
網路KPI異常檢測之時序分解演算法
時間序列資料伴隨著我們的生活和工作。從牙牙學語時的“1, 2, 3, 4, 5, ……”到房價的走勢變化,從金融領域的刷卡記錄到運維領域的核心網效能指標。時間序列中的規律能加深我們對事物和場景的認識,時間序列中的異常能提醒我們某些部分可能出現問題。那麼如何去發現時間序列中的規律、找出其中的異常點呢?接下來,我們將揭開這些問題的面紗。
什麼是異常
直觀上講,異常就是現實與心理預期產生較大差距的特殊情形。如2020年春節的新型肺炎(COVID-19,coronavirus disease 2019),可以看到2月12日有一個明顯的確診病例的升高,這就是一個異常點,如下圖:
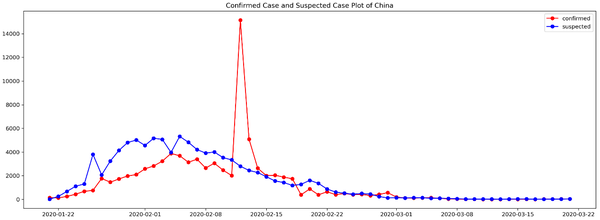
從統計上講,嚴重偏離預期的點,常見的可以通過3-sigma準則來判定。
從數學上講,它就是一個分段函式:

那麼我們有哪些方法來發現異常呢?異常分析的方法有很多,在本文中,我們主要講解時間序列分解的演算法。接下來,我們先從時間序列的定義開始講起。
什麼是時間序列
前面章節,我們列舉了生活和工作中的一些時間序列的例子,但是並沒有給出定義。在本節中,我們將首先給出時間序列的定義,然後給出時間序列的分類方法,最後再給大家展示常見的時間序列。
1.時間序列的定義
時間序列是不同時間點的一系列變數所組成的有序序列。例如北京市2013年4月每日的平均氣溫就構成了一個時間序列,為了方便,我們一般認為序列中相鄰元素具有相同的時間間隔。
時間序列可以分為確定的和隨機的。例如,一個1990年出生的人,從1990年到1999年年齡可以表述為{0,1,2,…,9},這個序列並沒有任何隨機因素。這是一個確定性的時間序列。現實生活中我們所面對的序列更多的是摻雜了隨機因素的時間序列,例如氣溫、銷售量等等,這些是帶有隨機性的例子。我們說的時間序列一般是指帶有隨機性的。
那麼對於隨機性的時間序列,又如何進行分類呢?
2.時間序列的分類
從研究物件上分,時間序列分為一元時間序列和多元時間序列,如新冠肺炎例子中,只看確診病例的變化,它是一元時間序列。如果把確診病例和疑似病例聯合起來看,它是一個多元時間序列。
從時間引數上分,時間序列分為離散時間的時間序列和連續時間的時間序列。例如氣溫變化曲線,通常是按照天、小時進行預測、計算的,這個採集的時間是離散的,因此,它是一個離散時間的時間序列。再如花粉在水中呈現不規則的運動,它無時無刻不在運動,它是一個連續時間的時間序列,這就是大家眾所周知的布朗運動。在我們的工作中,我們一般遇到的都是離散時間的時間序列。
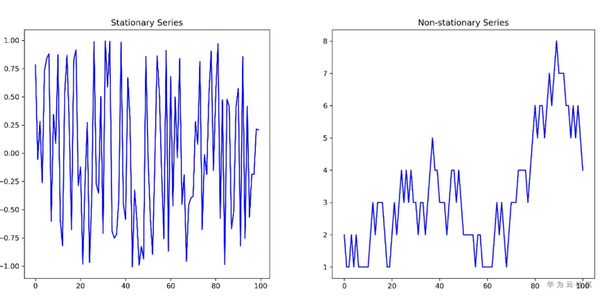
從統計特徵上分,時間序列分為平穩時間序列和非平穩時間序列。平穩序列從直觀上講,均值和標準差不隨著時間發生變化,而非平穩序列均值或者標準差一般會隨著時間發生變化。下面兩個圖分別給出平穩序列和非平穩序列的例子。
3.常見的時間序列
在本節,我們將給大家列舉一些常見的時間序列,讓大家對常見的時間序列有一個直觀的概念。
時間序列的分解
