
第十三章 時間序列分析和預測
時間序列的關鍵是確定出已有的時間序列的變化模式,並假定這種模式會延續到未來。
時間序列分析就其發展的歷史階段和所使用的統計分析方法來看,有傳統的時間序列分析和現代時間序列分析。下文主要介紹傳統的時間序列的分析方法,內容包括時間序列資料的統計和預測方法。
1 時間序列及其分解
時間序列是同一現象在不同時間上的相繼觀察值排列而成的序列,可以分為平穩序列和非平穩序列。
平穩序列(stationaryseries)是基本上不存在趨勢的序列。這類序列中的各觀察值基本上在某個固定的水平上波動,雖然在不同的時間段波動的程度不同,但並不存在某種規律,其波動可以看做是隨機的。
非平穩序列(non-stationaryseries)是包含趨勢、季節性或週期性的序列,它可能只包含其中的一種成分,也可能是幾種成分的組合。因此,非平穩序列又可以分為有趨勢的序列、有趨勢和季節性的序列、幾種成分混合而成的複合型序列。
時間序列中除去趨勢、週期性和季節性之後的偶然性波動,稱為隨機性,也稱不規則波動。
由上可以得出,時間序列的成分可以分為4種,即趨勢(T)、季節性或季節變動(S)、週期性或迴圈波動(C)、隨機性和不規則波動(I)。傳統時間序列分析的一項主要內容就是把這樣成分從時間序列中分離出來,並將它們之間的關係用一定的數學關係式予以表達,而後進行分析。按4中成分對時間序列的影響方式不同,時間序列可分解為多種模型,如加法模型、乘法模型,其中較常用的是乘法模型。
下文所介紹的時間序列分解方法都是以乘法模型為基礎的。
2 時間序列的描述性分析
1 圖形描述
通過對圖形的觀察和分析有助於作進一步的描述,併為選擇預測模型提供基本依據。
2 增長率分析
增長率是對現象在不同時間的變化狀況所做的描述。由於對比的基期不同,增長率有不同的計算方法。
a. 增長率
也稱增長速度,是時間序列中報告期觀察值與基期觀察值之比減1後的結果,用%表示。由於對比的基期不同,增長率可以分為環比增長率和定基增長率。
環比增長率是報告期觀察值與前一時期觀察值之比減1,說明現象逐期增長變化的程度。
定基增長率是報告期觀察值與某一固定時期觀察之比減1,說明現象在整個觀察時期內總的增長變化程度。
b. 平均增長率
平均增長率是時間序列總逐期環比值的幾何平均數減1後的結果。
c. 增長率分析中應注意的問題
(1)當時間序列中的觀察值出現0或負數時,不宜計算增長率
(2)在某些情況下,不能單純就增長率論增長率,要注意增長率與絕對水平的結合分析。
3 時間序列預測的程式
在對時間序列進行預測時,通常包括以下幾個步驟:
(1)確定時間序列所包含的成分,也就是確定時間序列的型別。
(2)找出適合此類時間序列的預測方法。
(3)對可能的預測方法進行評估,以確定最佳預測方案。
(4)利用最佳預測方案進行預測
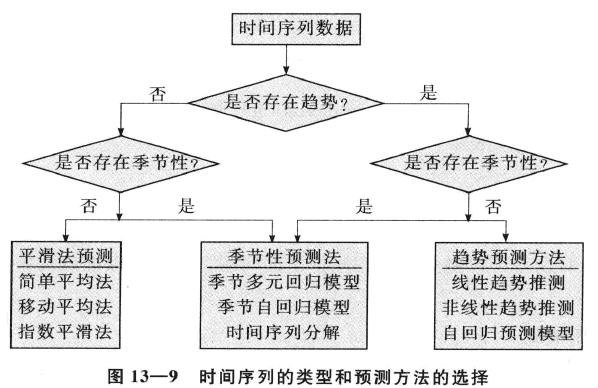
1 確定時間序列成分
判斷趨勢是否存在:
a. 繪製圖形,從圖上觀察
b. 利用迴歸分析擬合一條趨勢線,然後進行顯著性檢驗
確定季節成分是否存在:
繪製年度摺疊時間序列圖。該圖橫著只有一年的長度,每年的資料對於縱軸。
2 選擇預測方法
3 預測方法的評估
在選擇了某一種特定的方法進行預測時,需要評價該方法的預測效果或準確性。評價的方法就是找出預測值與實際值的差距,即預測誤差。最優的預測方法也就是預測誤差達到最小的方法。預測誤差的計算方法有平均誤差、平均絕對誤差、均方誤差、平均百分比誤差和平均絕對百分比誤差等。
a. 平均誤差
設時間序列的第i個觀測值為Yi,預測值為Fi
b. 平均絕對誤差
c. 均方誤差
d. 平均百分比誤差和平均絕對百分比誤差
平均絕對百分比誤差用MAPE表示,其計算公式為:
ME、MAD、MSE的大小受時間序列資料的水平和計量單位的影響,有時並不能真正反映預測模型的好壞,它們只有在比較不同模型對同一資料的預測時才有用。而平均百分比誤差和平均絕對百分比誤差則不同,它們消除了時間序列資料的水平和計量單位的影響,反映誤差大小的相對值。
平均百分比誤差用MPE表示,其計算公式為:
4 平穩序列的預測
