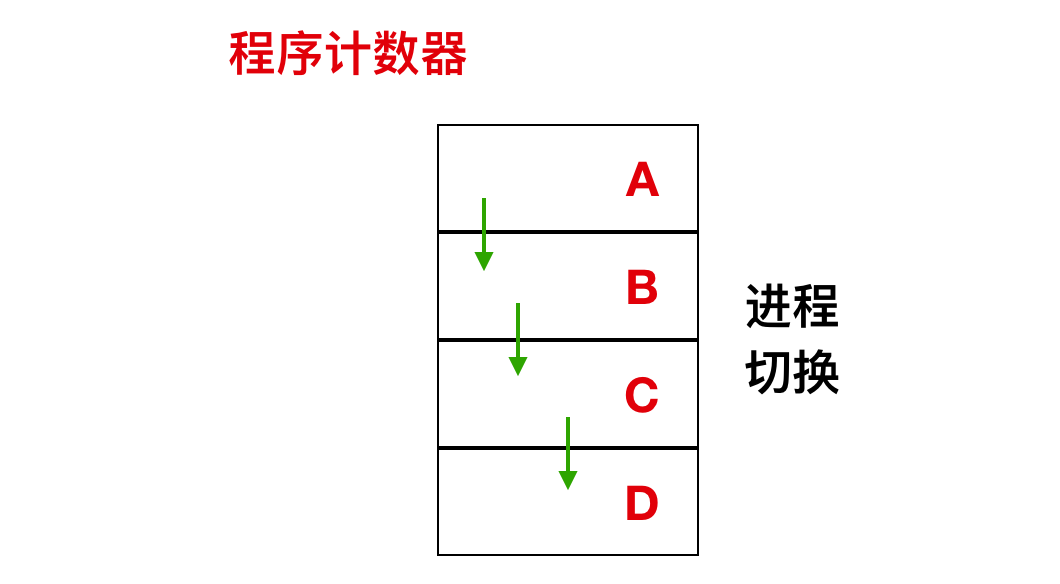
如上圖所示,這是一個具有 4 個程式的多道處理程式,在程序不斷切換的過程中,程式計數器也在不同的變化。
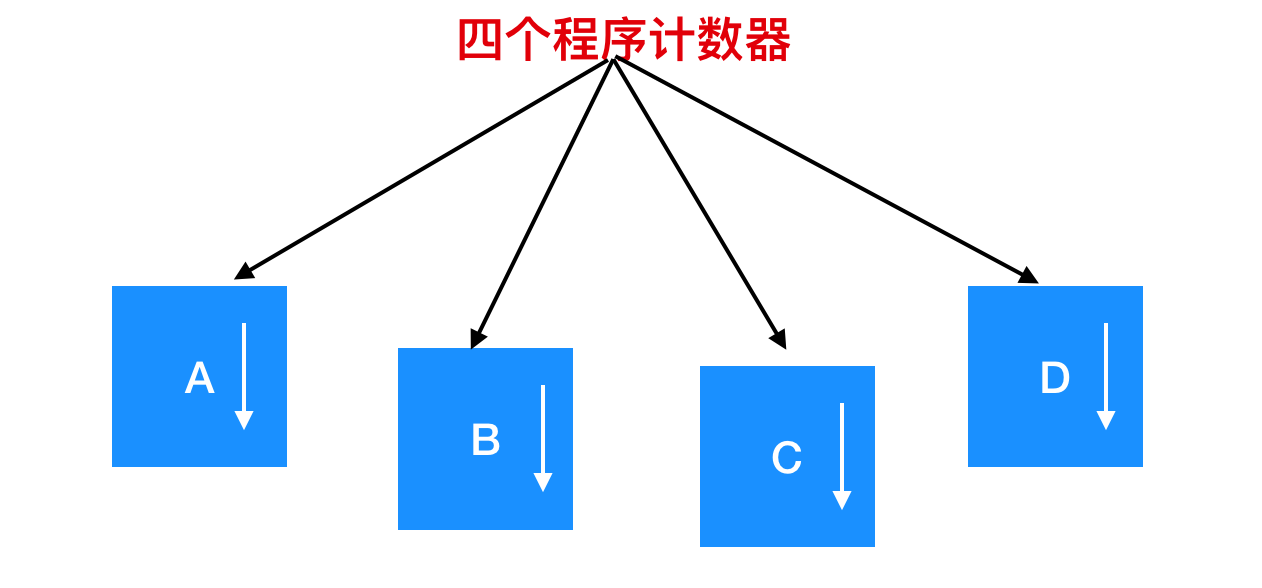
在上圖中,這 4 道程式被抽象為 4 個擁有各自控制流程(即每個自己的程式計數器)的程序,並且每個程式都獨立的執行。當然,實際上只有一個物理程式計數器,每個程式要執行時,其邏輯程式計數器會裝載到物理程式計數器中。當程式執行結束後,其物理程式計數器就會是真正的程式計數器,然後再把它放回程序的邏輯計數器中。
從下圖我們可以看到,在觀察足夠長的一段時間後,所有的程序都運行了,但在任何一個給定的瞬間僅有一個程序真正執行。
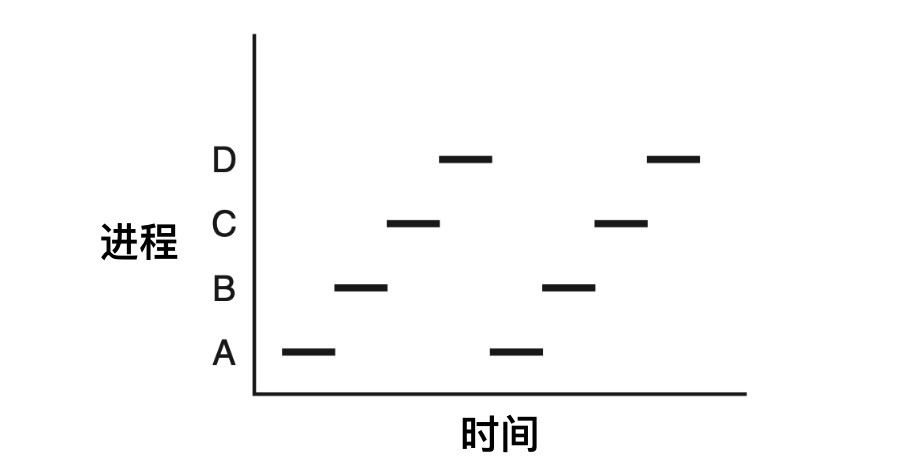
因此,當我們說一個 CPU 只能真正一次執行一個程序的時候,即使有 2 個核(或 CPU),每一個核也只能一次執行一個執行緒。
由於 CPU 會在各個程序之間來回快速切換,所以每個程序在 CPU 中的執行時間是無法確定的。並且當同一個程序再次在 CPU 中執行時,其在 CPU 內部的執行時間往往也是不固定的。
如下圖所示,從一個程序到另一個程序的轉換是由作業系統核心(kernel) 管理的。核心是作業系統程式碼常駐的部分。當應用程式需要作業系統某些操作時,比如讀寫檔案,它就會執行一條特殊的 系統呼叫 指令。
注意:核心不是一個獨立的程序。相反,它是系統管理全部程序所用程式碼和資料結構的集合。

我們會在後面具體介紹這些過程
執行緒
在傳統的作業系統中,每個程序都有一個地址空間和一個控制執行緒。事實上,這是大部分程序的定義。不過,在許多情況下,經常存在同一地址空間中執行多個控制執行緒的情形,這些執行緒就像是分離的程序。準確的說,這其實是程序模型和執行緒模型的討論,回答這個問題,可能需要分三步來回答
- 多執行緒之間會共享同一塊地址空間和所有可用資料的能力,這是程序所不具備的
