
AI大有可為:NAIE平臺助力垃圾分類
摘要:生活垃圾的分類和處理是目前整個社會都在關注的熱點,如何對生活垃圾進行簡潔高效的分類與檢測對垃圾的運輸處理至關重要。AI技術在垃圾分類中的應用成為了關注焦點。
如今AI已經是這個時代智慧的代名詞了,任何領域都有AI的身影,垃圾分類及監管等場景自然也少不了“AI+”的賦能。
不過,垃圾往往屬於商品的極端變形體,情況比較特殊。目前的技術在視覺可見的基礎上,是可以做到垃圾分類報警提醒的,比如判斷垃圾是否是經過分類整理的。至於是否能夠直接進行視覺檢測並分類,且達到某種效果,需要更多的資料和實驗支撐才能判斷這件事情的可行性。針對這些問題,我們或許可以從海華垃圾分類挑戰賽中去聽聽參賽者都是如何用技術來改變世界的。
海華垃圾分類挑戰賽資料包括單類垃圾資料集以及多類垃圾資料集。單類垃圾資料集包含80,000張單類生活垃圾圖片,每張單類垃圾圖片中僅有一個垃圾例項。多類垃圾資料集包括4998張影象,其中2,998張多類垃圾圖片作為訓練集資料,A榜和B榜各包含1000張測試影象,每張多類垃圾圖片中包含至多20類垃圾例項。我們將對兩種資料集分別進行介紹。
一、多類別垃圾
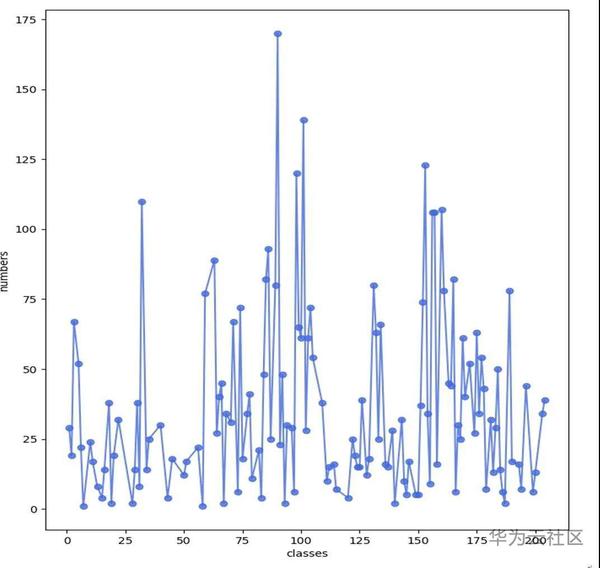
圖1 多類垃圾資料類別分佈
如圖1所示,多類別垃圾涵蓋了204類垃圾,但這204類的資料非常不均衡,有一些類別數目非常少甚至沒有出現。

圖2 多類垃圾資料視覺化
圖2中兩張圖是訓練集中的兩張影象,垃圾目標主要集中在影象的中心區域重疊度較高,此外可以看到很一些目標往往會以不同的角度姿態在另一張影象中出現。
從圖1與圖2的觀察與統計我們可以得出幾個結論:
(1)由於一個物體經常在多張影象中出現,因此過擬合這些目標非常有效,這也是為什麼這個比賽AP能訓到90以上的原因。因此可以考慮引數量更大的backbone,比如ResNext101 X64+DCN。
(2)影象是俯視拍攝的,水平和垂直翻轉都很有效。
(3)雖然類別非常不均衡,但是由於目標的重複出現,經常幾個目標的訓練,再見到同一個目標就能100%的檢測到。類別不均衡主要對資料極少的物體有影響,因此只需要對這些目標進行擴充,主要包括墨盒、螺螄、話梅核、貝類等。
(4)重疊度較高可以使用mixup等方法,人為地製造一些重疊度高的目標進行訓練。
表1 資料統計

除了影象級別的巨集觀統計,我們對資料集中的目標也做了詳細分析。表1為目標大小、以及長寬比層面的統計。首先物體長度按照coco的劃分,大於96的屬於大物體,75%的目標都是大物體,這意味著針對小物體的提升方法是基本無效的。其次長寬比很少有大比例物體的出現,這些給予我們anchor方面的引數調整很多啟發。
二、單類別垃圾
單類別垃圾主要包含80000張影象,每張1個目標,如左邊兩張圖所示單類別垃圾的目標都較大。單類的使用主要有兩種思路,一種是對類別少的資料擴充,另一種是使用單類資料集訓練得到一個較好的預訓練模型。