前面給大家講了異常和時間序列的概念,本章將給大家講解時間序列分解技術。
1.目的
時間序列分解是探索時序變化規律的一種方法,主要探索週期性和趨勢性。基於時序分解的結果,我們可以進行後續的時間預測和異常檢測。
2.主要組成部分
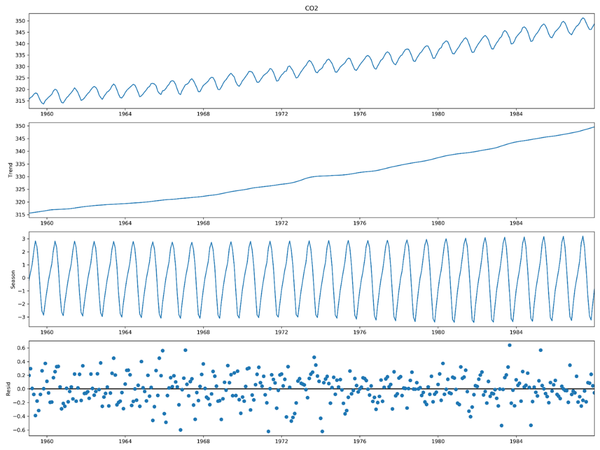
在時間序列分析中,我們經常要關注趨勢和週期。因此,一般地,我們將時序分成三個部分:趨勢部分、週期部分和殘差部分。結合下圖CO2含量的例子(見下圖)對這三個主要部分進行解釋:
1)趨勢部分:展示了CO2含量逐年增加;
2)週期部分:反應了一年中CO2含量是週期波動的;
3)殘差部分:趨勢和週期部分不能解釋的部分。
3.時序分解模型
時間序列分解基於分解模型的假設。通常,我們會考慮以下兩種模型:

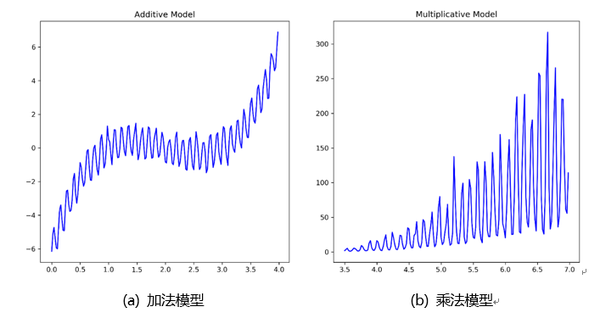
加法模型適用於以下場景:
- 當週期性不隨著趨勢發生變化時,首選加法模型,如下圖(a);
- 當目標存在負值時,應選擇加法模型;
乘法模型適用於以下場景:
- 週期隨著隨時發生變化時,首選乘法模型,如下圖(b);
- 經濟資料,首選乘法模型(增長率、可解釋)。
另外,當我們不清楚選擇哪個模型時,可以兩個模型都使用,選擇誤差最小的那一個。
由於乘法模型與加法模型可以相互轉化,我們後面僅以加法模型來進行介紹。
4.時序分解演算法
基於週期、趨勢分解的時序分解演算法主要有經典時序分解演算法、Holt-Winters演算法和STL演算法。經典時序分解演算法起源於20世紀20年代,方法較簡單。Holt-Winters演算法於1960年由Holt的學生 Peter Winters 提出,能夠適應隨著時間變化的季節項。STL(Seasonal and Trend decomposition using Loess)分解法,由Cleveland 等於1990年提出,比較通用,且較為穩健。三者之間的關係,如下圖所示:
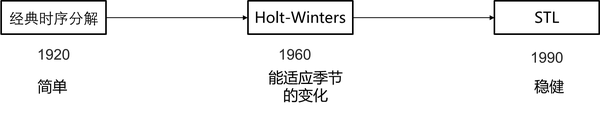
4.1經典時序分解演算法
經典時序分解演算法是最簡單的一種分解演算法,它是很多其他分解演算法的基礎。該演算法基於“季節部分不隨著時間發生變化”這一假設,且需要知道序列的週期。另外,該演算法基於滑動平均技術。
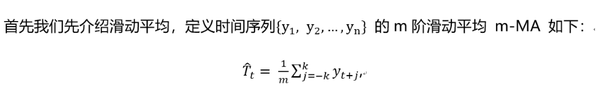
其中,m=2k+1. 也就是說,時刻t的趨勢項的估計值可以通過前後k個時刻內的平均值得到。階數 m 越大,趨勢越光滑。由上面的公式可以看出,m一般取奇數,這保證了對稱性。但是在很多場景下,週期是偶數,例如一年有4個季度,則週期為4,是偶數。此時,需要做先做一個4階滑動平均(4-MA),再對所得結果做一個2階滑動平均(2-MA),整個過程記為 。這樣處理後的結果是對稱的,即加權的滑動平均,數學表達如下:
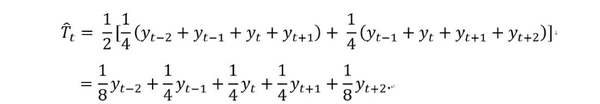
下面我們將講解經典時序分解演算法的計算步驟。

經典時序分解演算法雖然簡單、應用廣泛,但是也存在一些問題:
1) 無法估計序列最前面幾個和最後面幾個的趨勢和週期部分,例如若m=4,則無法估計前2個和後2個觀測的趨勢和週期的部分;
2) 嚴重依賴“季節性部分每個週期都是相同的”這一假設;
3) 過度光滑趨勢部分。
4.2Holt-Winters演算法
在上一節中,我們介紹了經典時序分解演算法,但是它嚴重依賴“季節性部分每個週期都是相同的”這一假設。為了能夠適應季節部分隨時間發生變化,Holt-Winters演算法被提出。Holt-Winters演算法是基於簡單指數光滑技術。首先,我們先介紹簡單指數光滑技術。
簡單指數光滑的思想主要是以下兩點:
- 對未來的預測:用當前的水平對下一時刻的點進行預測;
- 當前水平的估計:使用當前時刻的觀測值和預測值(基於歷史觀測資料的預測值,即上一時刻的水平)的加權平均作為當前水平的估計。
簡單指數光滑的模型比較簡單,如下:

Holt-Winters演算法是簡單指數光滑在趨勢(可理解為水平的變化率)和季節性上的推廣,主要包括水平(前文中的趨勢項)、趨勢項和季節項三個部分。

4.3 STL演算法
STL(Seasonal and Trend decomposition using Loess)是一個非常通用的、穩健性強的時序分解方法,其中Loess是一種估算非線性關係的方法。STL分解法由 Cleveland et al. (1990) 提出。
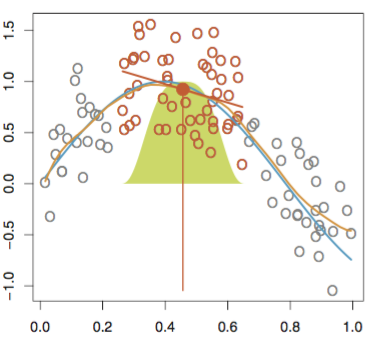
STL演算法中最主要的是區域性光滑技術 (locally weighted scatterplot smoothing, LOWESS or LOESS),有時也稱為區域性多項式迴歸擬合。它是對兩維散點圖進行平滑的常用方法,它結合了傳統線性迴歸的簡潔性和非線性迴歸的靈活性。當要估計某個響應變數值時,先從其預測點附近取一個數據子集(如下圖實點 是要預測的點,選取周圍的需點來進行擬合),然後對該子集進行線性迴歸或二次迴歸,迴歸時採用加權最小二乘法(如下圖,採用的是高斯核進行加權),即越靠近估計點的值其權重越大,最後利用得到的區域性迴歸模型來估計響應變數的值。用這種方法進行逐點運算得到整條擬合曲線。
STL演算法的主要環節包含內迴圈、外迴圈和季節項後平滑三個部分:
- 內迴圈:

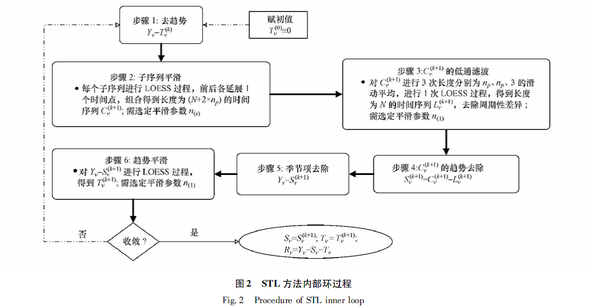
- 外迴圈:
外迴圈主要作用則是引入了一個穩健性權重項,以控制資料中異常值產生的影響,這一項將會考慮到下一階段內迴圈的臨近權重中去。
- 季節項後平滑:
趨勢分量和季節分量都是在內迴圈中得到的。迴圈完後,季節項將出現一定程度的毛刺現象,因為在內迴圈中平滑時是在每一個截口中進行的,因此,在按照時間序列重排後,就無法保證相鄰時段的平滑了,為此,還需要進行季節項的後平滑,後平滑基於區域性二次擬合,並且不再需要在loess中進行穩健性迭代。
異常判斷的準則
對於異常的判斷,我們常用的有 n-sigma 準則和boxplot準則(箱線圖準則)。那這些準備是如何計算的,有哪些區別和聯絡呢?
1.n-sigma 準則