平穩時間序列通常只含有隨機成分,其預測方法主要有簡單平均法、移動平均法和指數平滑法,這些方法主要通過對時間序列進行平滑以消除其隨機波動,因而也稱為平滑法。平滑法既可用於對平穩時間序列進行短期預測,也可以用於對時間序列進行平滑加以描述序列的趨勢(包括線性趨勢和非線性趨勢)。
1 簡單平均法
簡單平均法是根據過去已有的t期觀察值通過簡單平均來預測下一期的數值。設時間序列已有的t期觀察值為
缺點:(1)比較適合對較為平穩的時間序列進行預測
(2)遠期和近期數值看作同等重要,但實際不是
2 移動平均法
移動平均法是通過對時間序列逐期遞移求得平均數作為預測值的一種預測方法,包括簡單移動平均法和加權移動平均法。
簡單移動平均是將最近的k期資料加以平均,作為下一期的預測值。設移動間隔為k,則t期的移動平均值即t+1期的簡單移動平均預測值為:
3 指數平滑法
指數平滑法是通過對過去的觀察值加權平均進行預測的一種方法,該方法使t+1期的預測值等於t期的實際觀察值與t期的預測值的加權平均。指數平滑法是加權平均的一種特殊形式,觀察時間越遠,其權數也跟著呈指數下降。指數平滑法有一次指數平滑、二次指數平滑、三次指數平滑等。
時間序列的關鍵是確定出已有的時間序列的變化模式,並假定這種模式會延續到未來。
時間序列分析就其發展的歷史階段和所使用的統計分析方法來看,有傳統的時間序列分析和現代時間序列分析。下文主要介紹傳統的時間序列的分析方法,內容包括時間序列資料的統計和預測方法。
導論
研究時間序列主要目的:進行預測,根據已有的時間序列資料預測未來的變化。
時間序列預測關鍵:確定已有的時間序列的變化模式,並假定這種模式會延續到未來。
時間序列預測法的基本特點
假設事物發展趨勢會延伸到未來
預測所依據的資料具有不規則性
不
之前自己對於numpy和pandas是要用的時候東學一點西一點,直到看到《利用Python進行資料分析·第2版》,覺得只看這一篇就夠了。非常感謝原博主的翻譯和分享。
時間序列(time series)資料是一種重要的結構化資料形式,應用於多個領域,包括金融學、經濟學、生態學、神經科學、物
第十章、時間序列
時間戳timestamp:特定的時刻
固定時期period:2017年1月或2017年全年
時間間隔interval:時期是間隔的特例
實驗或過程時間:每一個時間點都是對特定起始實踐的一個獨立那個。例如,從放入烤箱起,每秒鐘餅乾的直徑。
1 stamp = ts.index[2]
print ts[stamp],'\n'
#還有更方便的用法,傳入可以被解釋為日期的字串
print ts['1/10/2011']
print ts['20110110'],'\n'
#對於較長的時間序列,只需傳入“年”或“年月”即可輕鬆選取資料切片
long_ts
僱傭問題:
假設你需要僱用一名新的辦公室助理。你先前的僱傭嘗試都以失敗告終,所以你決定找一個僱用代理。僱用代理每天給你推薦一個應聘者。你會面試這個人,然後決定要不要僱用他。你必須付給僱用代理一小筆費用來面試應聘者。要真正地僱用一個應聘者則要花更多的錢,因為你必須辭掉目前的辦公室助理,還要付一
時間序列是一組隨時間變化而收集的定量型變數觀測值。比如:道瓊斯工業股價指數、線上銷售、庫存、客戶數量、利率、費用等歷史資料都屬於時間序列。
預測時間序列變數對於企業準確掌控運營狀態非常有用。通常,獨立變數不能用來建立時間序列變數的迴歸模型。
時間序列分析的特點:
時間序列預測(time series forecasting)
ARIMA模型(Autoregressive Integrated Moving Average Model)
ARIMA模型,將非平
一.語義分析概述1.語義分析的任務 1)審查每一個語法結構的靜態語義,即驗證語法正確的結構是否有意義。如:賦值語句:x:=x+y,左邊變數型別與右邊變數型別是否一致。2)在語義正確的基礎上生成一種中間程式碼或目的碼。2.語義分析的範圍1)確定型別:確定識別符號所關聯的資料型別 【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![認真看圖][認真看圖]
【補充說明】時間序列分析主要有兩個方向,一個通過是對歷史資料的分析進行異常檢測和分類,二是進行預測!
