
[七夕特供版]:流年不利啊,才處理了執行緒死亡案件,這次更猛,程序連續死了好幾個
阿新 • • 發佈:2020-08-26
# 前言
前兩天發了一篇,關於執行緒神祕死亡的,過程也諸多波折,也很有意思。
結果就在昨天,又遇到一起程序死亡案件,容我給大家細細道來。
我們有一臺專門定製的,供市場人員進行產品展示和推銷的pc(配置是挺不錯,英特爾i7 * 8核,32g記憶體);這是一臺pc,裝的win10系統,市場人員要展示的時候,就開啟瀏覽器或者客戶端進行演示即可。
那後臺服務怎麼部署呢?我們是採用了Vmvare虛擬機器的方式;pc開機自動啟動Vmvare,自動啟動Vmvare中的虛擬機器;虛擬機器啟動時,通過systemd來啟動我們的n個基礎服務(redis、rabbitmq、mysql這類),和幾個微服務,為了簡單,都是做的單機部署。
微服務也不是很多,整體採用了spring cloud架構,一個eureka註冊中心,一個使用者管理中心,再加上1個業務微服務(之前的演示比較簡單,只演示核心功能,所以只需部署核心服務即可)。
我們怎麼做的呢,我們在`/usr/lib/systemd/system`下有個service:bootstrap.service。
```shell
[Unit]
Description=start all cad service
After=network.target redis.service fdfs_storaged.service fdfs_trackerd.service mysqld.service nginx.service rabbitmq-server.service
[Service]
// 1
ExecStart=/bin/bash -x /home/CAD_OneKeyDeploy/boot.sh
Type=forking
[Install]
WantedBy=multi-user.target
```
同時對這個service,設定成了開機啟動。
```shell
systemctl enable bootstrap.service
```
這個開機指令碼中,1處會去執行一個shell指令碼,我們看看這個指令碼的內容:
```shell
#!/bin/bash
echo "start to boot service"
// 啟動註冊中心
/bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart eureka
// 啟動使用者管理
/bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart scm
// 啟動核心業務服務
/bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart cad
netstat -nltp
jps -mlVv | grep -v "jps"
echo "boot service finished"
```
這個指令碼的邏輯很簡單,就是執行去`startup.sh`來順序啟動幾個服務,`startup.sh`的邏輯也比較簡單,就是根據引數來重啟對應的服務,重啟的邏輯就是,先停止服務,再啟動服務,啟動後,我們會呼叫如下url來檢測服務是否啟動成功:
```shell
// eureka服務對應的檢測url
curl -s localhost:8761/actuator/health
```
這個url,是spring boot的actuator自帶的,如果服務正常,那麼結果會是這樣的:
```shell
[root@localhost ~]#curl -s localhost:8761/actuator/health
{"status":"UP"}
```
簡單來說,我們重啟服務的邏輯很簡單:
1. 殺掉服務
2. 啟動服務
3. 60s內每s迴圈檢測url,檢視狀態是否為UP;如果超過60s,則列印錯誤日誌後退出本shell
之前,這個指令碼一直執行得挺好的,這次演示,說要加一些演示功能,於是我們更新了版本,也在boot.sh裡多加了2個要啟動的服務。
```shell
#!/bin/bash
echo "start to boot service"
/bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart eureka
/bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart scm
/bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart cad
// 這下邊,加了兩個服務
/bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart ccm
/bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart pas
netstat -nltp
jps -mlVv | grep -v "jps"
echo "boot service finished"
```
可以看到,我們加了兩個服務,ccm和pas,同時,scm、cad都更新了版本。
然後問題就來了,有一次我開機自啟動虛擬機器之後,就沒管了;其他組的同學,也部署了他們的服務在他們自己的虛擬機器上,要和我們聯動,跟我反饋說,我們的服務掛了。
我就上去看,一看發現eureka都沒有,然後趕時間嘛,直接進行了手工重啟,這個問題也就過了。
結果前兩天,另一位同事,負責上面新增的那個pas服務的,跟我說,也遇到了這個問題,他的描述更細緻一點:
```shell
虛擬機器開啟後,一開始用ps -ef都能看到啟動的程序,比如eureka,使用者中心慢慢都啟動起來了;但是,再過一陣,再執行ps -ef,發現一個java程序都沒有了。
最終的結果就是,一個程序都沒有啟動起來。
```
問題就是這麼個情況了,這個問題還是比較嚴重,萬一市場人員拿著去演示的時候,出這個事情,那問題就大發了!
手裡的bug它也不香了,還是優先處理這個bug吧!
# 排查過程
因為之前遇到過,因為第三方服務的ip地址發生了變化,我們這邊沒及時修改,導致服務啟動失敗的案例,我們優先排查了我們使用者中心服務的日誌。
發現確實又出現了第三方服務的ip發生變化了,我們這邊沒及時改,導致服務啟動的時候報錯了。
但是,仔細看了程式碼後,發現異常是捕獲了的,並不會導致使用者中心啟動失敗。
使用者中心的日誌裡顯示如下:
```shell
08-24 16:02:12.517 [main] INFO [] ScmApplication
-
Active Profile: dev
swagger-ui: http://127.0.0.1:9080/scm
---------------------------------------------------------- [ScmApplication.java:58]
08-24 16:02:28.913 [Thread-10] INFO [] o.s.c.n.e.serviceregistry.EurekaServiceRegistry
- Unregistering application SCM with eureka with status DOWN [EurekaServiceRegistry.java:65]
08-24 16:02:28.914 [Thread-10] WARN [] com.netflix.discovery.DiscoveryClient
- Saw local status change event StatusChangeEvent [timestamp=1598256148914, current=DOWN, previous=UP] [DiscoveryClient.java:1321]
```
請注意看第一行日誌的時間,是`16:02:12.517`,此時,列印的這行業務日誌是代表我們已經成功啟動了。
再看第二行日誌,是`16:02:28.913`,是Thread-10這個執行緒列印的,意思是說,向eureka取消註冊,修改狀態為down。
這中間過了16s,到底是為什麼就需要向eureka把服務取消註冊了呢?
檢視另外的核心業務服務的日誌,竟然發現:感覺日誌沒列印到日誌檔案,只有零星的幾行日誌。

我現在也沒想明白這個日誌為啥會這樣。
但是,我們還是有其他線索,啟動失敗後,我們檢視
`systemctl status bootstrap.service`,沒發現什麼大問題,就是說失敗了,因為沒截圖,我這裡只展示模擬的demo的結果圖:
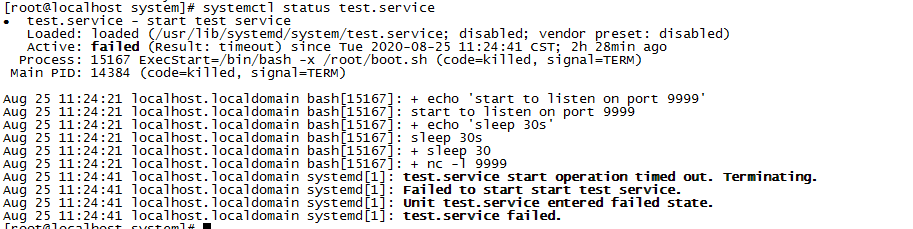
對於運維半桶水的我,也沒看出什麼線索,於是又去看journalctl日誌。
```shell
journalctl _SYSTEMD_UNIT=bootstrap.service
```
# journalctl日誌分析
由於我們嘗試過多次重啟,可能上文中的日誌時間和下面的不是配套的,但不影響具體問題的分析哈。
```shell
-- Logs begin at Mon 2020-08-24 16:39:30 CST, end at Tue 2020-08-25 10:40:56 CST. --
// 1
Aug 24 16:40:05 localhost.localdomain bash[14360]: + echo 'start to boot service'
Aug 24 16:40:05 localhost.localdomain bash[14360]: start to boot service
Aug 24 16:40:05 localhost.localdomain bash[14360]: + /bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart eureka
Aug 24 16:40:05 localhost.localdomain bash[14360]: +++ dirname /home/CAD_OneKeyDeploy/startup.sh
Aug 24 16:40:05 localhost.localdomain bash[14360]: ++ cd /home/CAD_OneKeyDeploy
...
```
執行上述的命令後,拿到的結果就是上面這樣的,1處,第一行日誌的時間為:
```shell
start 16:40:05
```
```shell
Aug 24 16:40:05 localhost.localdomain bash[14360]: + /bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart eureka
```
從上面的這一行可以看出,正在開始啟動eureka。
因為我已經把日誌檔案取回來了,我在本地搜尋了一下關鍵字:`startup.sh restart`
結果如下:
```shell
Aug 24 16:40:05 localhost.localdomain bash[14360]: + /bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart eureka
Aug 24 16:40:30 localhost.localdomain bash[14360]: + /bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart scm
Aug 24 16:41:25 localhost.localdomain bash[14360]: + /bin/bash -x /home/CAD_OneKeyDeploy/startup.sh restart cad
```
可以梳理出來:
```shell
16:40:05 eureka 開始啟動
16:40:30 使用者中心 開始啟動
16:41:25 業務系統cad 開始啟動
```
ok,現在是41:25的時候,開始啟動業務系統了,日誌也列印得很正常,直到:

可以看到,到41點35的時候,就已經開始看不懂了。
再到下邊的日誌,
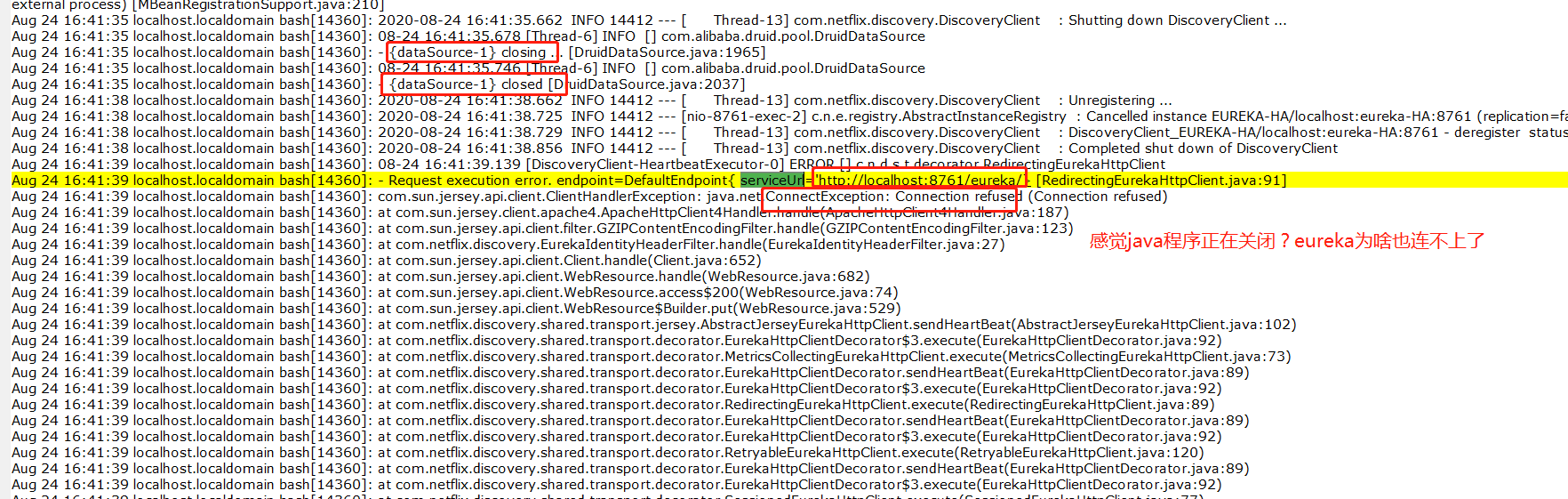
這邊就更暈了,eureka都關閉了?
# 柳暗花明
和同事盯著這個日誌看了半天,也沒看出個花來,後邊來了點靈感,看著那個時間,感覺有點巧合。
再來看看,開始時間:
```shell
start 16:40:05
出現異常的時間 16:41:35
```
算了下,好像剛好是90s?相差一個整數,看起來很像是一個配置項。
於是就開始在搜尋引擎裡查詢超時之類的關鍵字,然後就真的找到了這麼一個配置。
先是找到了一個預設配置項:
```shell
DefaultTimeoutStartSec=, DefaultTimeoutStopSec=, DefaultRestartSec=
設定啟動/停止一個單元所允許的最大時長, 以及在重啟一個單元時,停止與啟動之間的間隔時長。 若僅設定一個整數而沒有單位,那麼單位是秒。 也可以在整數後面加上時間單位字尾: "ms"(毫秒), "s"(秒), "min"(分鐘), "h"(小時), "d"(天), "w"(周) 。 DefaultTimeoutStartSec= 與 DefaultTimeoutStopSec= 的預設值都是 90s , 而 DefaultRestartSec= 的預設值是 100ms 。 對於 Type=oneshot 型別的 service 單元, 這些選項沒有意義(相當於全部被禁用)。 對於其他型別的 service 單元,可以在單元檔案中設定 TimeoutStartSec=, TimeoutStopSec=, RestartSec= 以覆蓋此處設定的預設值 (參見 systemd.service(5))。 對於其他非 service 型別的單元, DefaultTimeoutStartSec= 是 TimeoutSec= 的預設值。
```
引用自:
接下來,我找到了英文文件:
```shell
man 5 systemd-system.conf
```
```shell
DefaultTimeoutStartSec=, DefaultTimeoutStopSec=, DefaultRestartSec=
Configures the default timeouts for starting and stopping of units, as well as the default time to sleep between automatic restarts of units, as configured per-unit in TimeoutStartSec=, TimeoutStopSec= and RestartSec=
(for services, see systemd.service(5) for details on the per-unit settings). For non-service units, DefaultTimeoutStartSec= sets the default TimeoutSec= value.
```
既然都有預設值了,那肯定可以針對每個service單獨配置了,然後就又找到了如下選項:
```shell
man 5 systemd.service
TimeoutStartSec=
Configures the time to wait for start-up. If a daemon service does not signal start-up completion within the configured time, the service will be considered failed and will be shut down again. Takes a unit-less value in seconds, or a time span value such as "5min 20s". Pass "0" to disable the timeout logic. Defaults to DefaultTimeoutStartSec= from the manager configuration file, except when Type=oneshot is used, in which case the timeout is disabled by default (see systemd-system.conf(5)).
```
從這段話裡,我們就能找到這個問題的答案了:
```shell
TimeoutStartSec
配置服務啟動的最長等待時間。如果一個後臺服務沒有在指定時間內通知systemd,告知我們啟動完成的話,service會被認為是失敗了,將會被關閉。
單位為s,也可以手動指定單位,如"5min 20s"。
設定為0,則可以禁止超時的處理邏輯,相當於永不超時。預設值為DefaultTimeoutStartSec。
```
解決很簡單,把這個時間設定得很長就行了。

#結論
問題的原因就是這樣了,因為我們的指令碼的執行時間,超過了90s,雖然此時已經啟動了eureka,使用者中心,但是在執行業務微服務的過程中,超過了90s,導致systemd又主動關閉了eureka和使用者中心服務。
而我們再細看`systemctl status `時,終於知道什麼叫timeout了。
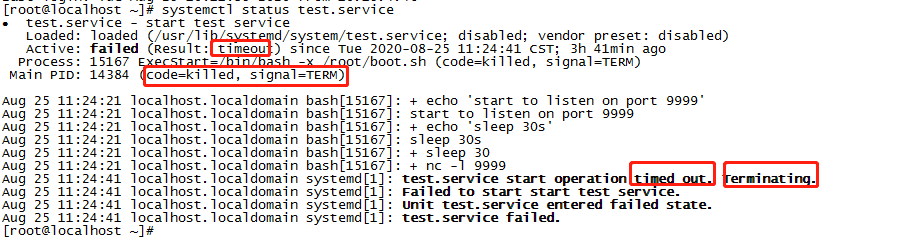
終於懂了,timeout,現在,看著這個詞,又有了一點新的理解。
# demo復現
我這邊實際弄了個demo,復現了一下。
## test.service
```shell
[Unit]
Description=start test service
After=network.target
[Service]
ExecStart=/bin/bash -x /root/boot.sh
Type=forking
TimeoutStartSec=20s
[Install]
WantedBy=multi-user.target
```
這個service會啟動一個shell,boot.sh。注意,超時為20s。
## boot.sh
```shell
#!/bin/bash
echo "start to listen on port 9999"
nc -l 9999 &
echo "sleep 30s"
sleep 30
echo "sleep over"
```
`nc -l 9999 &`會啟動一個程序,監聽9999埠。
然後我們的指令碼,睡眠了30s,這會導致超時。
超時後,按理來說,就會導致我們啟動的監聽9999埠的程序被殺掉。
## 測試開始
shell1上,啟動service:
```shell
[root@localhost ~]# systemctl restart test.service
```
shell2上,檢視9999埠的程序是否啟動:
```shell
[root@localhost system]# netstat -ntlp|grep 9999
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 18957/nc
tcp6 0 0 :::9999 :::* LISTEN 18957/nc
```
可以發現,已經啟動了。然後我們拿到這裡的18957這個pid。
開啟shell3,使用strace監聽18957這個程序的signal相關的活動,因為,按理來說,systemd超時後,會給18957傳送 sigterm 這個訊號量。
```shell
[root@localhost ~]# strace -e trace=signal -p 18957
strace: Process 18957 attached
--- SIGTERM {si_signo=SIGTERM, si_code=SI_USER, si_pid=1, si_uid=0} ---
+++ killed by SIGTERM +++
```
從上面看到,等待了一陣時間後,18957收到了systemd發來的`SIGTERM`訊號。
然後我們再切回shell1,看看結果:
```shell
[root@localhost ~]# systemctl restart test.service
Job for test.service failed because a timeout was exceeded. See "systemctl status test.service" and "journalctl -xe" for details.
```
檢視下status,test.service已經失敗了,原因是超時: 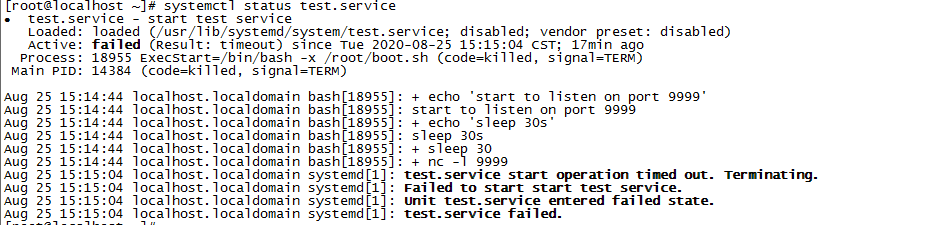
然後shell2中,再去檢視9999埠的程序是否還在:

ok,程序已死。
# 總結
好了,本案到這裡就算結了,其實根本原因在於,畢竟是個半桶水的運維,而不是運維大佬,linux裡面,還是很高深的,只能慢慢學了。
ok,我是逐日,一個混跡成都的Java後端程式猿,歡迎大家