
MySQL效能分析(Explain)
阿新 • • 發佈:2020-05-26
> 更多知識,請移步我的小破站:[http://hellofriend.top](http://hellofriend.top)
# 1. 概述
使用`EXPLAIN`關鍵字可以模擬優化器執行SQL查詢語句,從而知道MySQL是如何處理你的SQL語句的。分析你的查詢語句或是表結構的效能瓶頸。
通過`Explain`,我們可以獲取以下資訊:
- 表的讀取順序
- 哪些索引可以使用
- 資料讀取操作的操作型別
- 哪些索引被實際使用
- 表之間的引用
- 每張表有多少行被物理查詢
# 2. 怎樣獲取SQL語句的執行計劃?
```sql
Explain + SQL語句
```
## 舉例
```sql
EXPLAIN SELECT * FROM USER;
```

### 執行計劃所包含的資訊

# 3. 執行計劃各個名詞欄位的解釋
## 3.1 Id
select查詢的序列號,包含一組數字,表示查詢中執行select子句或操作表的順序。
### 三種情況
#### (1) ID相同
id相同,執行順序由上至下。

#### (2)ID不同
如果是子查詢,id的序號會遞增。id越大優先順序越高,越先被執行。

#### (3)ID既有相同的也有不同的
id如果相同,可以認為是一組,從上往下順序執行。在所有組中,id值越大,優先順序越高,越先執行。

### 注意點
id號每個號碼,表示一趟獨立的查詢。一個sql的查詢趟數越少越好。
## 3.2 Select_type
查詢的型別,主要是用於區別普通查詢、聯合查詢、子查詢等的複雜查詢。
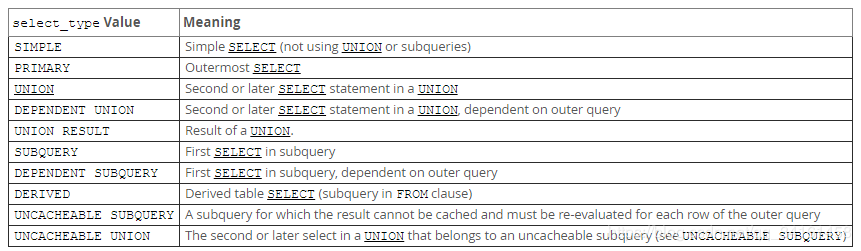
- **Simple**:簡單的 select 查詢,查詢中不包含子查詢或者UNION。

- **Primary**:查詢中若包含任何複雜的子部分,最外層查詢則被標記為Primary。

- **Derived**:在FROM列表中包含的子查詢被標記為DERIVED(衍生),MySQL會遞迴執行這些子查詢, 把結果放在臨時表裡。

- **SubQuery**:在SELECT或WHERE列表中包含了子查詢。

- **Dependent SubQuery**:在SELECT或WHERE列表中包含了子查詢,用到了IN關鍵字的。

- **Uncacheable SubQuery**:不可以使用到快取的子查詢,用到了變數作為篩選條件。

- **Union**:若第二個SELECT出現在UNION之後,則被標記為UNION;若UNION包含在FROM子句的子查詢中,外層SELECT將被標記為:DERIVED。
-
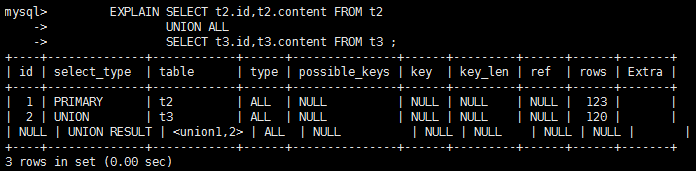
- **Union Result**:從UNION表獲取結果的SELECT。
## 3.3 Table
顯示這一行的資料是關於哪張表的。
## 3.4 Partitions
代表分割槽表中的命中情況,非分割槽表,該項為null。
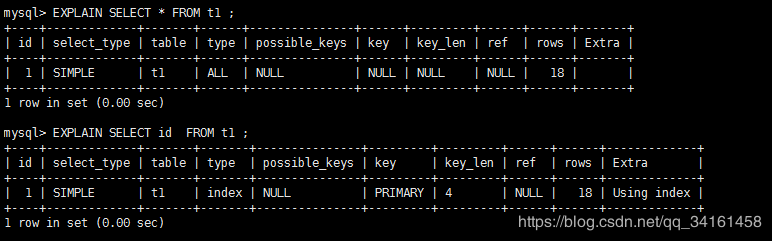
## 3.5 Type
type顯示的是訪問型別,是較為重要的一個指標,結果值從最好到最壞依次是:
```powershell
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
```
一般來說,得保證查詢至少達到`range`級別,最好能達到`ref`。
顯示查詢使用了何種型別,從最好到最差依次是:
```powershell
system > const > eq_ref > ref > range > index > ALL
```
### 總覽