- 執行緒要比程序
更輕量級,由於執行緒更輕,所以它比程序更容易建立,也更容易撤銷。在許多系統中,建立一個執行緒要比建立一個程序快 10 - 100 倍。 - 第三個原因可能是效能方面的探討,如果多個執行緒都是 CPU 密集型的,那麼並不能獲得性能上的增強,但是如果存在著大量的計算和大量的 I/O 處理,擁有多個執行緒能在這些活動中彼此重疊進行,從而會加快應用程式的執行速度
程序中擁有一個執行的執行緒,通常簡寫為 執行緒(thread)。執行緒會有程式計數器,用來記錄接著要執行哪一條指令;執行緒還擁有暫存器,用來儲存執行緒當前正在使用的變數;執行緒還會有堆疊,用來記錄程式的執行路徑。儘管執行緒必須在某個程序中執行,但是程序和執行緒完完全全是兩個不同的概念,並且他們可以分開處理。程序用於把資源集中在一起,而執行緒則是 CPU 上排程執行的實體。
執行緒給程序模型增加了一項內容,即在同一個程序中,允許彼此之間有較大的獨立性且互不干擾。在一個程序中並行執行多個執行緒類似於在一臺計算機上執行多個程序。在多個執行緒中,各個執行緒共享同一地址空間和其他資源。在多個程序中,程序共享實體記憶體、磁碟、印表機和其他資源。因為執行緒會包含有一些程序的屬性,所以執行緒被稱為輕量的程序(lightweight processes)。多執行緒(multithreading)一詞還用於描述在同一程序中多個執行緒的情況。
下圖我們可以看到三個傳統的程序,每個程序有自己的地址空間和單個控制執行緒。每個執行緒都在不同的地址空間中執行
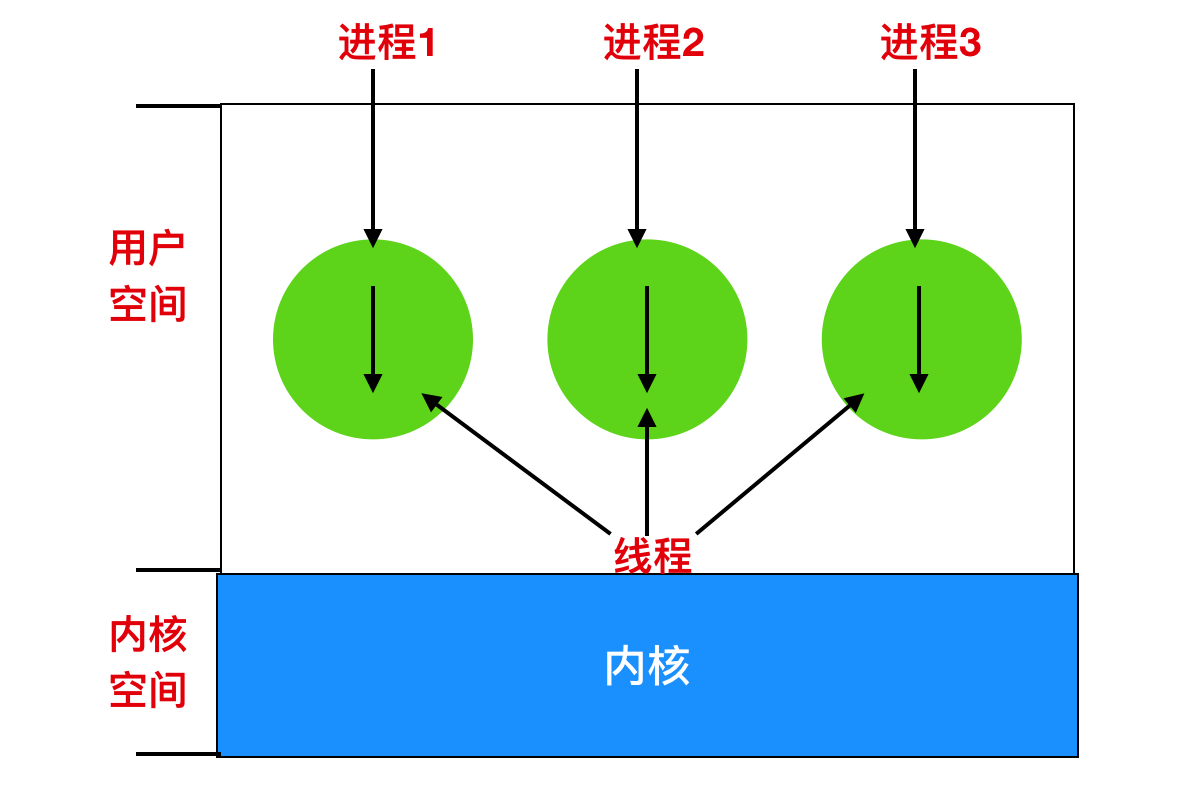
下圖中,我們可以看到有一個程序三個執行緒的情況。每個執行緒都在相同的地址空間中執行。

虛擬記憶體
虛擬記憶體的基本思想是,每個程式都有自己的地址空間,這個地址空間被劃分為多個稱為頁面(page)的塊。每一頁都是連續的地址範圍。這些頁被對映到實體記憶體,但並不是所有的頁都必須在記憶體中才能執行程式。當程式引用到一部分在實體記憶體中的地址空間時,硬體會立刻執行必要的對映。當程式引用到一部分不在實體記憶體中的地址空間時,由作業系統負責將缺失的部分裝入實體記憶體並重新執行失敗的指令。
