
人工智慧中小樣本問題相關的系列模型演變及學習筆記(一):元學習、小樣本學習
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![握手][握手]
【再囉嗦一下】本來只想記一下GAN的筆記,沒想到發現了一個大宇宙,很多個人並不擅長,主要是整理歸納!
一、Meta Learning 元學習綜述
Meta Learning,又稱為 learning to learn,已經成為繼 Reinforcement Learning 之後又一個重要的研究分支。
元學習區別於機器學習的是:機器學習通常是在擬合一個數據的分佈,而元學習是在擬合一系列相似任務的分佈。
本節主要參考了大佬的知乎專欄:https://zhuanlan.zhihu.com/p/28639662
推薦Stanford助理教授Chelsea Finn開設的CS330 multitask and meta learning課程
- 在 Machine Learning 機器學習時代,對於複雜一點的分類問題,模型效果就不好了。
- Deep Learning 深度學習解決了一對一對映問題,但如果輸出對下一個輸入有影響,也就是sequential decision making問題,單一的深度學習就解決不了了。
- Deep Reinforcement Learning 深度強化學習對序列決策取得成效,但深度強化學習太依賴於巨量的訓練,並且需要精確的Reward。
- 人類之所以能夠快速學習的關鍵是人類具備學會學習的能力,能夠充分利用以往的知識經驗來指導新任務的學習,因此 Meta Learning 成為新的攻克方向。
1. 基本概念
元學習是要去學習任務中的特徵表示,從而在新的任務上泛化。舉個例子,以下圖的影象分類來說,元學習的訓練過程是在task1和task2上訓練模型(更新模型引數),而在訓練樣本中的訓練集一般稱作support set,訓練樣本中的測試集一般叫做query set。測試過程是在測試任務上評估模型好壞,從圖中可以看出,測試任務和訓練任務內容完全不同。
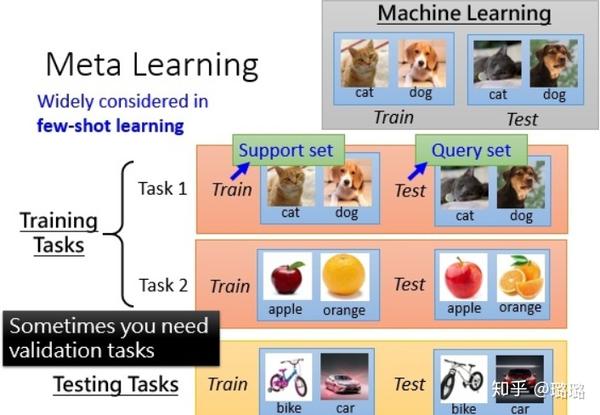
元學習解決的是學習如何學習的問題,元學習的思想是學習「學習(訓練)」過程。元學習主要包括Zero-Shot/One-Shot/Few-Shot 學習、模型無關元學習(Model Agnostic Meta Learning)和元強化學習(Meta Reinforcement Learning)等。
- Zero-shot Learing 就是訓練樣本里沒有這個類別的樣本,但是如果我們可以學到一個牛逼的對映,這個對映好到我們即使在訓練的時候沒看到這個類,但是我們在遇到的時候依然能通過這個對映得到這個新類的特徵。
- One-shot Learing 就是類別下訓練樣本只有一個或者很少,我們依然可以進行分類。比如我們可以在一個更大的資料集上或者利用knowledge graph、domain-knowledge 等方法,學到一個一般化的對映,然後再到小資料集上進行更新升級對映。
- Few-Shot Learing 的綜述將在下一節重點整理,這裡暫時不展開介紹。
元學習的主要方法包括基於記憶Memory的方法、基於預測梯度的方法、利用Attention注意力機制的方法、借鑑LSTM的方法、面向RL的Meta Learning方法、利用WaveNet的方法、預測Loss的方法等。
2. 基於記憶Memory的方法
基本思路:既然要通過以往的經驗來學習,那麼是不是可以通過在神經網路上新增Memory來實現呢?
