
【大資料】科普一下大資料的那些事兒
阿新 • • 發佈:2020-10-22
*最近一直沒更新,不是因為懶,而是要學的東西太多了,時間全用來學大資料的技術棧了,見諒。*
言歸正傳,這篇科普文章就給大家講講大資料的技術棧和生態圈,讓大資料不再神祕!
## 何謂**大資料**?
大資料的Wiki英文引文中的解釋如下:
> The tools, processes and procedures allowing an organization to create, manipulate, and manage very large data sets and storage facilities.
> 允許組織去建立,操縱和管理巨量資料集和儲存設施的工具,過程和程式。
因此,從廣義上來說,大資料是一個抽象的概念,它包含了巨量資料本身以及處理它所需要的工具、過程以及程式。從狹義上說,大資料就是各種來源結構化和非結構化的資料集合,通常這種資料集合造成傳統軟體在可接受的時間內進行資料處理的能力。
隨著時間的推移,資料的單位增長隨著軟硬體的不斷進步,而呈現出指數倍的增長,在氣象學、基因組學、神經網路體學、複雜的物理模擬、生物及環境研究、金融、電商等各個領域,資料的體量已經大到傳統的軟體程式對其進行分析處理的時間無法承受,也許可能計算一次大氣模擬需要一個月之久才能得到結果,但得到的結果的時候已經失去了其本身計算的意義。
截止2012年,全世界每天產生2.5EB(1EB=1000PB=1000000TB=1000000000GB)的資料,採用傳統的軟體處理資料已經是窮途末路,大資料技術的產生是大勢所趨。
