
從中國農業銀行“雅典娜杯”資料探勘大賽看金融行業資料分析與建模方法
阿新 • • 發佈:2020-05-10
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![握手][握手]
【再囉嗦一下】如果你對資料探勘感興趣,歡迎先瀏覽我的另一篇隨筆:[資料探勘比賽/專案全流程介紹](https://www.cnblogs.com/zhengzhicong/p/12728491.html)
【再囉嗦一下】如果你對金融科技感興趣,歡迎瀏覽我的另一篇隨筆:[如果你想了解金融科技,不妨先了解金融科技有哪些可能?](https://www.cnblogs.com/zhengzhicong/p/12657428.html)
【最後再說一下】本文結合了博主、內部賽優秀團隊以及外部賽冠/亞/季軍的方案分享!
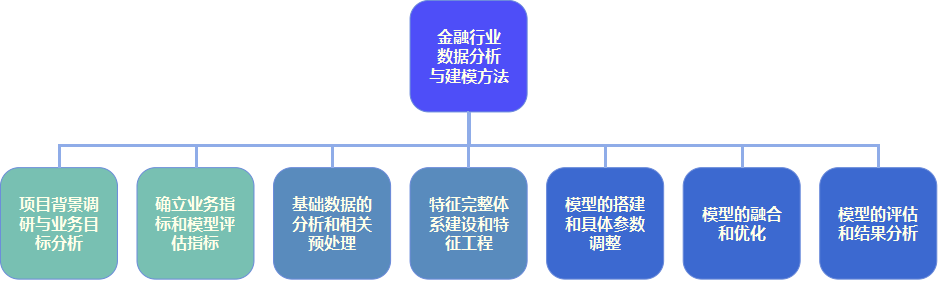
如何進行金融行業資料分析與建模,是挖掘金融行業資料價值的重要手段。金融行業資料分析與建模方法主要包括七個重要環節,每個環節緊密相連。
##1. 賽題介紹
###1.1 賽題名稱
