
時間序列分析中預測類問題下的建模方案
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![認真看圖][認真看圖]
【補充說明】時間序列分析主要有兩個方向,一個通過是對歷史資料的分析進行異常檢測和分類,二是進行預測!
【補充說明】迴歸分析假設每個資料點都是獨立的,而時間序列分析則是利用資料之間的相關性進行預測!
【多說一句】本文主要對時間序列分析中預測類問題下的建模方案進行探討,其他內容之後再分享!
一、基於統計學模型
1. 基本概念
一個時間序列可能存在的特徵包括以下幾種:
- 趨勢:時間序列在長時間內呈現出來的長期上升或下降的變動
- 季節性:時間序列在一年內出現的週期性波動,例如銷售淡季和銷售旺季等
- 序列相關性:又稱為自相關性。即時間序列中資料點之間存在正相關或者負相關
- 隨機噪聲:時間序列中除去趨勢、季節變化和自相關性之後的剩餘隨機擾動。
時間序列中預測類問題的目標是利用統計建模來識別時間序列中潛在的趨勢、季節變化和序列相關性。
而衡量一個模型是否適合原始時間序列的標準正是考察原始值和擬合值之間的殘差序列是否近似的為白噪聲。
因此,首先要進行時間序列的自相關性分析,確定訓練資料是符合時間序列要求:
- 用時滯圖觀察:時滯圖是把時間序列的值及相同序列在時間軸上後延的值放在一起展示。
- Ljung-Box檢驗:是一種對平穩性檢驗的方法,判斷一個序列是白噪聲還是序列存在相關性。
時間序列建模的過程可以總結如下:

2. 平穩性檢驗
如果想要對時間序列進行統計學模型分析,需要保證時間序列具有平穩性。
在數學上,時間序列的嚴平穩有著更精確的定義:它要求時間序列中任意給定長度的兩段子序列都滿足相同的聯合分佈。這是一個很強的條件,在實際中幾乎不可能被滿足。因此還有弱平穩的定義,它要求時間序列滿足均值平穩性和二階平穩性(方差平穩性)。
檢驗平穩性的方法有很多種:
(1)圖示法
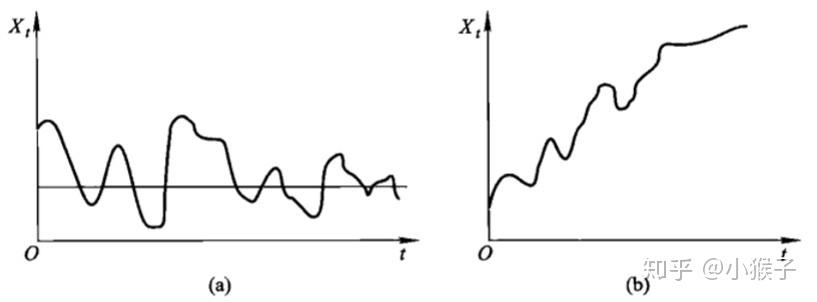
根據時序圖粗略判斷是否平穩:平穩時序圖的特徵為圍繞均值波動,而非平穩時序圖表現為在不同時間段具有不同的均值。
即可以從兩個特徵進行判斷:趨勢(即均值隨時間變化)、季節性(即方差隨時間變化、自協方差隨時間變化)。
如圖所示,圖a為平穩時序圖,圖b為非平穩時序圖。
(2)單位根檢測法
例如DF檢驗、ADF檢驗、KPSS、P-P等,具體不展開介紹。
3. 平穩化處理
- 變換:例如取對數、取平方等
- 平滑處理:例如移動平均等
- 差分
- 分解
- 多項式擬合:例如擬合迴歸等
4. 統計學模型:自迴歸模型 AR
數學上,滿足如下關係的時間序列 被稱為一個
階的自迴歸模型,記為
模型:
階的意思是使用當前時刻
之前的
個觀測值作為自變數對
建模。模型的含義是,
可以表達為
時刻之前的
個收益率觀測值的線性組合以及一個
時刻的隨機誤差
。
的取值可以是任何一個正整數,因此最簡單的自迴歸模型就是
模型(
)。
需要說明的是,自迴歸模型不一定都滿足平穩性。
5. 統計學模型:滑動平均模型 MA
數學上,滿足如下關係的時間序列 被稱為一個
階的滑動平均模型,記為
模型:
與自迴歸模型不同,滑動平均模型一定滿足平穩性。
6. 統計學模型:自迴歸滑動平均模型 ARMA
ARMA模型是針對平穩時間序列建立的模型。將一個 階的自迴歸模型和一個
階的滑動平均模型組合在一起,將 AR 和 MA 模型的優勢互補起來。由於 AR 和 MA 模型都是線性模型,因此它倆的線性組合,即 ARMA 模型,也是線性模型。
數學上,滿足如下關係的時間序列 被稱為一個階數為
的自迴歸滑動平均模型,記為
模型:
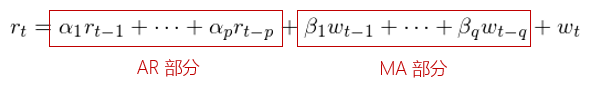
相比較單一的 AR 或者 MA 模型,ARMA 模型擁有更多的引數,出現過擬合的危險就更高。因此,在確定 AR、MA 以及 ARMA 模型的階數時,常使用資訊量準則,包括赤池資訊量準則(簡稱 AIC)以及貝葉斯資訊量準則(簡稱 BIC)。這兩個資訊量準則的目的都是尋找可以最好地解釋資料但包含最少自由引數的模型,均使用模型的似然函式、引數個數以及觀測點個數來構建一個標量函式,以此作為評價模型好壞的標準,區別在於標量函式的表示式有所不同。
