
GAN的前身——VAE模型原理
GAN的前身——VAE模型
今天跟大家說一說VAE模型相關的原理,首先我們從判別模型和生成模型定義開始說起:
判別式模型:已知觀察變數X和隱含變數z,它對p(z|X)進行建模,它根據輸入的觀察變數X得到隱含變數z出現的可能性。
在影象模型中,比如根據原始影象推測影象具備的一些性質,例如根據數字影象推測數字的名稱等等影象分類問題。
生成式模型:與判別式模型相反,它對p(X|z)進行建模,輸入變數是隱含變數,輸出是觀察變數的概率。
在影象中,通常是輸入影象具備的性質,輸出是性質對應的影象。
生成式模型通常用於解決如下問題:
1.構建高維、複雜概率分佈,2.資料缺失,3.多模態輸出,4.真實輸出模型,5.未來資料預測,等系列問題
VAE
在經典的自編碼機中,編碼網路把原始影象編碼卷積成向量,解碼網路則能夠將向量解碼成原始影象,通過使用盡可能多的影象來訓練網路,如果儲存了某張影象的編碼向量,那麼就能夠隨時用解碼組建來重建該影象。
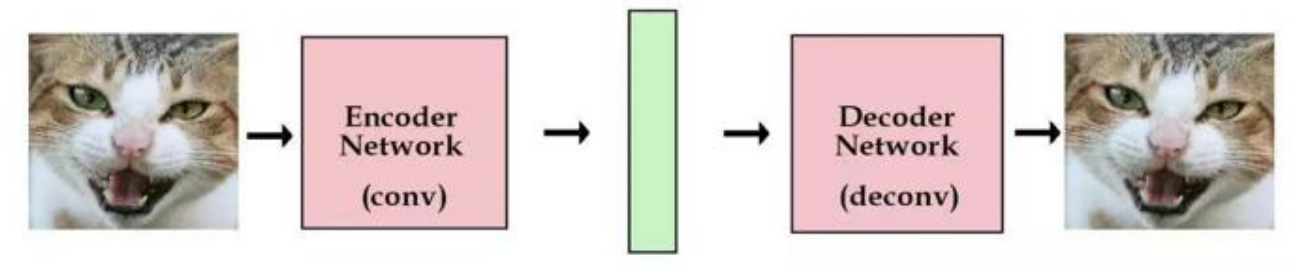
那麼,問題就來了,潛在向量除了從已有影象中編碼得到,能否憑空創造出這些潛在的向量來呢? 我們可以這樣做,在編碼網路中,增加一個約束,使得編碼網路所生成的潛在向量大體上服從單位高斯分佈。那麼,解碼器經過訓練之後,能是能夠解碼服從單位高斯分佈的解碼器了,於是我們只需要從單位高斯分佈中菜樣出一個潛在向量,並將其傳到解碼器中即可。
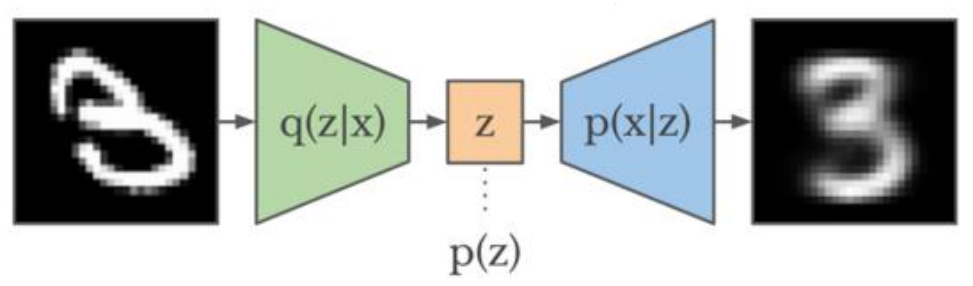
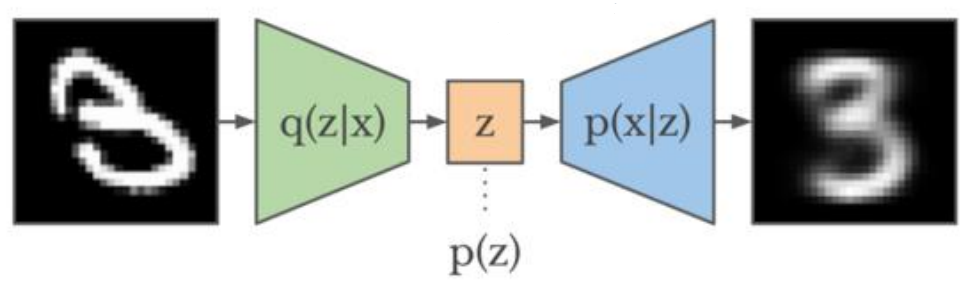
在VAE中,假定認為輸入資料的資料集D(顯示變數)的分佈完全有一組隱變數z操控,而這組隱變數之間相互獨立而且服從高斯分佈,那麼VAE讓encoder去學習輸入資料的隱變數模型,也就是去學習這組隱變數的高斯概率分佈的引數均值和方差,而隱變數z就可以從這組分佈引數的正態分佈中取樣得到z~N,再通過decoder對z隱變數進行解碼來重構輸入,本質上是實現了連續的,平滑的潛在空間表示。
對於目標函式,誤差項精度與潛在變數在單位高斯分佈上的契合程度,包括兩部分的內容:1、生成誤差,用以衡量網路在重構影象精度的均方誤差,2、潛在誤差,用以衡量潛在變數在單位高斯分佈上契合程度的KL散度,總的目標函式如下:
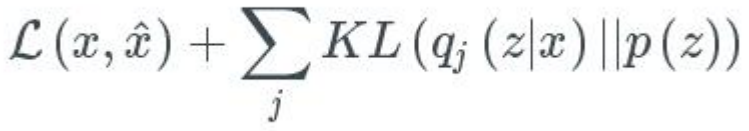
假設現在有一個樣本集中兩個概率分佈p,q,其中p為真實分佈,q為非真實分佈,那麼,按照真實分佈p來衡量識別一個樣本所需的編碼長度的期望為:
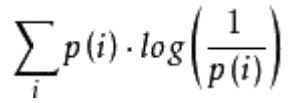
如果採用錯誤的分佈q來表示來自真實分佈p的平均編碼長度,則應該是:

此時,就將H(p,q)稱之為交叉熵。
對於KL散度,又稱為相對熵,就是兩個概率分佈P和Q差別的非對稱性度量。典型情況下,P表示資料的真實分佈,Q表示資料的理論分佈,那麼D(P||Q)的計算如下:

KL散度不是對稱的,並不滿足距離的性質,即D(P||Q) != D(Q||P)。為了解決對稱問題,我們引入JS散度。
JS散度度量了兩個概率分佈的相似度,基於KL散度的變體,解決了KL散度的非對稱的問題,一般的,JS散度是對稱的,其取值是0到1之間,計算如下:
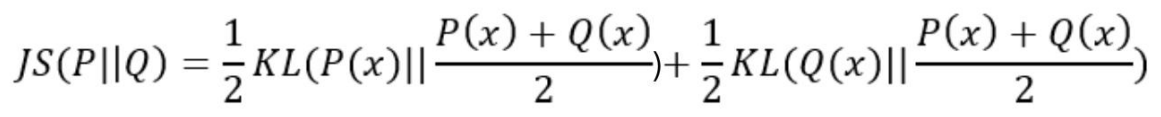
明白了度量之後,在VAE模型中並沒有真正的用z~N來取樣得到z變數,因為取樣之後,無法進行求導。其做法是先採樣一個標準高斯分佈(正態分佈),然後通過變換得到z~N分佈,這樣就能夠對引數進行正常的求導計算了:
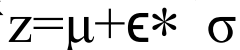
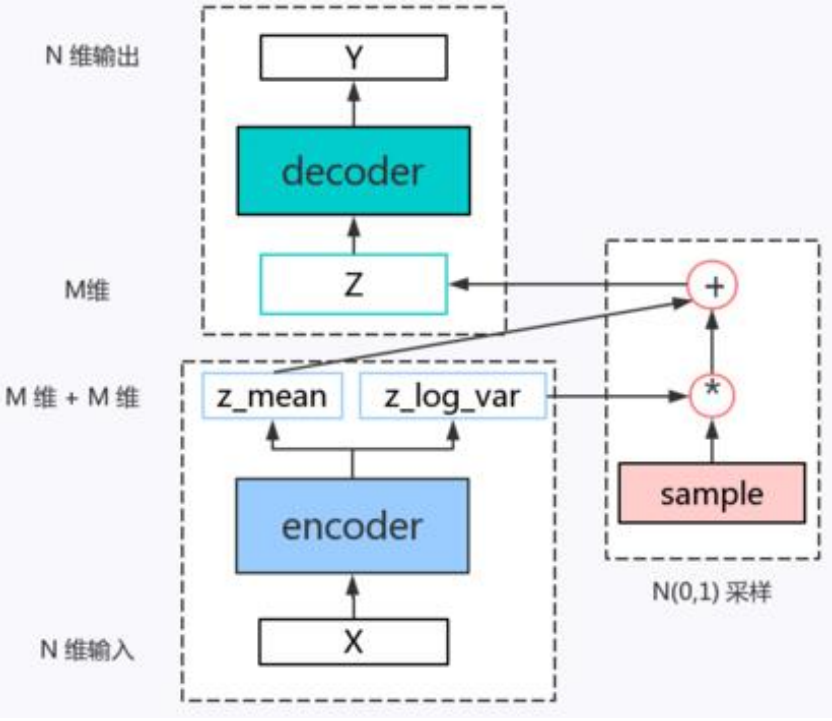

VAE遵循 編碼-解碼 的模式,能直接把生成的影象同原始影象進行對比,不足的是由於它是直接均方誤差,其神經網路傾向於生成模糊的影象。

&n