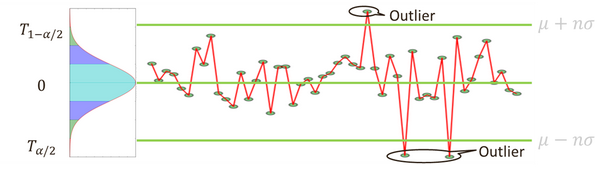
n-sigma準則有計算簡單、效率高且有很強的理論支撐,但是需要近似正態的假設,且均值和標準差的計算用到了全部的資料,因此,受異常點的影響較大。
2.boxplot 準則
為了降低異常點的影響,boxplot準則被提出。boxplot(箱線圖)是一種用作顯示一組資料分散情況的統計圖,經常用於異常檢測。BoxPlot的核心在於計算一組資料的中位數、兩個四分位數、上限和下限,基於這些統計值畫出箱線圖。

根據上面的統計值就可以畫出下面的圖,超過上限的點或這個低於下限的點都可以認為是異常點。
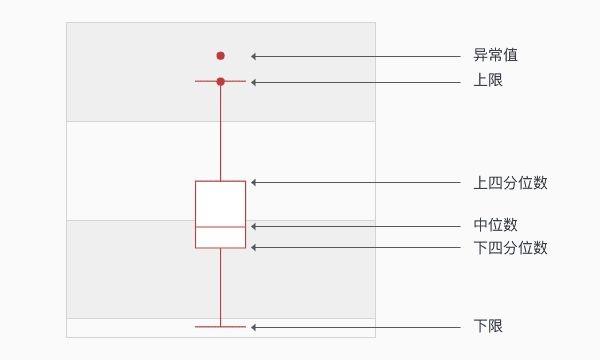
從上面的計算上可以看出,boxplot對異常點是穩健的。
基於時序分解的異常檢測演算法
在前面的章節,我們瞭解了時序分解的演算法,也學習了異常判斷的準則,那麼如何基於時序分解進行異常檢測呢?在本章,我們將首先給出異常檢測演算法的原理,再給出基於時序分解的異常檢測演算法步驟。
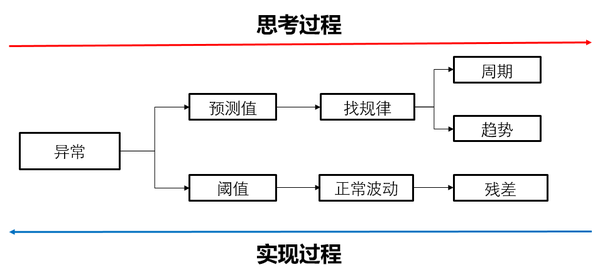
1.異常檢測演算法原理
回顧一下異常的定義,它是一個分段函式:
我們可以看到預測值(擬合值)和閾值是不知道的。對於預測值,我們可以通過找規律來猜這個預測值是多少,本章我們可以通過時序分解找週期和趨勢的規律,進而得到預測值。對於閾值,我們可以看到閾值是針對真實值和預測值的差值設定的,目的是把異常值找到,因此我們只要找到正常值的殘差和異常值的殘差的邊界即可。而我們n-sigma準則和boxplot準則就可以根據殘差把邊界找出來,即閾值。這個思考和實現的過程示意圖如下:
2.基於時序分解的異常檢測演算法

Demo程式碼下載地址 ,本文主要是想記錄基於時間序列的異常檢測方法,希望能夠幫到你。
點選關注,第一時間瞭解華為雲新鮮技術~

相關推薦
網路KPI異常檢測之時序分解演算法
時間序列資料伴隨著我們的生活和工作。從牙牙學語時的“1, 2, 3, 4, 5, ……”到房價的走勢變化,從金融領域的刷卡記錄到運維領域的核心網效能指標。時間序列中的規律能加深我們對事物和場景的認識,時間序列中的異常能提醒我們某些部分可能出現問題。那麼如何去發現時間序列中的規律、找出其中的異常點呢?接下來,我
基於PySpark的網路服務異常檢測系統 (四) Mysql與SparkSQL對接同步資料 kmeans演算法計算預測異常
def get_current_timestamp(): 2 """ 3 獲取當前時間戳 4 :return: 5 """ 6 return int(time.time()) * 1000 7 8 9 def convert_datetime_to_
異常檢測之淺談入侵檢測
開啟微信掃一掃,關注微信公眾號【資料與演算法聯盟】 轉載請註明出處:http://blog.csdn.net/gamer_gyt 博主微博:http://weibo.com/234654758 Github:https://github.c