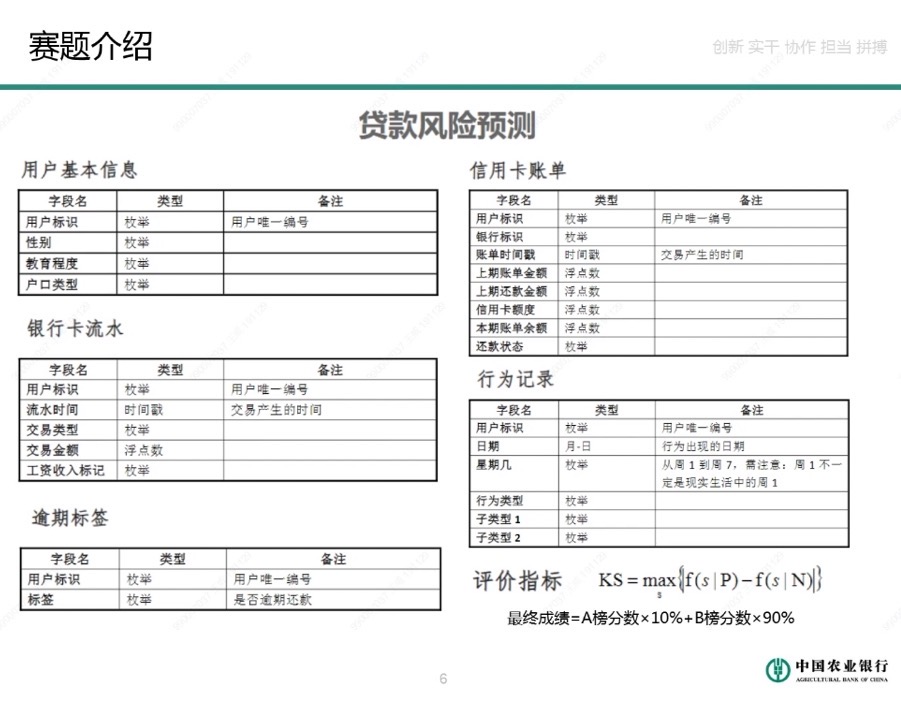
貸款風險預測(逾期還款分三種情況:要麼使用者不願意還款、要麼沒有錢還款、要麼忘了還款)
###1.2 問題描述
根據資料集中8萬用戶的相關資訊,預測使用者未來是否會逾期還款。
###1.3 提供資料
使用者基本資訊、銀行卡流水、信用卡賬單資訊以及使用者行為資料,欄位內容均為脫敏資料。
###1.4 評估指標
Kolmogorov-Smirnov(KS)是風險評分領域常用的評估指標,反應模型對正負樣本的辨識能力,KS越高表明模型對正負樣本的辨識能力越強。
KS = max { | f(s|P) - f(s|N) | }
其中,f(s|P) 為正樣本預測值的累計分佈函式,f(s|N) 為負樣本在預測值上的累計分佈函式。
##2. 資料探索
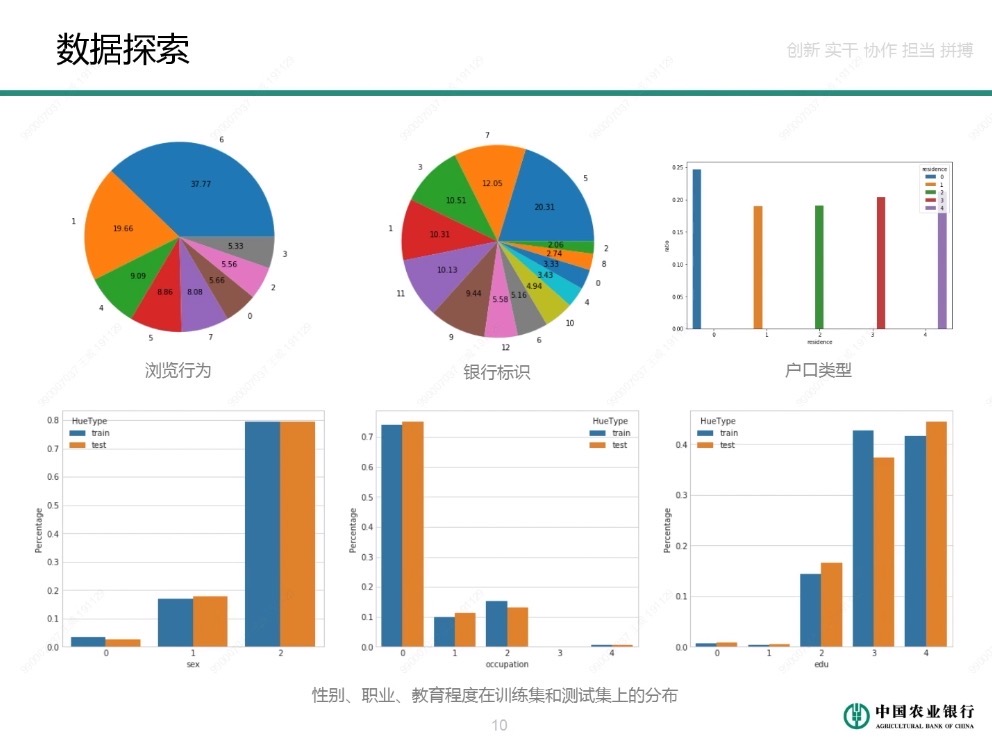
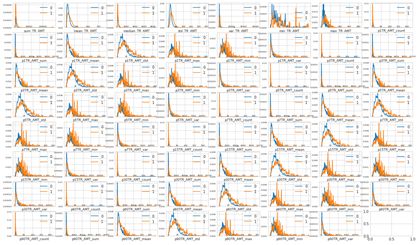
通過資料視覺化檢視資料樣本的分佈以及特徵的統計規律。
- 正/負樣本比例1:4(應該是人工取樣過,實際業務中逾期樣本比例很少)
- 訓練集/測試集樣本比例6w:8k
- ......
##3. 資料預處理
主要包括資料的缺失值處理、異常值處理、拼接、去重等基本處理。同時,還有匯率轉換和單位淨值*份額等基本資料操作。
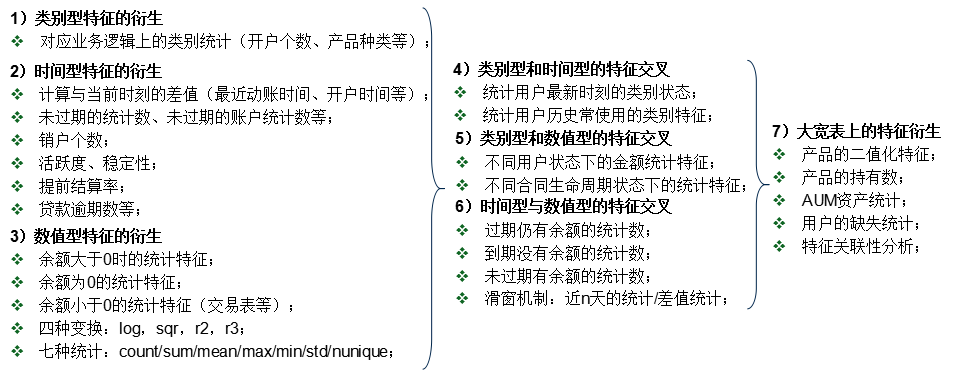
##4. 特徵工程
###4.1 基本特徵
根據類別型和數值型資料在標籤上的分佈進行預處理,包括標準化、歸一化、離散化、平滑化、one-hot編碼等。
###4.2 時序變化特徵
- 銀行卡流水:計算使用者在全域性、特定條件下(交易型別,非工資收入/工資收入,支出/收入)的金額和時間的統計特徵(sum/count/mean/median/std/min/max)
- 信用卡賬單:計算使用者在全域性、特定條件下(銀行標識,還款狀態)的金額(上期賬單金額,上期還款金額,本期賬單餘額,信用卡額度)和賬單時間戳的統計資訊
- 瀏覽行為:計算使用者每天每種行為型別/子型別的count、瀏覽行為數和瀏覽時間的統計資訊
- 日期的轉換:根據上半年/下半年、季度、月份等時間維度,提取大量可能的日期特徵衍生
- 滑動視窗處理:根據不同時間區間(近一個月、近兩個月等),計算使用者對應的銀行流水、信用卡賬單、瀏覽行為的基礎特徵/統計特徵
- 遮蔽取樣時間差異的特徵:取前五條和最後五條處理等
- ......
###4.3 交叉特徵
- 除法:例如某瀏覽行為型別佔總瀏覽的比例、工資收入/非工資收入等
- 減法:最大時間戳-最小時間戳(表示某種行為的時間跨度)等
- 拼接:例如行為型別-子型別1/2,拼接後計算特徵等
- 使用者的個人資訊之間的交叉特徵衍生
- ......
###4.4 業務理解特徵
- 上期未還款金額 = 上期賬單金額 - 上期還款金額
- 相鄰兩期賬單金額差 = 本期賬單餘額 - 上期賬單金額
- if 上期賬單金額 > 信用卡額度,爆卡 = 1 else 爆卡 = 0
- if 上期還款金額 < 上期賬單金額,未足額還款 = 1 else 未足額還款 = 0
- 缺失副表的數量
- ......
##5. 特徵選擇
- 刪除相關性高的特徵(例如取閾值0.98)
- 使用低成本特徵選擇運算元,過濾掉不重要的特徵(例如取50%)
- 使用預訓練的lightgbm模型獲得特徵重要性(例如取top3500)

##6. 模型選擇及調參
- 經過實驗選擇了lightgbm模型
- 使用網格搜尋/貝葉斯優化對其進行調參(調整葉子節點數、最大深度、行/列取樣比例、正則項係數等)
- 通過KS指標/自定義評價函式,通過交叉驗證,獲取較為準確的模型迭代輪次
##7. 模型融合
- bagging
- stacking
- ......
如果你對金融科技感興趣,歡迎瀏覽我的另一篇部落格:[如果你想了解金融科技,不妨先了解金融科技有哪些可能?](https://www.cnblogs.com/zhengzhicong/p/12657428.html)
如果您對資料探勘感興趣,歡迎瀏覽我的另一篇部落格:[資料探勘比賽/專案全流程介紹](https://www.cnblogs.com/zhengzhicong/p/12728491.html)
如果你對智慧推薦感興趣,歡迎先瀏覽我的另一篇隨筆:[智慧推薦演算法演變及學習筆記](https://www.cnblogs.com/zhengzhicong/p/12817941.html)
如果您對人工智慧演算法感興趣,歡迎瀏覽我的另一篇部落格:[人工智慧新手入門學習路線和學習資源合集(含AI綜述/python/機器學習/深度學習/tensorflow)](https://www.cnblogs.com/zhengzhicong/p/12670260.html)
如果你是計算機專業的應屆畢業生,歡迎瀏覽我的另外一篇部落格:[如果你是一個計算機領域的應屆生,你如何準備求職面試?](https://www.cnblogs.com/zhengzhicong/p/12650878.html)
如果你是計算機專業的本科生,歡迎瀏覽我的另外一篇部落格:[如果你是一個計算機領域的本科生,你可以選擇學習什麼?](https://www.cnblogs.com/zhengzhicong/p/12650191.html)
如果你是計算機專業的研究生,歡迎瀏覽我的另外一篇部落格:[如果你是一個計算機領域的研究生,你可以選擇學習什麼?](https://www.cnblogs.com/zhengzhicong/p/12650369.html)
之後博主將持續分享各大演算法的學習思路和學習筆記:[hello world: 我的部落格寫作思路](https://www.cnblogs.com/zhengzhicong/p/126414