代表方法包括:Meta-learning with memory-augmented neural networks、Meta Networks等。
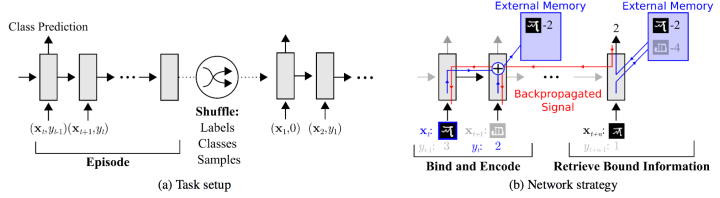
可以看到,網路的輸入把上一次的y label也作為輸入,並且添加了external memory儲存上一次的x輸入,這使得下一次輸入後進行反向傳播時,可以讓y label和x建立聯絡,使得之後的x能夠通過外部記憶獲取相關影象進行比對來實現更好的預測。
3. 基於預測梯度的方法
基本思路:既然Meta Learning的目的是實現快速學習,而快速學習的關鍵一點是神經網路的梯度下降要準,要快,那麼是不是可以讓神經網路利用以往的任務學習如何預測梯度,這樣面對新的任務,只要梯度預測得準,那麼學習得就會更快了?
代表方法包括:Learning to learn by gradient descent by gradient descent 等。
該方法訓練一個通用的神經網路來預測梯度,用一次二次方程的迴歸問題來訓練,優化器效果比Adam、RMSProp好,顯然就加快了訓練。
4. 利用Attention注意力機制的方法
基本思路:人的注意力是可以利用以往的經驗來實現提升的,比如我們看一個性感圖片,我們會很自然的把注意力集中在關鍵位置。那麼,能不能利用以往的任務來訓練一個Attention模型,從而面對新的任務,能夠直接關注最重要的部分。
代表方法包括:Matching networks for one shot learning 等。

這篇文章構造一個attention機制,也就是最後的label判斷是通過attention的疊加得到的:
attention a 則通過 g 和 f 得到。基本目的就是利用已有任務訓練出一個好的attention model。
5. 借鑑LSTM的方法
基本思路:LSTM內部的更新非常類似於梯度下降的更新,那麼,能否利用LSTM的結構訓練出一個神經網路的更新機制,輸入當前網路引數,直接輸出新的更新引數?
代表方法包括:Optimization as a model for few-shot learning 等。
這篇文章的核心思想是下面這一段:

怎麼把LSTM的更新和梯度下降聯絡起來才是更值得思考的問題吧。
6. 面向RL的Meta Learning方法
基本思路:Meta Learning可以用在監督學習,那麼增強學習上怎麼做呢?能否通過增加一些外部資訊比如reward,之前的action來實現?
代表方法包括:Learning to reinforcement learn、Rl2: Fast reinforcement learning via slow reinforcement learning 等。
兩篇文章思路一致,就是額外增加reward和之前action的輸入,從而強制讓神經網路學習一些任務級別的資訊:
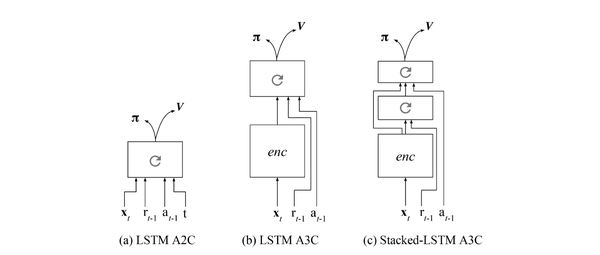
7. 通過訓練一個好的base model的方法,並且同時應用到監督學習和強化學習
基本思路:之前的方法都只能侷限在監督學習或強化學習上,能搞個更通用的?是不是相比finetune學習一個更好的base model就能work?
主要方法包括:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 等。
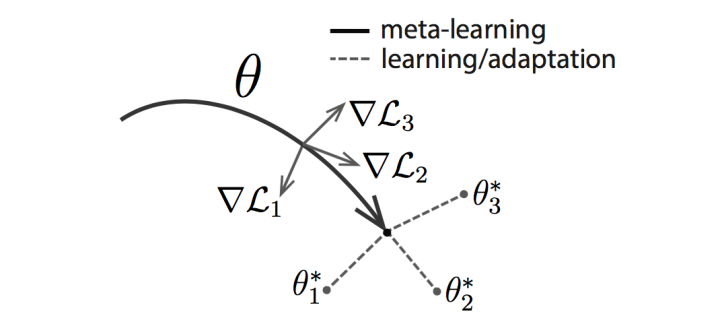
這篇文章的基本思路是同時啟動多個任務,然後獲取不同任務學習的合成梯度方向來更新,從而學習一個共同的最佳base。
8. 利用WaveNet的方法
基本思路:WaveNet的網路每次都利用了之前的資料,是否可以照搬WaveNet的方式來實現Meta Learning呢?就是充分利用以往的資料呀?
