
人工智慧中小樣本問題相關的系列模型演變及學習筆記(四):知識蒸餾、增量學習
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![握手][握手]
【再囉嗦一下】本文銜接上兩個隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(一):元學習、小樣本學習
【再囉嗦一下】本文銜接上兩個隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(二):生成對抗網路 GAN
【再囉嗦一下】本文銜接上兩個隨筆:人工智慧中小樣本問題相關的系列模型演變及學習筆記(三):遷移學習
一、知識蒸餾綜述
知識蒸餾被廣泛的用於模型壓縮和遷移學習當中。
本文主要參考:模型壓縮中知識蒸餾技術原理及其發展現狀和展望
1. 基本概念
知識蒸餾可以將一個網路的知識轉移到另一個網路,兩個網路可以是同構或者異構。做法是先訓練一個teacher網路,然後使用這個teacher網路的輸出和資料的真實標籤去訓練student網路。
- 可以用來將網路從大網路轉化成一個小網路,並保留接近於大網路的效能。
- 可以將多個網路的學到的知識轉移到一個網路中,使得單個網路的效能接近emsemble的結果。
2. 知識蒸餾的主要演算法
知識蒸餾是對模型的能力進行遷移,根據遷移的方法不同可以簡單分為基於目標驅動的演算法、基於特徵匹配的演算法兩個大的方向。
2.1 知識蒸餾基本框架
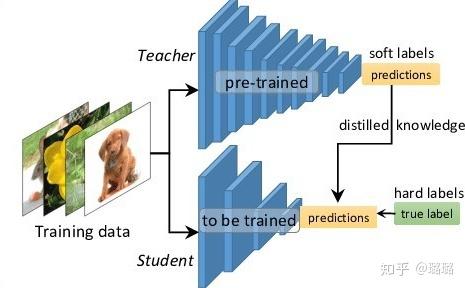
Hinton最早在文章“Distilling the knowledge in a neural network”中提出了知識蒸餾的概念,即knowledge distilling,對後續的許多演算法都產生了影響,其框架示意圖如下:
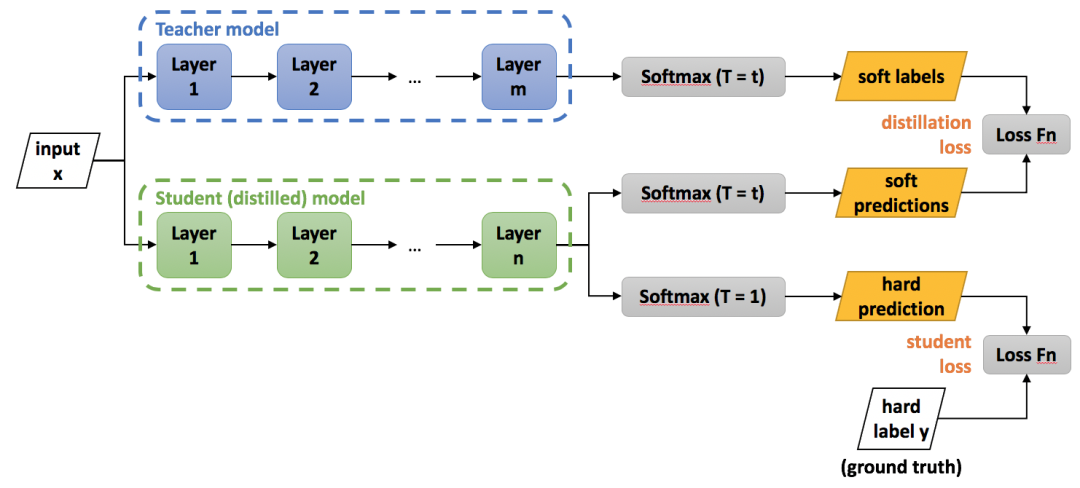
從上圖中可以看出,包括一個teacher model和一個student model,teacher model需要預先訓練好,使用的就是標準分類softmax損失,但是它的輸出使用帶溫度引數T的softmax函式進行對映,如下:
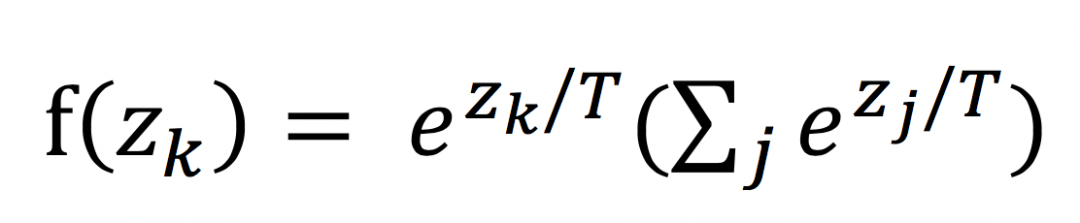