## 大資料的特點
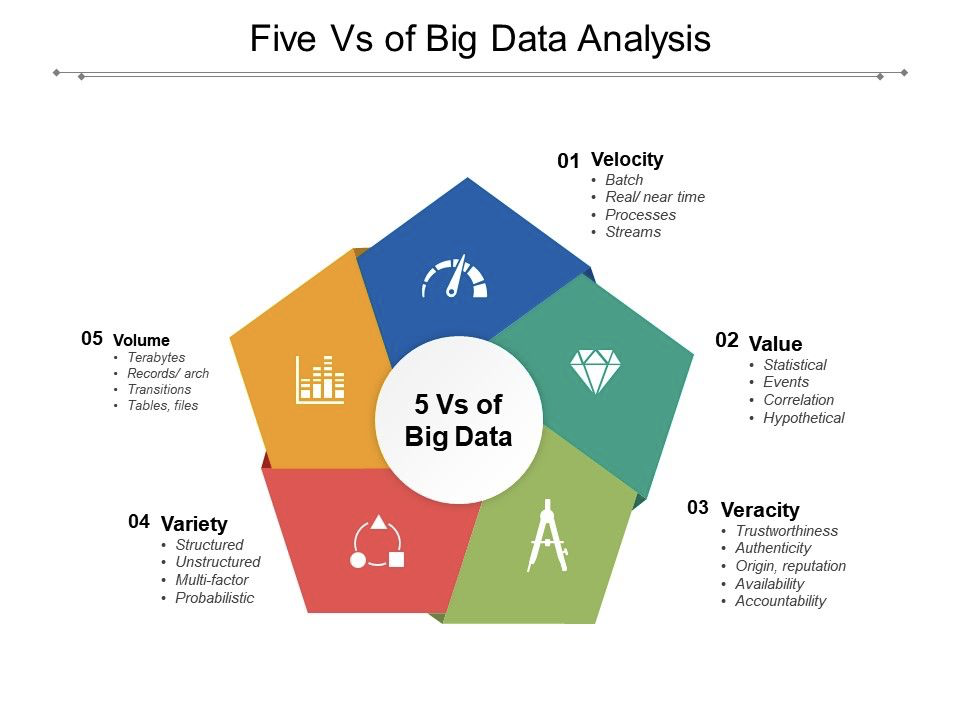
大資料的特點可以使用5個V來介紹,分別是Velocity、Value、Veracity、Variety、Volume。
* **Velocity(速度)**:大資料的產生速度是非常迅速的,圖中也介紹了這個特性中的幾個要點,分別是批量化產生、近乎實時的要求、處理速度快、以及支援流式處理操作。可以想象,如果一個公司的搜尋引擎不能近乎實時且精準地返回使用者想要查詢的結果,那麼這家公司一定會被市場淘汰掉。
* **Value(價值)**:資料的增加並不代表資料的價值增加,在一般的情況下,資料價值的密度較低,這是一個沙裡淘金的過程。如何採用合適的演算法模型來對資料進行分析、挖掘,尋找資料中的價值是未來相當長的一段時間內學界、業界需要共同努力的事情。
* **Veracity(真實性)**:這裡指的是資料的可信度。一般而言,大資料需要確保獲得的資料具有真實性的意義,否則一切都是無意義的徒勞。
* **Variety(種類)**:大資料的種類和來源是多樣化的,其中包括結構化、半結構化和非結構化的資料,具體表現有文字資料、音視訊資料、圖片、地理位置資料等等。多型別的資料對目標企業或機構的資料的處理能力就提出了更高的要求。
* **Volume(體量)**:毋庸置疑,大資料的資料體量是非常龐大的,通常意義上來說,一次計算的體量至少都應該是GB級別,大多數都是TB級別,有的甚至在PB、EB。
## 大資料的技術棧
從業務流的角度進行分析,大資料的技術棧的功能主要針對資料提供:採集、清洗、儲存、查詢、計算、視覺化等功能。針對這些功能,各個技術機構針對自己的業務需求,開發了可用的框架,目前這些技術框架有很多,我們可以看下面這張圖,來巨集觀感受一下。