主要方法包括:Meta-Learning with Temporal Convolutions 等。

直接利用之前的歷史資料,思路極其簡單,效果極其之好,是目前omniglot,mini imagenet影象識別的state-of-the-art。
9. 預測Loss的方法
基本思路:要讓學習的速度更快,除了更好的梯度,如果有更好的loss,那麼學習的速度也會更快,因此,是不是可以構造一個模型利用以往的任務來學習如何預測Loss呢?
主要方法包括:Learning to Learn: Meta-Critic Networks for Sample Efficient Learning 等。
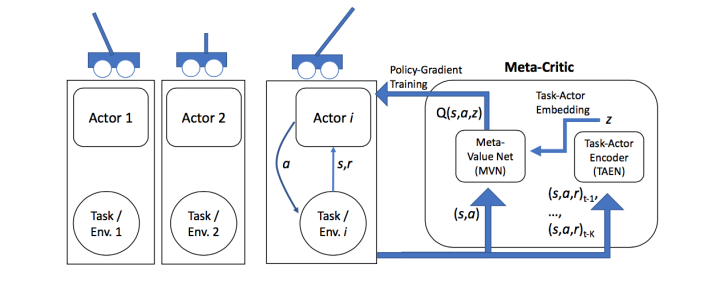
本文構造了一個Meta-Critic Network(包含Meta Value Network和Task-Actor Encoder)來學習預測Actor Network的Loss。對於Reinforcement Learning而言,這個Loss就是Q Value。
10. 小結
這是兩年前的綜述了,但是感覺質量很高。當然,後續又有了一些新進展。在應用上,元學習應用到了更廣泛的問題上,例如小樣本影象分類、視覺導航、機器翻譯和語音識別等。在演算法上,最值得一提的應該就是元強化學習,因為這樣的結合將有望使智慧體能夠更快速地學習新的任務,這個能力對於部署在複雜和不斷變化的世界中的智慧體來說是至關重要的。
具體的,以上關於元學習的論文已經介紹了在策略梯度(policy gradient)和密集獎勵(dense rewards)的有限環境中將元學習應用於強化學習的初步結果。此後,很多學者對這個方法產生了濃厚的興趣,也有更多論文展示了將元學習理念應用到更廣泛的環境中,比如:從人類演示中學習、模仿學習以及基於模型的強化學習。除了元學習模型引數外,還考慮了超引數和損失函式。為了解決稀疏獎勵設定問題,也有了一種利用元學習來探索策略的方法。
儘管取得了這些進展,樣本效率仍然是一項挑戰。當考慮將 meta-RL 應用於實際中更復雜的任務時,快速適應這些任務則需要更有效的探索策略。因此在實際學習任務中,需要考慮如何解決元訓練樣本效率低下的問題。因此,伯克利 AI 研究院基於這些問題進行了深入研究,並開發了一種旨在解決這兩個問題的演算法。
