
基於Scrapy的B站爬蟲
阿新 • • 發佈:2020-07-24
# **基於Scrapy的B站爬蟲**
最近又被叫去做爬蟲了,不得不拾起兩年前搞的東西。
說起來那時也是突發奇想,想到做一個B站的爬蟲,然後用的都是最基本的Python的各種庫。
不過確實,實現起來還是有點麻煩的,單純一個下載,就有很多麻煩事。
這回要快速實現一個爬蟲,於是想到基於現成的框架來開發。
Scrapy是以前就常聽說的一個爬蟲框架,另一個是PySpider。
不過以前都沒有好好學過框架。
這回學習了一波,順便擼出來一個小Demo。
這個Demo功能不多,只能爬取B站的視訊列表,不過主要在於學習、記錄、交流,不在於真的要爬B站。。
然後程式碼都在GitHub了:
https://github.com/wangzb96/Scrapy-Bilibili
---
## **爬蟲的定義**
爬蟲的定義有以下兩點:
- 自動爬取網路資源 (html、json、...)
- 模擬瀏覽器行為
第一點是常規的定義,第二點是進階版的定義,因為如果爬蟲要持久穩定地爬取資料,那麼就要模擬真人使用瀏覽器的行為,模擬得越像越好,越不容易被封。
---
## **爬蟲的流程**
- 頁面分析
- 工具
- 谷歌瀏覽器
- 360極速瀏覽器
- 問題
- 哪些資料需要爬取?
- 這些資料存放在什麼檔案上?
- 這些檔案的連結是什麼?
- 連結的生成規則是什麼?
- 存放在其他頁面檔案
- 通過某種簡單的規則生成 (如遞增的數字)
- 獲取連結
- 通過解析網頁檔案得到連結
- 通過模版生成不同的連結
- 下載資源
- `requests`
- `asyncio`
- 頁面解析
- `json`
- `bs4.BeautifulSoup`
- `pyquery.PyQuery`
- `re`
- 資料儲存
- 檔案
