
解Bug之路-NAT引發的效能瓶頸
阿新 • • 發佈:2020-11-11
# 解Bug之路-NAT引發的效能瓶頸
筆者最近解決了一個非常曲折的問題,從抓包開始一路排查到不同核心版本間的細微差異,最後才完美解釋了所有的現象。在這裡將整個過程寫成博文記錄下來,希望能夠對讀者有所幫助。(篇幅可能會有點長,耐心看完,絕對物有所值~)
## 環境介紹
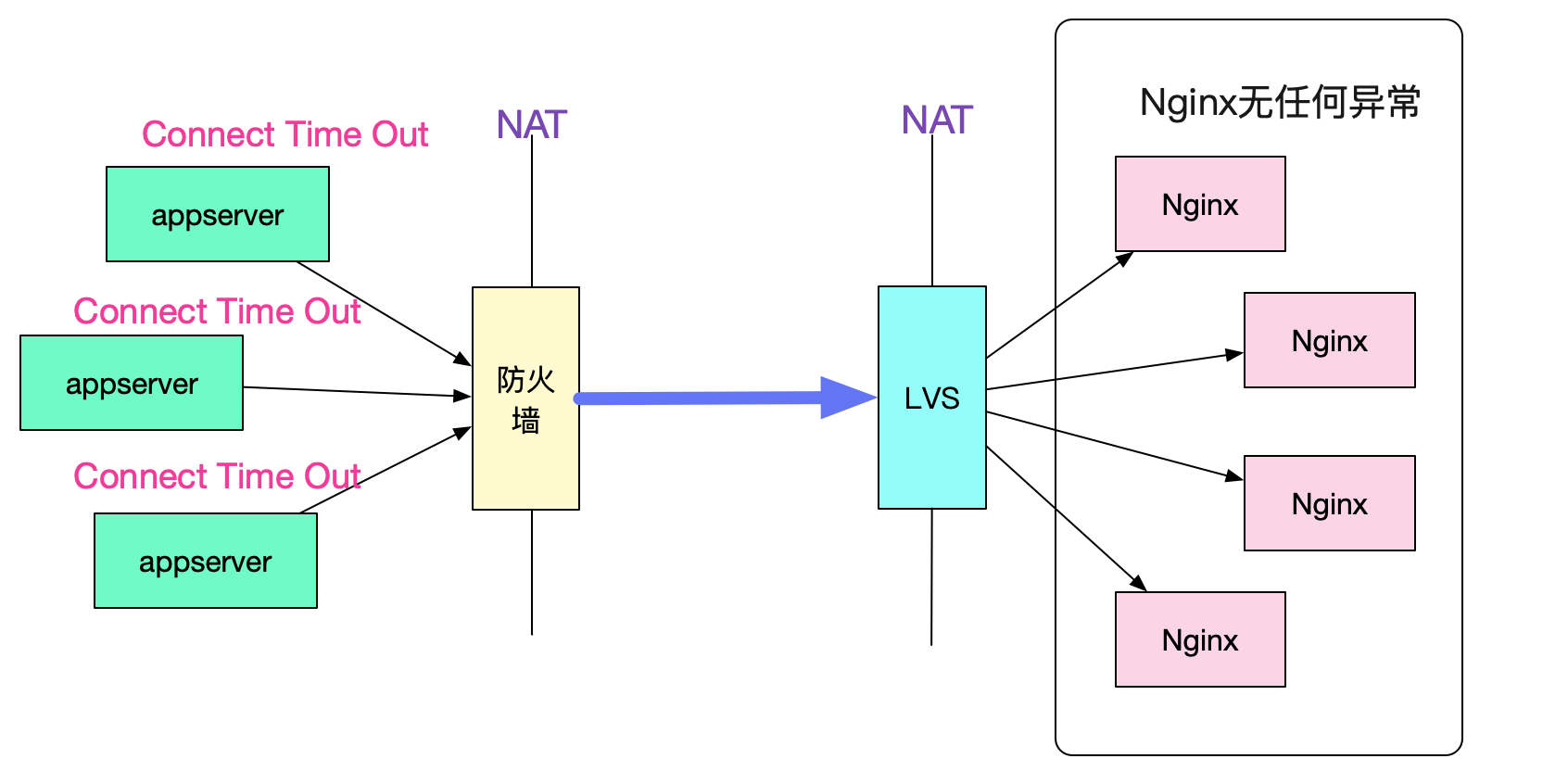
先來介紹一下出問題的環境吧,呼叫拓撲如下圖所示:
### 呼叫拓撲圖
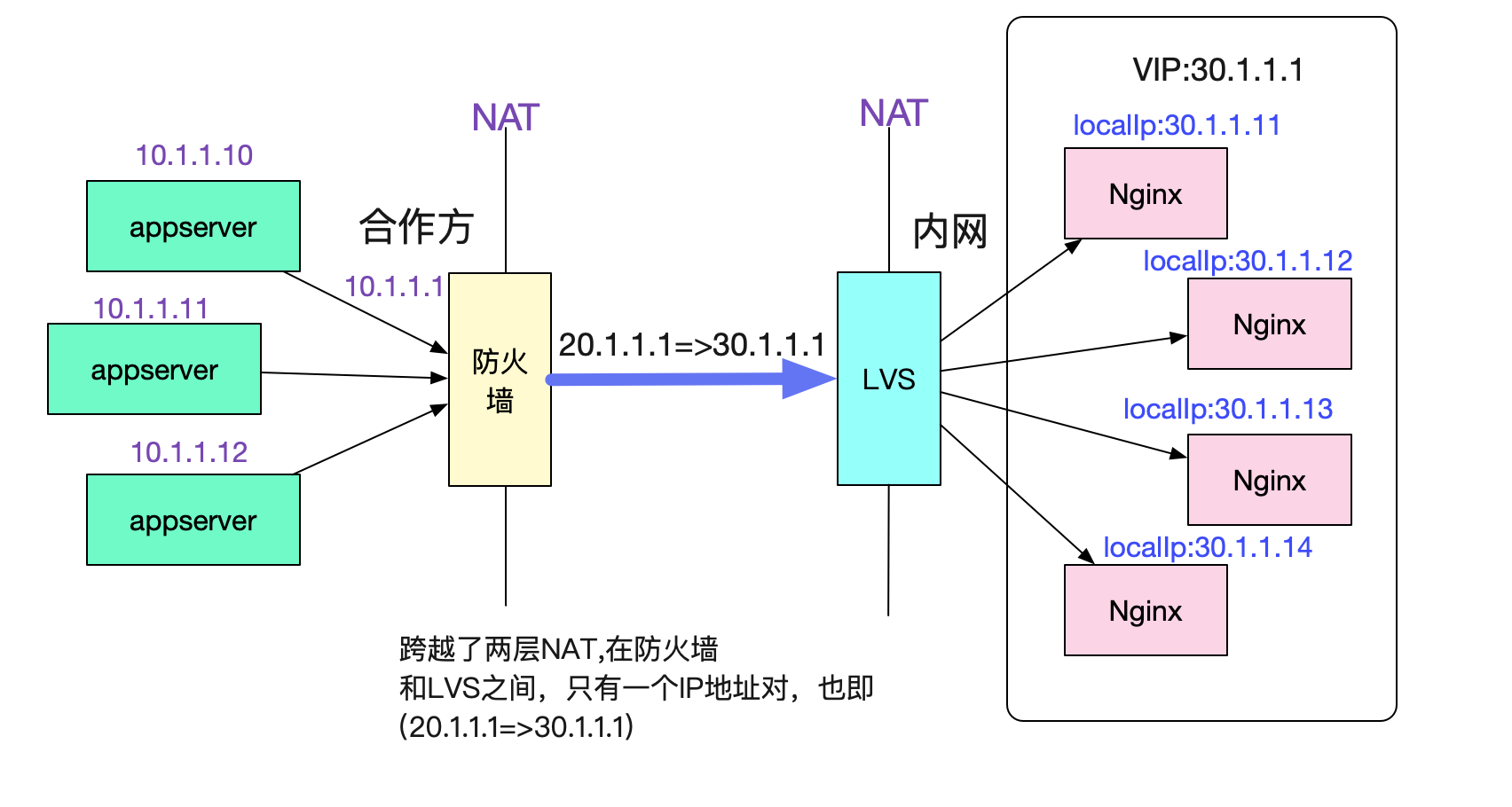
合作方的多臺機器用NAT將多個源ip對映成同一個出口ip 20.1.1.1,而我們內網將多個Nginx對映成同一個目的ip 30.1.1.1。這樣,在防火牆和LVS之間,所有的請求始終是通過(20.1.1.1,30.1.1.1)這樣一個ip地址對進行訪問。
同時還固定了一個引數,那就是目的埠號始終是443。
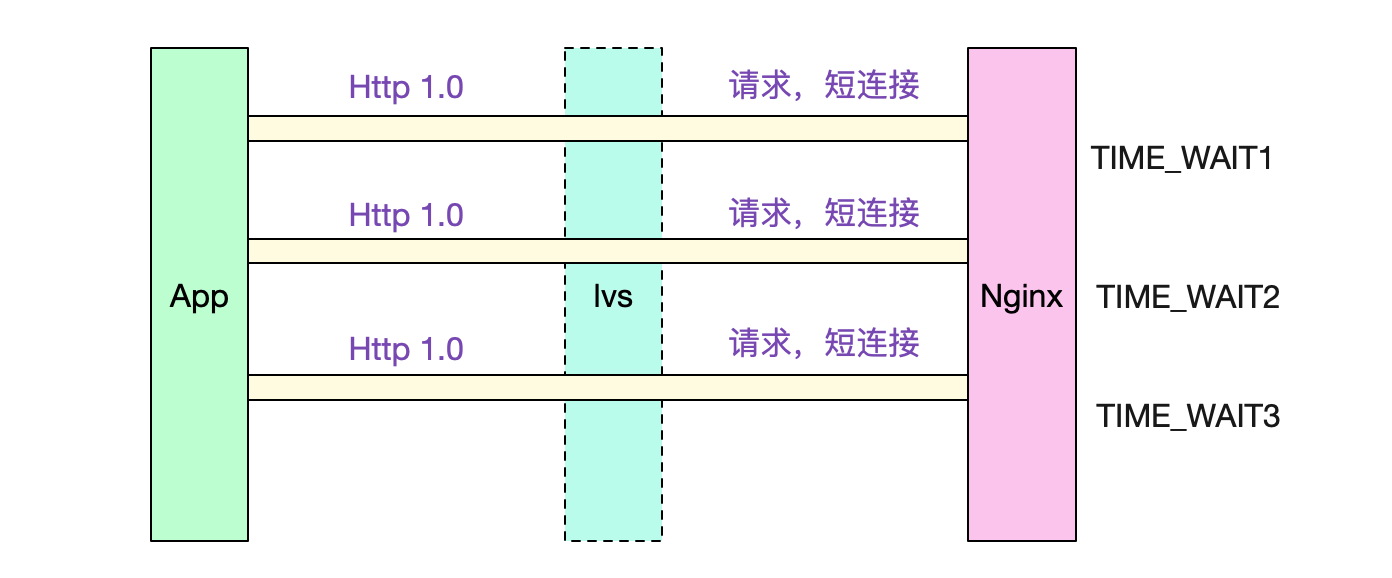
### 短連線-HTTP1.0
由於對方是採用短連線和Nginx進行互動的,而且採用的協議是HTTP-1.0。所以我們的Nginx在每個請求完成後,會主動關閉連線,從而造成有大量的TIME\_WAIT。
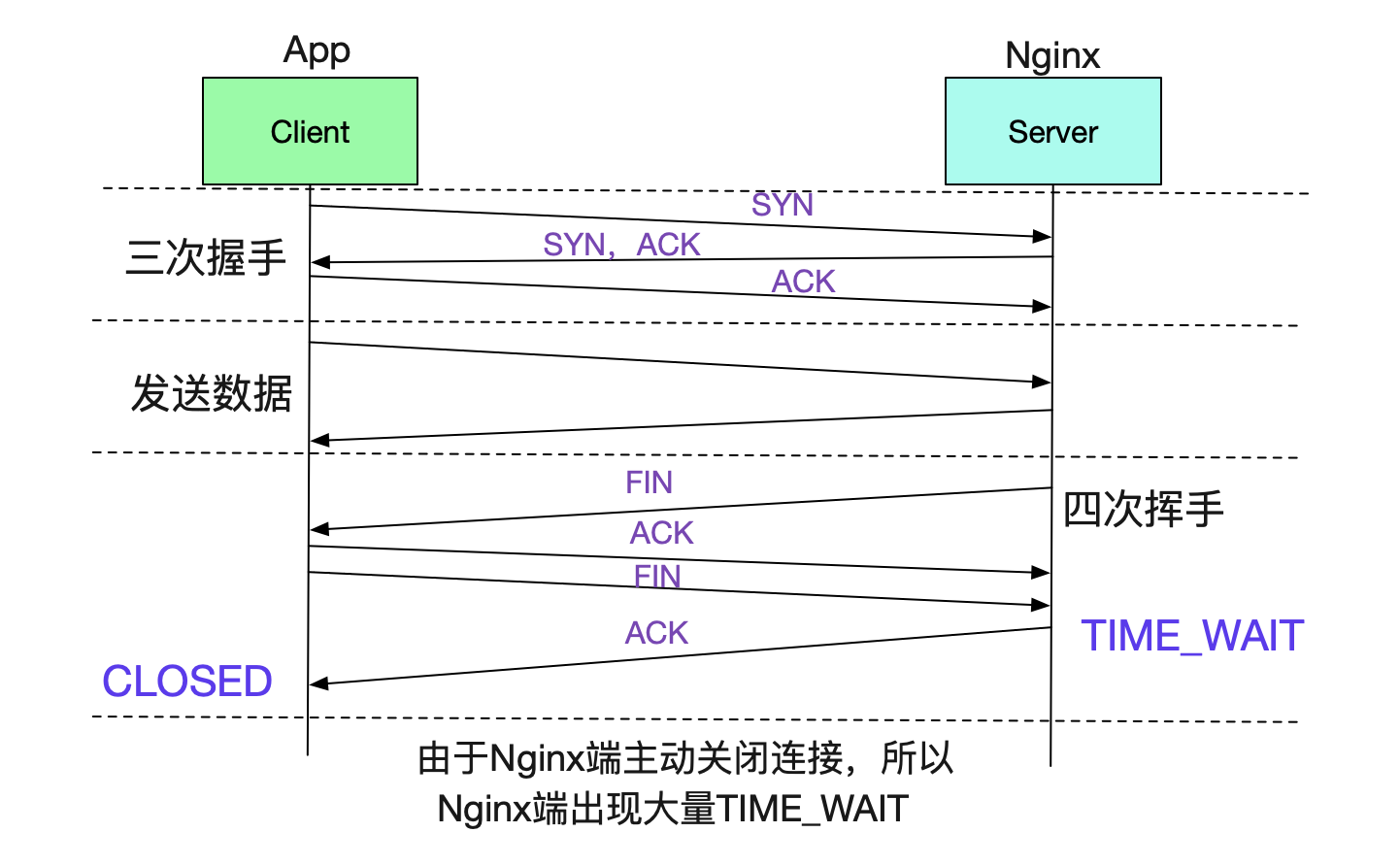
值得注意的是,TIME\_WAIT取決於Server端和Client端誰先關閉這個Socket。所以Nginx作為Server端先關閉的話,也必然會產生TIME\_WAIT。
### 核心引數配置
核心引數配置如下所示:
```
cat /proc/sys/net/ipv4/tcp_tw_reuse 0
cat /proc/sys/net/ipv4/tcp_tw_recycle 0
cat /proc/sys/net/ipv4/tcp_timestamps 1
```
其中tcp\_tw\_recycle設定為0。這樣,可以有效解決tcp\_timestamps和tcp\_tw\_recycle在NAT情況下導致的連線失敗問題。具體見筆者之前的部落格:
```
https://www.cnblogs.com/alchemystar/p/13444964.html
```
## Bug現場
好了,介紹完環境,我們就可以正式描述Bug現場了。
### Client端大量建立連線異常,而Server端無法感知
表象是合作方的應用出現大量的建立連線異常,而Server端確沒有任何關於這些異常的任何異常日誌,彷彿就從來沒有出現過這些請求一樣。
