
曹工說JDK原始碼(3)--ConcurrentHashMap,Hash演算法優化、位運算揭祕
阿新 • • 發佈:2020-06-09
# hashcode,有點講究
什麼是好的hashcode,一般來說,一個hashcode,一般用int來表示,32位。
下面兩個hashcode,大家覺得怎麼樣?
```java
0111 1111 1111 1111 1111 1111 1111 1111 ------A
1111 1111 1111 1111 1111 1111 1111 1111 ------B
```
只有第32位(從右到左)不一樣,好像也沒有所謂的好壞吧?
那,我們再想想,hashcode一般怎麼使用呢?在hashmap中,由陣列+連結串列+紅黑樹組成,其中,陣列乃重中之重,假設陣列長度為2的n次方,(hashmap的陣列,強制要求長度為2的n次方),這裡假設為8.
大家又知道,hashcode 對 8 取模,效果等同於 hashcode & (8 - 1)。
那麼,前面的A 和 (8 - 1)相與的結果如何呢?
```java
0111 1111 1111 1111 1111 1111 1111 1111 ------A
0000 0000 0000 0000 0000 0000 0000 0111 ------ 8 -1
相與
0000 0000 0000 0000 0000 0000 0000 0111 ------ 7
```
結果為7,也就是,會放進array[7]。
大家再看B的計算過程:
```java
1111 1111 1111 1111 1111 1111 1111 1111 ------B
0000 0000 0000 0000 0000 0000 0000 0111 ------ 8 -1
相與
0000 0000 0000 0000 0000 0000 0000 0111 ------ 7
```
雖然B的第32位為1,但是,奈何和我們相與的隊友,7,是個垃圾。
前面的高位,全是0。
ok,你懂了嗎,陣列長度太小了,才8,導致前面有29位都是0;你可能覺得一般容量不可能這麼小,那假設容量為2的16次方,容量為65536,這下不是很小了吧,但即使如此,前面的16位也是0.
所以,問題明白了嗎,我們計算出來的hashcode,低位相同,高位不同;但是,因為和我們進行`與`計算的隊友太過垃圾,導致我們出現了hash衝突。
ok,我們怎麼來解決這個問題呢?
我們能不能把高位也參與計算呢?自然,是可以的。
# hashmap中如何優化
```java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
```
這裡,其實分了3個步驟:
1. 計算hashcode,作為運算元1
```java
h = key.hashCode()
```
2. 將第一步的hashcode,右移16位,作為運算元2
```java
h >>> 16
```
3. 運算元1 和 運算元2 進行異或操作,得到最終的hashcode
還是拿前面的來算,
```java
0111 1111 1111 1111 1111 1111 1111 1111 ------A
0000 0000 0000 0000 0111 1111 1111 1111 ----- A >>> 16
異或(相同則為0,否則為1)
0111 1111 1111 1111 1000 0000 0000 0000 --- 2147450880
```
這裡算出來的結果是 2147450880,再去對 7 進行與運算:
```java
0111 1111 1111 1111 1000 0000 0000 0000 --- 2147450880
0000 0000 0000 0000 0000 0000 0000 0111 ------ 8 -1
與運算
0000 0000 0000 0000 0000 0000 0000 0000 ------ 0
```
這裡的A,算出來,依然在array[0]。
再拿B來算一下:
```java
1111 1111 1111 1111 1111 1111 1111 1111 ------ B
0000 0000 0000 0000 1111 1111 1111 1111 ----- B >>> 16
異或(相同則為0,否則為1)
1111 1111 1111 1111 0000 0000 0000 0000 --- -65536
0000 0000 0000 0000 0000 0000 0000 0111 ------ 7
與運算
0000 0000 0000 0000 0000 0000 0000 0000 ------- 0
```
最終算出來為0,所以,應該放在array[0]。
恩?算出來兩個還是衝突了,我只能說,我挑的數字真的牛逼,是不是該去買彩票啊。。
總的來說,大家可以多試幾組數,下邊提供下原始碼:
```java
public class BinaryTest {
public static void main(String[] args) {
int a = 0b00001111111111111111111111111011;
int b = 0b10001101111111111111110111111011;
int i = tabAt(32, a);
System.out.println("index for a:" + i);
i = tabAt(32, b);
System.out.println("index for b:" + i);
}
static final int tabAt(int arraySize, int hash) {
int h = hash;
int finalHashCode = h ^ (h >>> 16);
int i = finalHashCode & (arraySize - 1);
return i;
}
}
```
雖然說,我測試了幾個數字,還是有些衝突,但是,你把高16位弄進來參與計算,總比你不弄進來計算要好吧。
大家也可以看看hashmap中,hash方法的註釋:
> ```
> /**
> * Computes key.hashCode() and spreads (XORs) higher bits of hash
> * to lower. Because the table uses power-of-two masking, sets of
> * hashes that vary only in bits above the current mask will
> * always collide. (Among known examples are sets of Float keys
> * holding consecutive whole numbers in small tables.) So we
> * apply a transform that spreads the impact of higher bits
> * downward. There is a tradeoff between speed, utility, and
> * quality of bit-spreading. Because many common sets of hashes
> * are already reasonably distributed (so don't benefit from
> * spreading), and because we use trees to handle large sets of
> * collisions in bins, we just XOR some shifted bits in the
> * cheapest possible way to reduce systematic lossage, as well as
> * to incorporate impact of the highest bits that would otherwise
> * never be used in index calculations because of table bounds.