當T=1時,就是softmax本身。當T>1,稱之為soft softmax,T越大,因為輸入 zk 產生的概率 f(zk) 差異就會越小。之所以要這麼做,其背後的思想是:當訓練好一個模型之後,模型為所有的誤標籤都分配了很小的概率。然而實際上對於不同的錯誤標籤,其被分配的概率仍然可能存在數個量級的懸殊差距。這個差距,在softmax中直接就被忽略了,但這其實是一部分有用的資訊。
訓練的時候小模型有兩個損失:一個是與真實標籤的softmax損失,一個是與teacher model的蒸餾損失,定義為KL散度。
當teacher model和student model各自的預測概率為pi,qi時,其蒸餾損失部分梯度傳播如下:

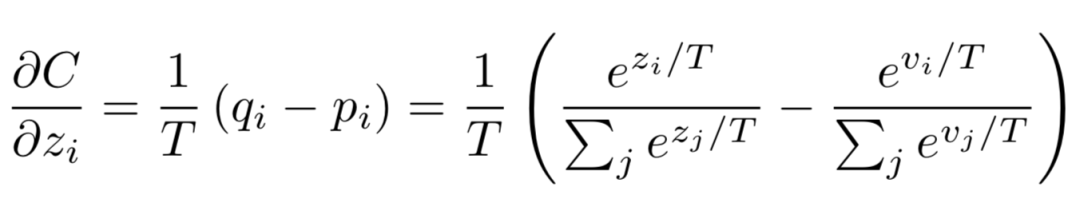
可以看出形式非常的簡單,梯度為兩者預測概率之差,這就是最簡單的知識蒸餾框架。
2.2 優化目標驅動的知識蒸餾框架
Hinton等人提出的框架是在模型最後的預測端,讓student模型學習到與teacher模型的知識,這可以稱之為直接使用優化目標進行驅動的框架,類似的還有ProjectionNet。
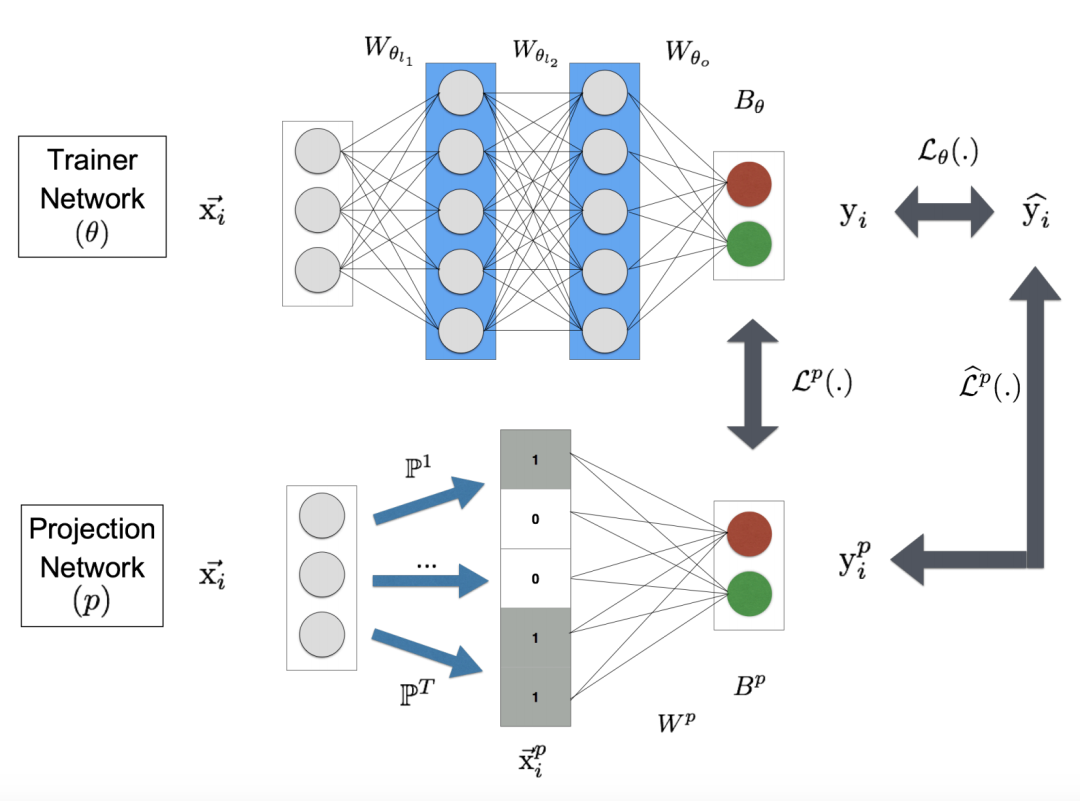
PrjojectNet同時訓練一個大模型和一個小模型,兩者的輸入都是樣本,其中大模型就是普通的CNN網路,而小模型會對輸入首先進行特徵投影。每一個投影矩陣P都對應了一個對映,由一個d-bit長的向量表示,其中每一個bit為0或者1,這是一個更加稀疏的表達。特徵用這種方法簡化後自然就可以使用更加輕量的網路的結構進行訓練。那麼怎麼完成這個過程呢?文中使用的是locality sensitive hashing(LSH)演算法,這是一種聚類任務中常用的降維的演算法。
優化目標包含了3部分,分別是大模型的損失,投影損失,以及大模型和小模型的預測損失,全部使用交叉熵,各自定義如下:
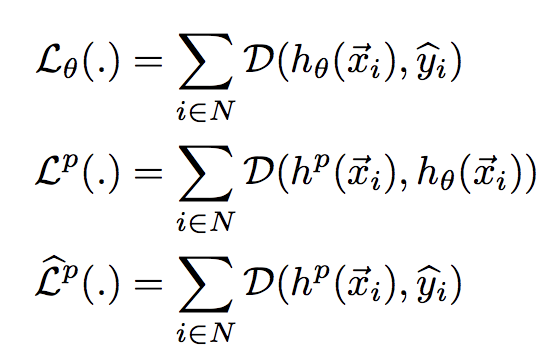
基於優化目標驅動的方法其思想是非常直觀,就是結果導向型,中間怎麼實現的不關心,對它進行改進的一個有趣方向是GAN的運用。

2.3 特徵匹配的知識蒸餾框架
結果導向型的知識蒸餾框架的具體細節是難以控制的,會讓訓練變得不穩定且緩慢。一種更直觀的方式是將teacher模型和student模型的特徵進行約束,從而保證student模型確實繼承了teacher模型的知識,其中一個典型代表就是FitNets,FitNets將比較淺而寬的Teacher模型的知識遷移到更窄更深的Student模型上,框架如下:

FitNets背後的思想是,用網路的中間層的特徵進行匹配,不僅僅是在輸出端。它的訓練包含了兩個階段:
(1)第一階段就是根據Teacher模型的損失來指導預訓練Student模型。記Teacher網路的某一中間層的權值Wt為Whint,意為指導的意思。Student網路的某一中間層的權值Ws為Wguided,即被指導的意思,在訓練之初Student網路進行隨機初始化。需要學習一個對映函式Wr使得Wguided的維度匹配Whint,得到Ws',並最小化兩者網路輸出的MSE差異作為損失,如下:
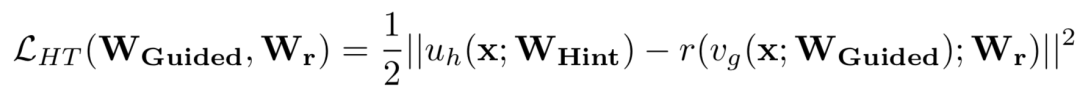
(2)第二個訓練階段,就是對整個網路進行知識蒸餾訓練,與上述Hinton等人提出的策略一致。不過FitNet直接將特徵值進行了匹配,先驗約束太強,有的框架對啟用值進行了歸一化。
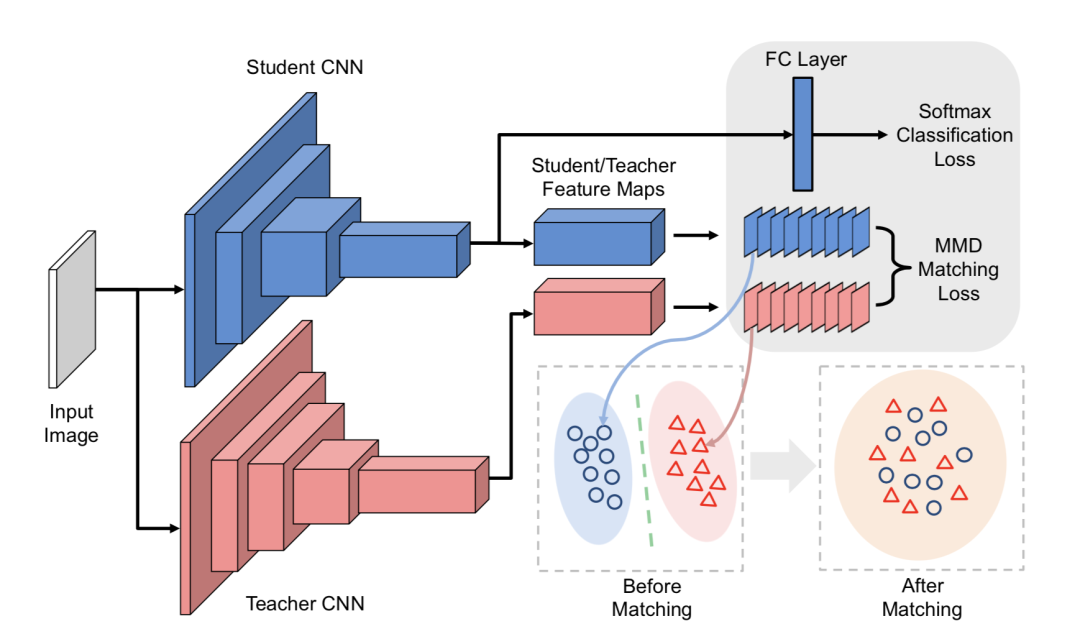
基於特徵空間進行匹配的方法其實是知識蒸餾的主流,類似的方法非常多,包括注意力機制的使用、類似於風格遷移演算法的特徵匹配等。
3. 知識蒸餾演算法的展望
知識蒸餾還有非常多有意思的研究方向,這裡我們介紹其中幾個。
3.1 不壓縮模型
機器學習模型要解決的問題如下,其中y是預測值,x是輸入,L是優化目標,θ1是優化引數。
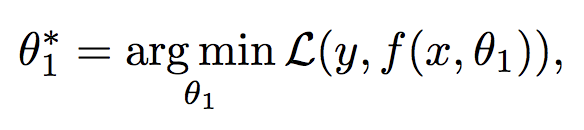
因為深度學習模型沒有解析解,往往無法得到最優解,我們經常會通過新增一些正則項來促使模型達到更好的效能。
Born Again Neural Networks框架思想是通過增加同樣的模型架構,並且重新進行優化,以增加一個模型為例,要解決的問題如下:

具體的流程就是:
(1)訓練一個教師模型使其收斂到較好的區域性值。
(2)對與教師模型結構相同的學生模型進行初始化,其優化目標包含兩部分,一部分是要匹配教師模型的輸出分佈,比如採用KL散度。另一部分就是與教師模型訓練時同樣的目標,即資料集的預測真值。
然後通過下面這樣的流程,一步一步往下傳,所以被形象地命名為“born again”。
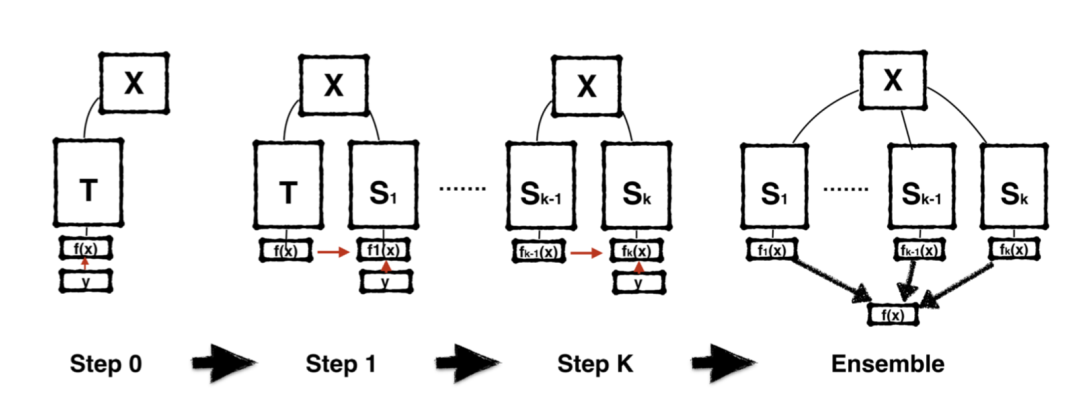
類似的框架還有Net2Net,network morphism等。
3.2 去掉 teacher 模型