異常檢測之正態分佈
開啟微信掃一掃,關注微信公眾號【資料與演算法聯盟】 轉載請註明出處:http://blog.csdn.net/gamer_gyt 博主微博:http://weibo.com/234654758 Github:https://github.
opencv輪廓檢測之FindContours函式演算法解釋
在檢測物體的輪廓時,我們通常會使用到opencv中的findcontour和drawcontour,比較常用而且效果不錯。 1985年,satoshi suzuki發表了一篇論文,Topological structural analysis of digitized bi
spark高階資料分析---網路流量異常檢測(升級實戰)
在我的上一篇裡我寫的那個只是個人對KMeans聚類在這個專案中的一部分,今天花了很長時間寫完和完整的執行測試完這個程式碼,篇幅很長,都是結合我前面寫的加上自己完善的異常檢測部分,廢話不多說,直接程式碼實戰: package internet import org.apa
機器學習----無監督學習演算法之異常檢測
問題2:如何選取有用的features 方法:觀察已有的屬性分佈,畫出高斯分佈圖形,觀察到有些異常樣本被正常樣本包圍,思考原因,這時,可以試著新增一個新的feature,這個新的feature能夠將異常樣本從正常樣本中區分開。對每個不能被區分的樣本進行同樣的思考,這樣就有了能夠將的所有異常樣本區分來的fea
人臉檢測之face_recognition演算法除錯
參考:https://github.com/ageitgey/face_recognition 公司專案需求,要出一個人臉檢測與識別的demo,檢視網上比較成熟的是face_recognition方案,因此在電腦上按照推薦步驟進行除錯。face_recognition使用dlib最先進的面部
軌跡資料之資料清洗以及異常檢測
軌跡資料之資料清洗以及異常檢測 空間軌跡是一個(x,y)點的序列,每個點都有一個時間戳.因為軌跡通常是由感測器測量的,所以它們不可避免地會出現一些錯誤,需要對資料進行平滑化處理。 此外,司機繞路或者交通事故也會導致軌跡資料出現偏離,這時候我們需要對軌跡資料進行異常檢測。 資料平滑化處理
基於語義分割和生成對抗網路的缺陷檢測演算法
一、缺陷型別 如下圖所示,缺陷型別主要有缺損和裂紋兩個型別。 二、語義分割網路 FCN網路 網上介紹FCN的教程很多,在這裡不再詳細講述,具體請參考連結: https://www.cnblogs.com/gujianhan/p/6030639.html https://
SLS機器學習介紹(03):時序異常檢測建模
文章系列連結 SLS機器學習介紹(01):時序統計建模 SLS機器學習介紹(02):時序聚類建模 SLS機器學習介紹(03):時序異常檢測建模 SLS機器學習介紹(04):規則模式挖掘 SLS機器學習最佳實戰:時序異常檢測和報警 摘要與背景 雖然計算機軟硬體的快速發展已
對基於深度神經網路的Auto Encoder用於異常檢測的一些思考