> */
> ```
裡面提到了2點:
> So we apply a transform that spreads the impact of higher bits downward.
所以,我們進行了一個轉換,把高位的作用利用起來。
> we just XOR some shifted bits in the cheapest possible way to reduce systematic lossage, as well as
>
> to incorporate impact of the highest bits that would otherwise never be used in index calculations because of table bounds.
我們僅僅異或了從高位移動下來的二進位制位,用最經濟的方式,削減系統性能損失,同樣,因為陣列大小的限制,導致高位在索引計算中一直用不到,我們通過這種轉換將其利用起來。
# ConcurrentHashMap如何優化
在concurrentHashMap中,其主要是:
```java
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
```
這裡主要是使用spread方法來計算hash值:
```java
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
```
大家如果要仔細觀察每一步的二進位制,可以使用下面的demo:
```java
static final int spread(int h) {
// 1
String s = Integer.toBinaryString(h);
System.out.println("h:" + s);
// 2
String lower16Bits = Integer.toBinaryString(h >>> 16);
System.out.println("lower16Bits:" + lower16Bits);
// 3
int temp = h ^ (h >>> 16);
System.out.println("h ^ (h >>> 16):" + Integer.toBinaryString(temp));
// 4
int result = (temp) & HASH_BITS;
System.out.println("final:" + Integer.toBinaryString(result));
return result;
}
```
這裡和HashMap相比,多了點東西,也就是多出來了:
`& HASH_BITS;`
這個有什麼用處呢?
因為`(h ^ (h >>> 16))`計算出來的hashcode,可能是負數。這裡,和 HASH_BITS進行了相與:
```java
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
```
```java
1111 1111 1111 1111 1111 1111 1111 1111 假設計算出來的hashcode為負數,因為第32位為1
0111 1111 1111 1111 1111 1111 1111 1111 0x7fffffff
進行相與
0111 ..................................
```
這裡,第32位,因為0x7fffffff的第32位,總為0,所以相與後的結果,第32位也總為0 ,所以,這樣的話,hashcode就總是正數了,不會是負數。
# concurrentHashMap中,node的hashcode,為啥不能是負數
當hashcode為正數時,表示該雜湊桶為正常的連結串列結構。
當hashcode為負數時,有幾種情況:
## ForwardingNode
此時,其hash值為:
```java
static final int MOVED = -1; // hash for forwarding nodes
```
當節點為ForwardingNode型別時(表示雜湊表在擴容進行中,該雜湊桶已經被遷移到了新的臨時hash表,此時,要get的話,需要去臨時hash表查詢;要put的話,是不行的,會幫助擴容)
## TreeBin
```java
static final int TREEBIN = -2; // hash for roots of trees
```
表示,該雜湊桶,已經轉了紅黑樹。
# 擴容時的位運算
```java
/**
* Returns the stamp bits for resizing a table of size n.
* Must be negative when shifted left by RESIZE_STAMP_SHIFT.
*/
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
```
這裡,假設,n為4,即,hashmap中陣列容量為4.
* 下面這句,求4的二進位制表示中,前面有多少個0.
Integer.numberOfLeadingZeros(n)
表示為32位後,如下
0000 0000 0000 0000, 0000 0000 0000 0100
所以,前面有29個0,即,這裡的結果為29.
* (1 << (RESIZE_STAMP_BITS - 1)
這一句呢,其中RESIZE_STAMP_BITS 是個常量,為16. 相當於,把1 向左移動15位。
二進位制為:
```java
1000 0000 0000 0000 -- 1 << 15
```
最終結果:
```java
0000 0000 0000 0000 0000 0000 0001 1101 -- 29
0000 0000 0000 0000 1000 0000 0000 0000 -- 1 << 15
進行或運算
0000 0000 0000 0000 1000 0000 0001 1101 -- 相當於把29的第一位,變成了1,其他都沒變。
```
所以,最終結果是,
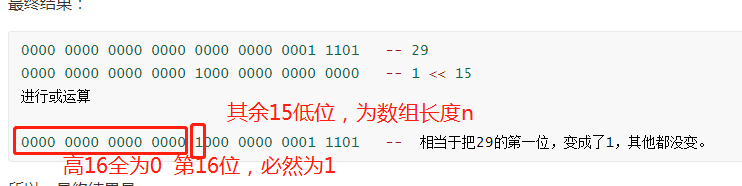
這個數,換算為10進位制,為32972,是個正數。
這個數,有啥用呢?
在addCount函式中,當整個雜湊表的鍵值對數量,超過sizeCtl時(一般為0.75 * 陣列長度),就會觸發擴容。
```java
java.util.concurrent.ConcurrentHashMap#addCount
int sc = sizeCtl;
boolean bSumExteedSizeControl = newBaseCount >