- 資料庫
---
## **Scrapy框架介紹**
Scrapy是一個用於實現爬蟲的Python框架,它將爬蟲執行過程抽象成幾個元件,如圖:
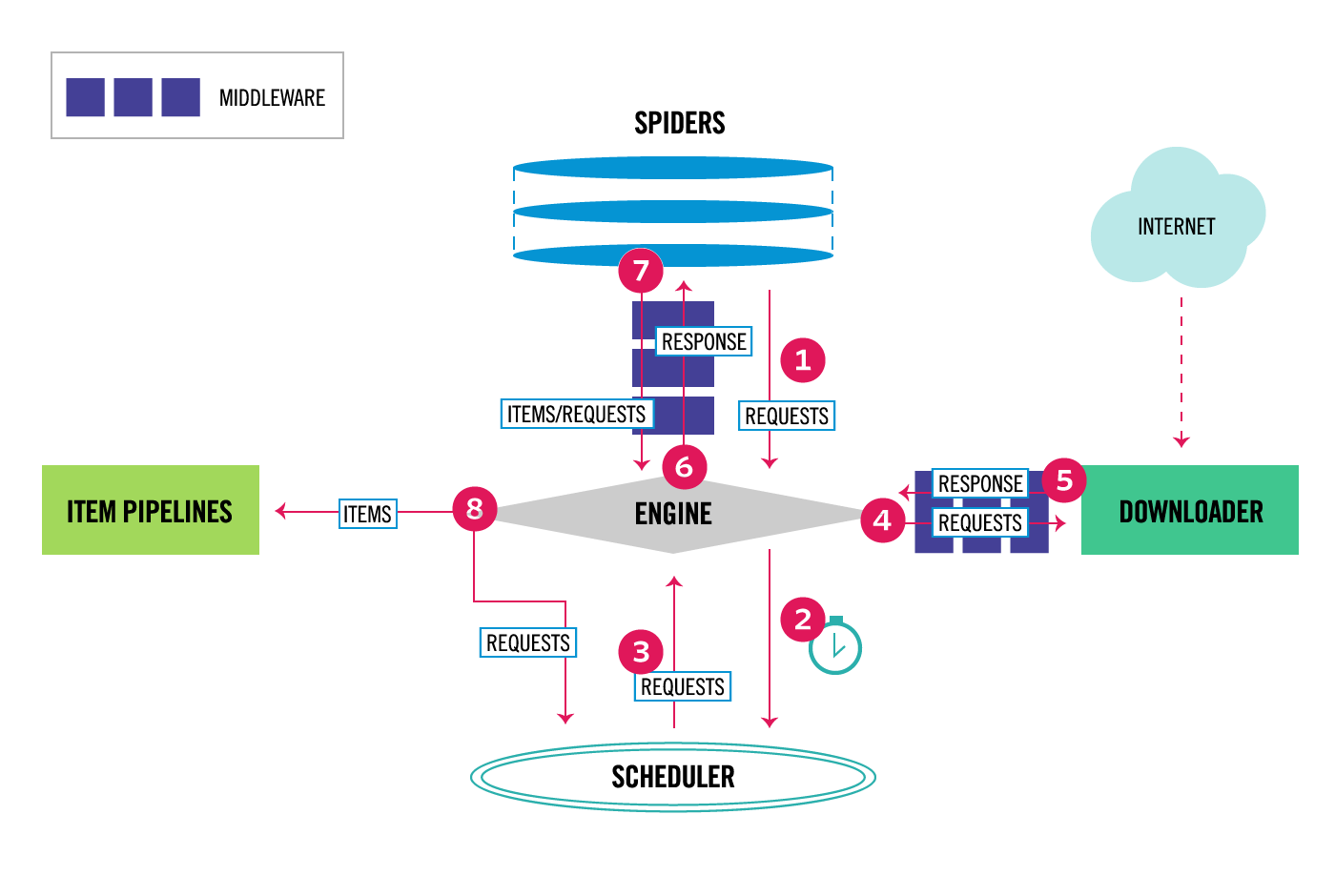 其中主要包括:
- Engine (不需要使用者實現)
- 驅動元件執行
- Scheduler (不需要使用者實現)
- 接收請求
- 排程請求
- 返回請求
- Downloader (不需要使用者實現)
- 請求網路資源
- 返回響應
- Spider (需要使用者實現)
- 返回初始請求
- 頁面解析
- 返回Item物件
- 返回新請求
- Item Pipeline (需要使用者實現)
- Item物件清洗
- Item物件驗證
- Item物件儲存
- Middleware (需要使用者實現)
- Downloader Middleware
- Spider Middleware
- 在元件執行的一些子過程中執行額外操作
當應用Scrapy實現爬蟲時,由於Scrapy已經實現了Engine、Scheduler、Downloader等元件,所以使用者無需實現這些元件,使用者主要要實現Spider,以及按需實現Item Pipeline、Middleware,另外還需要實現Item類。
---
## **基於Scrapy的B站爬蟲實現**
以下介紹一個B站美食區視訊列表爬蟲實現的案例。
---
### **開始一個Scrapy專案**
首先在命令列或終端中輸入:
scrapy startproject scrapy_bilibili
Scrapy會在當前目錄下生成如下的目錄:
- ***scrapy_bilibili***
- *scrapy_bilibili*
- *spiders*
- \_\_init\_\_.py
