
【雲原生下離線上混部實踐系列】深入淺出 Google Borg
阿新 • • 發佈:2020-09-24
Google Borg 是資源排程管理和離線上混部領域的鼻祖,同時也是 Kubernetes 的起源與參照,已成為從業人員首要學習的典範。本文嘗試管中窺豹,簡單從《Large-scale cluster management at Google with Borg》一文中剖析 Google Borg 的設計理念和功能特點,用以拋磚引玉。
## Google Borg 是什麼?
Google Borg 是 Google 內部自研的一套資源管理系統,用於叢集資源管控、分配和排程等。在 Borg 中,資源的單位是 Job 和 Task。Job 包含一組 Task。Task 是 Borg 管理和排程的最小單元,它對應一組 Linux 程序。熟悉 Kubernetes 的讀者,可以將 Job 和 Task 大致對應為 Kubernetes 的 Service 和 Pod。
在架構上,Borg 和 Kubernetes 類似,由 BorgMaster、Scheduler 和 Borglet 組成。
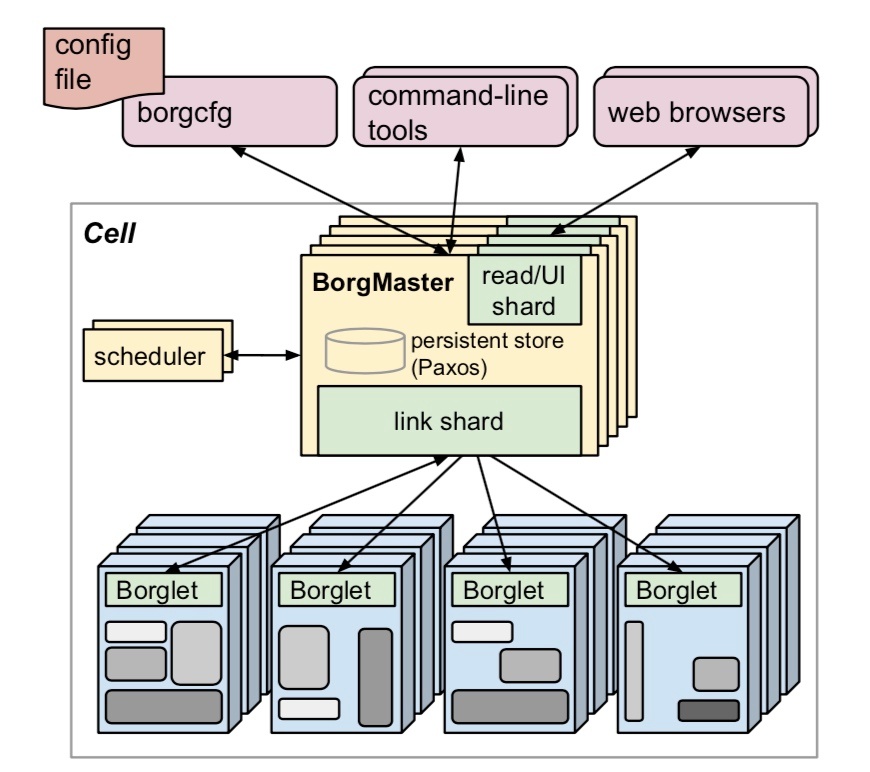
## Borg Allocs
**Borg Alloc 代表一組可用於執行 Task 的資源**,如 CPU、記憶體、IO 和磁碟空間。它實際上是叢集對物理資源的抽象。Alloc set 類似 Job,是一堆 Alloc 的集合。當一個 Alloc set 被建立時,一個或多個 Job 就可以執行在上面了。
## Priority 和 Quota
每個 Job 都可以設定 Priority。**Priority 可用於標識 Job 的重要程度,並影響一些資源分配、排程和 Preemption 策略。**比如在生產中,我們會將作業分為 Routine Job 和 Batch Job。Routine Job 為生產級的例行作業,優先順序最高,它佔用對應實際物理資源的 Alloc set。Batch Job 代表一些臨時作業,優先順序最低。當資源緊張時,叢集會優先 Preempt Batch Job,將資源提供給 Routine Job 使用。這時 Preempted Batch Job 會回到排程佇列等待重新排程。
**Quota 代表資源配額,它約束 Job 的可用資源,比如 CPU、記憶體或磁碟**。Quota 一般在排程之前進行檢查。Job 若不滿足,會立即在提交時被拒絕。生產中,我們一般依據實際物理資源配置 Routine Job Quota。這種方式可以確保 Routine Job 在 Quota 內一定有可用的資源。為了充分提升叢集資源使用率,我們會將 Batch Job Quota 設定為無限,讓它儘量去佔用 Routine Job 的閒置資源,從而實現超賣。這方面內容後面會在再次詳述。
## Schedule
**排程是資源管理系統的核心功能,它直接決定了系統的“好壞”。**在 Borg 中,Job 被提交後,Borgmaster 會將其放入一個 Pending Queue。Scheduler 非同步地掃描佇列,將 Task 排程到有充足資源的機器上。
通常情況下,排程過程分為兩個步驟:Filter 和 Score。
- Filter,或是 Feasibility Checking,用於判斷機器是否滿足 Task 的約束和限制,比如 Schedule Preference、Affinity 或 Resource Limit。
