
從JDK原始碼學習HashSet和HashTable
HashSet
Java中的集合(Collection)有三類,一類是List,一類是Queue,再有一類就是Set。 前兩個集合內的元素是有序的,元素可以重複;最後一個集合內的元素無序,但元素不可重複。
Set:
1.用於儲存無序(存入和取出的順序不一定相同)元素,值不能重複
2.物件的相等性本質是物件hashCode值(java是依據物件的記憶體地址計算出的此序號,不同物件的hashcode不一定不一樣)判斷的,如果想要讓兩個不同的物件視為相等的,就必須覆蓋Object的hashCode方法和equals方法,比如string類就重寫了hashcode方法,算出的hashcode值並不是物件的實際記憶體地址,equals也被重寫了
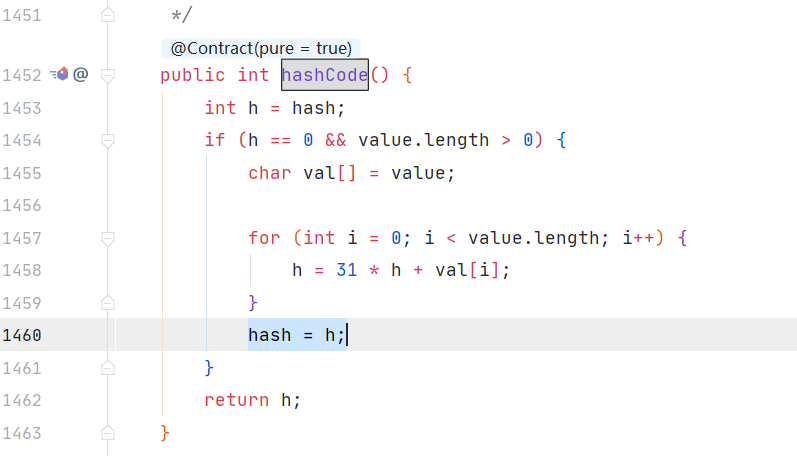
String.hashcode()
String.equals
1.先驗證是否是否是同一個物件
2.再驗證是否是同一型別(String),然後驗證值是否相等

Hashset也是支援序列化、淺拷貝的
Hashset內部還是Hashset,只不過呼叫它的add直接放入的不再是鍵值對
看下其add方法:
直接呼叫map.put放入e所代表的的鍵以及present成員變數

而這裡的map就是hashset內部儲存值的結構,可以看到其鍵是放入的,鍵所對應的值是object的例項

既然其用的hashmap,那麼其構造方法實際上就是定義hashmap,所以就是hashmap的那四種構造方法
那麼取值的時候不像hashmap那麼方便可以直接取某個鍵對應的值,取hashset中的值是獲得一個迭代器,取得內部hashmap所有的鍵然後遍歷再進行操作

所以其內部儲存時結構也和hashmap結構一樣了,同時hashset也是非執行緒安全的
ArrayList和HashSet的區別
1.前者有序,可存放重複值,後者無序,不可存放重複值,因為hashmap鍵不能重複
2.Arraylist被填滿擴充1.5倍,Hashset擴充機制和hashmap相同
HashTable
HashTable實現的map介面,支援序列化和淺拷貝

hashtable也是"拉鍊法"實現的hash表(只是陣列加單鏈表),其內部儲存結構為entry陣列,和hashmap類似,其也有負載因子和初始容量
其構造方法也有4種
第一種如下支援初始指定容量和負載因子,此時將給entry分配記憶體空間,並且初始化閾值為初始容量和(2的31次-1)-8(最大值位元組數)+1的較小值

第二種只指定初始化大小

第三種使用預設初始容量和負載因子,初始容量為11

第四種則是直接放入一個map進來初始化構造一個hashtable,此時的hashtable容量將變為放入的map的鍵值對的個數的2倍和預設容量的較大值,然後再將map放入

而hashmap這裡是和hashtable不一樣的,初始化時將用放入的map的鍵值數量/負載因子+0.75,算出的值再和2的30次方做比較,取兩者較小值和閾值進行比較,並賦值閾值為大於算出值最接近的2的次方值,便於後面resize擴容,然後後面再通過循壞將map中的值依次放入

HashTable和HashMap的比較
1.HashTable 基於 Dictionary 類,而 HashMap 是基於 AbstractMap。Dictionary 是任何可將鍵對映到相應值的類的抽象父類, AbstractMap 是基於 Map 介面的實現,但hashtable和hashmap二者都實現了Map介面
2.hashmap可以放鍵和值均為null的值,但是這樣的值你也只能放一個進去,所以hashmap中判斷是否存在某個鍵要用containskey(鍵必定是唯一的),而不能用get,因此能有多個鍵對應的value都是null,而hashtable的鍵和值不可以為null,否則將會報空指標錯誤
hashmap的處理:

所以hashmap考慮到了這種key為null的情況,讓其hash算出來為0,不為null的key再呼叫object的hashcode方法算hash
hashmap的get方法如下圖,不存在也有可能返回null或者鍵的值為null,無法判斷

hashtable的處理:
hashtable的設計並沒有考慮這麼多,而是直接呼叫其key的hashcode,那麼null.hashcode,必將報錯

hashtable將檢測放入的鍵對應的值是否為null
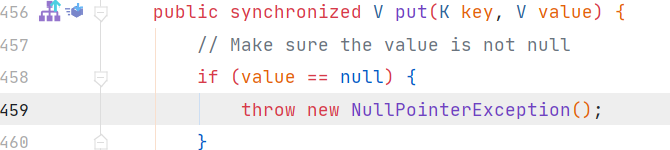
3.hashmap在預設情況下是非執行緒安全的,而hashtable以為基本public方法都是用synchronized修飾的,因此其為同步的
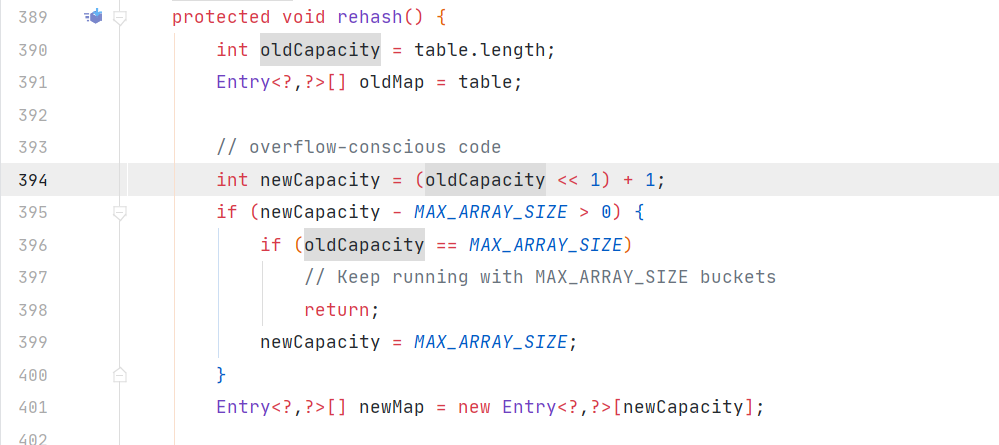
4.兩者的擴容方式不一樣,hashmap擴容是resize方法,容量變為old*2,而hashtable是rehash方法,容量變為old*2+1,
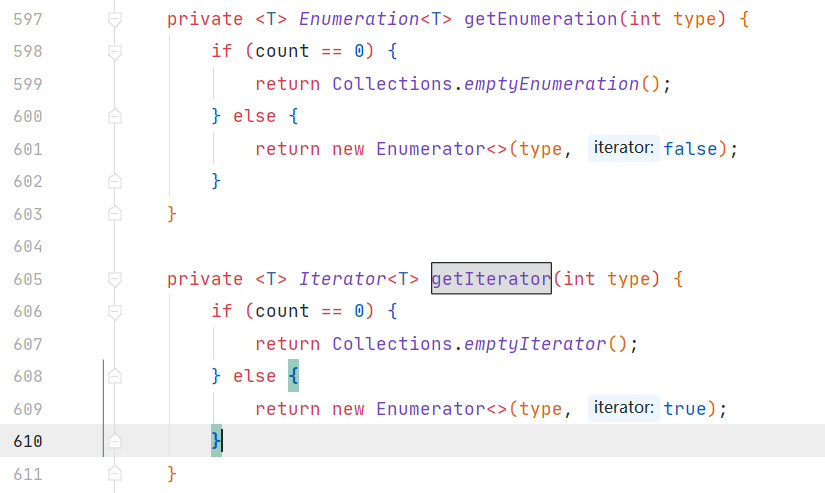
5.兩者內部遍歷實現不一樣:
hashmap的鍵值遍歷為iterator

hashtable的鍵值遍歷為Enumerator
6.獲取鍵所在的位置時的方法不同:
hashmap中首先用與邏輯代替了模運算加快了速度,2的n次方-1位全1二進位制位再與key的hash與算出鍵值對的位置,並且其hash值並不是單純的hashcode,而是用到了key的hashcode的高16位來做異或運算


hashtable中是根據key直接算一個hashcode(可能為負值),然後再和2的31次方-1做與算出來的正值再模當前hash表的長度,然後確定鍵值對的位置,那麼取模的效率肯定沒有與邏輯的執行效率更高

參考
https://blog.csdn.net/fujiakai/article/details/51585767 hashmap和hashtable區別
https://wiki.jikexueyuan.com/project/java-collection/hashtable.html hashmap實現原理