一般知識蒸餾框架都需要包括一個Teacher模型和一個Student模型,而Deep mutual learning則沒有Teacher模型,它通過多個小模型進行協同訓練,框架示意圖如下。
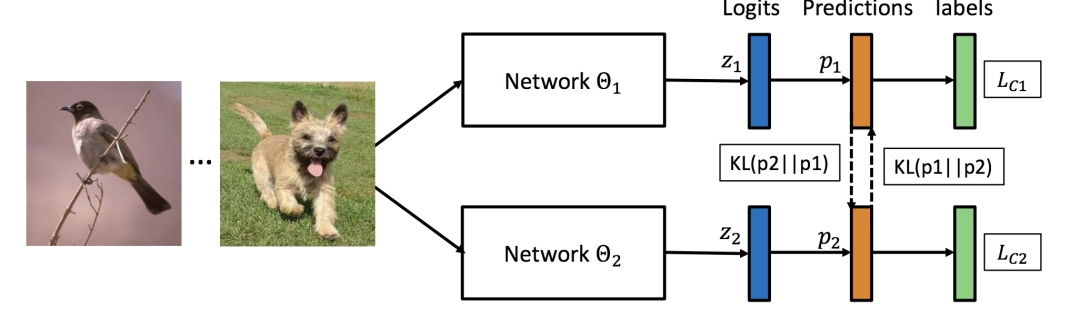
Deep mutual learning在訓練的過程中讓兩個學生網路相互學習,每一個網路都有兩個損失。一個是任務本身的損失,另外一個就是KL散度。由於KL散度是非對稱的,所以兩個網路的散度會不同。
相比單獨訓練,每一個模型可以取得更高的精度。值得注意的是,就算是兩個結構完全一樣的模型,也會學習到不同的特徵表達。
3.3 與其他框架的結合
在進行知識蒸餾時,我們通常假設teacher模型有更好的效能,而student模型是一個壓縮版的模型,這不就是模型壓縮嗎?與模型剪枝,量化前後的模型對比是一樣的。所以知識蒸餾也被用於與相關技術進行結合,apprentice框架是一個代表。
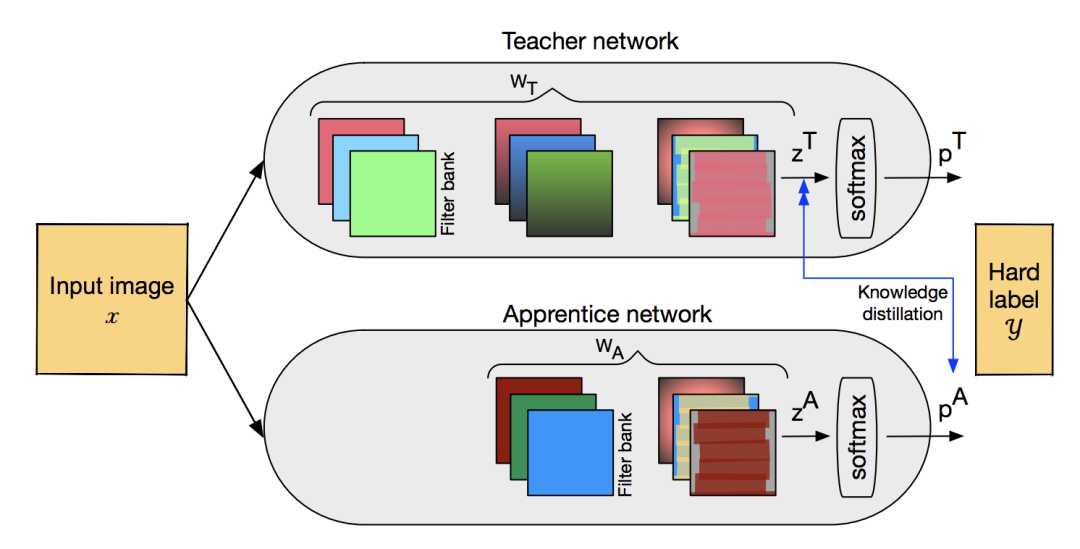
網路結構如上圖所示,Teacher模型是一個全精度模型,Apprentice模型是一個低精度模型。
4. 知識蒸餾在智慧推薦中的應用
如果您對智慧推薦感興趣,歡迎瀏覽我的另一篇部落格:智慧推薦演算法演變及學習筆記 、CTR預估模型演變及學習筆記
本文主要參考:知識蒸餾在推薦系統中的應用
1. 基本概念
深度學習模型正在變得越來越複雜,網路深度越來越深,模型引數量也在變得越來越多。而這會帶來一個現實應用的問題:將這種複雜模型推上線,模型響應速度太慢,當流量大的時候撐不住。
知識蒸餾就是目前一種比較流行的解決此類問題的技術方向。複雜笨重但是效果好的 Teacher 模型不上線,就單純是個導師角色,真正上戰場擋搶撐流量的是靈活輕巧的 Student 小模型。
在智慧推薦中已經提到,一般有三個級聯的過程:召回、粗排和精排。
- 召回環節從海量物品庫裡快速篩選部分使用者可能感興趣的物品,傳給粗排模組。
- 粗排環節通常採取使用少量特徵的簡單排序模型,對召回物料進行初步排序,並做截斷,進一步將物品集合縮小到合理數量,向後傳遞給精排模組。
- 精排環節採用利用較多特徵的複雜模型,對少量物品進行精準排序。
以上環節都可以採用知識蒸餾技術來優化效能和效果,這裡的效能指的線上服務響應速度快,效果指的推薦質量好。
2. 精排環節採用知識蒸餾