### 三種需要優化的型別
#### Range
只檢索給定範圍的行,使用一個索引來選擇行。key 列顯示使用了哪個索引。一般就是在你的where語句中出現了between、<、>、in等的查詢。
這種範圍掃描索引掃描比全表掃描要好,因為它只需要開始於索引的某一點,而結束語另一點,不用掃描全部索引。


#### Index
SQL使用到了索引,但是沒用索引進行過濾。一般是使用到了覆蓋索引或者是使用索引進行排序分組。
#### All
Full Table Scan,將遍歷全表以找到匹配的行。

## 3.6 Possible_Keys
顯示可能應用在這張表中的索引,一個或多個。查詢涉及到的欄位上若存在索引,則該索引將被列出,但不一定被查詢實際使用。
## 3.7 Key
實際使用的索引。如果為NULL,則沒有使用索引。查詢中若使用了覆蓋索引,則該索引和查詢的select欄位重疊。
## 3.8 Key_Len
表示索引中使用的位元組數,可通過該列計算查詢中使用的索引的長度。key_len欄位能夠幫你檢查是否充分的利用上了索引。`key_len越長,查詢效率越高`。Where條件命中索引的長度,不包含分組排序。
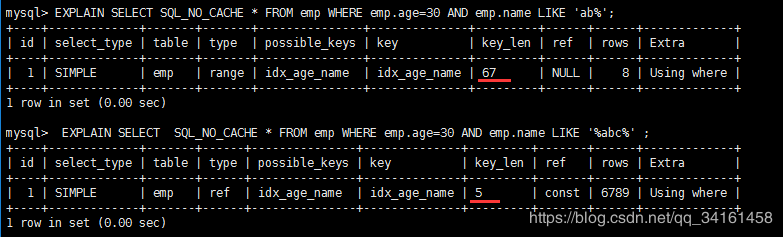
## 3.9 Ref
顯示索引的哪一列被使用了,如果可能的話,是一個常數。哪些列或常量被用於查詢索引列上的值。

## 3.10 Rows
rows列顯示MySQL認為它執行查詢時必須檢查的行數。行數越少,效率越高!
## 3.11 Filtered
這個欄位表示儲存引擎返回的資料在server層過濾後,剩下多少滿足查詢的記錄數量的比例,注意是百分比,不是具體記錄數。
## 3.12 Extra
包含不適合在其他列中顯示但十分重要的額外資訊。主要用來檢查分組、排序的時候用沒用到索引。
#### Using filesort
說明mysql會對資料使用一個外部的索引排序,而不是按照表內的索引順序進行讀取。MySQL中無法利用索引完成的排序操作稱為“ 檔案排序 ”。**排序的欄位沒有建立索引**。
#### Using temporary
使了用臨時表儲存中間結果,MySQL在對查詢結果排序時使用臨時表。常見於排序 order by 和分組查詢 group by。**分組的時候使用的欄位沒有建立索引,分組其實內部包含了一個排序的過程,所以上面的Using filesort 也會出現。**
#### Using Index
表示相應的select操作中使用了覆蓋索引,避免訪問了表的資料行,效率不錯。
#### Using Where
表明使用到了Where過濾。
#### Using Join Buffer
使用到了連線快取。
#### Impossible where
where 子句的結果永遠為false,表示sql語句錯了。
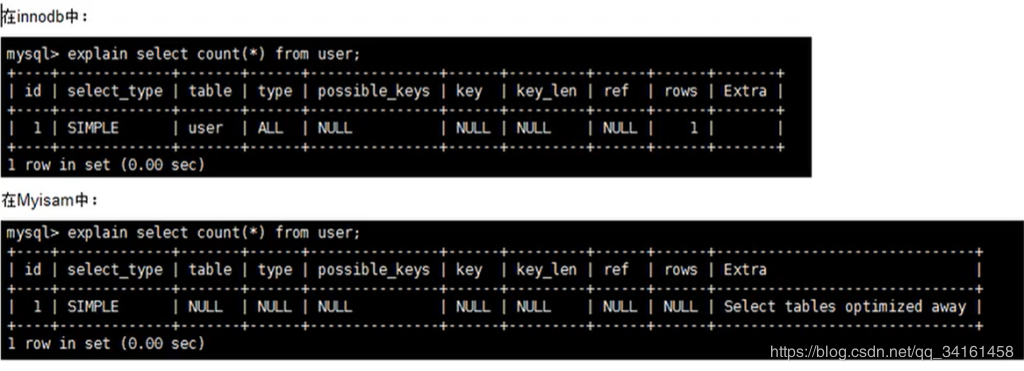
#### Select tables optimized away
在沒有GROUPBY子句的情況下,基於索引優化MIN/MAX操作或者 對於MyISAM儲存引擎優化COUNT(*)操作,不必等到執行階段再進行計算, 查詢執行計劃生成的階段即完成優化。
# 總結
本文講述了通過使用`Explain`關鍵字進行MySQL語句效能的分析,下篇將更進一步的講解如何進行優化。
> 本文由部落格群發一文多發等運營工具平臺 [OpenWrite](https://openwrite.cn?from=article_bottom