圖3資料對比
資料擴充時我們發現,和多類別垃圾相比,同一類的目標並不是完全一致的,單類的小龍蝦是小龍蝦,多類的小龍蝦實際標的是牛奶盒,二極體標的是塑料管。這一點說明想用單類做資料擴充是行不通的,因為資料不是同源的。我們嘗試了這種方案,但是精度保持不變。
針對預訓練模型,由於目標較大,我們將影象按照4*4進行拼接,減少了資料量,提升了單張影象的目標數,也能取得一定的效果。但是當與其他增強方法結合時基本沒有效果,因此我們也放棄了這種方案。
三、模型方案:
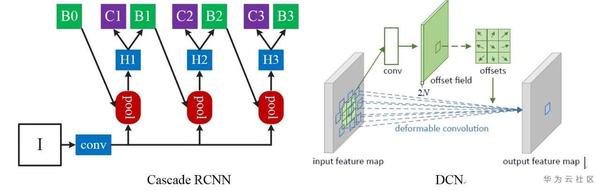
1.Baseline
圖4 baseline方案
我們baseline選用的是mmdetection所實現的Cascade RCNN,backbone選用的是ResNeXt101 X64+DCN。因為此次比賽採用的是coco的評測指標AP50:95,因此Cascade RCNN通過設定不同的閾值進行迴歸可以取得非常好的效果。此外較大的backbone在這個資料集上往往能取得更好的效果。
2. 引數調整
在比賽的初期,我們將訓練集的資料選取2500張訓練,498張本地驗證,在此基礎上進行調參。由於目標重疊度較高,在使用softnms閾值為0.001、max_per_img =300、翻轉測試時效果較好,相比不使用這些引數大約能提升0.02左右。受到視訊記憶體的限制從影象中隨機裁剪(0.8w,0.8h)的影象區域,然後將短邊隨機限制在[640,960]之間,長邊限制到1800進行多尺度訓練,測試時影象適度放大短邊設定為1200,精度可以訓練到88.3%, 結合OHEM精度訓練到88.6%左右,將本地驗證的498張影象也輸入進去訓練能提升0.5%到89.2%左右。
針對數量較少的類別,我們在多類訓練集中對貝類去硬殼、螺螄、二極體、話梅核這幾個類別進行補充標註,把一些模稜兩可的目標都進行標註提高召回率,大約標記了100多個目標,在A榜能提升到90%左右。
如圖5所示,針對anchor的調整,我們調整anchor 的比例從【0.5,1.0,2.0】改為【2.0/3.0,1.0,1.5】。此外為了提升大物體的檢測能力,我們調整FPN的層次劃分從56改為了70,相當於將FPN各層所分配的目標都調大,然後我們將anchor的尺度由8改為12對這些大物體進行檢測。

圖5 anchor 修改
如圖6所示引數調整後可以發現FPN中目標數量的分佈更加接近正態分佈,我們認為這樣的一種分佈對檢測會有所幫助。從ResNet的幾個stage的卷積數量我們可以看到,FPN中間層所對應的ResNet的stage引數較多應檢測較多目標,FPN兩側對應到backbone的引數較少檢測目標數不宜過多。
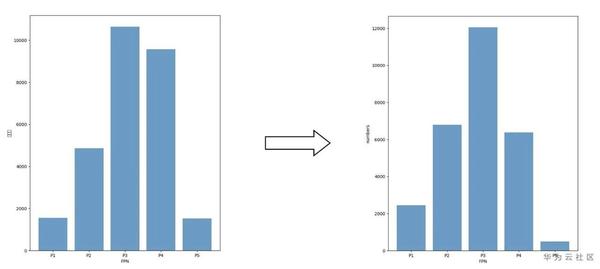
圖6 目標在FPN上的數量分佈變化
在影象增強時,我們加入線上的mixup進行24個epoch的訓練可以提升到91.2%~91.3%,不過只有12個epoch的時候沒有提升。Mixup我們設定的比較簡單,兩張影象分別以0.5的比例進行融合,因此沒必要對loss進行加權。