不要被嚇到,這裡的所有技術並不會要求你全部搞定,一般的大資料從業人員也只需要會每隔小部分中最重要的一個或幾個技術就夠了。在眾多的技術中,最讓人熟悉的莫過於Hadoop技術生態圈裡的內容了,因此我首先來介紹一下有關Hadoop的技術生態圈,讓大家瞭解Hadoop的各種技術之間是怎麼進行協同工作的。
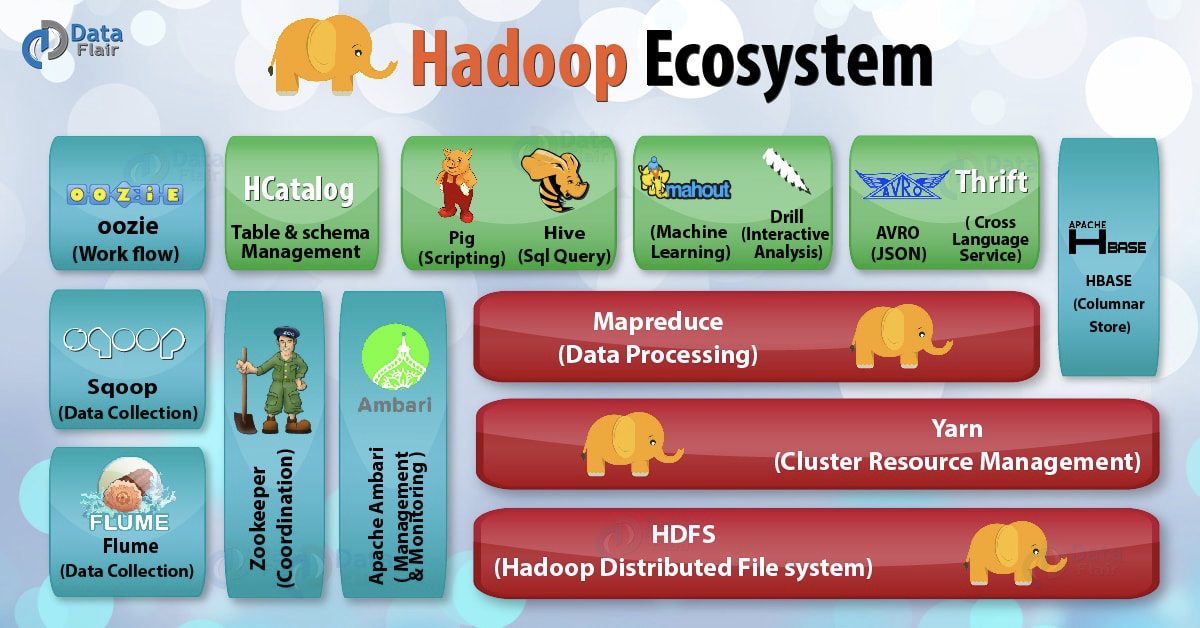
上圖是一個Hadoop的技術生態圈,裡面包括了Hadoop全部的技術棧,各個技術都充當了整個大資料處理流程中的某個特定角色,下面我來挨著解釋一下。
1、**HDFS**
HDFS,全稱為Hadoop Distributed File System,叫做Hadoop分散式檔案系統。它是Hadoop生態系統中最重要的元件。 HDFS是Hadoop的主要儲存系統。 Hadoop分散式檔案系統(HDFS)是基於Java的檔案系統,可為大資料提供可伸縮、容錯、可靠且經濟高效的資料儲存。 HDFS是在商用硬體上執行的分散式檔案系統。它支援通過類似shell的命令的直接互動。HDFS其內部有兩個最重要的元件,分別是NameNode和DataNode。
NameNode,不儲存實際的資料而是對檔案系統內的元資料進行管理,比如資料塊資訊、資料分佈的存放節點與位置、DataNode節點的資料存放細節等,在同一個叢集中,此元件要求只能有一個處於工作狀態。