精排環節注重精準排序,所以採用儘量多特徵複雜模型,以期待獲得優質的個性化推薦結果。這也意味著複雜模型的線上服務響應變慢。
(1)在離線訓練的時候,可以訓練一個複雜精排模型作為 Teacher,一個結構較簡單的 DNN 排序模型作為 Student。
- 因為 Student 結構簡單,所以模型表達能力弱,於是,我們可以在 Student 訓練的時候,除了採用常規的 Ground Truth 訓練資料外,Teacher 也輔助 Student 的訓練,將 Teacher 複雜模型學到的一些知識遷移給 Student,增強其模型表達能力,以此加強其推薦效果。
(2)在模型上線服務的時候,並不用那個大 Teacher,而是使用小的 Student 作為線上服務精排模型,進行線上推理。
- 因為 Student 結構較為簡單,所以線上推理速度會大大快於複雜模型。
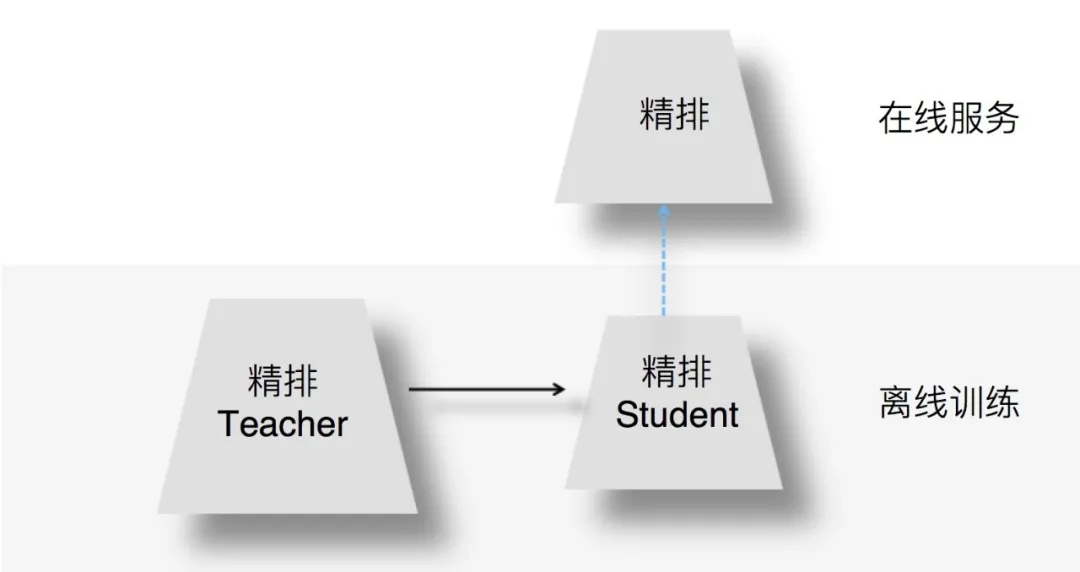
3. 精排環節蒸餾方法
(1)阿里媽媽在論文 "Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net" 提出。
在精排環節採用知識蒸餾,主要採用 Teacher 和 Student 聯合訓練 ( Joint Learning ) 的方法。所謂聯合訓練,指的是在離線訓練 Student 模型的時候,增加複雜 Teacher 模型來輔助 Student,兩者同時進行訓練,是一種訓練過程中的輔導。
從網路結構來說,Teacher 和 Student 模型共享底層特徵 Embedding 層,Teacher 網路具有層深更深、神經元更多的 MLP 隱層,而 Student 則由較少層深及神經元個數的 MLP 隱層構成,兩者的 MLP 部分引數各自私有。
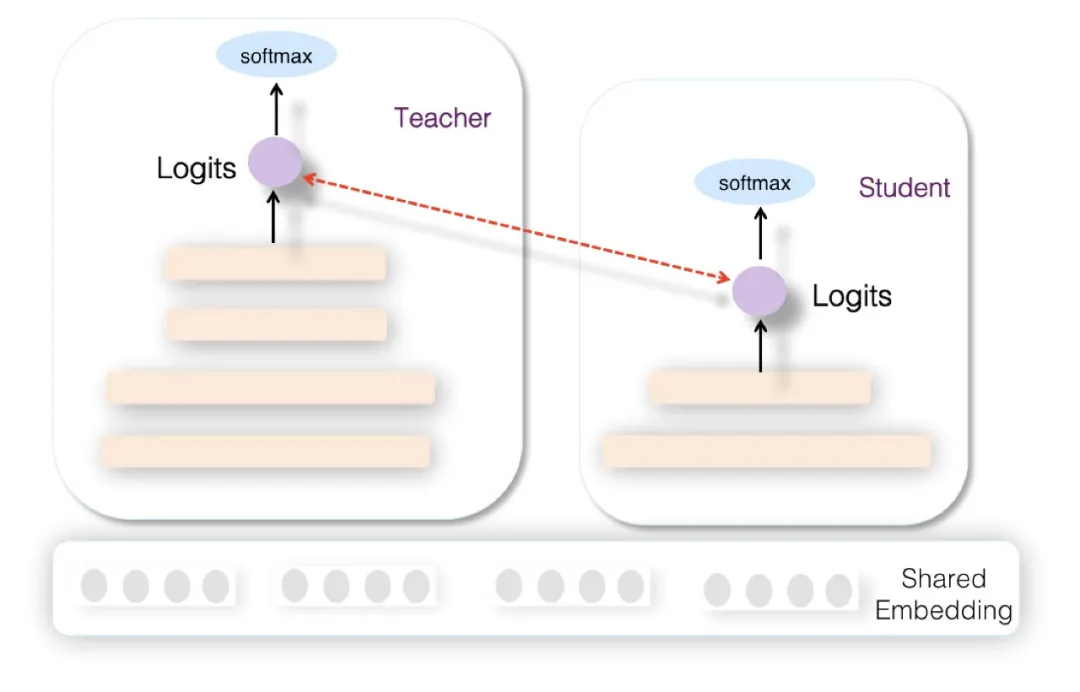
(2)愛奇藝在排序階段提出了雙 DNN 排序模型,可以看作是在阿里的 rocket launching 模型基礎上的進一步改進。
為了進一步增強 student 的泛化能力,要求 student 的隱層 MLP 的啟用也要學習 Teacher 對應隱層的響應,這點同樣可以通過在 student 的損失函式中加子項來實現。但是這會帶來一個問題,就是在 MLP 隱層複雜度方面,Student 和 Teacher 是相當的。那麼,Teacher 相比 student,模型複雜在哪裡呢?