### LVS監控曲線
出現問題後,筆者翻了下LVS對應的監控曲線,其中有個曲線的變現非常的詭異。如下圖所示:
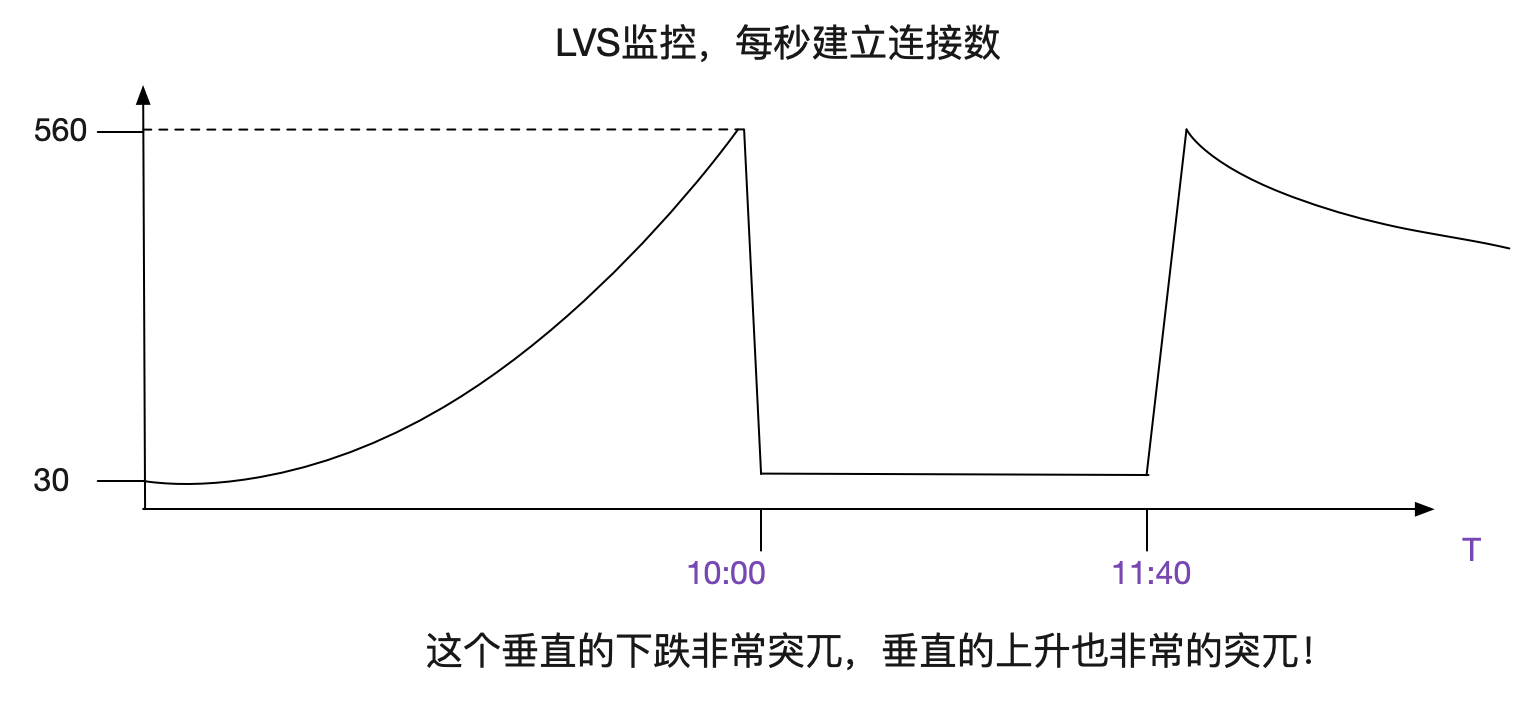
什麼情況?看上去像建立不了連線了?但是雖然業務有大量的報錯,依舊有很高的訪問量,看日誌的話,每秒請求應該在550向上!和這個曲線上面每秒只有30個新建連線是矛盾的!
### 每天發生的時間點非常接近
觀察了幾天後。發現,每天都在10點左右開始發生報錯,同時在12點左右就慢慢恢復。
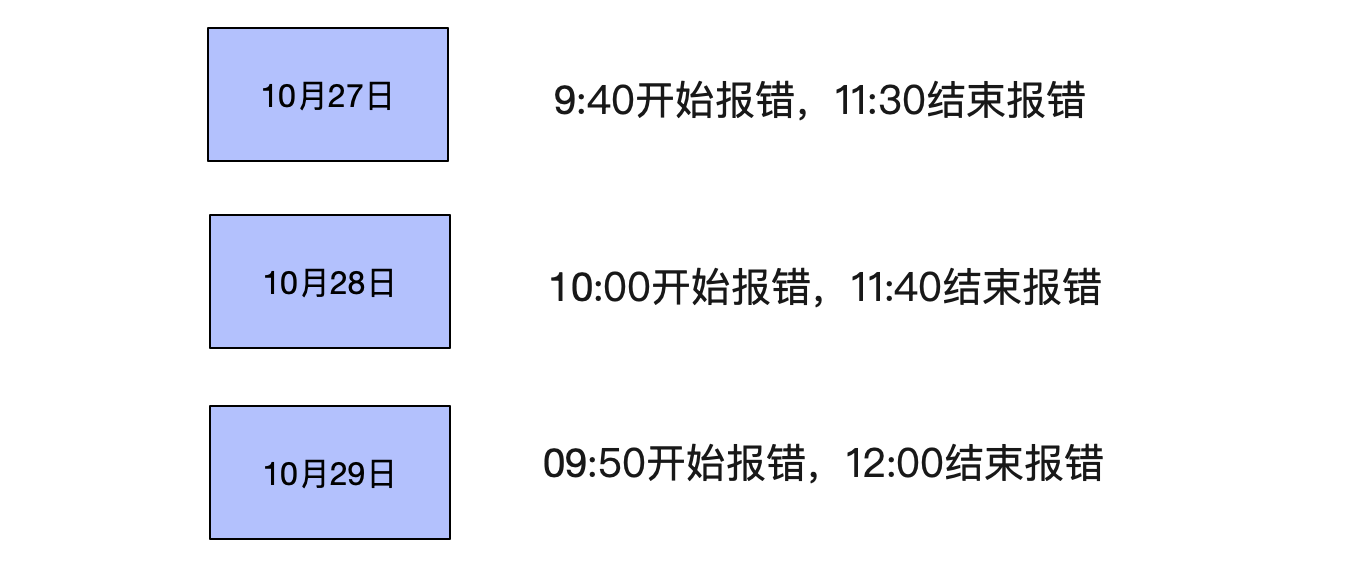
感覺就像每天10點在做活動,導致流量超過了系統瓶頸,進而暴露出問題。而11:40之後,流量慢慢下降,系統才慢慢恢復。難道LVS這點量都撐不住?才550TPS啊?就崩潰了?
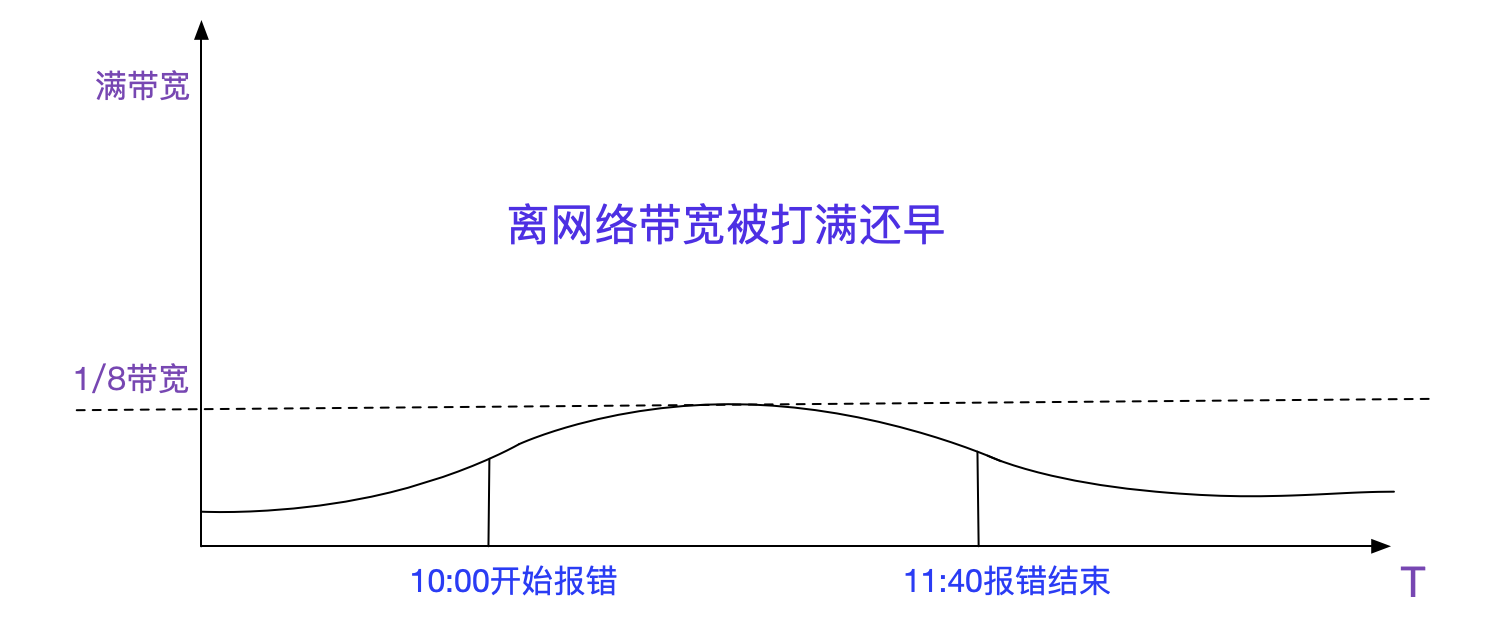
### 難道是網路問題?
難道就是傳說中的網路問題?看了下監控,流量確實增加,不過只佔了將近1/8的頻寬,離打爆網路還遠著呢。
## 進行抓包
不管三七二十一,先抓包吧!
### 抓包結果
在這裡筆者給出一個典型的抓包結果:
|序號|時間|源地址|目的地址|源埠號|目的埠號|資訊|
|:---|:---|:--- |:---|:---|:---|:---|
|1|09:57:30.60|30.1.1.1|20.1.1.1|443|33735|[FIN,ACK]Seq=507,Ack=2195,TSval=1164446830|
|2|09:57:30.64|20.1.1.1|30.1.1.1|33735|443|[FIN,ACK]Seq=2195,Ack=508,TSval=2149756058|
|3|09:57:30.64|30.1.1.1|20.1.1.1|443|33735|[ACK]Seq=508,Ack=2196,TSval=1164446863|
|4|09:59:22.06|20.1.1.1|30.1.1.1|33735|443|[SYN]Seq=0,TSVal=21495149222|
|5|09:59:22.06|30.1.1.1|20.1.1.1|443|33735|[ACK]Seq=1,Ack=1487349876,TSval=1164558280|
|6|09:59:22.08|20.1.1.1|30.1.1.1|33735|443|[RST]Seq=1487349876|
上面抓包結果如下圖所示,一開始33735->443這個Socket四次揮手。在將近兩分鐘後又使用了同一個33735埠和443建立連線,443給33735回了一個莫名其妙的Ack,導致33735發了RST!
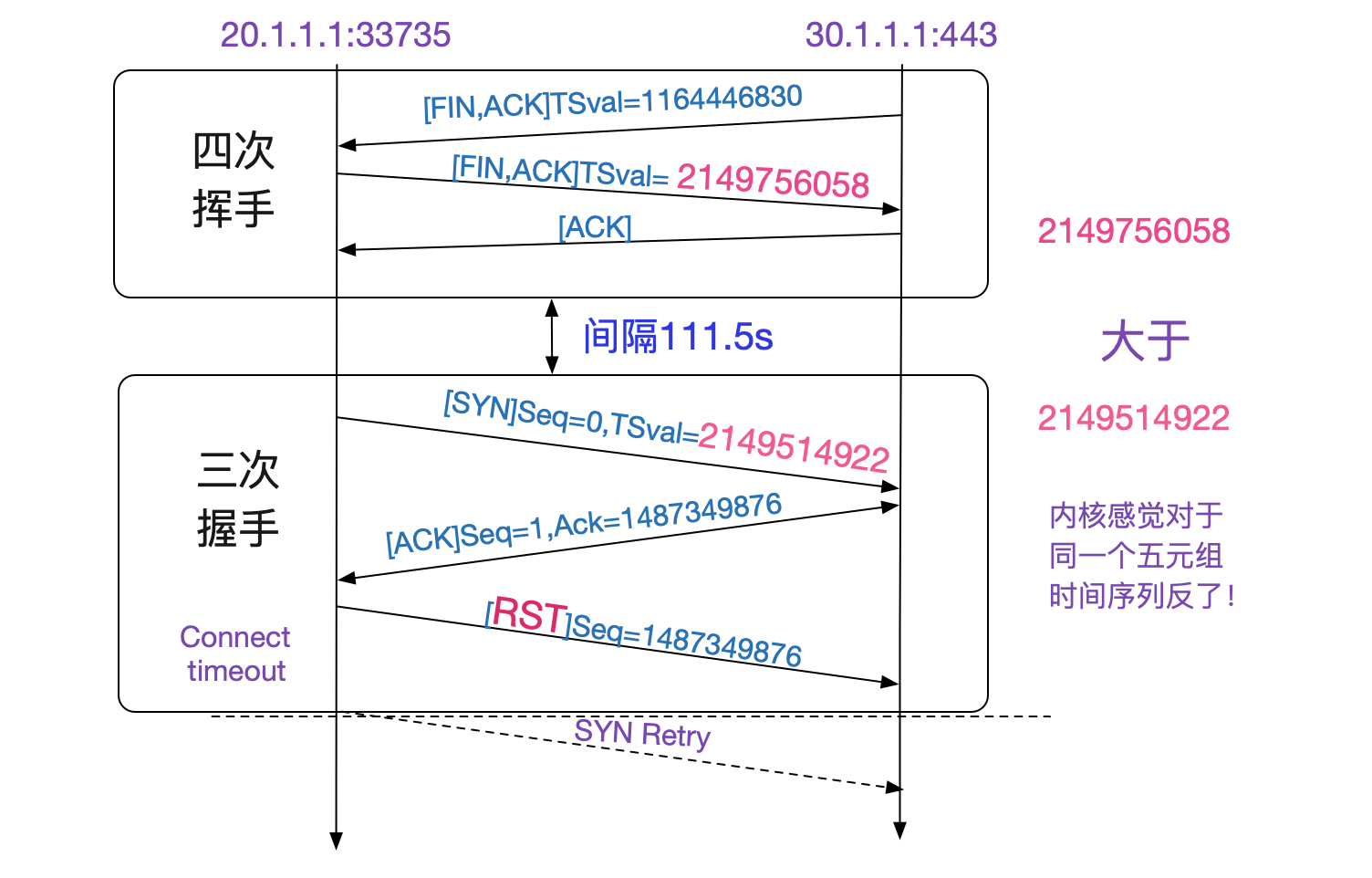
### 現象是怎麼產生的?
首先最可疑的是為什麼傳送了一個莫名其妙的Ack回來?筆者想到,這個Ack是WireShark給我計算出來的。為了我們方便,WireShark會根據Seq=0而調整Ack的值。事實上,真正的Seq是個隨機數!有沒有可能是WireShark在某些情況下計算錯誤?
還是看看最原始的未經過加工的資料吧,於是筆者將wireshark的
```
Relative sequence numbers
```
給取消了。取消後的抓包結果立馬就有意思了!調整過後抓包結果如下所示:
|序號|時間|源地址|目的地址|源埠號|目的埠號|資訊|
|:---|:---|:--- |:---|:---|:---|:---|
|1|09:57:30.60|30.1.1.1|20.1.1.1|443|33735|[FIN,ACK]Seq=909296387,Ack=1556577962,TSval=1164446830|
|2|09:57:30.64|20.1.1.1|30.1.1.1|33735|443|[FIN,ACK]Seq=1556577962,Ack=909296388,TSval=2149756058|
|3|09:57:30.64|30.1.1.1|20.1.1.1|443|33735|[ACK]Seq=909296388,Ack=1556577963,TSval=1164446863|
|4|09:59:22.06|20.1.1.1|30.1.1.1|33735|443|[SYN]Seq=69228087,TSVal=21495149222|
|5|09:59:22.06|30.1.1.1|20.1.1.1|443|33735|[ACK]Seq=909296388,Ack=1556577963,TSval=1164558280|
|6|09:59:22.08|20.1.1.1|30.1.1.1|33735|443|[RST]Seq=1556577963|
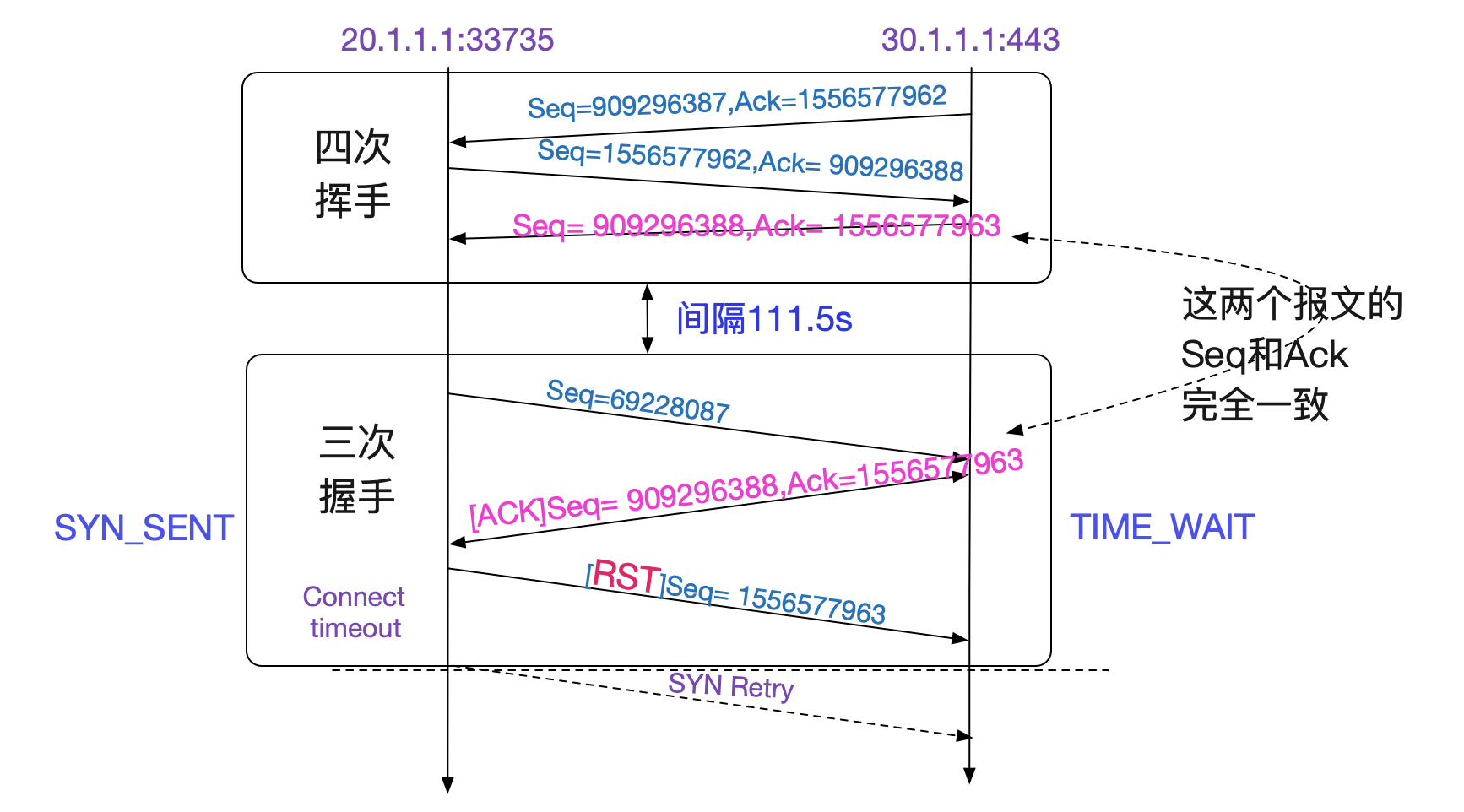
看錶中,四次揮手裡面的Seq和Ack對應的值和三次回收中那個錯誤的ACK完全一致!也就是說,四次回收後,五元組並沒有消失,而是在111.5s內還存活著!按照TCPIP狀態轉移圖,只有TIME\_WAIT狀態才會如此。
我們可以看看Linux關於TIME\_WAIT處理的核心原始碼:
```
switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) {
// 如果是TCP_TW_SYN,那麼允許此SYN分節重建連線
// 即允許TIM_WAIT狀態躍遷到SYN_RECV
case TCP_TW_SYN: {
struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev),
&tcp_hashinfo,
iph->saddr, th->source,
iph->daddr, th->dest,
inet_iif(skb));
if (sk2) {
inet_twsk_deschedule(inet_twsk(sk), &tcp_death_row);
inet_twsk_put(inet_twsk(sk));
sk = sk2;
goto process;
}
/* Fall through to ACK */
}
// 如果是TCP_TW_ACK,那麼,返回記憶中的ACK,這和我們的現象一致
case TCP_TW_ACK:
tcp_v4_timewait_ack(sk, skb);
break;
// 如果是TCP_TW_RST直接傳送RESET包
case TCP_TW_RST:
tcp_v4_send_reset(sk, skb);
inet_twsk_deschedule(inet_twsk(sk), &tcp_death_row);
inet_twsk_put(inet_twsk(sk));
goto discard_it;
// 如果是TCP_TW_SUCCESS則直接丟棄此包,不做任何響應
case TCP_TW_SUCCESS:;
}
goto discard_it;
```
上面的程式碼有兩個分支,值得我們注意,一個是TCP\_TW\_ACK,在這個分支下,返回TIME\_WAIT記憶中的ACK和我們的抓包現象一模一樣。還有一個TCP\_TW\_SYN,它表明了在
TIME\_WAIT狀態下,可以立馬重用此五元組,跳過2MSL而達到SYN_RECV狀態!
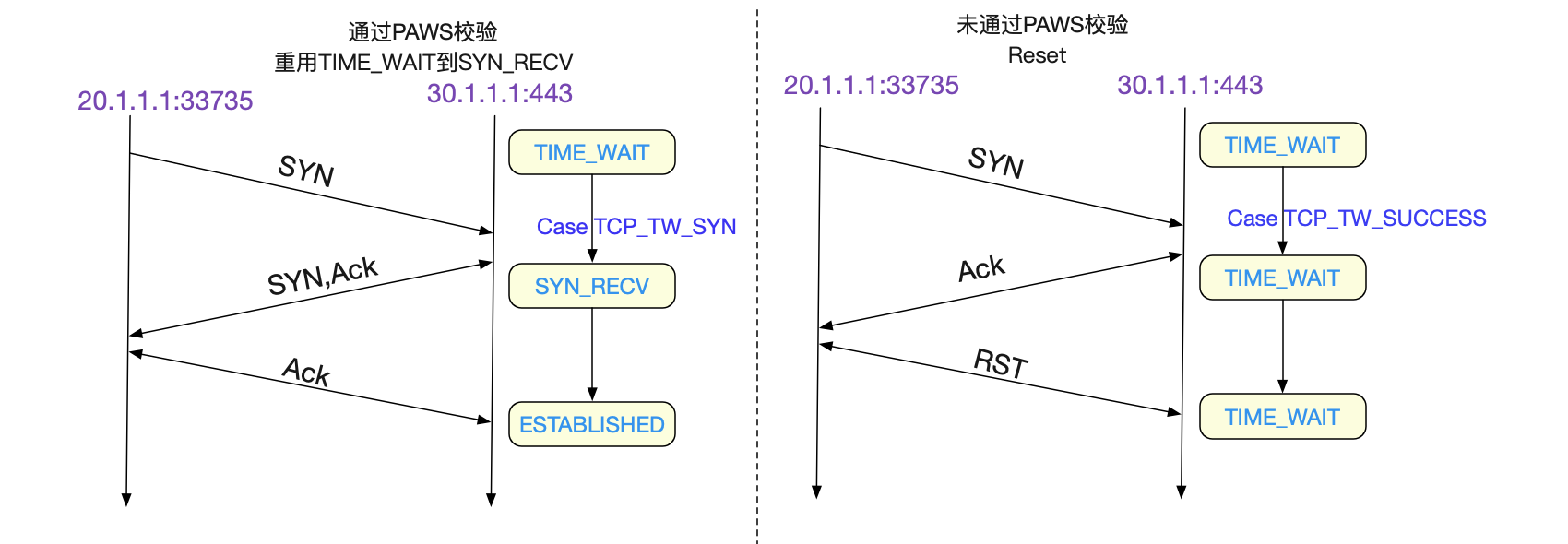
狀態的遷移就在於tcp\_timewait\_state\_process這個函式,我們著重看下想要觀察的分支:
```
enum tcp_tw_status
tcp_timewait_state_process(struct inet_timewait_sock *tw, struct sk_buff *skb,
const struct tcphdr *th)
{
bool paws_reject = false;
......
paws_reject = tcp_paws_reject(&tmp_opt, th->rst);
if (!paws_reject &&
(TCP_SKB_CB(skb)->seq == tcptw->tw_rcv_nxt &&
(TCP_SKB_CB(skb)->seq == TCP_SKB_CB(skb)->end_seq || th->rst))) {
......