DataNode,負責在HDFS中儲存實際資料。DataNode根據客戶端的請求執行讀取和寫入操作。DataNode的副本塊由檔案系統上的2個檔案組成。第一個檔案用於資料,第二個檔案用於記錄塊的元資料。在啟動時,每個DataNode連線到其相應的NameNode並進行握手。名稱空間ID和DataNode的軟體版本的驗證通過握手進行。發現不匹配時,DataNode自動關閉。DataNode根據NameNode的指令執行諸如塊副本建立,刪除和複製之類的操作。
2、**Mapreduce**
Hadoop MapReduce是提供資料處理的核心Hadoop生態系統元件。MapReduce是一個大資料計算框架,用於處理Hadoop分散式檔案系統中儲存的大量結構化和非結構化資料的計算應用程式。MapReduce程式本質上是並行的,因此對於使用叢集中的多臺計算機執行大規模資料分析非常有用。因此,它提高了叢集並行處理的速度和可靠性。
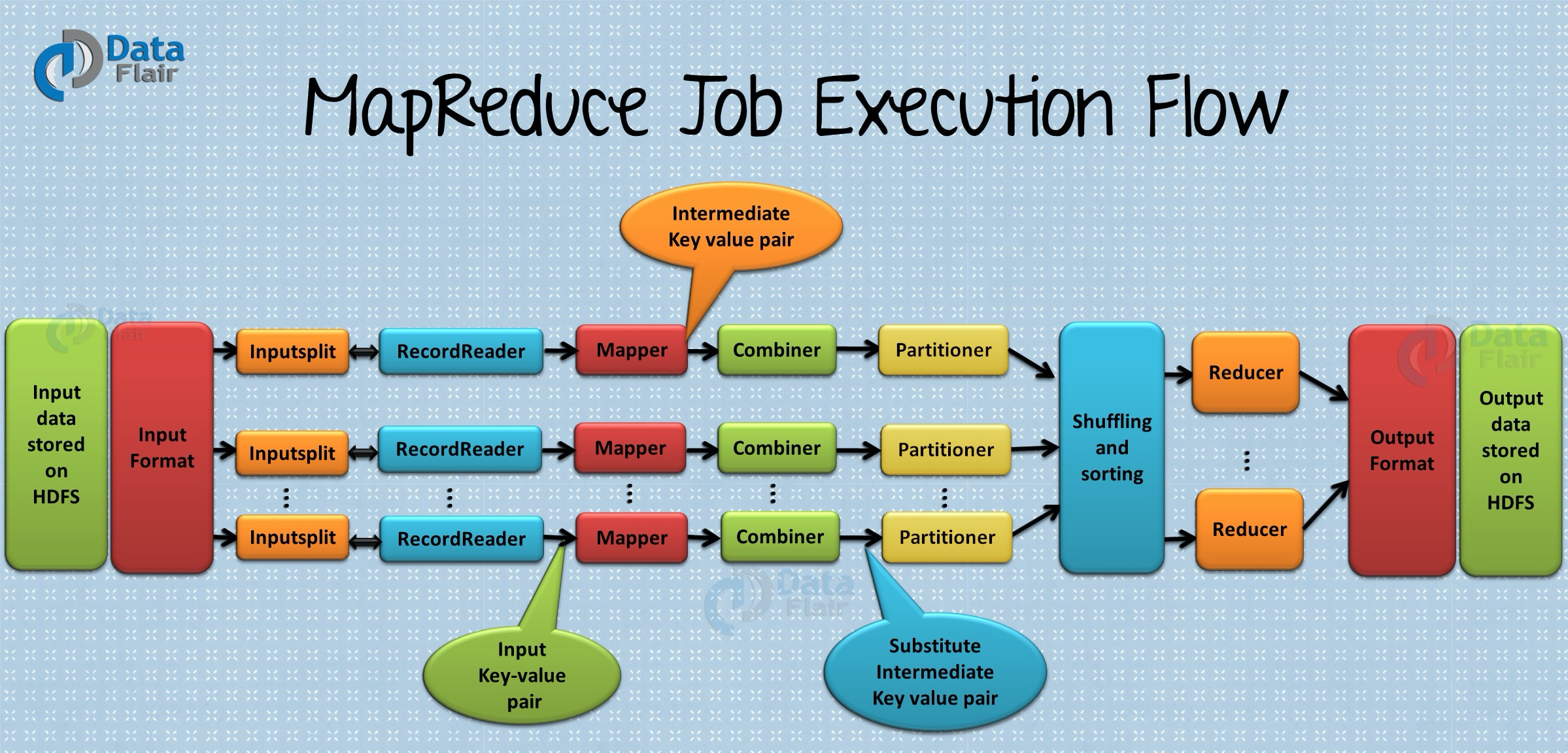
在MapReduce中,有兩個階段,分別是Map階段和Reduce階段。每個階段都有鍵值對作為輸入和輸出。Map函式獲取一組資料並將其轉換為另一組資料,其中個元素分解為元組(鍵值對)。Reduce函式將Map的輸出作為輸入,並根據鍵組合這些資料元組,並相應地修改鍵的值。
該框架擁有執行處理PB級資料的能力,以及快速、高容錯性等特點,是Hadoop生態圈中很重要的技術框架。
3、**YARN**
Hadoop Yarn(Yet Another Resource Negotiator),是提供資源管理的Hadoop生態系統元件。Yarn也是Hadoop生態系統中最重要的元件之一。 YARN被稱為Hadoop的作業系統,因為它負責管理和監視工作負載。它允許多個數據處理引擎(例如實時流和批處理)處理儲存在單個平臺上的資料。