這引出了第二點不同:雙 DNN 排序模型的 Teacher 在特徵 Embedding 層和 MLP 層之間,可以比較靈活加入各種不同方法的特徵組合功能。通過這種方式,體現 Teacher 模型的較強的模型表達和泛化能力。

4. 召回 / 粗排環節採用知識蒸餾
召回或者粗排環節,作為精排的前置環節,需要在準確性和速度方面找到一個平衡點,在保證一定推薦精準性的前提下,對物品進行粗篩,減小精排環節壓力。這兩個環節並不追求最高的推薦精度。畢竟在這兩個環節,如果準確性不足可以靠返回物品數量多來彌補。而模型小,速度快則是模型召回及粗排的重要目標之一。
- 用複雜的精排模型作為 Teacher,召回或粗排模型作為小的 Student,比如 FM 或者雙塔 DNN 模型等。
- 通過 Student 模型模擬精排模型的排序結果,可以使得前置兩個環節的優化目標和推薦任務的最終優化目標保持一致。
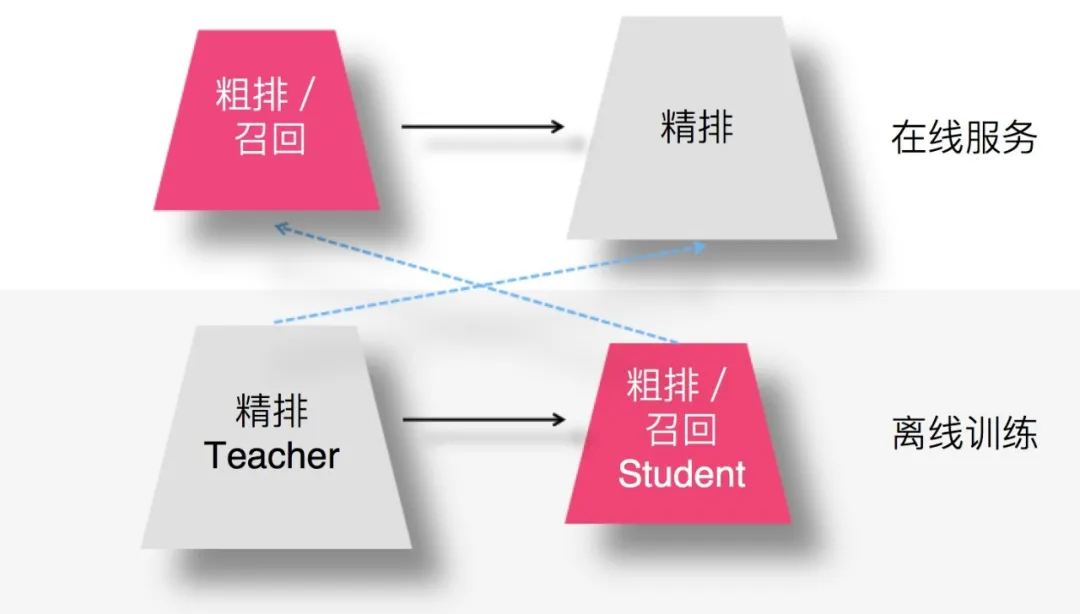
5. 召回/粗排環節蒸餾方法
作者給出了一些可能的處理方式,目前業內還沒定論。
(1)設想一:召回蒸餾的兩階段方法
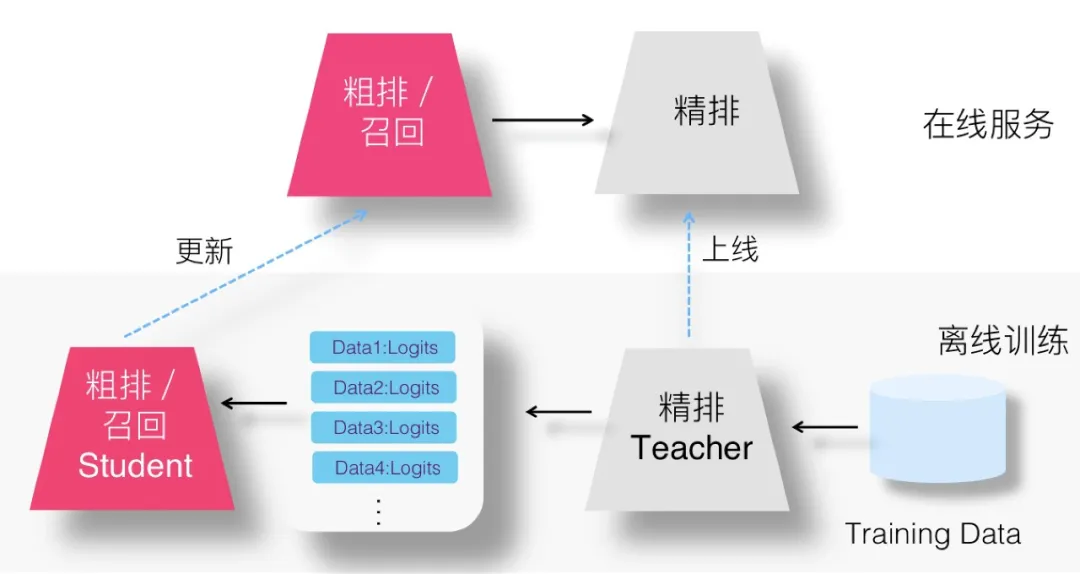
(2)設想二:logits方法
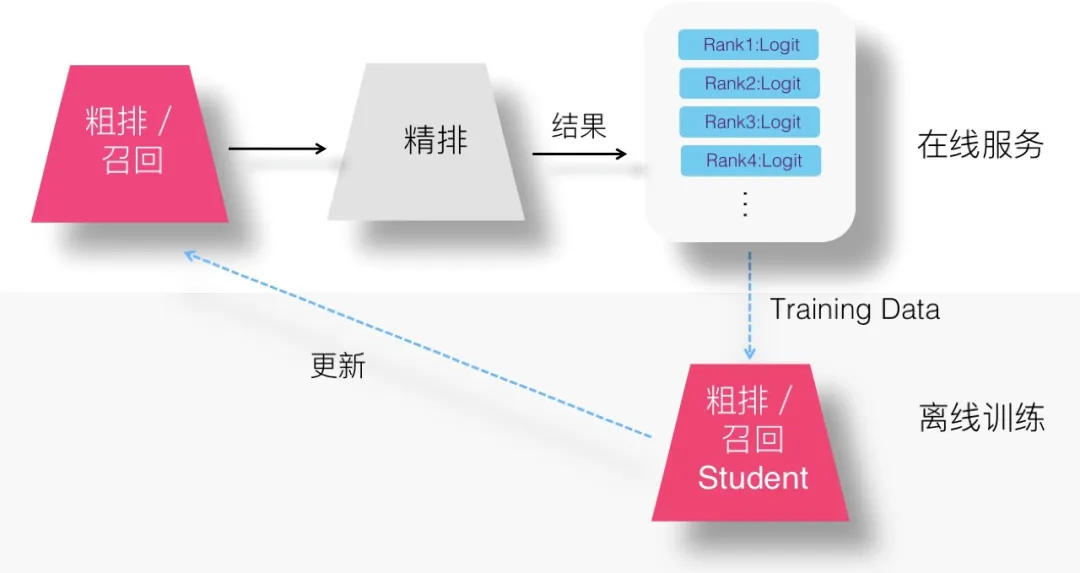
(3)設想三:Without-Logits 方案
(4)設想四:Point Wise 蒸餾:Point Wise Loss 將學習問題簡化為單 Item 打分問題。