- Filter 結束後,就需要 Score 符合要求的機器,或稱為 Weight。上述兩個步驟完成後,Scheduler 就會挑選相應數量的機器排程給 Task 執行。實際上,選擇合適的排程策略尤為重要。
這裡可以拿一個我們生產遇到的排程問題舉例。
生產初期,我們的排程系統採用的 Score 策略類似 Borg E-PVM,它的作用是將 Task 儘量均勻的排程到整個叢集上。從正面效果上講,這種策略分散了 Task 負載,並在一定程度上縮小了故障域。但從反面看,它也引發了資源碎片化的問題。由於我們底層環境是異構的,機器配置並不統一,並且 Task 配置和物理配置並無對應關係。**這就造成一些配置過大的 Task 無法執行,由此在一定程度上降低了資源的分配率和使用率。**
**為了應付此類問題,我們自研了新的 Score 策略,稱之為 “Best Fillup”。**它的原理是在排程 Task 時選擇可用資源最少的機器,也就是儘量填滿。不過這種策略的缺點顯而易見:單臺機器的負載會升高,從而增加 Bursty Load 的風險;不利於 Batch Job 執行;故障域會增加。
**本篇論文作者採用了一種被稱為 hybrid 的方式,據稱比第一種策略增加 3-5% 的效率。**
## Utilization
**資源管理系統的首要目標是提高資源使用率**,Borg 亦是如此。不過由於過多的前置條件,諸如 Job 放置約束、負載尖峰、多樣的機器配置和 Batch Job,導致不能僅選擇 “average utilization” 作為策略指標。在Borg中,使用Cell Compaction 作為評判基準。簡述之就是:能承載給定負載的最小 Cell。
Borg 提供了一些提高 utilization 的思路和實踐方法,有些是我們在生產中已經採用的,有些則非常值得我們學習和借鑑。
### Cell Sharing
Borg 發現,將各種優先順序的 Task,比如 prod 和 non-prod 執行在共享的 Cell 中可以大幅度的提升資源利用率。
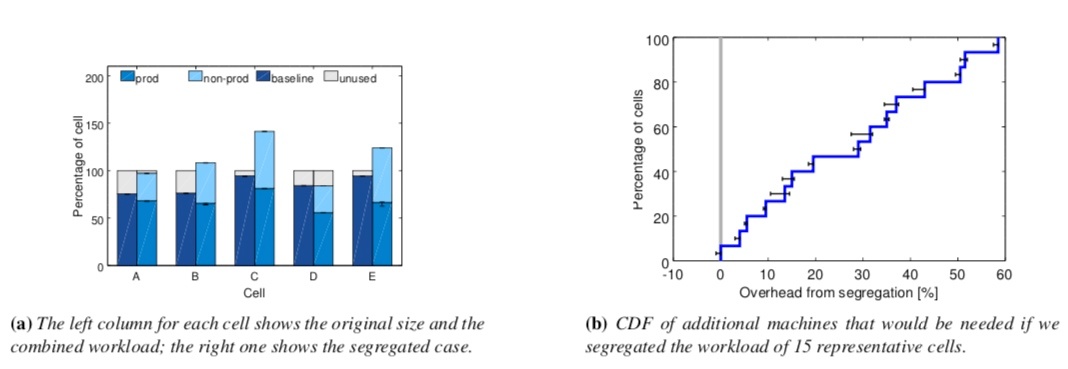
上面(a)圖表明,採用 Task 隔離的部署方式會增加對機器的需求。圖(b)是對額外機器需求的分佈函式。圖(a)和圖(b)都清楚的表明了將 prod Job 和 non-prod Job 分開部署會消耗更多的物理資源。Borg 的經驗是大約會新增 20-30% 左右。
箇中原理也很好理解:prod Job 通常會為應對負載尖峰申請較大資源,實際上這部分資源在多數時間裡是閒置的。Borg 會定時回收這部分資源,並將之分配給 non-prod Job 使用。在 Kubernetes 中,對應的概念是 request limit 和 limit。我們在生產中,一般設定 Prod Job 的 Request limit 等於 limit,這樣它就具有了最高的 Guaranteed Qos。該 QoS 使得 pod 在機器負載高時不至於被驅逐和 OOM。non-prod Job 則不設定 request limit 和 limit,這使得它具有 BestEffort 級別的 QoS。kubelet 會在資源負載高時優先驅逐此類 Pod。這樣也達到了和 Borg 類似的效果。
### Large cells
**Borg 通過實驗資料表明,小容量的 cell 通常比大容量的更佔用物理資源。**
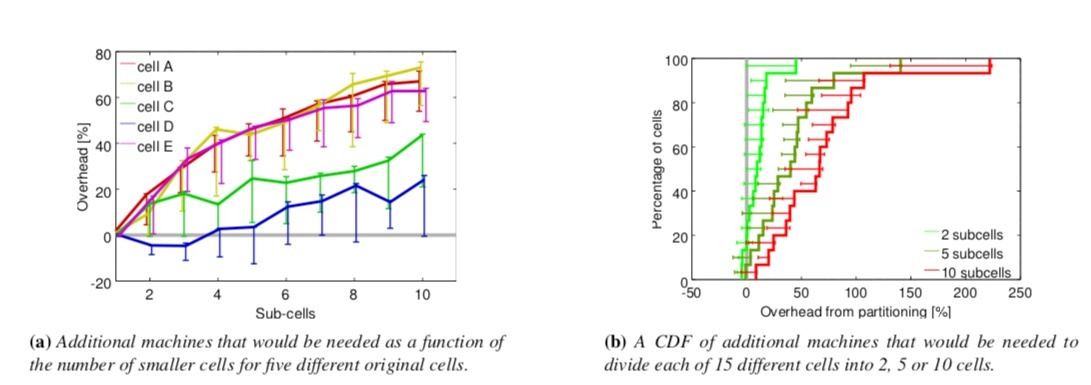
這點對我們有很重要的指導意義。通常情況下,我們會在設計叢集時對容量問題感到猶豫不決。
顯而易見,小叢集可以帶來更高的隔離性、更小的故障域以及潛在風險。但隨之帶來的則是管理和架構複雜度的增加,以及更多的故障點。
大叢集的優缺點正好相反。在資源利用率這個指標上,我們憑直覺認為是大叢集更優,但苦於無堅實的理論依據。Borg 的研究表明,大叢集有利於增加資源利用率,這點對我們的決策很有幫助。
### Fine-grained resource requests
Borg 對資源細粒度分配的方法,目前已是主流,在此就不再贅述。
### Resource reclamation
瞭解 Kubernetes 的讀者,應該對 resource request 和 limit,在 Google Borg 中概念類似。Job 在提交時需要指定 resource limit,它能確保內部的 Task 有足夠資源可以執行。
有些使用者會為 Task 申請過大的資源,以應對可能的請求或計算的突增。但實際上,部分資源在多數時間內是閒置的。與其資源浪費,不如利用起來。這需要系統有較精確的預測機制,可以評估 Task 對實際資源的需求,並將閒置資源回收以分配給低 priority 的任務,比如 Batch Job。
上述過程在 Borg 中被稱為 resource reclamation,對使用資源的評估則被稱為 reservation。Borgmaster 會定期從 Borglet 收集 resource consumption,並執行 reservation。在初始階段,reservation 等於 resource limit。隨著 Task 的執行,reservation 就變為了資源的實際使用量,外加 safety margin。
在 Borg 排程時,Scheduler 使用 resource limit 為 prod Task 過濾和選擇主機,這個過程並不依賴 reclaimed resource。從這個角度看,並不支援對 prod Task 的資源超賣。但 non-prod Task 則不同,它是佔用已有 Task 的 resource reservation。所以 non-prod Task 會被排程到擁有 reclaimed resource 的機器上。
這種做法當然也是有一定風險的。若資源評估出現偏差,機器上的可用資源可能會被耗盡。在這種情況下,Borg 會殺死或者降級 non-prod Task,prod Task 則不會受到任何影響。
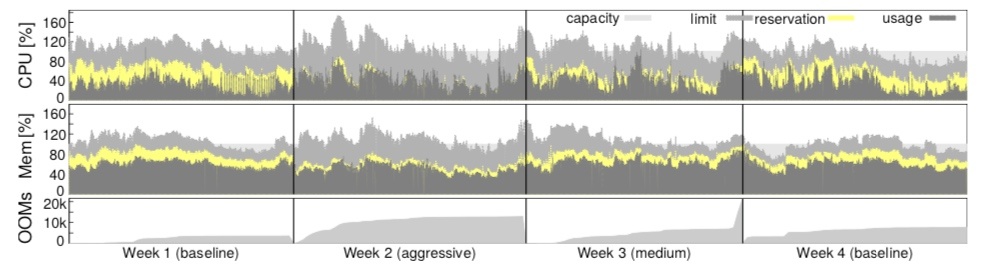
上圖證實了這種策略的有效性。參照 Week 1 和 4 的 baseline,Week 2 和 3 在調整了 estimation algorithm 後,實際資源的 usage 與 reservation 的 gap 在顯著縮小。在 Borg 的一個 median cell 中,有 20% 的負載是執行在 reclaimed resource 上。
相較於 Borg,Kubernetes 雖然有 resource limit 和 capacity 的概念,但卻缺少動態 reclaim 機制。這會使得系統對低 priority Task 的資源缺少行之有效的評估機制,從而引發系統負載問題。這個功能對資源排程和提升資源使用率影響巨大。
## Isolation
由於 Google Borg 天生就考慮混部場景,所以資源隔離對其尤為重要。在內部場景,Google Borg 多使用 Linux 隔離,比如 chroot、cgroup 等,類似容器隔離機制。公有云側,Google Borg 則通過 VM 或沙箱技術實現 Task 間的強隔離。
在效能隔離方面,Google Borg 通過區分應用優先順序的方式保證服務質量。latency-sensitive(LS) 高優任務擁有高的資源保證,Batch 低優任務佔用資源則會根據需要被抑制。
在叢集資源方面,Google Borg 將之分為可壓縮和不可壓縮資源。與流速相關的資源,諸如 CPU、磁碟 IO 等,被定義為可壓縮資源。這部分資源若被耗盡,Borglet 會首先降級處理低優任務,而不是直接殺死。這種做法能最大程度保證低優任務服務質量。不可壓縮資源,包括記憶體、磁碟空間等,在資源緊張時,任務會被按照優先順序從低到高殺死,直到緊張情況緩解。
在核心層面,Google Borg 同樣有策略保證資源隔離與複用。比如 LS 任務可獨享物理 CPU 核心,其他 LS 任務不可複用。Batch 任務能共用這部分 CPU,通過設定低 cpus_share 的方式與 LS 任務隔離。Borget 也會週期性的調整 LS 任務,以避免 Batch 任務被餓死。為了支援高敏任務,Google Borg 對 CFS 做了增強,使之可根據 cgroup 負載預測提前搶佔 Batch 任務,從而降低 CFS 排程延遲。
## 總結
離線上混合部署是一套複雜的系統和技術,需要從方法論、業務、應用、資源排程系統、作業系統等多個層面的實現和配合,並且也需要長期的實戰和經驗積累。Google Borg 作為 Google 內部的經驗結晶,系統的闡述了混部應有的基本形態,很有啟發意義。**目前我們在騰訊內部也開發和上線了一套基於 Kubernetes 的離線上混合部署系統,支援動態資源預測、資源回收和核心級隔離。**後續會持續分享混部相關的理論和實戰經驗。
## 參考資料
1. Large-scale cluster management at Google with Borg:https://iwiki.oa.tencent.com/images/43438.pdfThe
2. evolution of cluster scheduler architecture:http://www.firmament.io/blog/scheduler-architectures.html
3. poseidon:https://github.com/kubernetes-sigs/poseidonPoseidon
4. design:https://docs.google.com/document/d/1VNoaw1GoRK-yop_Oqzn7wZhxMxvN3pdNjuaICjXLarA/edit?usp=sharing
5. firemament:https://github.com/camsas/firmament
>【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多幹貨!!
![](https://img2020.cnblogs.com/other/2041406/202009/2041406-20200924094529401-135490