- \_\_init\_\_.py
- items.py
- pipelines.py
- middlewares.py
- settings.py
- scrapy.cfg
其中斜體的是資料夾,我們把加粗的資料夾設定成專案的根目錄。
---
### **B站美食區視訊列表頁面分析**
B站美食區的連結地址是固定的:
https://www.bilibili.com/v/life/food/?#/all/default/0
進去後裡面有個視訊列表,我們使用360極速瀏覽器分析:
其中主要包括:
- Engine (不需要使用者實現)
- 驅動元件執行
- Scheduler (不需要使用者實現)
- 接收請求
- 排程請求
- 返回請求
- Downloader (不需要使用者實現)
- 請求網路資源
- 返回響應
- Spider (需要使用者實現)
- 返回初始請求
- 頁面解析
- 返回Item物件
- 返回新請求
- Item Pipeline (需要使用者實現)
- Item物件清洗
- Item物件驗證
- Item物件儲存
- Middleware (需要使用者實現)
- Downloader Middleware
- Spider Middleware
- 在元件執行的一些子過程中執行額外操作
當應用Scrapy實現爬蟲時,由於Scrapy已經實現了Engine、Scheduler、Downloader等元件,所以使用者無需實現這些元件,使用者主要要實現Spider,以及按需實現Item Pipeline、Middleware,另外還需要實現Item類。
---
## **基於Scrapy的B站爬蟲實現**
以下介紹一個B站美食區視訊列表爬蟲實現的案例。
---
### **開始一個Scrapy專案**
首先在命令列或終端中輸入:
scrapy startproject scrapy_bilibili
Scrapy會在當前目錄下生成如下的目錄:
- ***scrapy_bilibili***
- *scrapy_bilibili*
- *spiders*
- \_\_init\_\_.py
- \_\_init\_\_.py
- items.py
- pipelines.py
- middlewares.py
- settings.py
- scrapy.cfg
其中斜體的是資料夾,我們把加粗的資料夾設定成專案的根目錄。
---
### **B站美食區視訊列表頁面分析**
B站美食區的連結地址是固定的:
https://www.bilibili.com/v/life/food/?#/all/default/0
進去後裡面有個視訊列表,我們使用360極速瀏覽器分析:
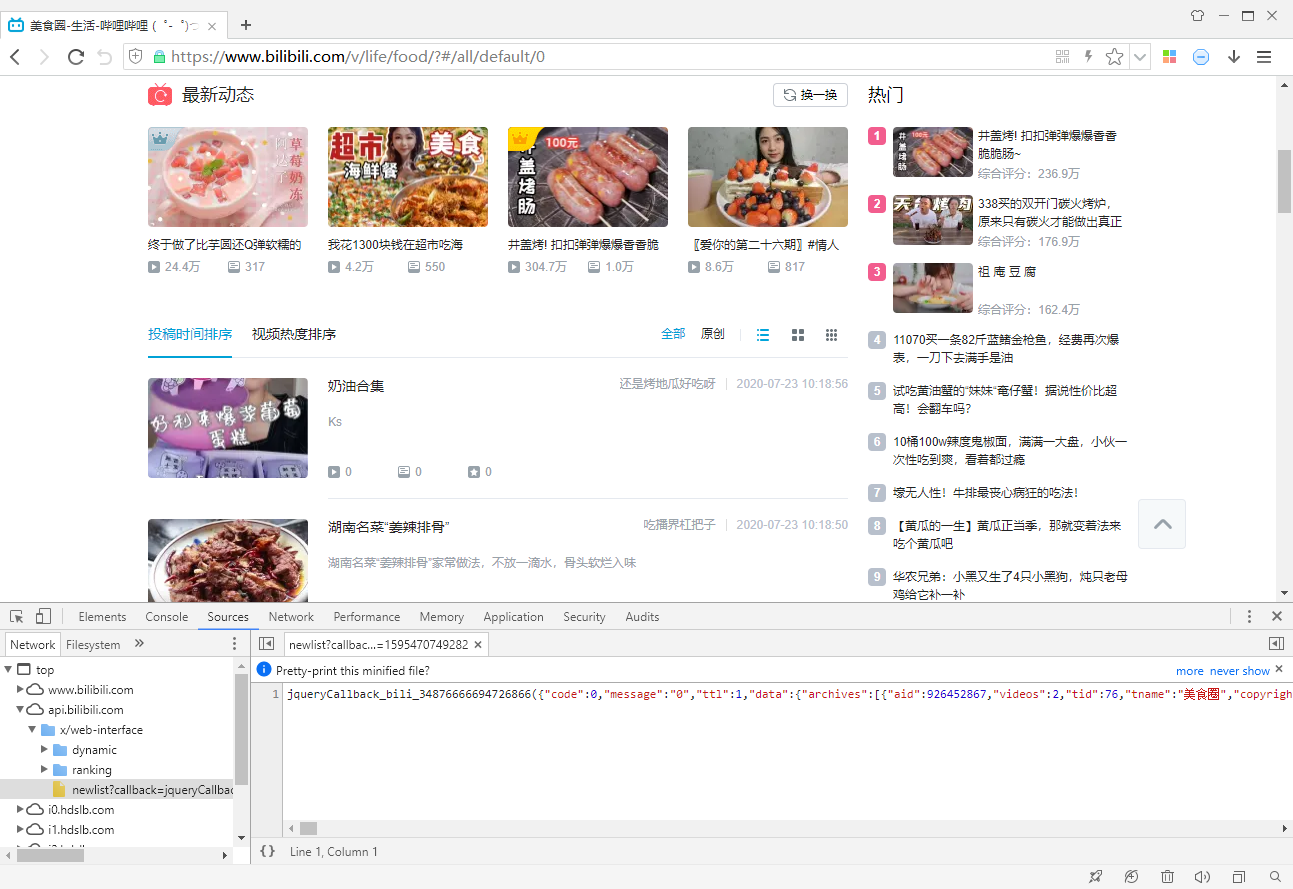
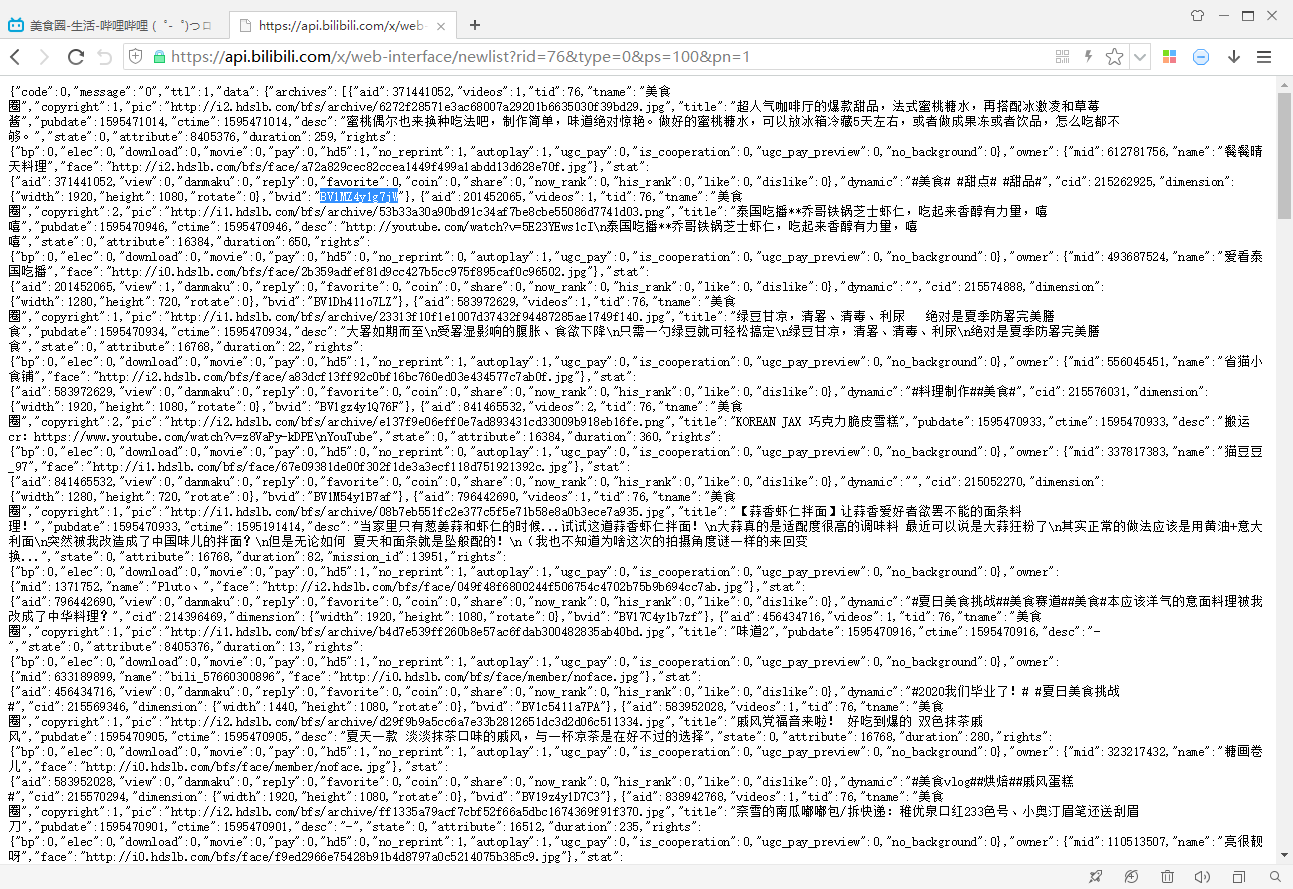 分析一下這個連結的引數,`rid`是美食區的id,`type`是按日期排序還是按熱度排序,`ps`表示每頁視訊數量,`pn`表示第幾頁。
然後觀察B站的視訊頁面:
分析一下這個連結的引數,`rid`是美食區的id,`type`是按日期排序還是按熱度排序,`ps`表示每頁視訊數量,`pn`表示第幾頁。
然後觀察B站的視訊頁面:
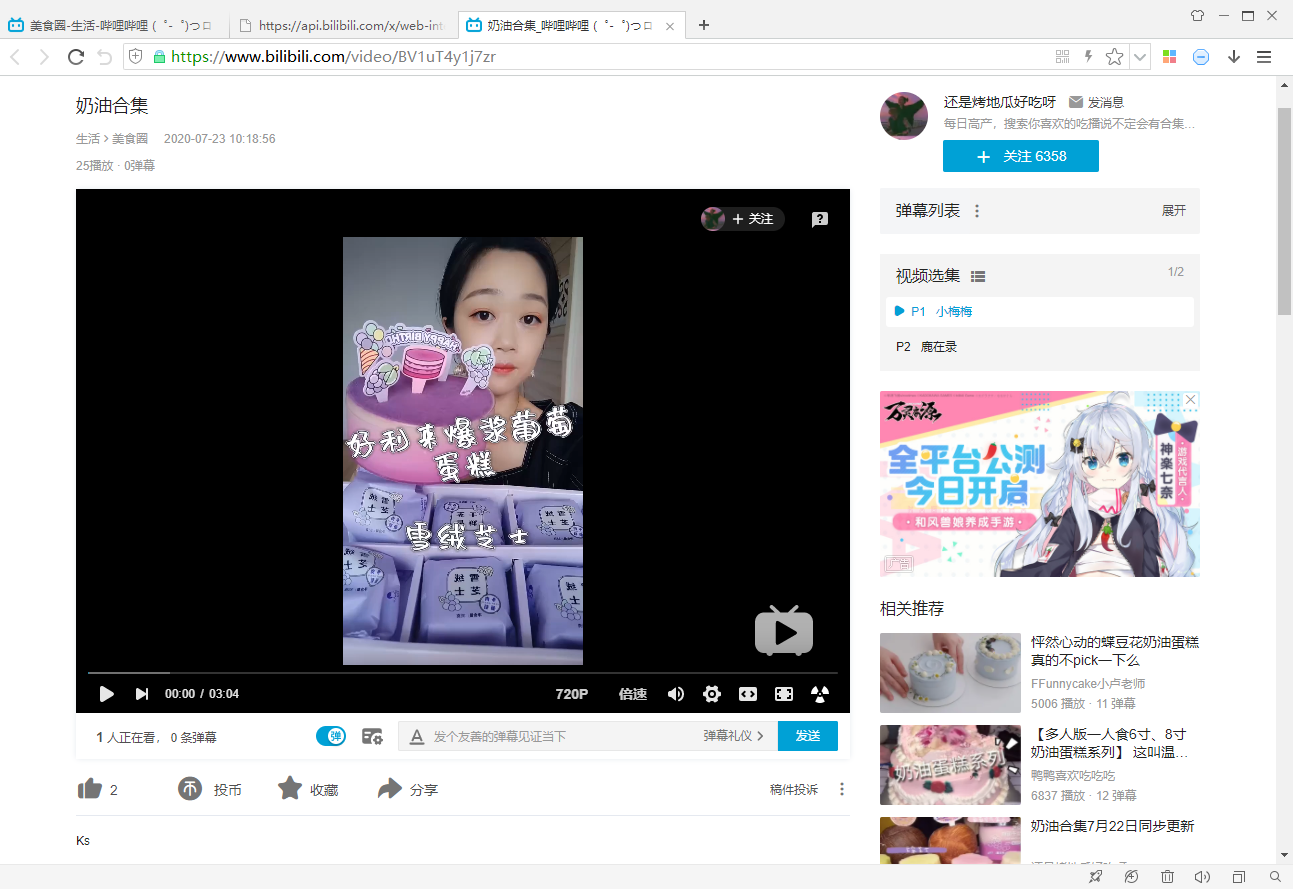 發現視訊頁面的連結地址是由固定模版生成的:
https://www.bilibili.com/video/{bvid}
其中bvid是每個視訊的id,可以通過“newlist”連結獲得。
如果要爬取視訊頁面資訊,那麼應用以上方法分析一下就可以了。
---