一、前言 現實中,大部分資料都是無標籤的,人和動物多數情況下都是通過無監督學習獲取概念,故而無監督學習擁有廣闊的業務場景。舉幾個場景:網路流量是正常流量還是攻擊流量、視訊中的人的行為是否正常、運維中伺服器狀態是否異常等等。有監督學習的做法是給樣本標出label,那麼標
[吳恩達機器學習筆記]15.1-3非監督學習異常檢測演算法/高斯回回歸模型
15.異常檢測 Anomaly detection 覺得有用的話,歡迎一起討論相互學習~Follow Me 15.1問題動機 Problem motivation 飛機引擎異常檢測
CSP之高速公路(Kosaraju演算法,正反向DFS,強連通子圖分解演算法,第二次做)
問題描述 試題編號: 201509-4 試題名稱: 高速公路 時間限制: 1.0s 記憶體限制: 256.0MB 問題描述: 問題描述 某國有n個城市,為了使得城市間的交通更便利,該國國王打算在城市之間修一些
異常測試之Socket網路異常
本文由作者張雨授權網易雲社群釋出。 前言 不知道大家在測試的過程中有沒有發現關於異常測試這樣一個特點: 無論是分散在功能測試中的異常用例還是規模相對較大的專項異常測試中,異常測試的用例佔比雖然不大但是對於挖掘問題卻扮演著十分重要的角色。 隨著專案組微服務化的演變程序,服務間通過http介面訪問的場景也越來
計算機網路之慢開始演算法和擁塞演算法
慢開始演算法 顧名思義,慢開始演算法在開始時不要傳送大量資料,從小到大增加擁塞視窗的大小。 在開始時,將傳送視窗以及擁塞視窗初始值設為1,等接收方確認資料之後,擁塞視窗 成倍增加,傳送視窗也成倍增加.直到視窗大小等於滿開始門限
目標檢測之網路篇(2)【STN-空間變換網路】
1. STN是什麼 STN:Spatial Transformer Networks,即空間變換網路,是Google旗下 DeepMind 公司的研究成果。該論文提出空間變換網路STN,分為引數預測、座標對映、畫素採集三大部分,可以插入到現有的CNN模型中。通
目標檢測之模型篇(1)【CTPN連線文字提議網路】
1. 前言 本週開始看模型篇,本週目標:CTPN,RRPN,DMPNet,EAST,衝鴨!! 第一篇,CTPN(Connectionist Text Proposal Network),其實是基於Faster R-CNN改進的,將RPN的體系結構擴充套件到文字
目標檢測之網路篇(3)【Faster R-CNN】
前言 1.有關VGG16結構,參見:VGG16圖形化描述 2.本週目標是看三篇網路類,讀到第三篇Faster R-CNN的時候我發現需要先弄懂R-CNN以及Fast R-CNN。引用@v_JULY_v的文章的總結: R-CNN 1.在影象中確定約1000-200
邊緣檢測之Canny演算法_Qt實現(C++)
邊緣檢測之Canny演算法_Qt實現(C++) Canny邊緣檢測演算法的簡單介紹 Canny的目標是找到一個最優的邊緣檢測演算法,最優邊緣檢測的含義是: 好的檢測 - 演算法能夠儘可能多地標識出影象中的實際邊緣。 好的定位 - 標識出的