
解讀生成對抗網路(GAN) 之U-GAN-IT
Unsupervised Generative Attentionnal Networks with Adapter Layer-In(U-GAN-IT)
從字面我們可以理解為無監督生成對抗網路和適配層的結合
論文實現:
- 論文實現了無監督影象的翻譯問題,當兩個影象之間兩個影象、紋理差別較大時的影象風格(style)轉換。
- 論文實現了相同的網路結構和超引數同時需要同時保持shape的影象翻譯I(類似風格遷移但是影象本身形狀這些原始shape不變),以及需要改變shape的影象翻譯任務(個人觀點,跨domain)

圖1:風格遷移(horse2zebra)

圖2跨domain的影象翻譯(cat2dog)
創新:
在於這篇論文新增加了一個新的注意模組(attention):輔助分類器和一個可以自主學習的規範化函式(自適應的歸一化方式)AdaLIN,使得該模型具有更優越性。
- attention:增強判別器的鑑別能力,更好的區分原始影象和生成影象
- 自適應的歸一化AdaLIN:增強魯棒性
得到了在固定網路結構和超引數下保持形狀(如horse2zebra)和改變形狀(如cat2dog)的影象轉換的預期結果。需要針對特定資料集調整網路結構或超引數設定。在這項工作中,我們提出了一種新的無監督影象到影象的翻譯方法,它以端到端的方式結合了一個新的注意模組和一個新的可學習的規範化函式。我們的模型根據輔助分類器獲得的注意圖,通過區分源域和目標域,引導翻譯關注更重要的區域而忽略次要區域。這些注意對映被嵌入到生成器和鑑別器中,以集中在語義上重要的區域,從而便於形狀轉換。而在生成器中的注意圖將焦點誘導到專門區分這兩個域的區域,而鑑別器中的注意對映通過聚焦目標域中真實影象和假影象的差異來幫助微調。除了注意機制外,我們還發現,對於形狀和紋理變化量不同的資料集,歸一化函式的選擇對轉換結果的質量有顯著影響。受批處理例項規範化(BIN)(Nam&Kim(2018))的啟發,我們提出了自適應層例項規範化(AdaLIN),該方法通過自適應選擇例項規範化(IN)和層規範化(LN)之間的比例,在訓練過程中從資料集學習引數。AdaLIN函式幫助我們的注意力引導模型靈活地控制形狀和紋理的變化量。不需要改變模型的整體形狀,也不需要改變模型的整體形狀。實驗結果表明,與現有的模型相比,本文提出的方法在風格轉換和物體變形方面都具有優勢。擬議工作的主要貢獻可概括如下:
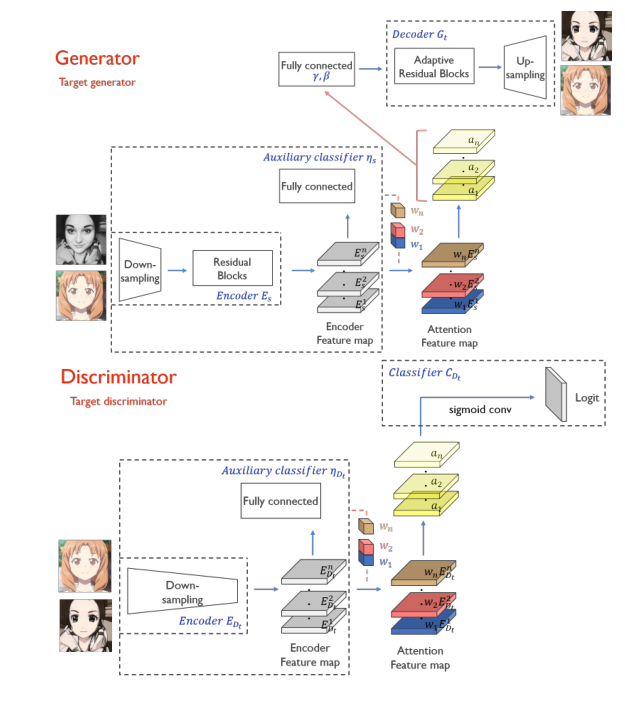
圖3.生成器和判別器工作流程
AdaLIN:
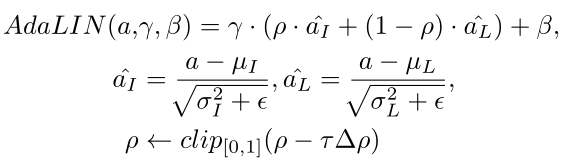
層級歸一化Layer Norm(LN),更多考慮特徵輸入通道之間的相關性,自適應例項級歸一化(IN)更多考慮的是單個特徵通道的內容,可以更好地儲存源影象的語義資訊,但是對於風格轉換不徹底。所以本論文將兩者相結合,並且做了很多實驗從實驗資料我們可以看到這種學習方法,證明實驗可用性。
Ateention:
圖三中我們可以分析出該神經網路的流程,首先經過一個編碼器獲得圖片特徵,編碼器由上取樣和殘差block結構組成,然後經過全連線層獲得一個預測E然後乘以權重之後經過attention之後的特徵圖經過解碼(dencoder)之後獲得最後的圖片。
資料驗證:
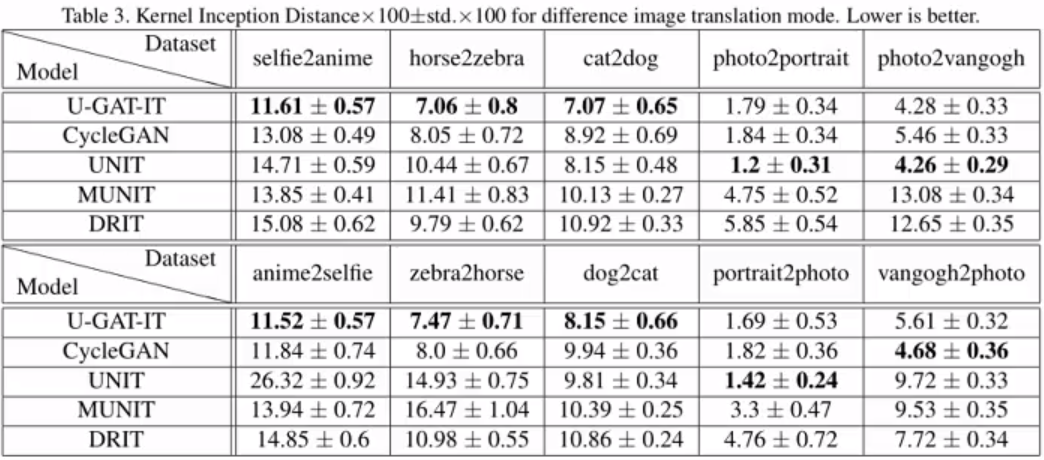
前置內容:
GAN的基本思想
納什均衡,也叫非合作博弈均衡。
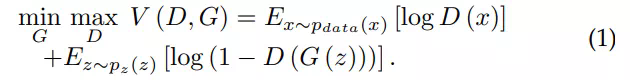
Pdata(x) = Pgen(x) ∀x
D(x) = 1/2 ∀x
理解起來就是生成器的生成圖片能夠讓判別器判別不出來為最終目的,通過一個數據樣本的潛在分佈生成一個新的資料樣本,這和VAE(變分自編碼器)是很相似的。
CycleGAN:
本篇論文應對cycleGAN有一個前置瞭解,本篇論文的網路結構基於cycleGAN
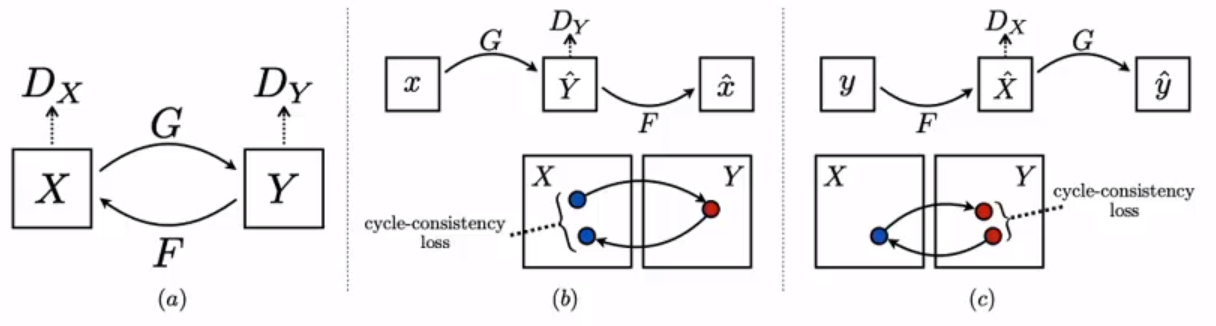
x生成y,y反迴圈給x,確保F(G(X))≈X。
實驗效果:


分析:
我們復現論文可以從以下幾點考慮
1. 該模型基於cycleGAN,所以應該對cycleGAN深入瞭解
2.關於attention以及AdaLIN自適應的使用
git:https://github.com/znxlwm/UGATIT-pytorch
參考出處:
李巨集毅GAN2018筆記 | GAN背後的數學理論
百度AI Studio論文精讀
&n