### **B站視訊列表Item類實現**
Scrapy的Item類,在概念上相當於C/C++的結構體、Java的POJO。
這裡簡單起見,我們將視訊列表json檔案中每個元素感興趣的資訊均存放在一個Item物件中,程式碼如下:
發現視訊頁面的連結地址是由固定模版生成的:
https://www.bilibili.com/video/{bvid}
其中bvid是每個視訊的id,可以通過“newlist”連結獲得。
如果要爬取視訊頁面資訊,那麼應用以上方法分析一下就可以了。
---
### **B站視訊列表Item類實現**
Scrapy的Item類,在概念上相當於C/C++的結構體、Java的POJO。
這裡簡單起見,我們將視訊列表json檔案中每個元素感興趣的資訊均存放在一個Item物件中,程式碼如下:
其中主要包括:
- Engine (不需要使用者實現)
- 驅動元件執行
- Scheduler (不需要使用者實現)
- 接收請求
- 排程請求
- 返回請求
- Downloader (不需要使用者實現)
- 請求網路資源
- 返回響應
- Spider (需要使用者實現)
- 返回初始請求
- 頁面解析
- 返回Item物件
- 返回新請求
- Item Pipeline (需要使用者實現)
- Item物件清洗
- Item物件驗證
- Item物件儲存
- Middleware (需要使用者實現)
- Downloader Middleware
- Spider Middleware
- 在元件執行的一些子過程中執行額外操作
當應用Scrapy實現爬蟲時,由於Scrapy已經實現了Engine、Scheduler、Downloader等元件,所以使用者無需實現這些元件,使用者主要要實現Spider,以及按需實現Item Pipeline、Middleware,另外還需要實現Item類。