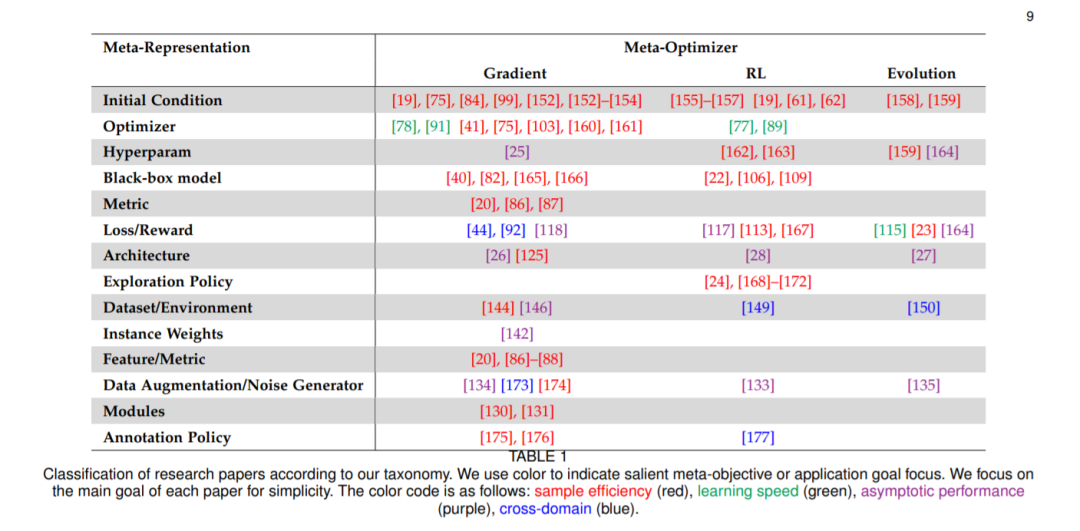
最後分享看到的元學習 meta learning 的2020綜述論文。提出了一個新的分類法,對元學習方法的空間進行了更全面的細分:[認真看圖]
論文標題:Meta-Learning in Neural Networks: A Survey
論文連結:https://arxiv.org/abs/2004.05439
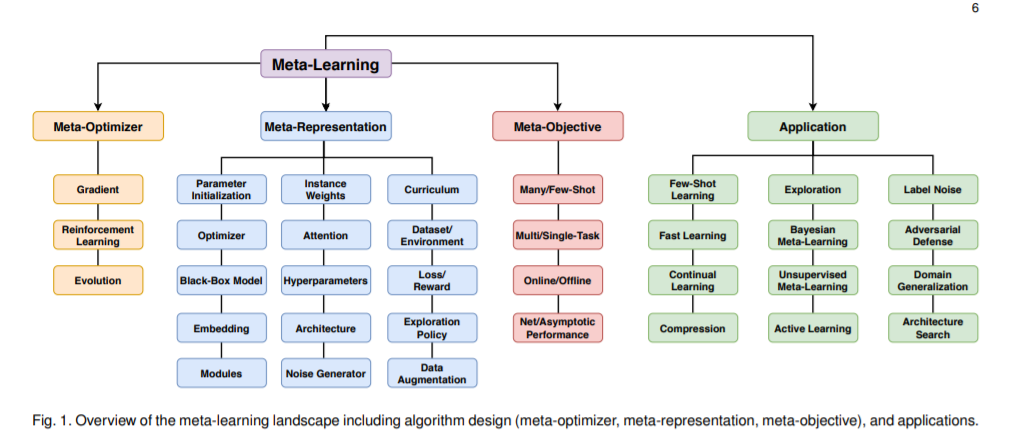
二、Few-shot Learning 小樣本學習綜述
Few-shot Learning 可以說是 元學習 Meta Learning 在監督學習領域的一個應用,當然也有它自己研究領域的東西。
本節來自香港科技大學和第四正規化的綜述:Generalizing from a Few Examples: A Survey on Few-Shot Learning
該綜述已被 ACM Computing Surveys 接收,還建立了 GitHub repo,持續更新:https://github.com/tata1661/FewShotPapers
1. 基本概念
機器學習在資料密集型應用中非常成功,但當資料集很小時,它常常受到阻礙。為了解決這一問題,近年來提出了小樣本學習(FSL)。利用先驗知識,FSL可以快速地泛化到只包含少量有監督資訊的樣本的新任務中。
大多數人認為FSL就是 meta learning,其實不是。FSL可以是各種形式的學習(例如監督、半監督、強化學習、遷移學習等),本質上的定義取決於可用的資料。但現在大多數時候在解決FSL任務時,採用的都是 meta Learning 的一些方法。
基於各個方法利用先驗知識處理核心問題的方式,該綜述將 FSL 方法分為三大類:
- 資料:利用先驗知識增強監督訊號
- 模型:利用先驗知識縮小假設空間的大小
- 演算法:利用先驗知識更改給定假設空間中對最優假設的搜尋
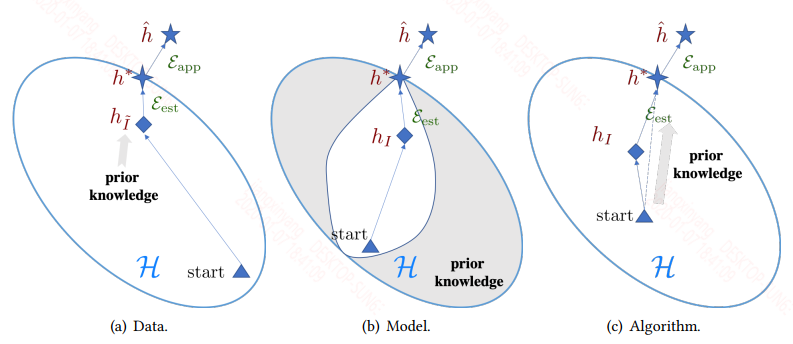
基於此,該綜述將現有的 FSL 方法納入此框架,得到如下分類體系:
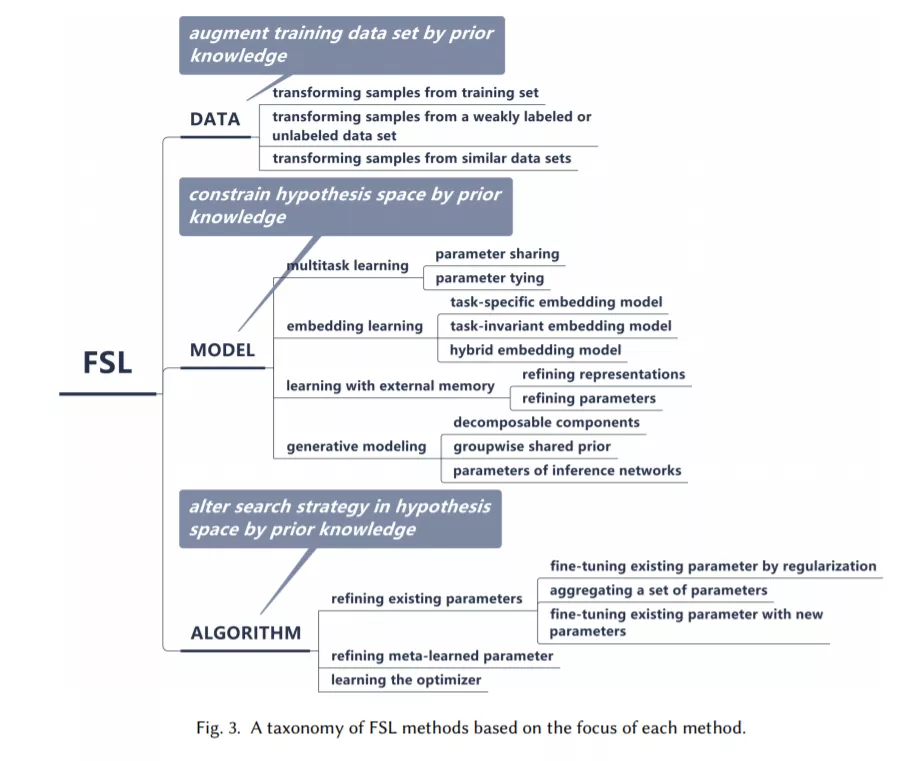
2. DATA