圖7 mixup 效果圖
3.模型融合
之前的測試過程中,我們認為1080Ti與2080速度應該相差不大,每次1080Ti上測試大約需要40分鐘,因此我們只選用3個模型左右,這一點是比較吃虧的,在B榜的測試時我們發現2080居然比1080Ti快很多,我們單個模型加翻轉測試只使用了25分鐘,如果用更多模型可能會進一步提高分數。我們使用基於ResNext101 x32+gcb+DCN的Cascade RCNN,基於ResNext101 x64 +DCN的Cascade RCNN,基於ResNext101 x64 +DCN的Guided anchor Cascade RCNN。對於融合所使用的方法,不同的方法所能取得的效果都相差不大,我們採用的方法是論文《Weighted Boxes Fusion: ensembling boxes for object detection models》所提供的方法,融合閾值設定為0.8.
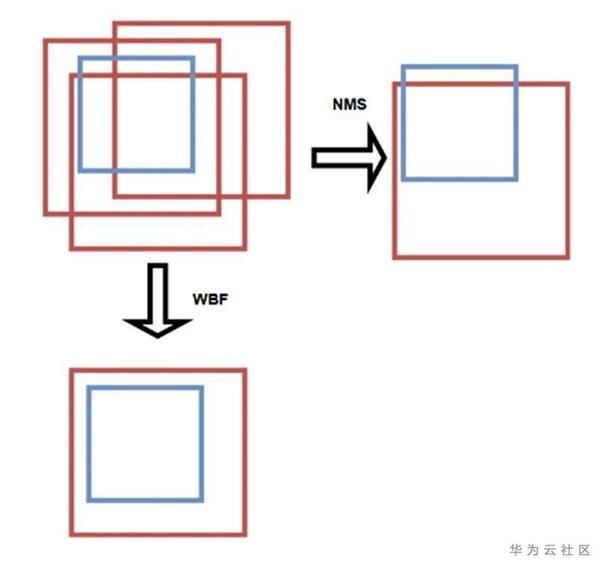
圖8 wbf效果圖
4.引數效果
表2 引數設定
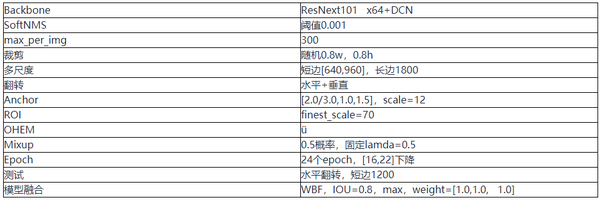
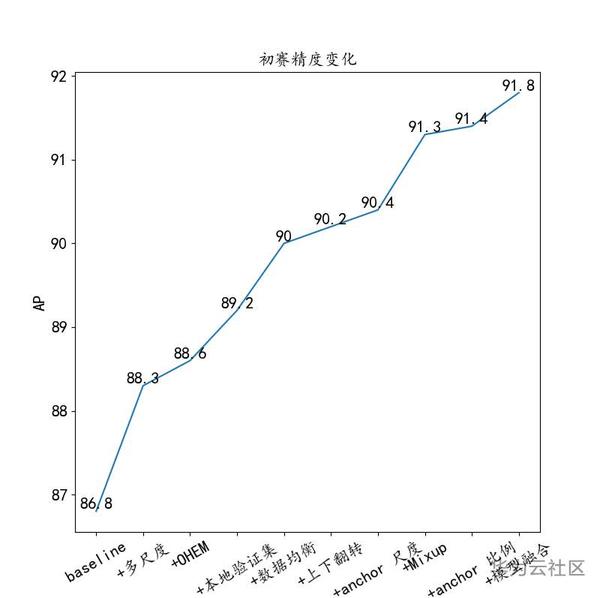
圖9 A榜精度變化
四、NAIE平臺部署使用
1.平臺理解
個人理解NAIE平臺主要由三部分組成,本地除錯區、雲端儲存區、雲端訓練區域,對這三部分各自地功能有所瞭解便可以很快上手。
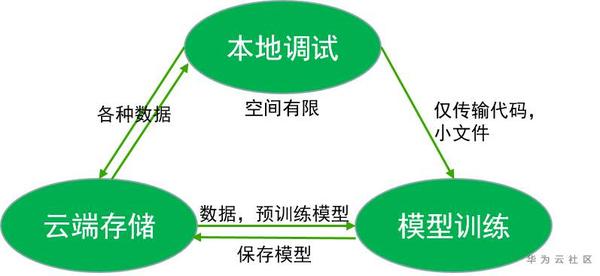
本地除錯區域基於vscode,關聯到一臺無GPU的伺服器,可以在命令列像正常linux伺服器一樣操作進行環境的初步部署除錯。

雲端儲存區域主要儲存大的資料以及預訓練模型,像預訓練模型這些大檔案是無法直接從本地除錯區傳送到模型訓練區域的。
模型訓練區域呼叫GPU完成模型的訓練,並將訓好的引數模型copy到雲端進行儲存,只有存至雲端的模型才可下載。
2. 模型部署
這裡以mmdetection的部署為例進行介紹。
- 1)程式碼上傳
程式碼上傳通過右鍵選取NAIE upload,程式碼上傳時有大小限制,大約不能超過100M,因此建議將預訓練模型以及一些無關的檔案刪除只保留核心程式碼。
- 2)環境部署
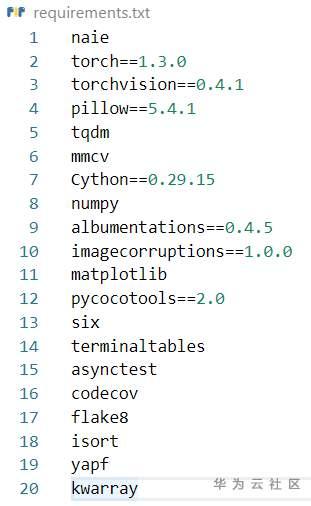
環境部署需要在原生代碼區寫一個requirements.txt的檔案,上面寫明所需要的python庫和版本號。
- 3)模型執行
平臺不支援sh檔案的執行,因此需要寫一個py比如叫model.py ,裡面使用os.system()仿照命令列進行執行。

此外在model.py中還要呼叫moxing 包,將訓好的模型存至雲端。

在模型訓練區域,選中model.py 以及所需的GPU規格進行訓練。
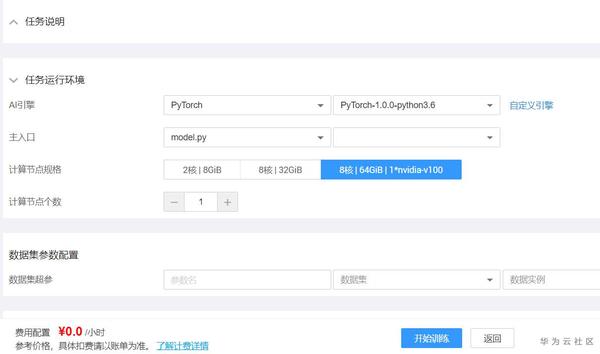
- 4)額外補充
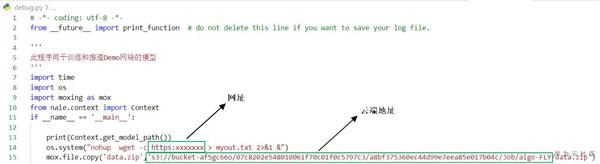
直接通過NAIE upload是無法完成大檔案上傳的,因此可以在本地除錯區域寫一個程式比如叫debug.py, 在程式中呼叫wget下載檔案,並通過moxing包傳至雲端,訓練過程中可以在model.py中利用moxing包再將其傳輸到伺服器中。
幾位參賽者最終完成比賽並獲得獎勵,雖然名次不是特別好,但還是通過比賽積累了很多經驗。他們表示,取得的成績離不開華為NAIE訓練平臺的算力支援,華為NAIE訓練平臺免費提供了V100和P100顯示卡進行訓練,為我們科研以及參加比賽提供了很大的幫助,修改程式碼和訓練都非常方便,前期熟悉平臺遇到的問題都能及時解答或者協助解決。希望通過這次分享能給大家提供一定借鑑和避坑的經驗。
參考文獻
[1]. Cai Z , Vasconcelos N . Cascade R-CNN: Delving into High Quality Object Detection[J]. 2017.
[2]. Zhang H , Cisse M , Dauphin Y N , et al. mixup: Beyond Empirical Risk Minimization[J]. 2017.
[3]. Solovyev R , Wang W . Weighted Boxes Fusion: ensembling boxes for object detection models[J]. arXiv, 2019.
[4]. P. Wang, X. Sun, W. Diao, and K. Fu, “Fmssd: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery,” IEEE Transactions on Geoscience and Remote Sensing, 2019.
[5]. Zhang S , Chi C , Yao Y , et al. Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection[J]. 2019.
[6]. Pang J , Chen K , Shi J , et al. Libra R-CNN: Towards Balanced Learning for Object Detection[J]. 2019.
[7]. Deng L , Yang M , Li T , et al. RFBNet: Deep Multimodal Networks with Residual Fusion Blocks for RGB-D Semantic Segmentation[J]. 2019.
[8]. Ren S , He K , Girshick R , et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6).
[9]. Lin T Y , Dollár, Piotr, Girshick R , et al. Feature Pyramid Networks for Object Detection[J]. 2016.
[10]. J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y.Wei, “Deformable convolutional networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 764–773.
[11]. X. Zhu, H. Hu, S. Lin, and J. Dai, “Deformable convnets v2: More deformable, better results,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 9308–9316.
[12]. Z. Huang, X. Wang, L. Huang, C. Huang, Y. Wei, and W. Liu, “Ccnet: Criss-cross attention for semantic segmentation,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 603–612.
[13]. Wang J , Chen K , Yang S , et al. Region Proposal by Guided Anchoring[J]. 2019.
點選關注,第一時間瞭解華為雲新鮮技