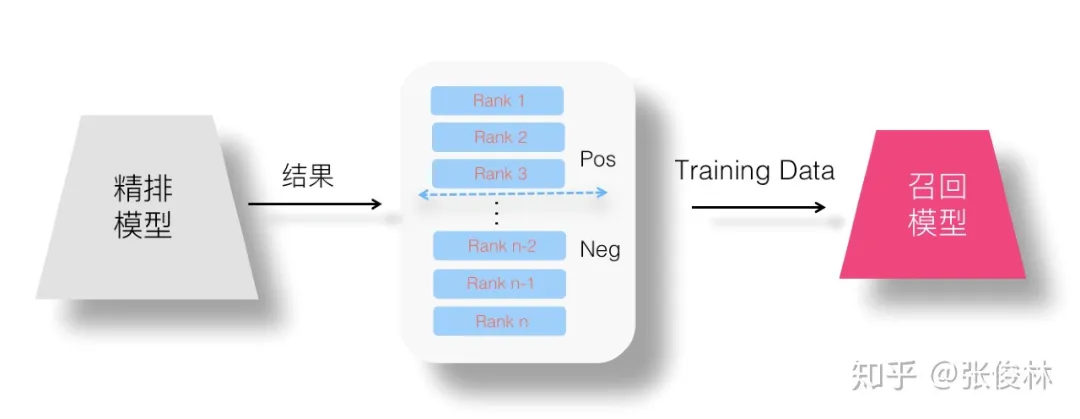
(5)設想五:Pair Wise 蒸餾:Pair Wise Loss 對能夠保持序關係的訓練資料對建模。
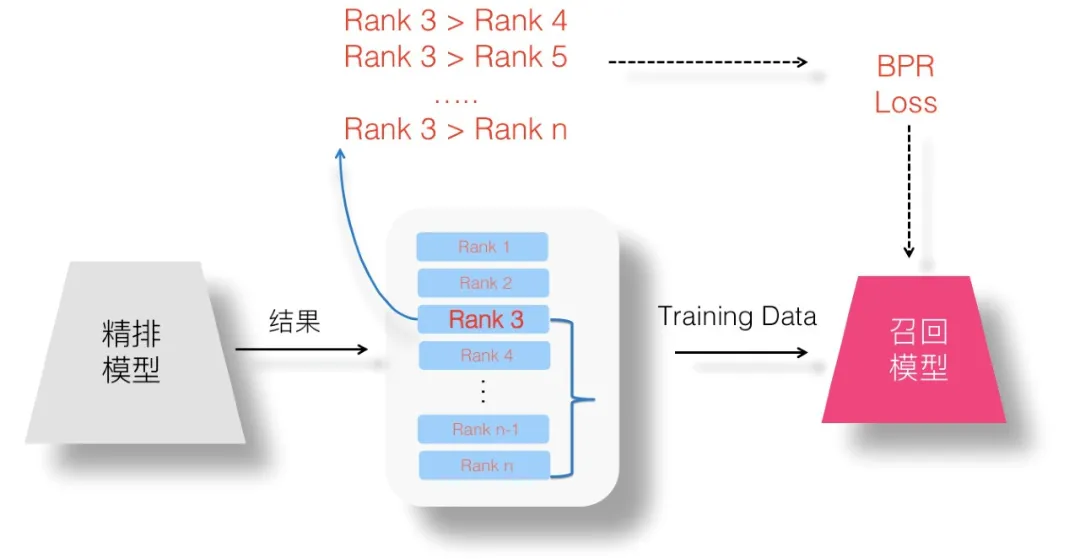
(6)設想六:List Wise 蒸餾:List Wise Loss 則對整個排序列表順序關係建模。
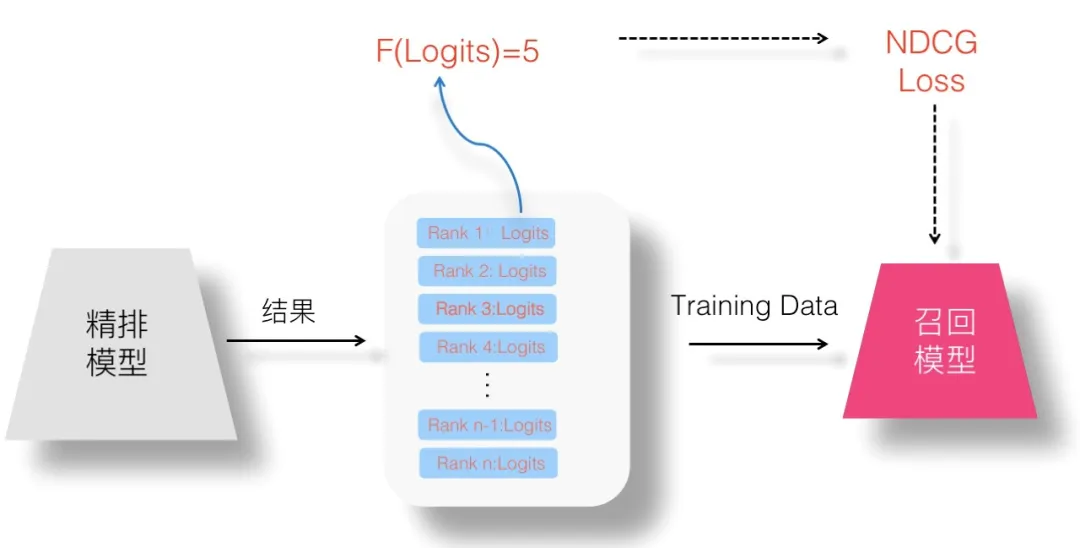
(7)設想七:聯合訓練召回、粗排及精排模型的設想

二、增量學習:補充介紹
主要關注的是災難性遺忘,平衡新知識與舊知識之間的關係。即如何在學習新知識的情況下不忘記舊知識。
引用Robipolikar對增量學習演算法的定義,即一個增量學習演算法應同時具有以下特點:
- 可以從新資料中學習新知識
- 以前已經處理過的資料不需要重複處理
- 每次只有一個訓練觀測樣本被看到和學習
- 學習新知識的同時能保持以前學習到的大部分知識
- 一旦學習完成後訓練觀測樣本被丟棄
- 學習系統沒有關於整個訓練樣本的先驗知識
在概念上,增量學習與遷移學習最大的區別就是對待舊知識的處理:
- 增量學習在學習新知識的同時需要儘可能保持舊知識,不管它們類別相關還是不相關的。
- 遷移學習只是藉助舊知識來學習新知識,學習完成後只關注在新知識上的效能,不再考慮在舊知識上的效能。
關於這部分內容,未來有看到好的資料,再來分享。
如果您對異常檢測感興趣,歡迎瀏覽我的另一篇部落格:異常檢測演算法演變及學習筆記
如果您對智慧推薦感興趣,歡迎瀏覽我的另一篇部落格:智慧推薦演算法演變及學習筆記 、CTR預估模型演變及學習筆記