資料增強的方式有很多種,平時也被使用的比較多,在這裡作者將資料增強的方法概括成三類:

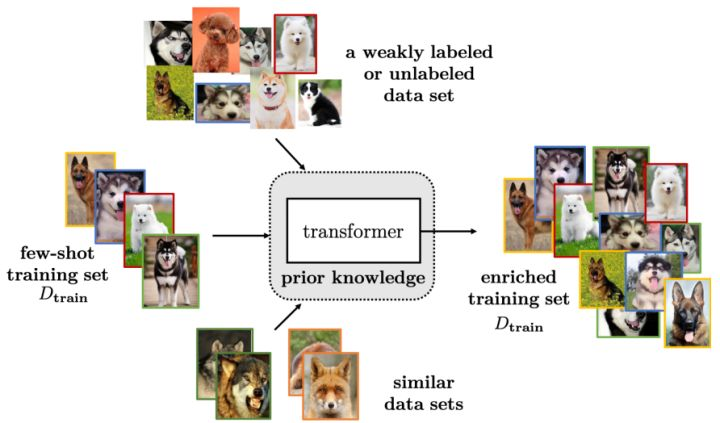
總之,資料增強沒有什麼神祕感,可以是手動在資料上修改(例如圖片的旋轉、句子中的同義詞替換等),也可以是複雜的生成模型(生成和真實資料相近的資料)。資料增強的方式有很多種,大量合適的增強一定程度上可以緩解FSL問題,但其能力還是有限的。
3. MODEL
和模型剪枝中的理念類似,你一開始給一個小的模型,這個模型空間離真實假設太遠了。而你給一個大的模型空間,它離真實假設近的概率比較大,然後通過先驗知識去掉哪些離真實假設遠的假設。
作者根據使用不同的先驗知識將MODEL的方法分成4類:

3.1 Multitask Learning
對於多個共享資訊的任務(例如資料相同任務不同、資料和任務都不同等),都可以用多工學習來訓練。
多工分為硬引數共享和軟引數共享兩種模式:
- 硬引數共享認為任務之間的假設空間是有部分重疊的,體現在模型上就是有部分引數是共享的。而共享的引數可以是模型的前面一些層,表徵任務的低階資訊。也可以是在嵌入層之後,不同的嵌入層將不同任務嵌入到同一不變任務空間,然後共享模型引數等。
- 軟引數共享不再顯示的共享模型引數,而是讓不同的任務的引數相似。這就可以通過不同任務的引數正則,或者通過損失來影響引數的相似,以此讓不同任務的假設空間類似。
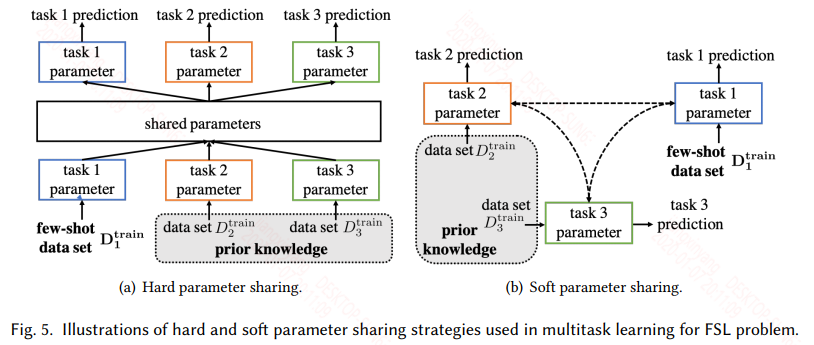
多工通過多個任務來限制模型的假設空間:
- 對於硬引數共享,多個任務會有一個共享的假設空間,然後每個任務還有自己特定的假設空間。
- 對於軟引數共享也類似,軟引數更靈活,但也需要精心設計。
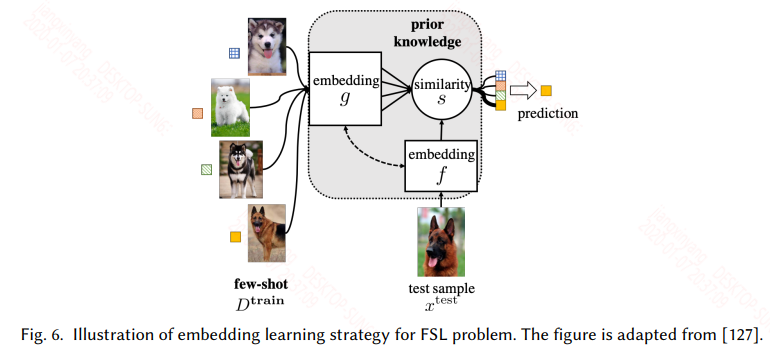
3.2 Embedding Learning
嵌入學習很好理解,將訓練集中所有的樣本通過一個函式 f 嵌入到一個低維可分的空間Z,然後將測試集中的樣本通過一個函式 g 嵌入到這個低維空間Z,然後計算測試樣本和所有訓練樣本的相似度,選擇相似度最高的樣本的標籤作為測試樣本的標籤。
根據task-specific和task-invariant,以及兩者的結合可以分為三種,嵌入學習如下:
- Task-specific是在任務自身的訓練集上訓練的,通過構造同類樣本相同,不同類樣本不同的樣本對作為資料集,這樣資料集會有一個爆炸式的擴充,可以提高樣本的複雜度,然後可以用如siamese network等來訓練。
- Task-invariant是在一個大的且和任務相似的source資料集上訓練一個嵌入模型,然後直接用於當前任務的訓練集和測試集嵌入。
- 實際上現在用的比較多的還是兩者的結合,既可以利用大的通用資料集學習通用特徵,又可以在特定任務上學習特定的特徵,而現在常用的訓練模式是meta learning中的metric-based的方式,此類常見的模型有match network、prototypical network、relation network等。
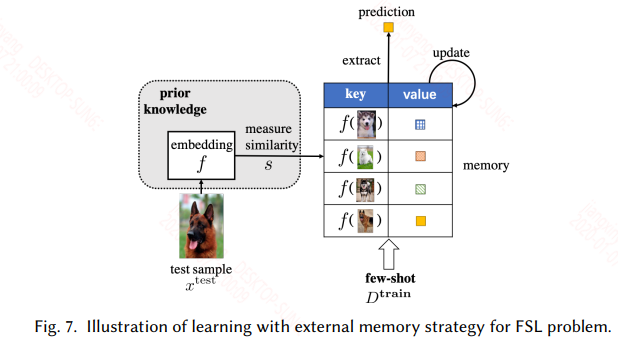
3.3 Learning with External Memory
具有外部儲存機制的網路都可以用來處理這一類問題,其實本質上和遷移學習一樣。只不過這裡不更新模型的引數,只更新外部記憶庫。外部記憶庫一般都是一個矩陣,如神經圖靈機,其外部記憶庫具有讀寫操作。
在這裡就是在一個用大量類似的資料訓練的具有外部儲存機制的網路上,用具體task的樣本來更新外部記憶庫。這類方法需要精心設計才能有好的效果,比如外部記憶庫寫入或更新的規則可能就影響模型能夠在當前任務上的表現。具體的如下圖所示:
3.4 Generative Modeling
引入了生成式的模型來解FSL問題。
4. ALGORITHM
在機器學習中,通常使用SGD及其變體(例如ADAM、RMSProp等)來尋找最優引數。但是在FSL中,樣本數量很少,這種方法就失效了。
在這一節,我們不再限制假設空間。根據使用不同的先驗知識,可以將ALGORITHM分為下面3類:

4.1 Refine Existing Parameters
本質就是pretrained + fine-tuning的模式,最常見的就是直接在pre-trianed的模型上直接fine-tuning引數,還可以在一個新的網路上使用pre-trained的部分引數來初始化等。
4.2 Refine Meta-learned Parameters
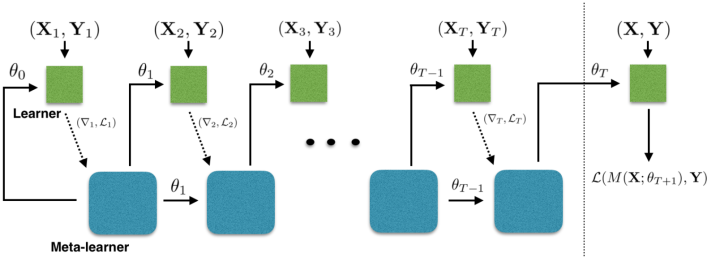