// 重複的ACK,discard此包
return TCP_TW_SUCCESS;
}
// 如果是SYN分節,而且通過了paws校驗
if (th->syn && !th->rst && !th->ack && !paws_reject &&
(after(TCP_SKB_CB(skb)->seq, tcptw->tw_rcv_nxt) ||
(tmp_opt.saw_tstamp &&
(s32)(tcptw->tw_ts_recent - tmp_opt.rcv_tsval) < 0))) {
......
// 返回TCP_TW_SYN,允許重用TIME_WAIT五元組重新建立連線
return TCP_TW_SYN;
}
// 如果沒有通過paws校驗,則增加統計引數
if (paws_reject)
NET_INC_STATS_BH(twsk_net(tw), LINUX_MIB_PAWSESTABREJECTED);
if (!th->rst) {
// 如果沒有通過paws校驗,而且這個分節包含ack,則將TIMEWAIT持續時間重新延長
// 我們抓包結果的結果沒有ACK,只有SYN,所以並不會延長
if (paws_reject || th->ack)
inet_twsk_schedule(tw, &tcp_death_row, TCP_TIMEWAIT_LEN,
TCP_TIMEWAIT_LEN);
// 返回TCP_TW_ACK,也即TCP重傳ACK到對面
return TCP_TW_ACK;
}
}
```
根據上面原始碼,PAWS(Protect Againest Wrapped Sequence numbers防止迴繞)校驗機制如果生效而拒絕此分節的話,LINUX\_MIB\_PAWSESTABREJECTED這個統計引數會增加,對應於Linux中的命令即是:
```
netstat -s | grep reject
216576 packets rejects in established connections because of timestamp
```
這麼上去後端的Nginx一統計,果然有大量的報錯。而且根據筆者的觀察,這個統計引數急速增加的時間段就是出問題的時間段,也就是每天早上10:00-12:00左右。每次大概會增加1W多個統計引數。
那麼什麼時候PAWS會不通過呢,我們直接看下tcp\_paws\_reject的原始碼吧:
```
static inline int tcp_paws_reject(const struct tcp_options_received *rx_opt,
int rst)
{
if (tcp_paws_check(rx_opt, 0))
return 0;
// 如果是rst,則放鬆要求,60s沒有收到對端報文,認為PAWS檢測通過
if (rst && get_seconds() >= rx_opt->ts_recent_stamp + TCP_PAWS_MSL)
return 0;
return 1;
}
static inline int tcp_paws_check(const struct tcp_options_received *rx_opt,
int paws_win)
{
// 如果ts_recent中記錄的上次報文(SYN)的時間戳,小於當前報文的時間戳(TSval),表明paws檢測通過
// paws_win = 0
if ((s32)(rx_opt->ts_recent - rx_opt->rcv_tsval) <= paws_win)
return 1;
// 否則,上一次獲得ts_recent時間戳的時刻的24天之後,為真表明已經有超過24天沒有接收到對端的報文了,認為PAWS檢測通過
if (unlikely(get_seconds() >= rx_opt->ts_recent_stamp + TCP_PAWS_24DAYS))
return 1;
return 0;
}
```
在抓包的過程中,我們明顯發現,在四次揮手時候,記錄的tsval是2149756058,而下一次syn三次握手的時候是21495149222,反而比之前的小了!
|序號|時間|源地址|目的地址|源埠號|目的埠號|資訊|
|:---|:---|:--- |:---|:---|:---|:---|
|2|09:57:30.64|20.1.1.1|30.1.1.1|33735|443|[FIN,ACK]TSval=2149756058|
|4|09:59:22.06|20.1.1.1|30.1.1.1|33735|443|[SYN]TSVal=21495149222|
所以PAWS校驗不過。
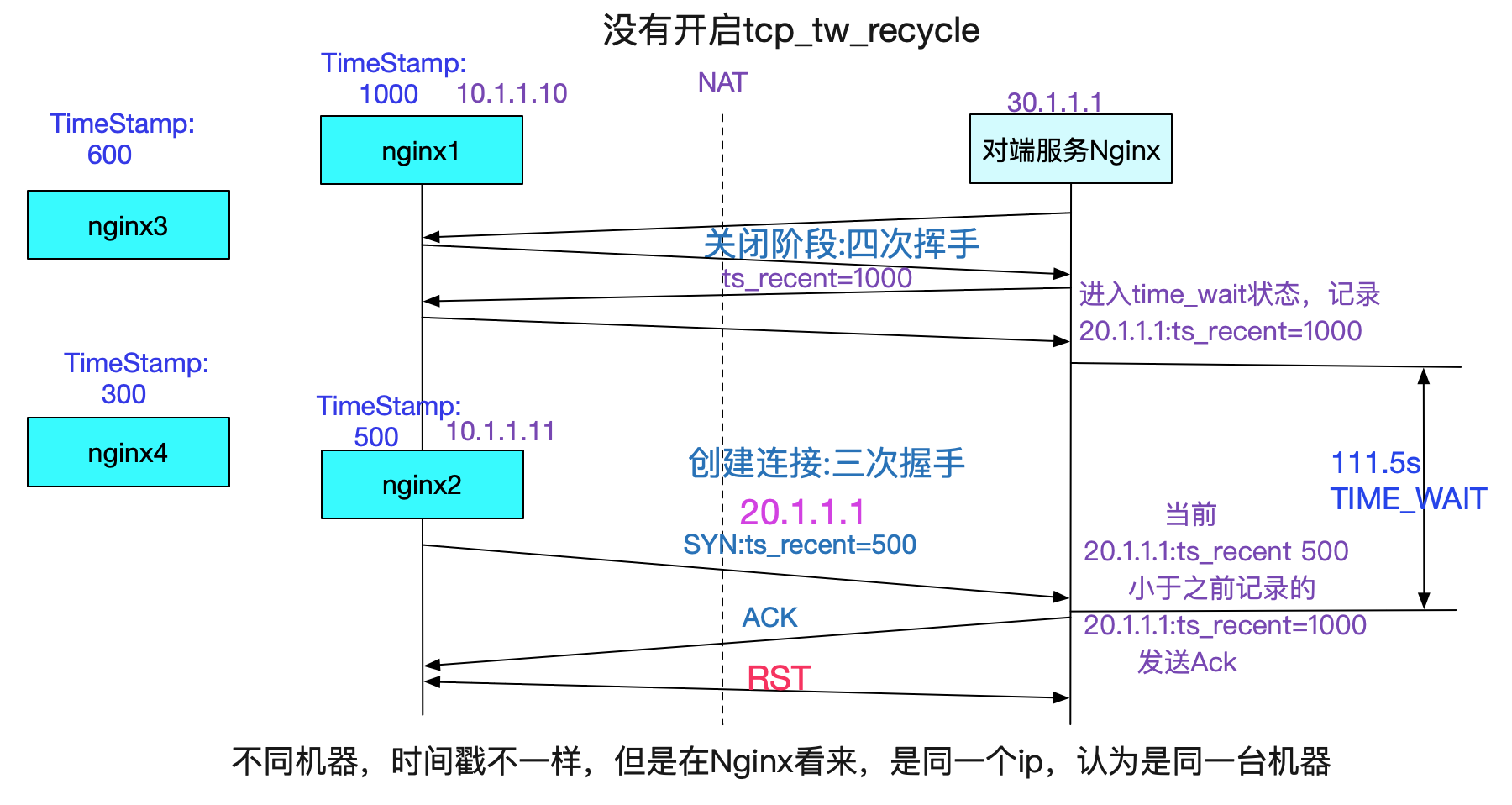
那麼為什麼會這個SYN時間戳比之前揮手的時間戳還小呢?那當然是NAT的鍋嘍,NAT把多臺機器的ip虛擬成同一個ip。但是多臺機器的時間戳(也即從啟動開始到現在的時間,非牆上時間),如下圖所示:
但是還有一個疑問,筆者記得TIME\_WAIT也即2MSL在Linux的程式碼裡面是定義為了60s。為何抓包的結果卻存活了將近2分鐘之久呢?
### TIME_WAIT的持續時間
於是筆者開始閱讀器關於TIME\_WAIT定時器的原始碼,具體可見筆者的另一篇部落格:
```
從Linux原始碼看TIME_WAIT狀態的持續時間
https://www.cnblogs.com/alchemystar/p/13883871.html
```
結論如下
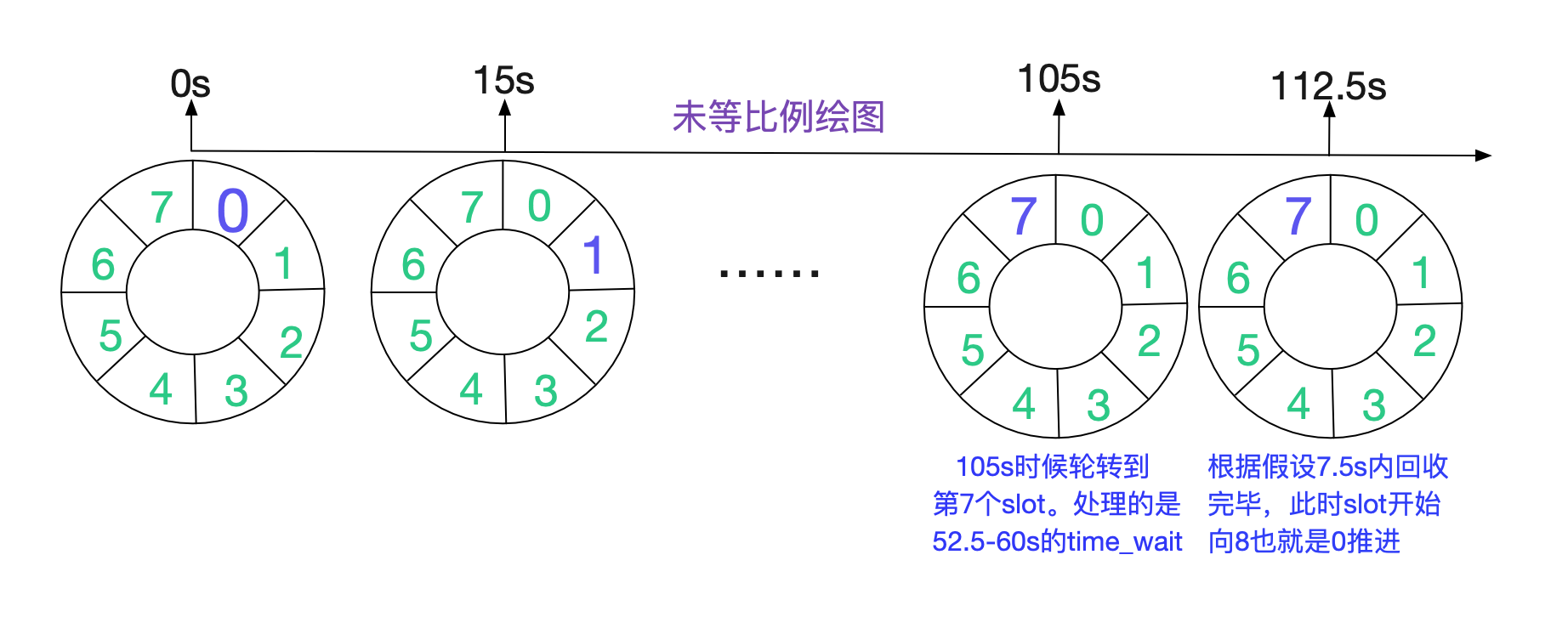
在TIME\_WAIT很多的狀態下,TIME\_WAIT能夠存活112.5s,將近兩分鐘的時間,和我們的抓包結果一致。
當然了,這個計算只是針對Linux 2.6和3.10核心而言,而對紅帽維護的3.10.1127核心版本則會有另外的變化,這個變化導致了一個令筆者感到非常奇異的現象,這個在後面會提到。
### 問題發生條件
如上面所解釋,只有在Server端TIME\_WAIT還沒有消失時候,重用這個Socket的時候,遇上了反序的時間戳SYN,就會發生這種問題。由於NAT前面的所有機器時間戳都不相同,所以有很大概率會導致時間戳反序!
### 那麼什麼時候重用TIME\_WAIT狀態的Socket呢
筆者知道,防火牆的埠號選擇邏輯是RoundRobin的,也即從2048開始一直增長到65535,再回繞到2048,如下圖所示:

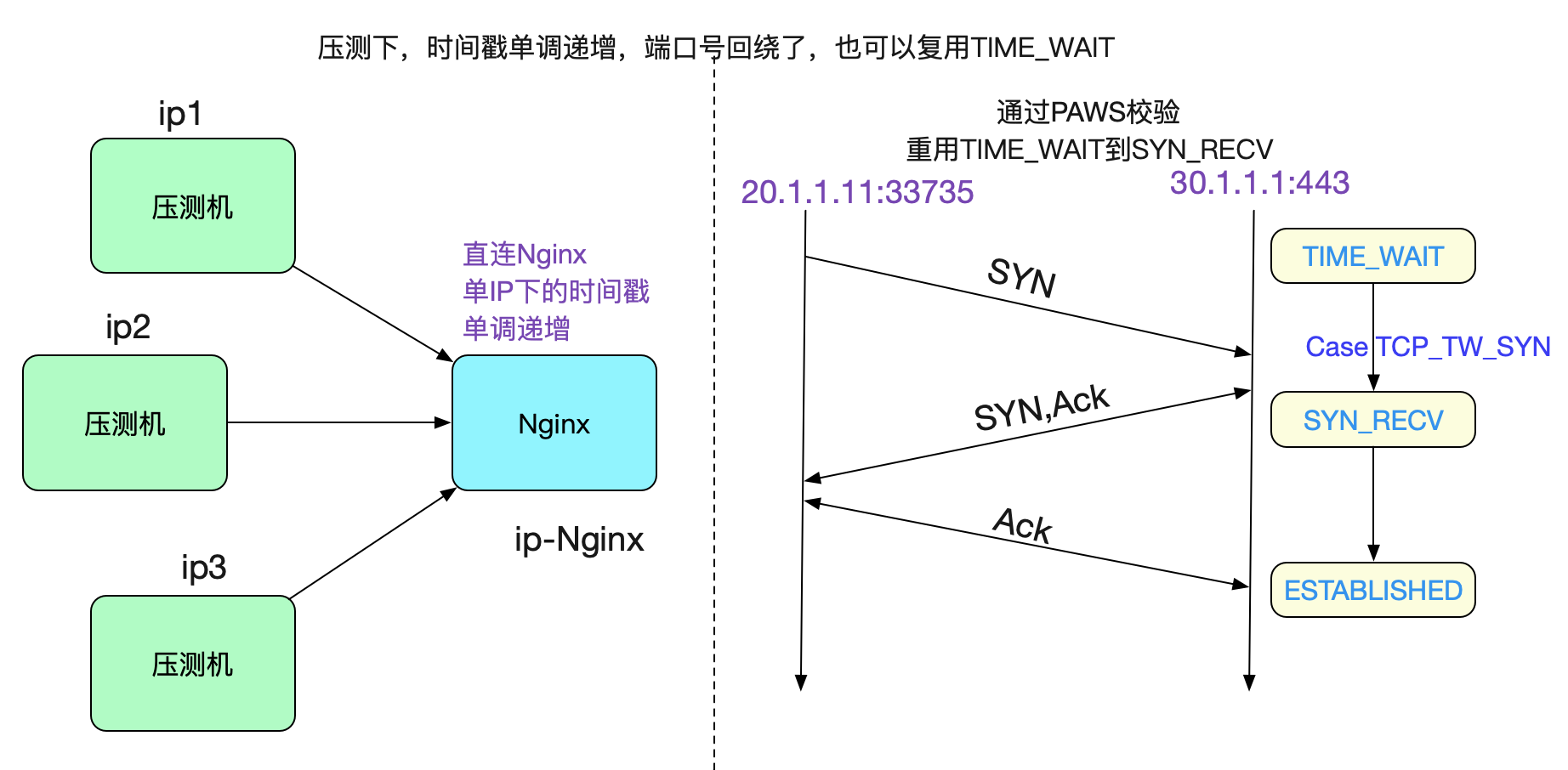
### 為什麼壓測的時候不出現問題
但我們線上下壓測的時候,明顯速率遠超560tps,那為何確沒有這樣的問題出現呢。很簡單,是因為
TCP\_SYN\_SUCCESS這個分支,由於我們的壓測機沒有過NAT,那麼時間戳始終保持單IP下的單調遞增,即便>560TPS之後,走的也是TCP\_SYN\_SUCCESS,將TIME\_WAIT Socket重用為SYN\_RECV,自然不會出現這樣的問題,如下圖所示:
### 如何解釋LVS的監控曲線?
等等,564TPS?這個和LVS陡然下跌的TPS基本相同!難道在埠號複用之後LVS就不會新建連線(其實是LVS中的session表項)?從而導致統計引數並不增加?
於是筆者直接去擼了一下LVS的原始碼:
```
tcp_conn_schedule
|->ip_vs_schedule
/* 如果新建conn表項成功,則對已有連線數++ */
|->ip_vs_conn_stats
而在我們的入口函式ip\_vs\_in中
static unsigned int
ip_vs_in(unsigned int hooknum, struct sk_buff *skb,
const struct net_device *in, const struct net_device *out,
int (*okfn) (struct sk_buff *))
{
......
// 如果能找到對應的五元組
cp = pp->conn_in_get(af, skb, pp, &iph, iph.len, 0, &res_dir);
if (likely(cp)) {
/* For full-nat/local-client packets, it could be a response */
if (res_dir == IP_VS_CIDX_F_IN2OUT) {
return handle_response(af, skb, pp, cp, iph.len);
}
} else {
/* create a new connection */
int v;
// 找不到對應的五元組,則新建連線,同時conn++
if (!pp->conn_schedule(af, skb, pp, &v, &cp))
return v;
}
