
二分查詢及其變種演算法
阿新 • • 發佈:2020-09-15
[TOC]
## 前言
**概念**:二分查詢(Binary Search)演算法,一種針對有序資料集合的查詢演算法,也叫折半查詢演算法。
**思想**:二分查詢針對的是一個**有序的資料集合**( 升序或降序 ),查詢思想有點類似分治思想。每次都通過跟區間的中間元素對比,將待查詢的區間縮小為之前的一半,直到找到要查詢的元素,或者區間被縮小為 0
**步驟:** 定義 `low`,`high`,`mid`指標,分別指向首尾中間 3 個位置,`value` 是我們要查詢的值
進行如下演算法
(1)當`arr[mid] = value` 時,找到則返回 `mid`下標
(2)當`arr[mid] < value `時,說明目標元素在經由`mid`分割的右區間,故將區間起始位置 `low ` 賦值為`mid+1`
(3)當`arr[mid] > value `時,說明目標元素在經由`mid`分割的左區間,故將區間結束位置 `high ` 賦值為`mid-1`
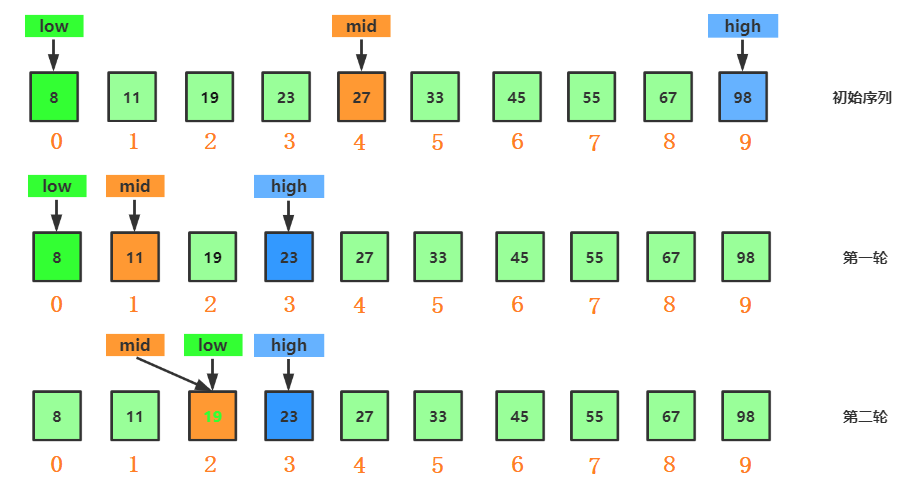
**圖解:**
以有序集合` {8,11,19,23,27,33,45,55,67,98}`為例,以查詢值 `value = 19`進行分析
## 複雜度分析
假設資料規模是 n,每一輪查詢資料規模都會縮小一半,也就是會除以2。最好的情況就是,在初始化就找到,最壞情況下,直到查詢區間被縮小為空,才停止。
查詢的區間變化是 —— $n$、$\frac{n}{2}$、$\frac{n}{4}$、$\frac{n}{8}$、... 、$\frac{n}{2^k}$, 可以看出來,這是一個等比數列。其中 $\frac{n}{2^k}$ = $1$ 時, k 的值就是總共縮小的次數。而每一次縮小操作只涉及兩個資料的大小比較,所以,經過了 k 次區間縮小操作,時間複雜度就是 O(k)。通過 $\frac{n}{2^k}$ = $1$ ,我們可以求得 $k$ = $\log_2n$,所以時間複雜度就是 O(logn)
優點:高效的二分查詢,擁有驚人的查詢速度,因為 logn 是一個非常“恐怖”的數量級,即便 n 非常非常大,對應的 logn 也很小。比如 n 等於 2 的 32 次方,這個數很大了吧?大約是 42 億。也就是說,如果我們在 42 億個資料中用二分查詢一個數據,最多需要比較 32 次
## 編碼
### 常規
**迭代法實現**
```java
/**
* 迭代法實現
* @param arr
* @param value
* @return
*/
public static int binarySerach1(int[] arr, int value) {
//頭部指標
int low = 0;
//尾部指標
int high = arr.length - 1;
while (low <= high){
int mid = low + ((high - low) >> 1);
if (arr[mid] == value){
return mid;
}else if (arr[mid] > value){
high = mid - 1;
}else {
low = mid + 1;
}
}
return -1;
}
```
**注意點:**
+ 迴圈退出條件:注意是 low <= high,而不是 low < high
+ mid 的取值問題:
+ `mid =( low + high)/2 `這種寫法是有問題的。因為如果 low 和 high 比較大的話,兩者之和就有可能會溢位
+ 改進的方法是將 mid 的計算方式寫成 `low + (high - low)/2`
+ 將除法運算改為位運算,因為相比除法運算來說,計算機處理位運算要快得多
**遞迴法實現**
```java
/**
* 遞迴法
* @param arr
* @param value
* @return
*/
public static int binarySerach2(int[] arr, int value){
return bsearch(arr,0,arr.length -1,value);
}
private static int bsearch(int[] arr, int low, int high, int value) {
if (low > high) return -1;
int mid = low + ((high - low) >> 1);
if (arr[mid] == value) {
return mid;
} else if (arr[mid] > value) {
return bsearch(arr, low, mid-1, value);
} else {
return bsearch(arr, mid+1, high, value);
}
}
```
### 變種
**1、查詢第一個值等於給定值的元素**
上面實現的二分查詢演算法實比較簡單的需求,是有一定侷限性的,例如,它是預設元素是不重複的。那麼,假設有序結合是存在重複元素的,那麼用上面的演算法來解決肯定是有問題的。以有序陣列`{1,3,4,5,6,8,8,8,11,18}`,其中,a[5],a[6],a[7] 的值都等於 8,是重複的資料。我們希望查詢第一個等於 8 的資料,也就是下標是 5 的元素。配圖如下:

**編碼:**
```java
public static int binarySerach3(int[] arr, int value) {
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else if (arr[mid] < value) {
low = mid + 1;
} else {
if ((mid == 0) || (arr[mid - 1] != value)) return mid;
else high = mid - 1;
}
}
return -1;
}
```
重點:從第11行程式碼才是演算法的重點,前面的程式碼和之前的思路是一樣的,在第11行程式碼開始就不同了,我們的需求是查詢第一個值等於給定值的元素,那麼只要注意兩個地方就可以了
+ `mid == 0`,這說明找到的值是陣列下標 0 位置的值,也就是起點位置,那麼肯定就是第一個值了
+ 如果`mid`前一位的值不是要匹配的`value`,那麼說明找到的就是第一個值,否則,`high`指向`mid - 1`,重新比較
**2、查詢最後一個值等於給定值的元素**
還是以有序陣列`{1,3,4,5,6,8,8,8,11,18}`,其中,a[5],a[6],a[7] 的值都等於 8,是重複的資料。我們希望查詢最後個等於 8 的資料,也就是下標是 7 的元素。
**編碼:**
```java
/**
* 查詢最後一個值等於給定值的元素
* @param arr
* @param value
* @return
*/
public static int binarySerach4(int[] arr, int value) {
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else if (arr[mid] < value) {
low = mid + 1;
} else {
if ((mid == arr.length - 1) || (arr[mid + 1] != value)) return mid;
else high = mid + 1;
}
}
return -1;
}
```
這個變種的案例與第一個很相似,稍微修改一下第11行後邊的程式碼條件即可,不做詳細分析
**3、查詢第一個大於等於給定值的元素**
我們再來看另外一類變形問題。在有序陣列中,查詢第一個大於等於給定值的元素。比如,陣列中儲存的這樣一個序列:`{3,4,6,7,10}`,如果查詢第一個大於等於 5 的元素,那就是 6。
**編碼:**
```java
/**
* 變種三: 查詢第一個大於等於給定值的元素
* @param arr
* @param value
* @return
*/
public static int binarySerach3(int[] arr, int value) {
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] >= value) {
if ((mid == 0) || (arr[mid - 1] < value)) return mid;
else high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
}
```
重點:該變種也是尋找的第一個的值,同變種一的查詢邏輯是一樣的,只是將匹配值`value`改成查詢比比值`value`大的,將`arr[mid] >= value`統一處理
**4、查詢最後一個小於等於給定值的元素**
仍然以有效序列`{3,4,6,7,10}`為例,查詢最後一個小於等於給定值的元素,如果給定值是5,那查詢處理的就是就是 4。
```java
/**
* 變種四: 查詢第一個大於等於給定值的元素
* @param arr
* @param value
* @return
*/
public static int binarySerach4(int[] arr, int value) {
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else {
if ((mid == arr.length - 1) || (arr[mid + 1] > value)) return mid;
else low = mid + 1;
}
}
return -1;
}
```
思路和上面的大致一樣,就不作分析了
## 侷限性
二分查詢的時間複雜度是 O(logn),查詢資料的效率非常高。不過,並不是什麼情況下都可以用二分查詢,它的應用場景是有很大侷限性的。那什麼情況下適合用二分查詢,什麼情況下不適合呢?