該小節是基於 meta learning 的解決方法,利用元學習器學習一個好的初始化引數。之後在新的任務上,只要對這個初始化引數少量迭代更新就能很好的適應新的任務。這種方法最經典的模型就是MAML,MAML的訓練模式如下圖所示:
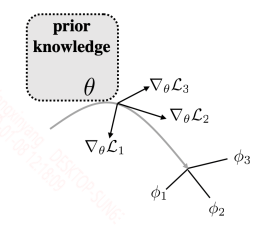
上面的引數是元學習器的引數,最後用多個任務的梯度向量和來更新引數。這樣的方式也有一個問題,就是新的任務的特性必須要和元訓練中的任務相近,這樣值才能作為一個較好的初始化值,否則效果會很差。因此,也就有不少研究在根據新任務的資料集來動態的生成一個適合它的初始化引數。
4.3 Learn Search Steps
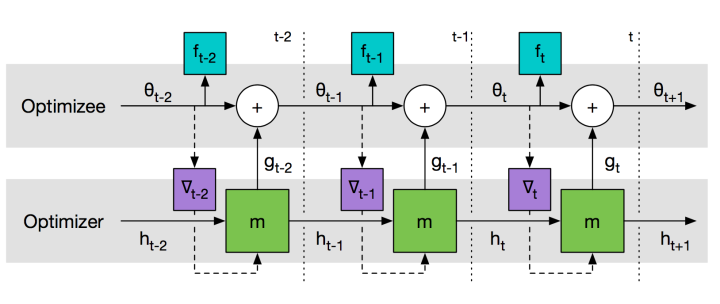
上一節使用元學習來獲得一個較好的初始化引數,而本節旨在用元學習來學習一個引數更新的策略。針對每一個子任務能給定特定的優化方式實際上是提高效能的唯一方法,這裡就是設計一個元優化器來為特定的任務提供特定的優化方法,具體的如下圖所示:

梯度的更新也可以寫成:

在這裡使用RNN來實現,因為RNN具有時序記憶功能,而梯度迭代的過程中正好是一個時序操作。具體的訓練如下圖所示:
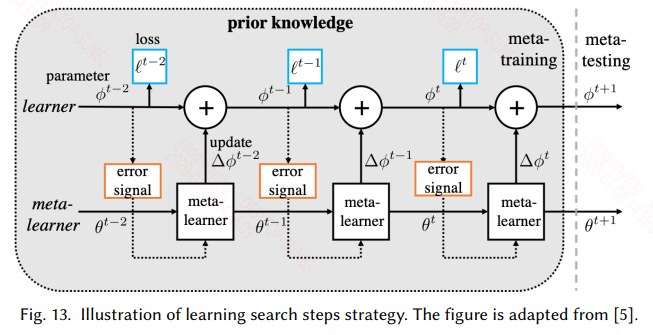
訓練過程大致如下:
- 對於每個任務,同樣劃分訓練集和測試集,訓練集經過meta-learner得到一系列的梯度,因為RNN每個時刻都有輸出,因此每個時刻的梯度都去依次更新learner的引數ϕ。這樣看就相當於一個batch的樣本就更新了T次learner
- 訓練完一輪之後,用測試集在learner上的到的梯度來更新meta-learner的引數
這和上一節面臨的問題一樣,meta-learner 學到的更新策略是針對這一類任務的,一旦新任務和元訓練中的任務偏差較大時,這種更新策略可能就失效了。
5. FUTURE WORKS
未來的方向可能有:
- 從使用的先驗資料:例如利用更多的先驗知識、多模態的資料等
- 從使用的模型方法:用新的網路結構去替換以前的,例如用transformer替換RNN
- 從使用的場景:現在FSL在字元識別、影象識別、小樣本分割等取得效果,在目標檢測、目標跟蹤、NLP中的各項任務上等值得嘗試
- 理論分析
- ......