【補充說明】迴歸分析假設每個資料點都是獨立的,而時間序列分析則是
分析的資料來自一個kaggle的比賽資料,是一組維基百科頁面的瀏覽量資料,對資料進行簡單的分析和處理,預測未來的流量.資料包含部分網頁從2015年7月1日到2016年12月31日的每天的瀏覽量資料,資料有存在缺失,網頁的型別包含多個語種.
下面是資料的部分
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
//anaconda/lib/python2.7/site-packa
這一章內容是對財政收入的影響因素進行分析,並構建預測模型。
本章資料比較清楚,幾乎不用做清洗工作,主要工作都在模型構建上,中間涉及到的演算法有Lasso演算法的改進演算法——Adaptive-Lasso、書中自己編寫的灰色預測、神經網路。
書中對財政地方收入 arima reg poi 11.2 樣本 誤差 == 兩種 class 第11章
11.1幹預分析
library(TSA)
win.graph(width = 4.875,height = 2.5,pointsize = 8)
data(airm 對文本進行排序、單一和重復操作 sort命令 uniq命令 第十三章 對文本進行排序、單一和重復操作:sort命令、uniq命令
sort命令
名字解釋
sort命令 它將文件進行排序,並將排序結果標準輸出。sort命令即可以從特定的文件,也可以從stdin中獲取輸入。
語法
sort (選項) pac ica link tor 包含 3.1 request closed comm 博客地址:http://www.moonxy.com
一、前言
日誌文件記錄了系統每天發生的各種各樣的事情,比如監測系統狀況、排查問題等。作為系統運維人員可以通過日誌來檢查錯誤發生的原因 方法 target speed cnblogs rsync -av html links 布爾值 單個 博客地址:http://www.moonxy.com
一、前言
sync 命令是一個遠程數據同步工具,可通過 LAN/WAN 快速同步多臺主機間的文件,可以理解為 rem
資料來源: R語言自帶 co2 資料集
分析工具:R-3.5.0 & Rstudio-1.1.453
本篇分析只是一個簡單的教程,不作深究
#清理環境,載入包
rm(list=ls())
library(forecast)
library(tseries)
#檢視資料
co2
Vi
以ARIMA模型為例介紹時間序列演算法在python中是如何實現的,一下是應用Python語言建模步驟:
-- coding: utf-8 --
“””
Created on Mon Apr 2 16:45:36 2018
@author: hou
這是Flask Mega-Tutorial系列的第十三部分,我將告訴你如何擴充套件Microblog應用以支援多種語言。 作為其中的一部分,你還將學習如何為flask命令建立自己的CLI擴充套件。
本章的主題是國際化和本地化,通常縮寫為I18n和L10n。
一次指數平滑是以前期的預測值與觀察值的線性組合作為t+1期的預測值,其預測模型為:
也可寫成以下形式:
相關推薦
第十三章 時間序列分析和預測
時間序列分析和預測
資料基礎---《利用Python進行資料分析·第2版》第11章 時間序列
《利用python進行資料分析》 第10章 時間序列
《利用python進行資料分析》第十章 時間序列(一)
演算法導論 第五章:概率分析和隨機演算法 筆記(僱傭問題、指示器隨機變數、隨機演算法、概率分析和指示器隨機變數的進一步使用)
【原始碼】時間序列分析與預測工具箱(Time Series Analysis and Forecast,TSAF)
R中時間序列分析-趨勢預測ARIMA
第七章:語義分析和中間程式碼的產生
時間序列分析中預測類問題下的建模方案
時間序列的分析和預測ARIMA
《利用python做資料分析》第十章:時間序列分析
《Python資料分析與資料探勘實戰》第十三章學習——預測
《時間序列分析及應用.R語言》第十一章閱讀筆記
第十三章 對文本進行排序、單一和重復操作:sort命令、uniq命令
Linux 筆記 - 第十三章 Linux 系統日常管理之(三)Linux 系統日誌和服務
Linux 筆記 - 第十三章 Linux 系統日常管理之(四)Linux 數據備份工具 rsync 和網絡配置
基於R語言的簡單時間序列分析預測
ARIMA時間序列分析-----Python例項(一週銷售營業額預測)
Flask 教程 第十三章:國際化和本地化