......
}
```
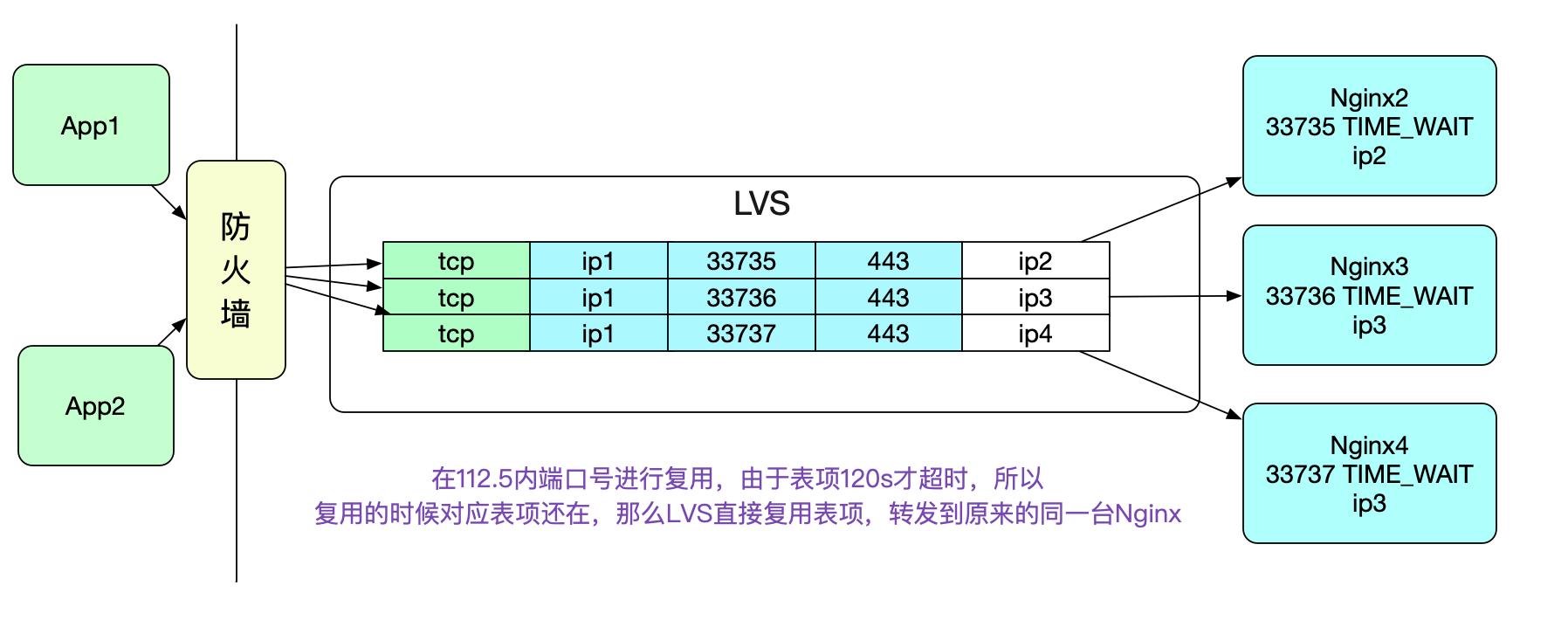
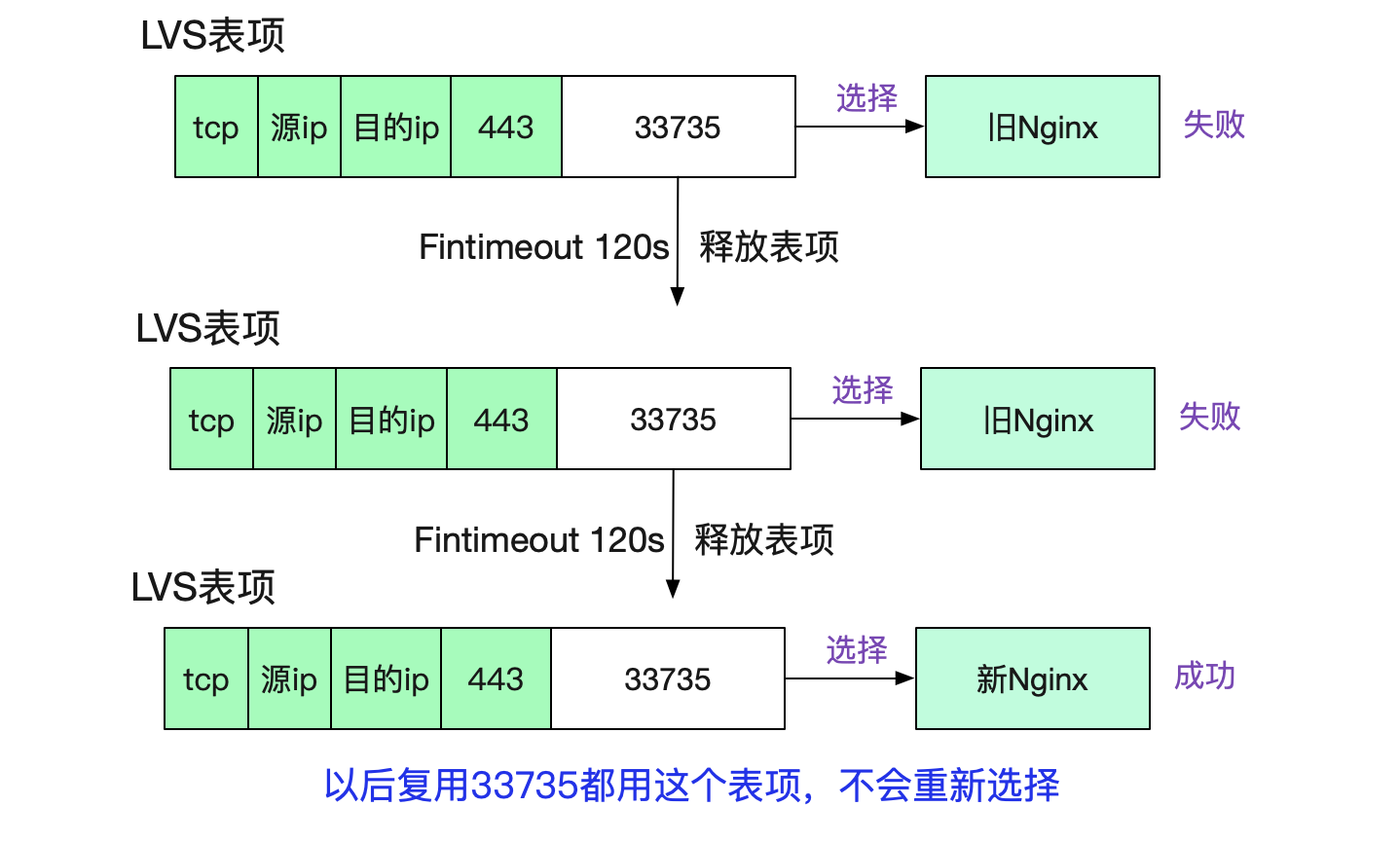
很明顯的,如果當前五元組表項存在,則直接複用表項,而不存在,才建立新的表項,同時conn++。而表項需要在LVS的Fintimeout時間超過後才消失(在筆者的環境裡面是120s)。這樣,在埠號複用的時候,因為<112.5s,所以LVS會直接複用表項,而統計引數不會有任何變化,從而導致了下面這個曲線。
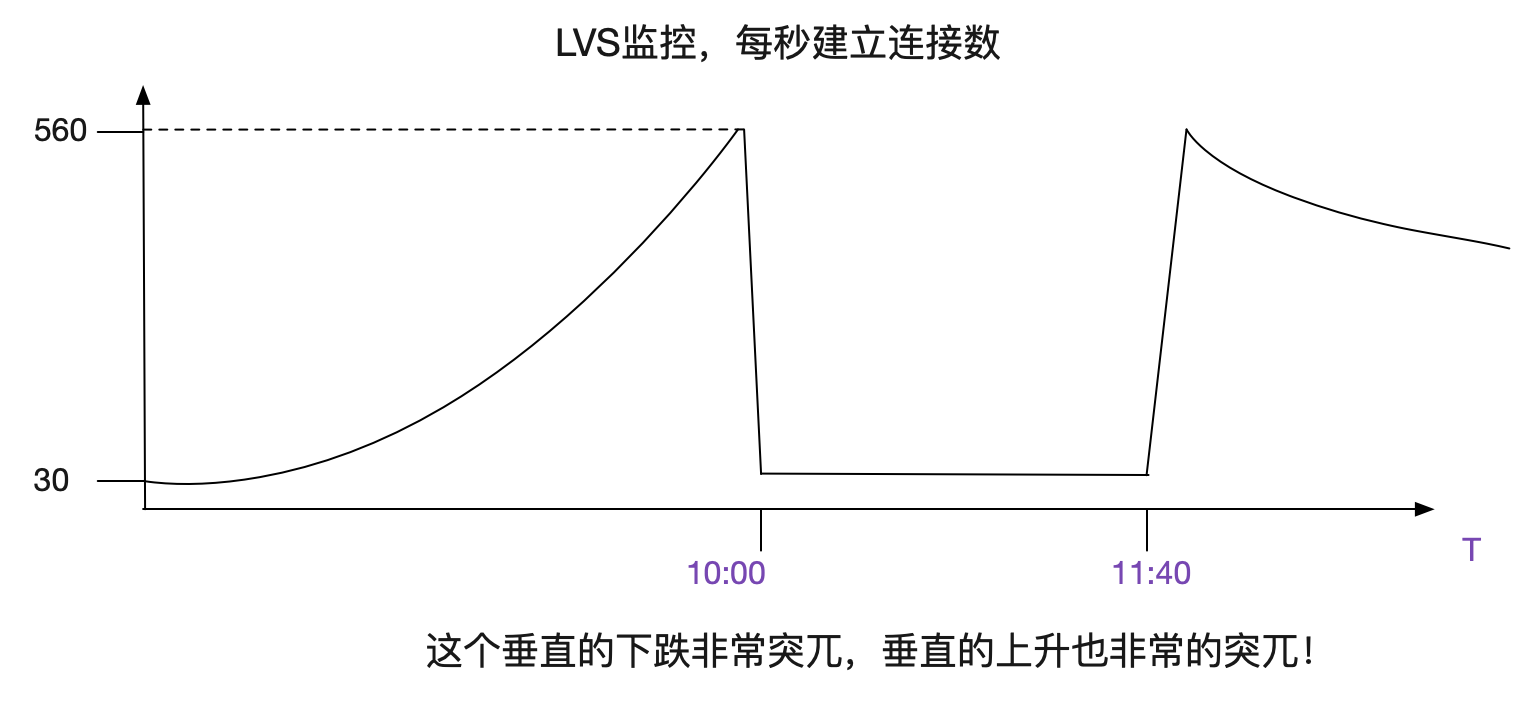
當流量慢慢變小,無法達到重用埠號的條件的時候,曲線又會垂直上升。和筆者的推測一致。也就是說在五元組固定四元的情況下>529tps(63487/120)的時候,在此固定業務下的新建連線數不會增加。
而圖中僅存的560-529=>21+個連線建立,是由另一個業務的vip引起,在這個vip上,由於量很小,沒有埠複用。但是LVS統計的是總數量,所以在埠號開始複用之後,始終會有少量的新建連線存在。
值得注意的是,埠號複用之後,LVS轉發的時候就會直接使用這個對映表項,所以相同的五元組到LVS後會轉發給相同的Nginx,而不會進行WRR(Weight Round Robin)負載均衡,表現出了一定的"親和性"。如下圖所示:
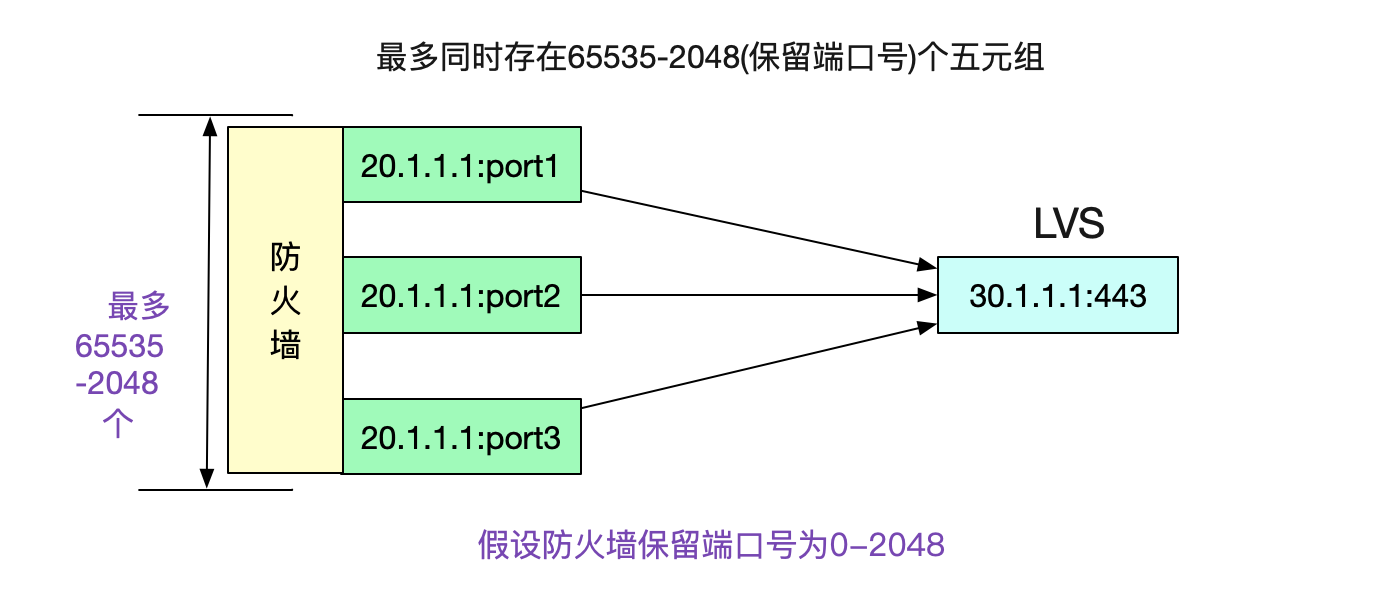
## NAT下固定ip地址對的效能瓶頸
好了,現在可以下結論了。在ip源和目的地址固定,目的埠號也固定的情況下,五元組的可變數只有ip源埠號了。而源埠號最多是65535個,如果計算保留埠號(0-2048)的話(假設防火牆保留2048個),那麼最多可使用63487個埠。
由於每使用一個埠號,在高負載的情況下,都會產生一個112.5s才消失的TIME\_WAIT。那麼在63487/112.5也就是564TPS(使用短連線)的情況下,就會複用TIME\_WAIT下的Socket。再加上PAWS校驗,就會造成大量的連線建立異常!
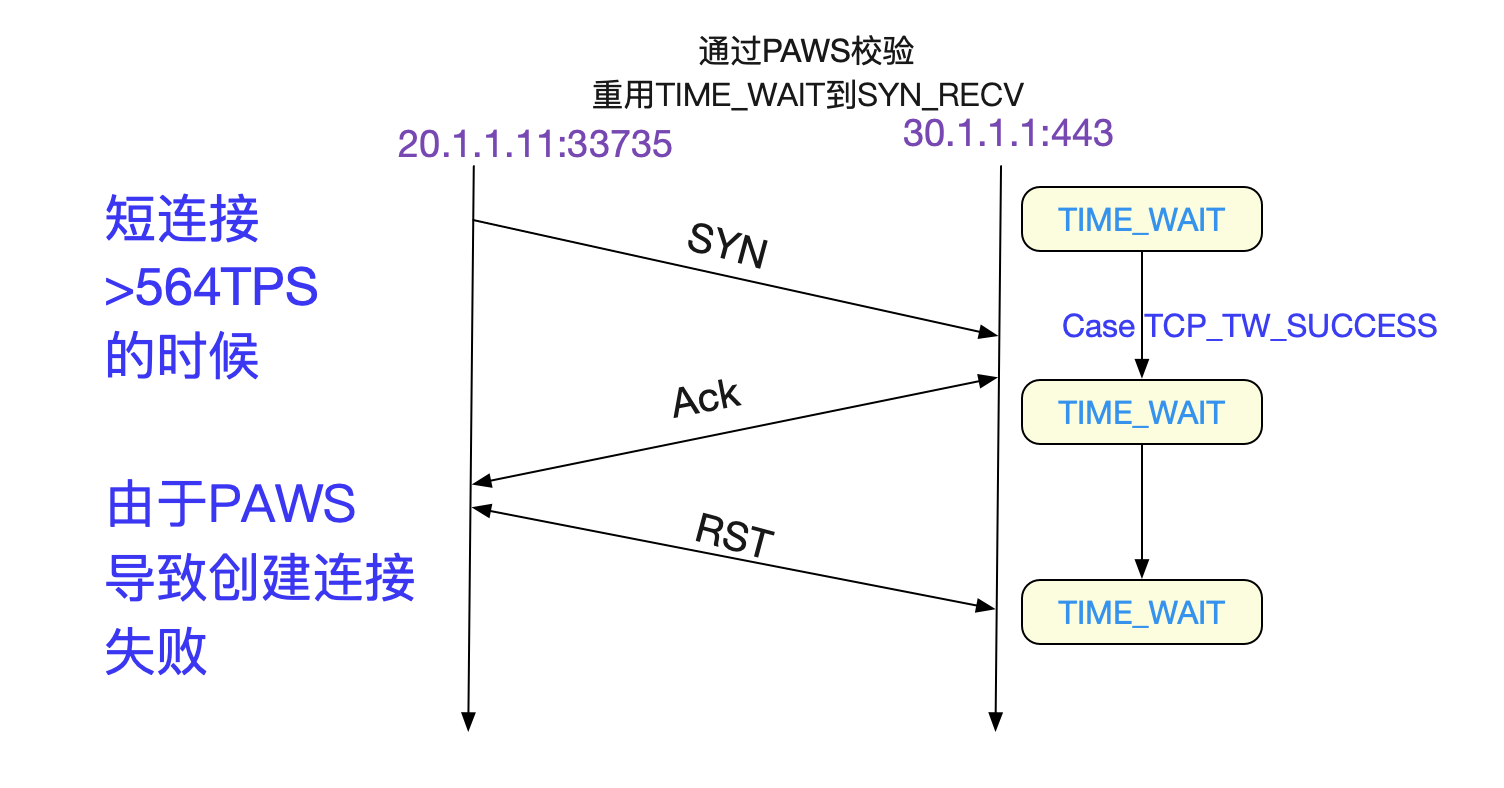
這個論斷和筆者觀察到的應用報錯以及LVS監控曲線一致。
### LVS曲線異常事件和報錯時間接近
因為LVS是在529TPS時候開始垂直下降,而埠號複用是在564TPS的時候開始,兩者所需TPS非常接近,所以一般LVS出現曲線異常的時候,基本就是開始報錯的時候!但是LVS曲線異常只能表明複用表項,並不能表明一定有問題,因為可以通過調節某些核心引數使得在埠號複用的時候不報錯!