如果您對知識圖譜感興趣,歡迎瀏覽我的另一篇部落格:行業知識圖譜的構建及應用、基於圖模型的智慧推薦演算法學習筆記
如果您對時間序列分析感興趣,歡迎瀏覽我的另一篇部落格:時間序列分析中預測類問題下的建模方案 、深度學習中的序列模型演變及學習筆記
如果您對資料探勘感興趣,歡迎瀏覽我的另一篇部落格:資料探勘比賽/專案全流程介紹 、機器學習中的聚類演算法演變及學習筆記
如果您對人工智慧演算法感興趣,歡迎瀏覽我的另一篇部落格:人工智慧新手入門學習路線和學習資源合集(含AI綜述/python/機器學習/深度學習/tensorflow)、人工智慧領域常用的開源框架和庫(含機器學習/深度學習/強化學習/知識圖譜/圖神經網路)
如果你是計算機專業的應屆畢業生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的應屆生,你如何準備求職面試?
如果你是計算機專業的本科生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的本科生,你可以選擇學習什麼?
如果你是計算機專業的研究生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的研究生,你可以選擇學習什麼?
如果你對金融科技感興趣,歡迎瀏覽我的另一篇部落格:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之後博主將持續分享各大演算法的學習思路和學習筆記:hello world: 我的部落格寫作思路