---
## **基於Scrapy的B站爬蟲實現**
以下介紹一個B站美食區視訊列表爬蟲實現的案例。
---
### **開始一個Scrapy專案**
首先在命令列或終端中輸入:
scrapy startproject scrapy_bilibili
Scrapy會在當前目錄下生成如下的目錄:
- ***scrapy_bilibili***
- *scrapy_bilibili*
- *spiders*
- \_\_init\_\_.py
- \_\_init\_\_.py
- items.py
- pipelines.py
- middlewares.py
- settings.py
- scrapy.cfg
其中斜體的是資料夾,我們把加粗的資料夾設定成專案的根目錄。
---
### **B站美食區視訊列表頁面分析**
B站美食區的連結地址是固定的:
https://www.bilibili.com/v/life/food/?#/all/default/0
進去後裡面有個視訊列表,我們使用360極速瀏覽器分析:
分析一下這個連結的引數,`rid`是美食區的id,`type`是按日期排序還是按熱度排序,`ps`表示每頁視訊數量,`pn`表示第幾頁。
然後觀察B站的視訊頁面:
發現視訊頁面的連結地址是由固定模版生成的:
https://www.bilibili.com/video/{bvid}
其中bvid是每個視訊的id,可以通過“newlist”連結獲得。
如果要爬取視訊頁面資訊,那麼應用以上方法分析一下就可以了。
---
### **B站視訊列表Item類實現**
Scrapy的Item類,在概念上相當於C/C++的結構體、Java的POJO。
這裡簡單起見,我們將視訊列表json檔案中每個元素感興趣的資訊均存放在一個Item物件中,程式碼如下: