
鷹眼:海量級分散式日誌系統上雲的架構和實踐
導語 | 鷹眼是由騰訊PCG技術運營部負責的海量級分散式實時監控和日誌分析系統,為響應公司戰略要求,將原先的業務遷移上雲,最終產生了可喜的變化。本文將介紹分散式日誌系統(鷹眼)的整體上雲方案,希望與大家一同交流。
一、鷹眼平臺介紹
鷹眼是由PCG技術運營部負責的海量級分散式實時監控和日誌分析系統,支援多語言的上報,域名為:http://log2.oa.com/
鷹眼的資料上報是通過ATTA提供的,ATTA支援多語言的上報(JAVA,Python,C++等),上報之後,鷹眼從ATTA系統拉取資料最終寫入到ES,通過ES的倒排索引機制,快速查詢功能,寫入功能等。
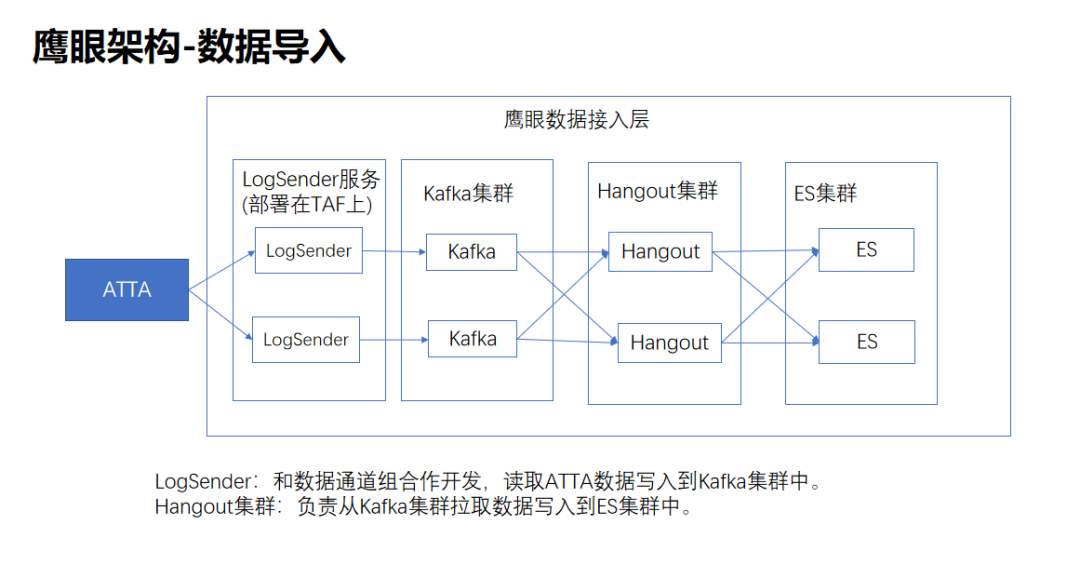
使用ES的倒排索引機制,百億資料秒級查詢返回的能力,鷹眼提供了以下功能:
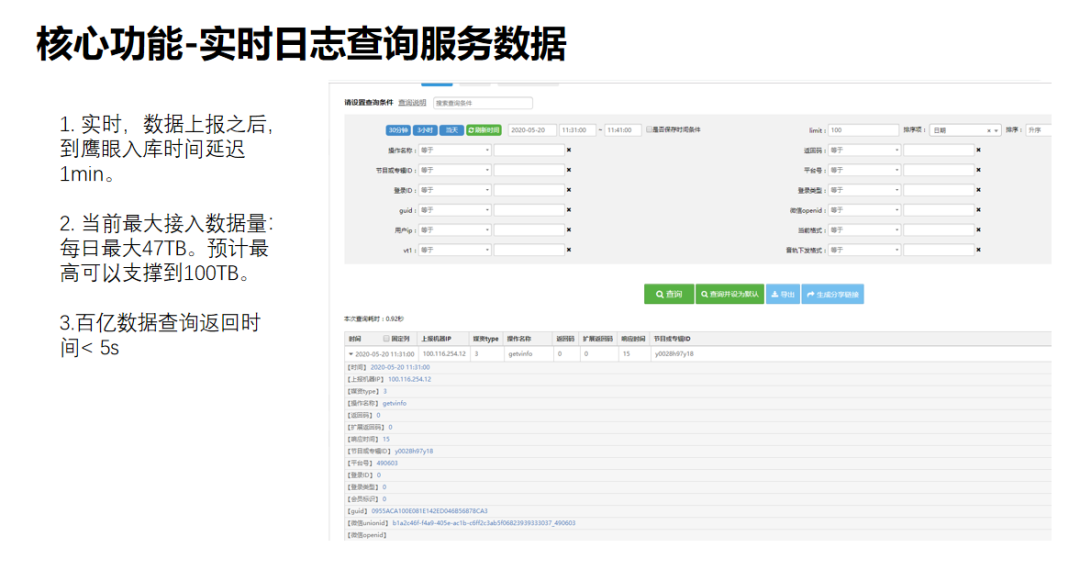
1. 實時日誌查詢服務資料
實時日誌查詢服務資料上報到ATTA之後,開發可以通過鷹眼及時查詢到日誌,定位問題,運維可以通過鷹眼提供的資料統計介面實時查詢到業務的執行情況。
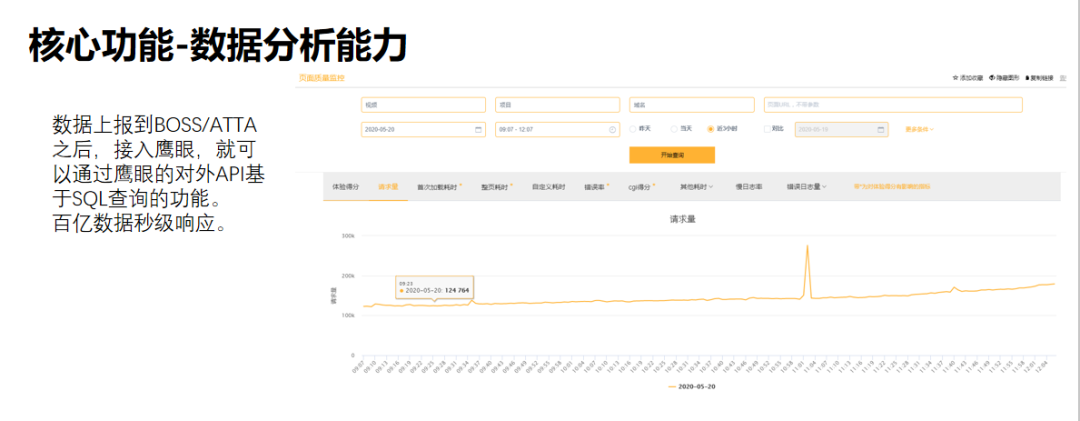
2. 資料分析能力
鷹眼資料入庫後,使用者可以通過API直接呼叫,進行OLAP分析。
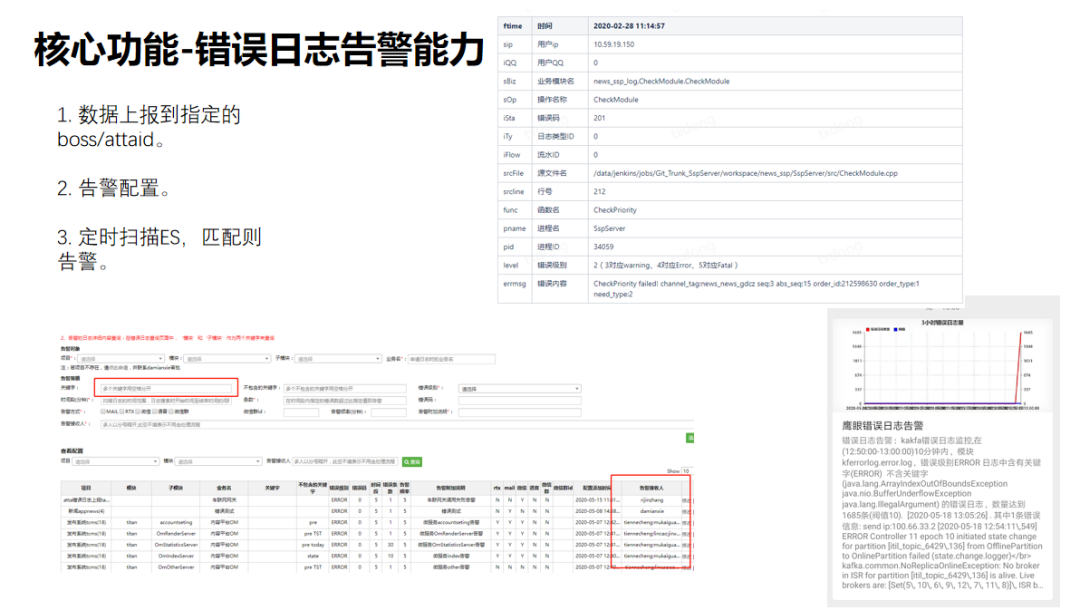
3. 錯誤日誌告警服務
程式如果出現錯誤之後,可以按照鷹眼規範來上報錯誤日誌,鷹眼進行分詞,根據不同的錯誤碼進行分鐘級別的告警。
4. grafana實時分析告警
通過grafana對上報到鷹眼的資料進行實時的分析告警。(由於ES不支援大併發查詢,所以無法對超大資料進行實時分析)
二、上雲的背景
公司戰略調整,成立新的雲事業群,內部成立“技術委員會”,啟動“開源協同”和“業務上雲”的兩大戰略方向。
在架構演進中,鷹眼團隊上雲能得到什麼好處?上雲的價值是什麼?
1. 業務價值
-
聚焦業務,提升研發效率 ;
-
加快技術換代,保持技術優勢(傳統網際網路 vs 雲時代);
-
使用更好的雲開源元件服務(可用性、穩定性、文件API…);
-
計算資源重用,彈性伸縮,優化成本 ;
-
標準化CI/CD流程。
2. 工程師價值
-
擴寬技術視野,避免閉門造車 ;
-
掌握的技能更有價值 ;
-
輸出優秀元件到雲,提高影響力。
3. 騰訊雲價值
-
為客戶輸出業務上雲經驗 ;
-
幫助騰訊雲打磨雲元件。
三、元件上雲架構選型
為了保證業務的延續性和架構的演進,資料匯入過程中的主體流程並沒有太大改變,Kafka直接使用到雲上的CKAFKA,ES直接使用到雲上的ES。

ES和Kafka直接使用雲上元件,其他元件需要進行重構。
1. 重構LogSender
生產者程式寫入Kafka效能瓶頸特別大,高峰期丟資料特別嚴重。
生產者程式寫資料流程:讀取BOSS訂閱->IP解析->寫入Kafka。
(1)IP解析效能瓶頸
之前生產者程式是C++版本,經過列印日誌,發現高峰期IP解析耗時特別嚴重。排查程式碼,發現IP解析加鎖了。所以高峰期丟資料特別嚴重。解決方法是:將IP解析改為二分查詢演算法來進行IP定位,然後取消鎖,解決。
(2)Kafka效能瓶頸問題
由於我們生產者程式,一個程式會讀取很多很多個topic,然後寫入到Kafka,我們嘗試,使用一個producer和多個producer傳送,效能都提升不起來。
經過原始碼排查,發現Kafka傳送時,會根據topic分割槽來鎖佇列,當這個佇列滿的時候,就會發送一批訊息出去。所以解決方案為,每個BOSSID應該有獨立的傳送客戶端。
-
資料量大的,有多個Kafka客戶端
-
資料量小的一批topic,可以共用一個kafka生產者。
優化之後:在資料量非常大的時候,因為程式效能原因,會導致一分鐘單節點最多隻能處理13萬條左右的資料。改進後, 單節點能處理55w條左右的資料。 效能提升4倍。
2. Kafka選型
Kafka整體來說,高版本比低版本支援的功能更多,如事務,磁碟間的資料轉移等,寫入效能並不會下降。此處選型選的是最高版本。
當然CKAFKA並沒有給我們選擇版本的機會,客戶端寫入的時候還是得注意下和Kafka服務端版本一致,避免不必要的問題。
如低版本的客戶端寫入高版本的Kafka時,如果使用資料壓縮,則服務端接受到資料後,會進行解壓,然後再按照對應的格式壓縮(如果版本一致,則不會有此動作),增加服務端的執行成本。
Kafka上雲之後,單機效能能達到400MB/s,而我們自建的Kafka,單機效能最多達到100MB/s,效能提升4倍。
3. 重構Hangout
ES寫入部分,業界有很多元件,最出名的是Logstach,由於效能不夠,我們自己重新開發了一套讀取Kafka寫入ES的元件。
核心優化點如下所示:

由於磁碟IO的大幅減少,能在極限優化下繼續提升效能2倍以上。整體來說,ES寫入提升效能6倍左右。
4. ES選型
ES低版本支援TCP寫入和HTTP寫入兩種方式,高版本只支援一種HTTP寫入方式。實測發現有如下區別:
-
TCP寫入比HTTP更快;
-
HTTP寫入更穩定一點,TCP寫入是直接寫到節點上面的,容易出現負載不均衡,HTTP更容易通過資料節點節點進行負載均衡。
因此我們採用了雲版本ES 6.8.2。
上雲之後的效果:
-
平均寫入1TB資料,雲下需要 80核,256G記憶體 12TB磁碟 (BX1機型);
-
雲上需要 3 * (16核 64GB 5TB硬碟 );
-
平均節省資源1倍左右。
四、上雲之後的變化
ES/Kafka上雲之後,統計有50多個ES叢集,12個Kafka叢集.
1. 工作量的減少
如果不上雲的話,搭建這些叢集平均一個ES叢集需要20臺機器,從申請機器,到機器初始化,磁碟RAID,安裝ES,平均每個ES需要3-4人/天,則搭建成本就已經需要200多人(62*3-4)/天了,還沒有談到叢集運維成本,遠遠超過鷹眼團隊的人力。
2. 成本的減少
上雲之後,伴隨著各個元件的優化,整體效能提升至少2-3倍,所需要的資源同比會減少2-3倍、每年節省成本至少2kw。
3. 工作更加聚焦
上雲之後:
-
鷹眼聚焦於寫入效能優化,大大提升了寫入效率;
-
監控體系的建立,資料上報到ATTA之後,就進行資料對賬,及時發現數據的延遲給出告警;
-
在新功能開發上,基於ES支援隔天查詢,如果當日資料暴漲之後,通過建立備份索引的機制增大寫入量。
五、後續架構演進
1. 監控體系建設
核心模組既要有日誌,也要有監控,不同模組的監控維度對應起來,讓核心的模組,日誌和監控都有,當業務出現異常時,及時調出發生異常的基礎資料(如CPU/Mem等),指標資料,日誌資料等進行完整的監控體系的建設。
2. 架構持續升級
目前自研Hangout寫入只能保證at least once,但是無法保證exactly once。嘗試通過flink的checkpoint機制,保證資料鏈路的完整