**1、二分查詢依賴的是順序表結構,簡單點說就是陣列**
那二分查詢能否依賴其他資料結構呢?比如連結串列。答案是不可以的,主要原因是二分查詢演算法需要按照下標隨機訪問元素。我們在陣列和連結串列那兩節講過,陣列按照下標隨機訪問資料的時間複雜度是 O(1),而連結串列隨機訪問的時間複雜度是 O(n)。所以,如果資料使用連結串列儲存,二分查詢的時間複雜就會變得很高。
**2、二分查詢針對的是有序資料**
二分查詢對這一點的要求比較苛刻,資料必須是有序的。如果資料沒有序,我們需要先排序。排序的時間複雜度最低是 O(nlogn)。所以,如果我們針對的是一組靜態的資料,沒有頻繁地插入、刪除,我們可以進行一次排序,多次二分查詢。這樣排序的成本可被均攤,二分查詢的邊際成本就會比較低。
所以,二分查詢只能用在插入、刪除操作不頻繁,一次排序多次查詢的場景中。針對動態變化的資料集合,二分查詢將不再適用。
**3、資料量太小不適合二分查詢。**
如果要處理的資料量很小,完全沒有必要用二分查詢,順序遍歷就足夠了。比如我們在一個大小為 10 的陣列中查詢一個元素,不管用二分查詢還是順序遍歷,查詢速度都差不多。只有資料量比較大的時候,二分查詢的優勢才會比較明顯。
不過,這裡有一個例外。如果資料之間的比較操作非常耗時,不管資料量大小,我都推薦使用二分查詢。比如,陣列中儲存的都是長度超過 300 的字串,如此長的兩個字串之間比對大小,就會非常耗時。我們需要儘可能地減少比較次數,而比較次數的減少會大大提高效能,這個時候二分查詢就比順序遍歷更有優勢。
**4、資料量太大也不適合二分查詢。**
二分查詢的底層需要依賴陣列這種資料結構,而陣列為了支援隨機訪問的特性,要求記憶體空間連續,對記憶體的要求比較苛刻。比如,我們有 1GB 大小的資料,如果希望用陣列來儲存,那就需要 1GB 的連續記憶體空間。
注意這裡的“連續”二字,也就是說,即便有 2GB 的記憶體空間剩餘,但是如果這剩餘的 2GB 記憶體空間都是零散的,沒有連續的 1GB 大小的記憶體空間,那照樣無法申請一個 1GB 大小的陣列。而我們的二分查詢是作用在陣列這種資料結構之上的,所以太大的資料用陣列儲存就比較吃力了,也就不能用二分查找了。
## 宣告
**參考資料:**王爭 —[《資料結構與演算法之美》](https://time.geekbang.org/column/intro/100017301?utm_source=web&utm_medium=pinpaizhuanqu&utm_campaign=baidu&utm_term=pinpaizhuanqu&utm_content=0427) 、 [排序的最低時間複雜度為什麼是O(nlogn)](https://blog.csdn.net/micx0124/article/details/9852289)
**文章為原創,歡迎轉載,註明出處即可**
**個人能力有限,有不正確的地方,還請指正**
**本文的程式碼已上傳`github`,歡迎star —— [GitHub地址](https://github.com/kaltons/Java-Algor