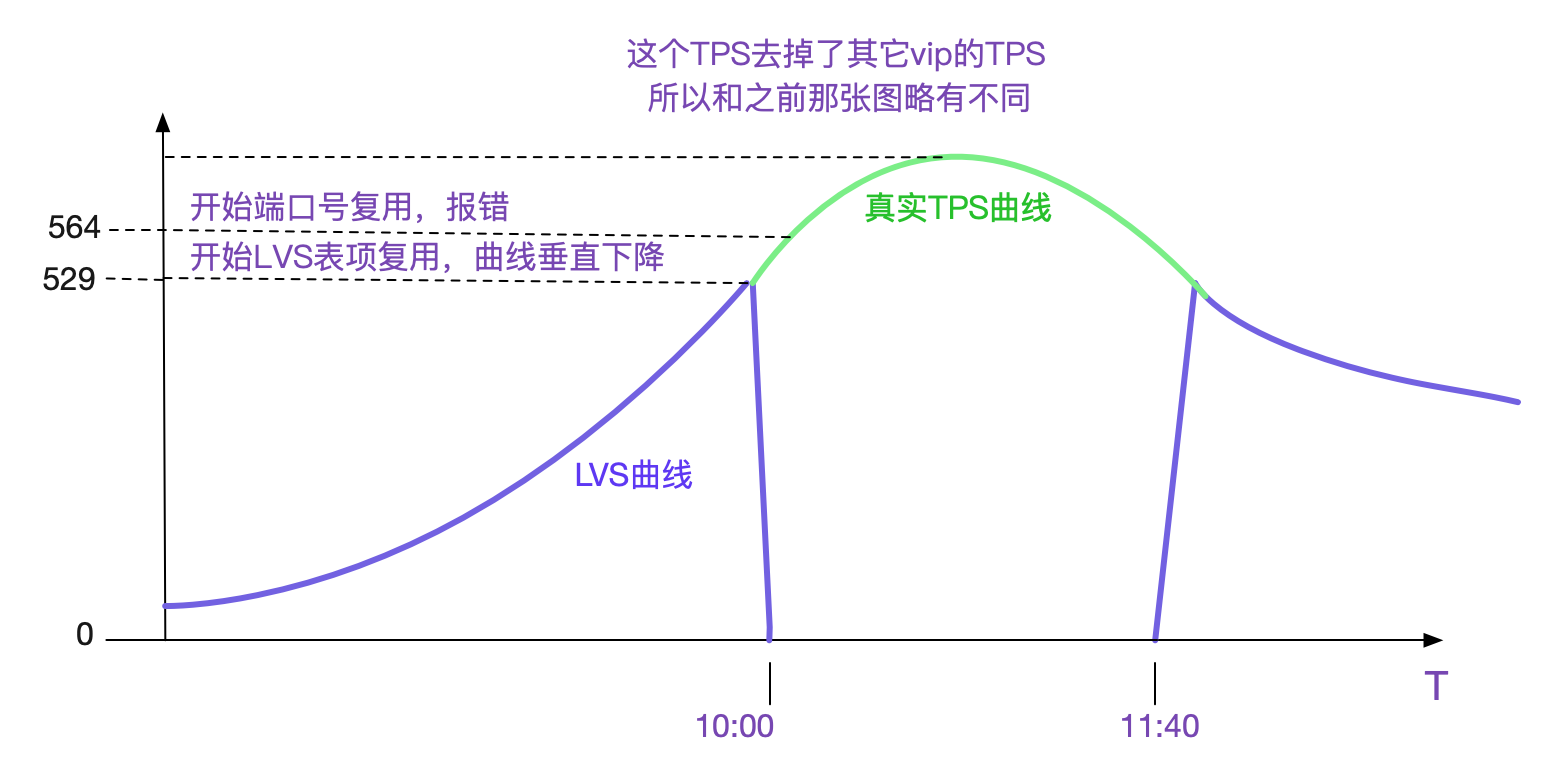
在埠號複用情況下,lvs本身的新建連線數無法代表真實TPS。
## 嘗試修復
### 設定tcp\_tw\_max_bucket
首先,筆者嘗試限制Nginx所在Linux中最大TIME\_WAIT數量
```
echo '5000' > /proc/sys/net/ipv4/tcp_tw_max_bucket
```
這基於一個很簡單的想法,TIME\_WAIT狀態越少,那麼命中TIME\_WAIT狀態Socket的概率肯定越小。設定了之後,確實報錯量確實減少了好多。但由於TPS超越極限之後埠號不停的迴繞,導致還是一直在報錯,不會有根本性好轉。
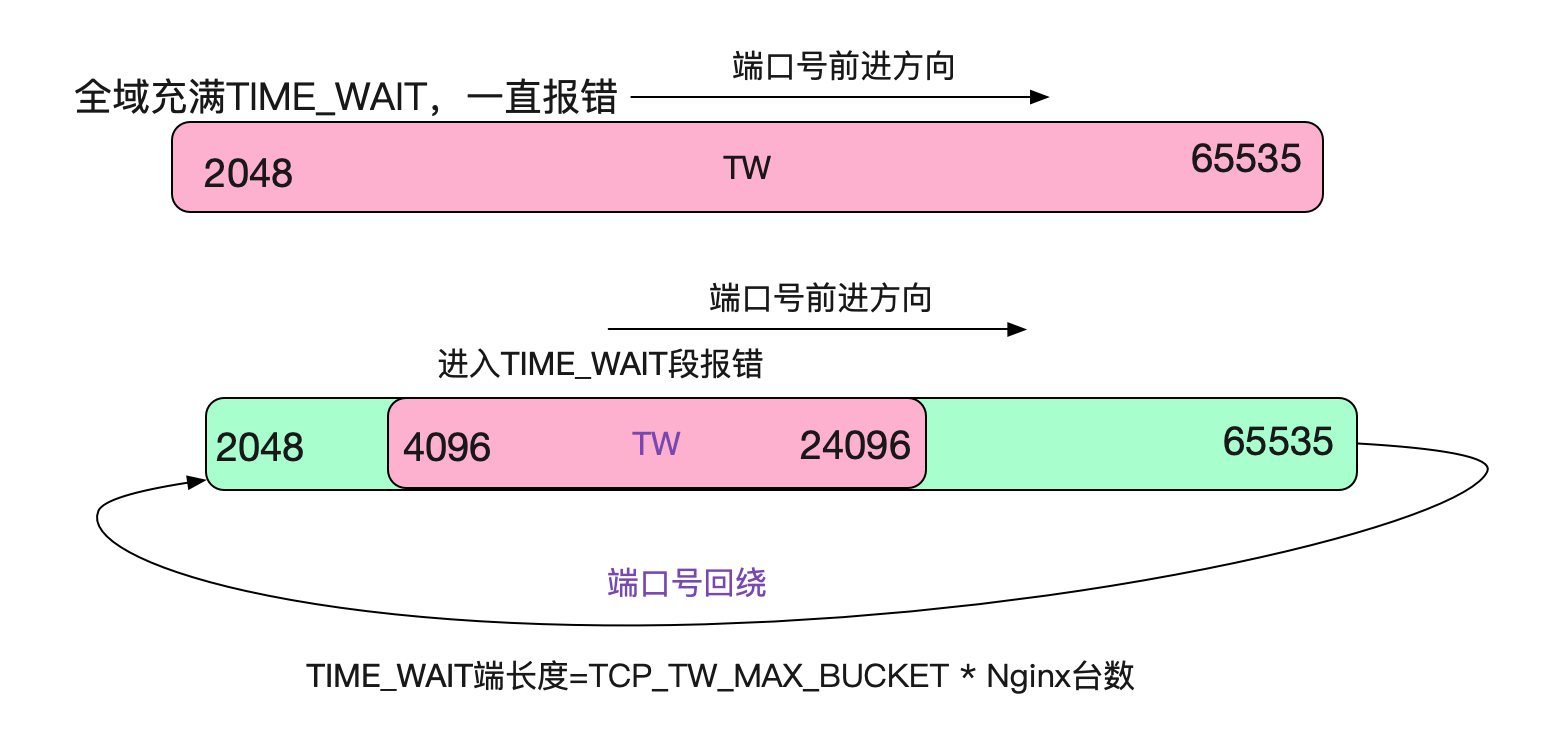
如果將tcp\_tw\_max\_bucket設定為0,那麼按理論上來說不會出問題了。
但是無疑將TCP精心設計的TIME\_WAIT這個狀態給廢棄了,筆者覺得這樣做過於冒險,於是沒有進行嘗試。
### 嘗試擴充套件源地址
這個問題本質是由於五元組在限定了4元,只有源埠號可變的情況下,埠號只有
2048-65535可用。那麼我們放開源地址的限定,例如將源IP增加到3個,無疑可以將TPS擴大三倍。
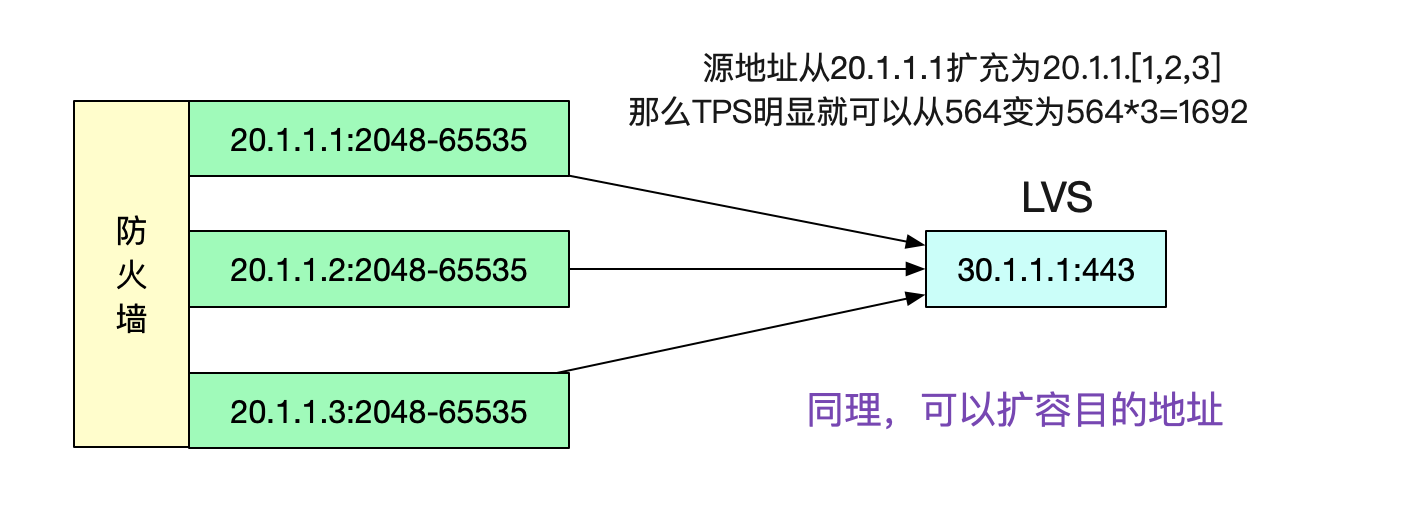
同理,將目的地址給擴容,也能達到類似的效果。
但據網工反映,合作方通過他們的防火牆出來之後就只有一個IP,而一個IP在我們的防火牆上並不能對映成多個IP,多以在不變更它們網路設定的情況下無法擴充套件源地址。而擴容目的地址,也需要對合作方網路設定進行修改。本著不讓合作方改動的服務精神,筆者開始嘗試其它方案。
### 擴容Nginx?沒效果
在一開始筆者沒有搞明白LVS那個詭異的曲線的時候,筆者並不知道在埠複用的情況下,LVS會表現出"親和性"。於是想著,如果擴容Nginx後,根據負載均衡原則,正好落到有這個TIME\_WAIT五元組的概率會降低,所以嘗試著另擴容了一倍的Nginx。但由於之前所說的LVS在埠號複用下的親和性,反而加大了TIME\_WAIT段!