歡迎持續關注我的下一篇隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(二):生成對抗網路 GAN
歡迎持續關注我的下一篇隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(三):遷移學習
歡迎持續關注我的下一篇隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(四):知識蒸餾、增量學習
如果您對異常檢測感興趣,歡迎瀏覽我的另一篇部落格:異常檢測演算法演變及學習筆記
如果您對智慧推薦感興趣,歡迎瀏覽我的另一篇部落格:智慧推薦演算法演變及學習筆記 、CTR預估模型演變及學習筆記
如果您對知識圖譜感興趣,歡迎瀏覽我的另一篇部落格:行業知識圖譜的構建及應用、基於圖模型的智慧推薦演算法學習筆記
如果您對時間序列分析感興趣,歡迎瀏覽我的另一篇部落格:時間序列分析中預測類問題下的建模方案 、深度學習中的序列模型演變及學習筆記
如果您對資料探勘感興趣,歡迎瀏覽我的另一篇部落格:資料探勘比賽/專案全流程介紹 、機器學習中的聚類演算法演變及學習筆記
如果您對人工智慧演算法感興趣,歡迎瀏覽我的另一篇部落格:人工智慧新手入門學習路線和學習資源合集(含AI綜述/python/機器學習/深度學習/tensorflow)、人工智慧領域常用的開源框架和庫(含機器學習/深度學習/強化學習/知識圖譜/圖神經網路)
如果你是計算機專業的應屆畢業生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的應屆生,你如何準備求職面試?
如果你是計算機專業的本科生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的本科生,你可以選擇學習什麼?
如果你是計算機專業的研究生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的研究生,你可以選擇學習什麼?
如果你對金融科技感興趣,歡迎瀏覽我的另一篇部落格:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之後博主將持續分享各大演算法的學習思路和學習筆記:hello world: 我的部落格寫作