在某種意義上來說,虛擬地址是對基址暫存器和變址暫存器的一種概述。8088 有分離的基址暫存器(但不是變址暫存器)用於放入 text 和 data 。
使用虛擬記憶體,可以將整個地址空間以很小的單位對映到實體記憶體中,而不是僅僅針對 text 和 data 區進行重定位。下面我們會探討虛擬記憶體是如何實現的。
虛擬記憶體很適合在多道程式設計系統中使用,許多程式的片段同時儲存在記憶體中,當一個程式等待它的一部分讀入記憶體時,可以把 CPU 交給另一個程序使用。
檔案
檔案(Files)是由程序建立的邏輯資訊單元。一個磁碟會包含幾千甚至幾百萬個檔案,每個檔案是獨立於其他檔案的。它是一種抽象機制,它提供了一種方式用來儲存資訊以及在後面進行讀取。
網路通訊
現代系統是不會獨立存在的,因此經常通過網路和其他系統連線到一起。從一個單獨的系統來看,網路可以視為 I/O 裝置,如下圖所示

當系統從主存複製一串位元組到網路介面卡時,資料流經過網路到達另一臺機器,而不是說到達本地磁碟驅動器。類似的,系統可以讀取其他系統傳送過來的資料,把資料複製到自己的主存中。
隨著 internet 的出現,資料從一臺主機複製到另一臺主機的情況已經成為最重要的用途之一。比如,像電子郵件、即時通訊、FTP 和 telnet 這樣的應用都是基於網路複製資訊的功能。
全文完。
文章參考:
https://en.wikipedia.org/wiki/Locality_of_reference
https://en.wikipedia.org/wiki/Arithmetic_logic_unit
《深入理解計算機系統》第三版
https://github.com/keithnull/TeachYourselfCS-CN/blob/master/TeachYourselfCS-CN.md
http://ascii.911cha.com/?year=%23