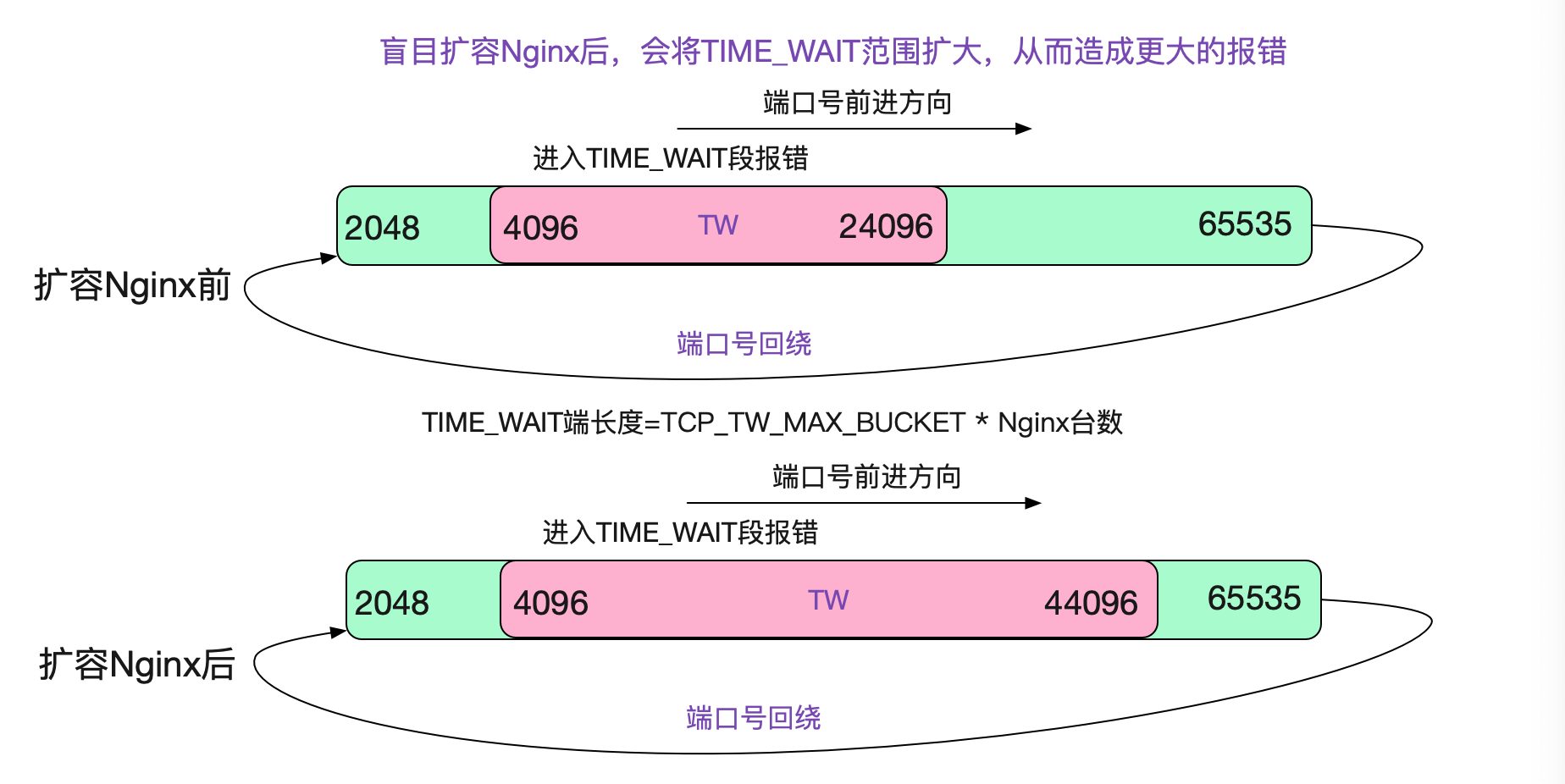
#### 擴容Nginx的奇異現象
在筆者想明白LVS的"親和性"之後,對擴容Nginx會導致更多的報錯已經有了心理預期,不過被現實啪啪啪打臉!報錯量和之前基本一樣。更奇怪的是,筆者發現非活躍連線數監控(即非ESTABLISHED)狀態,會在埠號複用之後,呈現出一種負載不均衡的現象,如下圖所示。
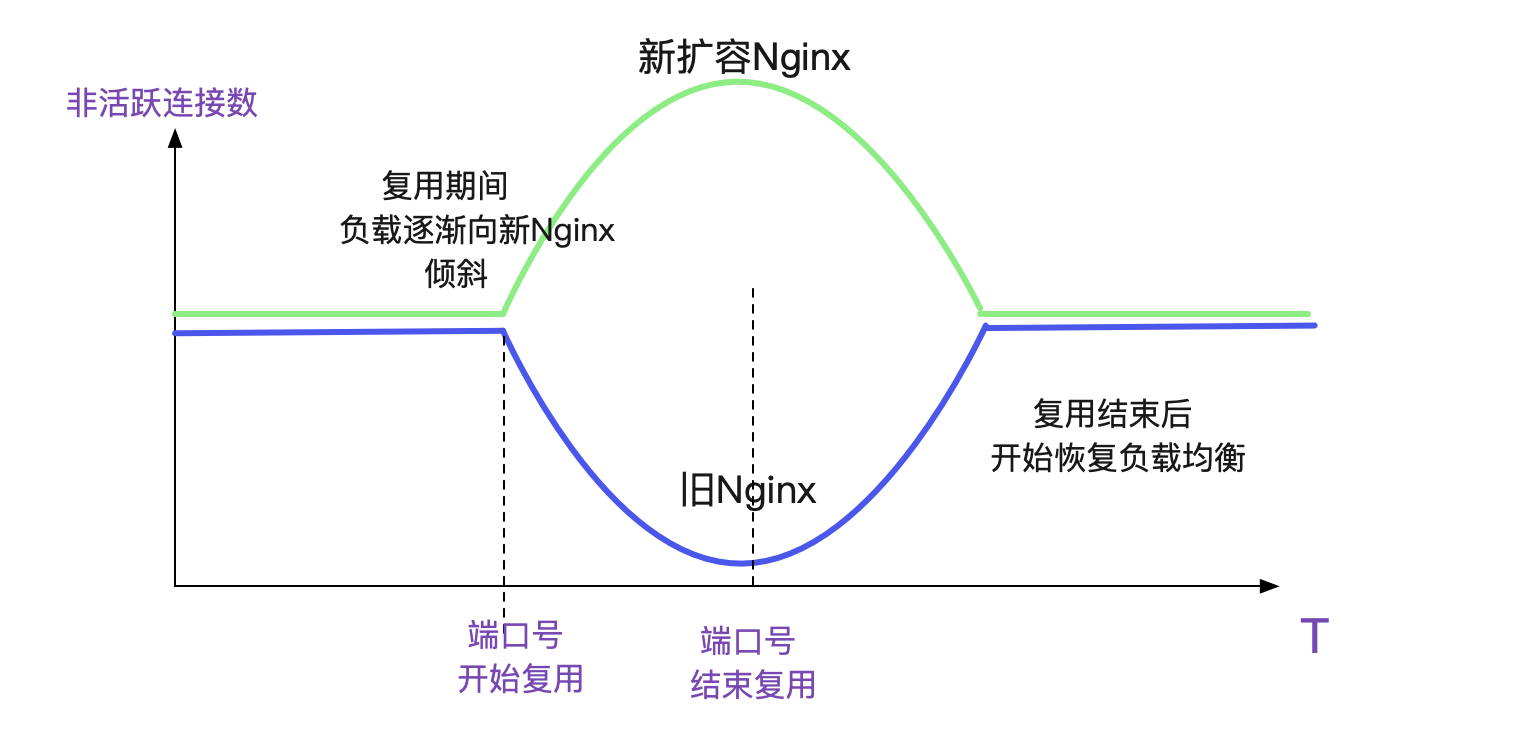
筆者上去新擴容的Nginx看了一下,發現新Nginx只有很少量的由於PAWS引起的報錯,增長速率很慢,基本1個小時只有100多。而舊Nginx一個小時就有1W多!
那麼按照這個錯誤比例分佈,就很好理解為什麼形成這樣的曲線了。因為LVS的親和性,在埠號複用時刻,落到舊Nginx上會大概率失敗,從而在Fintimeout到期後,重新選擇一個負載均衡的時候,如果落到新Nginx上,按照統計引數來看基本都會成功,但如果還是落到舊Nginx上則基本還會失敗,如此往復。就天然的形成了一個優先選擇的過程,從而造成了這個曲線。
當然實際的過程會比這個複雜一點,多一些步驟,但大體是這個思路。
而在埠複用結束後,不管落到哪個Nginx上都會成功,所以負載均衡又會慢慢趨於均衡。
### 為什麼新擴容的Nginx表現異常優異呢?
新擴容的Nginx表現異常優異,在這個TPS下沒有問題,那到底是為什麼呢?筆者想了一天都沒想明白。睡了一覺之後,對比了兩者的核心引數,突然豁然開朗。原來新擴容的Nginx所在的核心版本變了,變成了3.10!
筆者連忙對比起了原來的2.6核心和3.10的核心版本變化,但毫無所得。。。思維有陷入了停滯
#### Linux官方3.10和紅帽的3.10.1127分支差異
等等,我們線上的核心版本是3.10.1127,並不是官方的核心,難道程式碼有所不同?於是筆者立馬下載了3.10.1127的原始碼。這一比對,終於讓筆者找到了原因所在,看如下程式碼!
```
void inet_twdr_twkill_work(struct work_struct *work)
{
struct inet_timewait_death_row *twdr =
container_of(work, struct inet_timewait_death_row, twkill_work);
bool rearm_timer = false;
int i;
BUILD_BUG_ON((INET_TWDR_TWKILL_SLOTS - 1) >
(sizeof(twdr->thread_slots) * 8));
while (twdr->thread_slots) {
spin_lock_bh(&twdr->death_lock);
for (i = 0; i < INET_TWDR_TWKILL_SLOTS; i++) {
if (!(twdr->thread_slots & (1 << i)))
continue;
while (inet_twdr_do_twkill_work(twdr, i) != 0) {
// 如果這次沒處理完,將rearm_timer設定為true
rearm_timer = true;
if (need_resched()) {
spin_unlock_bh(&twdr->death_lock);
schedule();
spin_lock_bh(&twdr->death_lock);
}
}
twdr->thread_slots &= ~(1 << i);
}
spin_unlock_bh(&twdr->death_lock);
}
// 在這邊多了一個rearm_timer,並將定時器設定為1s之後
// 這樣,原來需要額外等待的7.5s現在收斂為額外等待1s
if (rearm_timer)
mod_timer(&twdr->tw_timer, jiffies + HZ);
}
```
如程式碼所示,3.10.1127對TIME\_WAIT的時間輪處理做了加速,讓原來需要額外等待的7.5s收斂為額外等待的1s。經過校正後的時間輪如下所示:
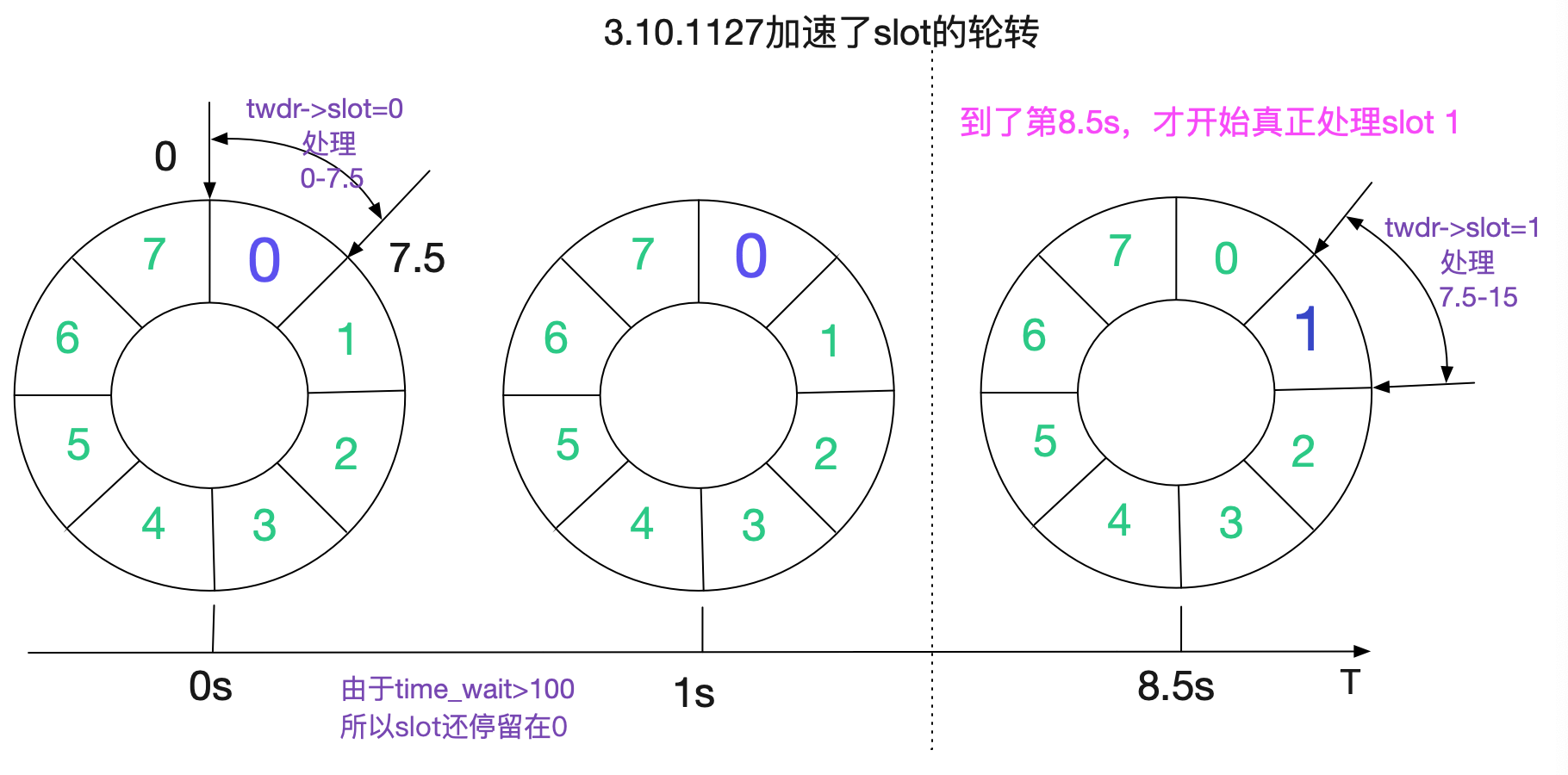
那麼TIME\_WAIT的存活時間就從112.5s下降到60.5s(計算公式8.5*7+1)。
那麼,在這個狀態下,我們的埠複用臨界TPS就達到了(65535-2048)/60.5=1049tps,由於線上業務量並沒有達到這一tps。所以對於新擴容的Nginx,並不會造成TIME\_WAIT下的埠複用。所以錯誤量並沒有變多!當然,由於舊Nginx的存在,錯誤量也沒有變少。
但是,由於那個神奇的選擇性負載均衡的存在,在埠複用時間越長,每秒鐘的報錯量會越少!直到LVS的表項全部指到新Nginx叢集,就不會再有報錯了!
#### TPS漲到1049tps依舊會報錯
當然了,根據上面的計算,在TPS繼續上漲到1049後,依舊會產生錯誤。新版本核心只不過拉高了臨界值,所以筆者還是要尋求更加徹底的解決方案。
#### 順便吐槽一句
Linux TCP的實現對TIME\_WAIT的處理用時間輪在筆者看來並不是什麼高明的處理方式。
Linux本身對於Timer的處理本身就提供了紅黑樹這樣的方案。放著這樣好的方案不用,偏偏去實現一個精度不高還很複雜的時間輪。
所幸在Linux 4.x版本中,擯棄了時間輪,直接使用Linux本身的紅黑樹方案。感覺自然多了!
### 關閉tcp\_timestamps
筆者一開始並不想修改這個引數,因為修改意味著關閉PAWS校驗。要是真有個什麼亂序包之類,就少了一層防禦手段。但是事到如今,為了不讓合作方修改,只能改這個引數了。不過由於是我們是專線!所以風險可控。
```
echo '0' > /proc/sys/net/ipv4/tcp_tw_max_bucket
```
執行至今,業務上反饋良好。終於,這個問題終於被解決了!!!!!!
補充一句,關閉tcp\_timestamps只是筆者在種種限制下所做的選擇,更好的方案應該是擴充源或者目的地址。
# 總結
解決這個問題真的是一波三折。在問題解決過程中,從LVS原始碼看到Linux 2.6核心對TIME\_WAIT狀態的處理,再到3.10核心和3.10.1127核心之間的細微區別。
為了解釋所有的疑點,筆者始終在找尋著各種蛛絲馬跡。雖然不追尋這些,問題依舊大概率能夠通過各種嘗試得到解決。但是,那些奇怪的曲線始終縈繞在筆者心頭,讓筆者日思夜想。然後,突然靈光乍現,找到線索後頓悟的那種感覺實在是太棒了!這也是筆者解決複雜問題源源不斷的動力!
歡迎大家關注我公眾號,裡面有各種乾貨,還有大禮包相送哦!