7. 統計學模型:差分整合移動平均自迴歸模型 ARIMA
ARIMA (p,d,q)模型是針對非平穩時間序列建模,在ARMA模型的基礎上多了差分項(即前文提到的平穩化處理)。其中AR是“自迴歸”,p為自迴歸項數,MA為“滑動平均”,q為滑動平均項數,d為使之成為平穩序列所做的差分次數。其中,對於p,d,q的選擇是通過ACF(自相關函式,描述了時間序列資料與其之後版本的相關性)與PACF(偏自相關函式,描述了各個序列的相關性)來確定的。
8. 統計學模型:季節性差分自迴歸滑動平均模型 SARIMA
在 ARIMA 模型的基礎上進行了季節性調節。不同的是SARIMA的差分項有兩個,分別是季節性差分與非季節性差分。
9. 模型檢驗:殘差檢驗
如果一個模型和原時間序列的殘差滿足白噪聲,那麼該模型就是合適的。因此,只需要檢驗殘差序列是否在任何間隔 k 上呈現出統計意義上顯著的自相關性。在這方面,Ljung–Box 檢驗是一個很好的方法,它同時檢驗殘差序列各間隔的自相關係數是否顯著的不為 0。
最後,分享大佬總結的一些內容:時間序列分析常用統計模型
- 單變數時間序列統計學模型:例如平均方法、平滑方法、有/無季節性條件的 ARIMA 模型等
- 多變數時間序列統計學模型:例如外生迴歸變數、VAR等
- 附加或元件模型:例如Facebook Prophet、ETS等
- 結構化時間序列模型:例如貝葉斯結構化時間序列模型、分層時間序列模型等
二、基於機器學習模型
時間序列預測類問題被抽象為迴歸問題,從而可以使用機器學習的相關模型,不需要受到基本假設的限制,適用範圍更廣。
具體方法包括但不限於線性迴歸、支援向量機、隨機森林、xgboost等。
關於機器學習/資料探勘的全流程介紹,歡迎瀏覽我的另一篇部落格:資料探勘比賽/專案全流程介紹,這裡不再贅述。
值得一提的是,機器學習在特徵工程階段,可以提取時間截面特徵/統計特徵/滑窗特徵等,也可以藉助特徵提取工具(例如tsfresh等)。
三、基於深度學習模型
具體方法包括但不限於卷積神經網路CNN、迴圈神經網路LSTM等,目前還有用生成對抗網路GAN等比較新的技術來實現時間序列預測。
關於迴圈神經網路,歡迎瀏覽我的另一篇部落格:深度學習中的序列模型演變及學習筆記,這裡不再贅述。
關於深度學習模型,歡迎瀏覽我的另一篇部落格:深度學習中的一些元件及使用技巧,這裡不再贅述。
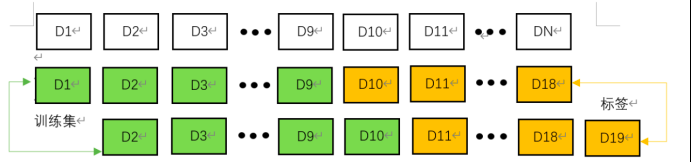
值得一提的是,深度學習在準備資料時,需要將時序資料通過時間滑窗進行時間步的拼接,從而作為訓練集的輸入與標籤。
綜上所述,三種類型的模型各有所長和不足。一般來說,統計類模型適合於資料量較小同時工業化需求不高的情況,機器學習類模型更廣泛適合於工業化情境,而深度學習模型在大資料量的預測上更具備優勢。
如果你對智慧推薦感興趣,歡迎瀏覽我的另一篇隨筆:智慧推薦演算法演變及學習筆記
如果你對廣告推薦感興趣,歡迎瀏覽我的另一篇隨筆:CTR預估模型演變及學習筆記
如果您對人工智慧演算法感興趣,歡迎瀏覽我的另一篇部落格:人工智慧新手入門學習路線和學習資源合集(含AI綜述/python/機器學習/深度學習/tensorflow)、人工智慧領域常用的開源框架和庫(含機器學習/深度學習/強化學習/知識圖譜/圖神經網路)
如果你是計算機專業的應屆畢業生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的應屆生,你如何準備求職面試?
如果你是計算機專業的本科生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的本科生,你可以選擇學習什麼?
如果你是計算機專業的研究生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的研究生,你可以選擇學習什麼?
如果你對金融科技感興趣,歡迎瀏覽我的另一篇部落格:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之後博主將持續分享各大演算法的學習思路和學習筆記:hello world: 我的部落格寫作