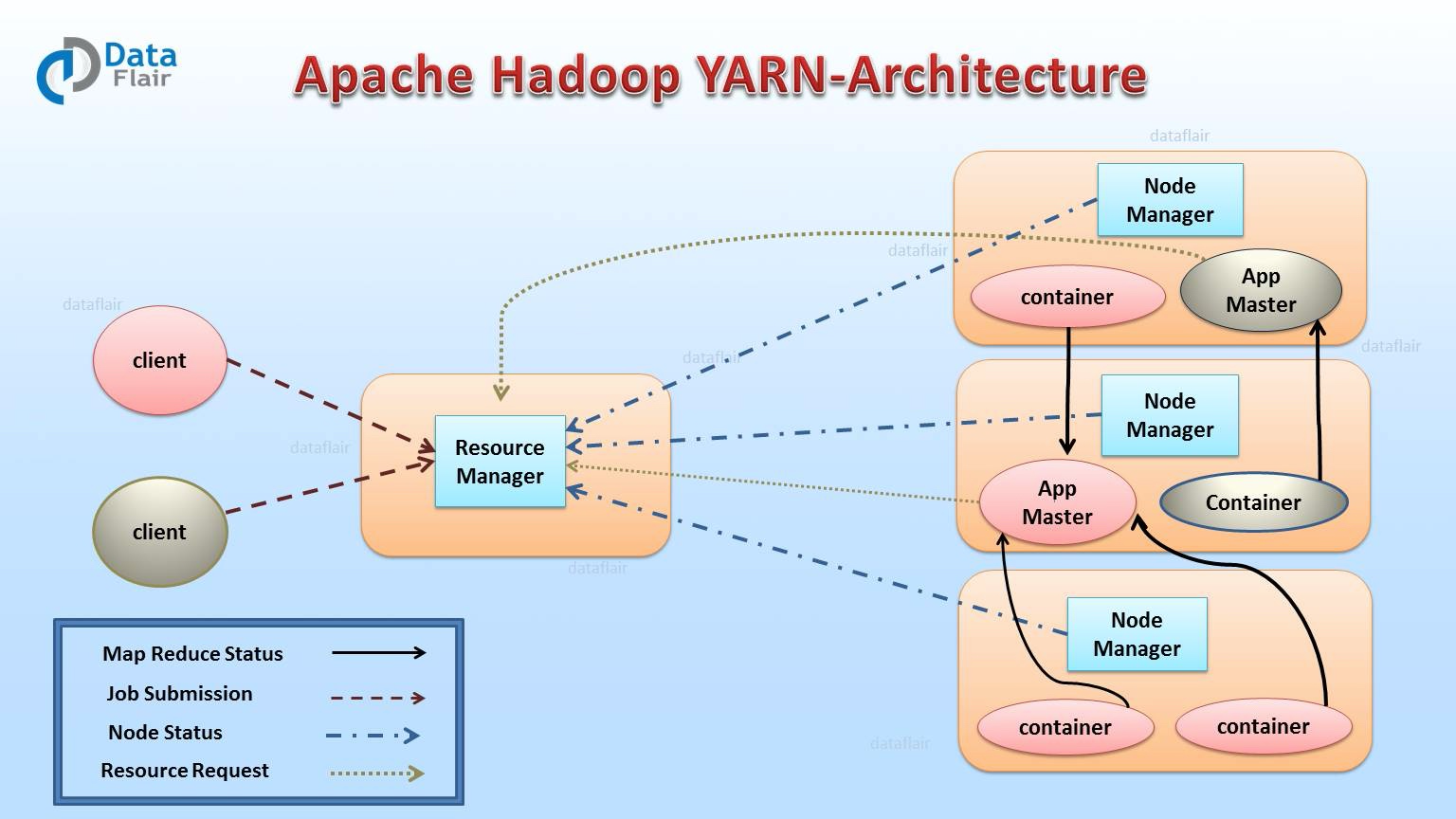
Yarn具有靈活性的特點,除了可以用於批處理計算框架,比如MapReduce外,還可以用於其他模式的資料處理,比如互動式和流式處理模式。由於這個優勢,其他的計算框架也可以在Yarn的資源排程下,與MapReduce程式一起執行,提高了Hadoop叢集的服務效率。另外,Yarn還具有高共享性的特點,在多個工作負載之間提供穩定、可靠、安全的共享操作服務,所以在對於資料處理的過程中,可以使用其他的程式設計模型,比如圖形處理模型或迭代模型等。
4、**ZooKeeper**
Apache Zookeeper是Hadoop生態系統的重要元件,提供了分散式應用程式的協調服務,它是一個為分散式應用提供一致性服務的軟體,包括阿配置維護、域名服務、分散式同步、組服務等。
Zookeeper的特性有以下幾個方面:
* **順序一致性**,從同一個客戶端發起的事務請求,最終將會嚴格地按照其發起順序被應用到Zookeeper中去。
* **原子性**,所有事務請求的處理結果在整個叢集中所有機器上的應用情況是一致的,即整個叢集要麼都成功應用了某個事務,要麼都沒有應用。
* **單一檢視**,無論客戶端連線的是哪個 Zookeeper 伺服器,其看到的服務端資料模型都是一致的。
* **可靠性**,一旦服務端成功地應用了一個事務,並完成對客戶端的響應,那麼該事務所引起的服務端狀態變更將會一直被保留,除非有另一個事務對其進行了變更。
* **實時性**,Zookeeper 保證在一定的時間段內,客戶端最終一定能夠從服務端上讀取到最新的資料狀態。
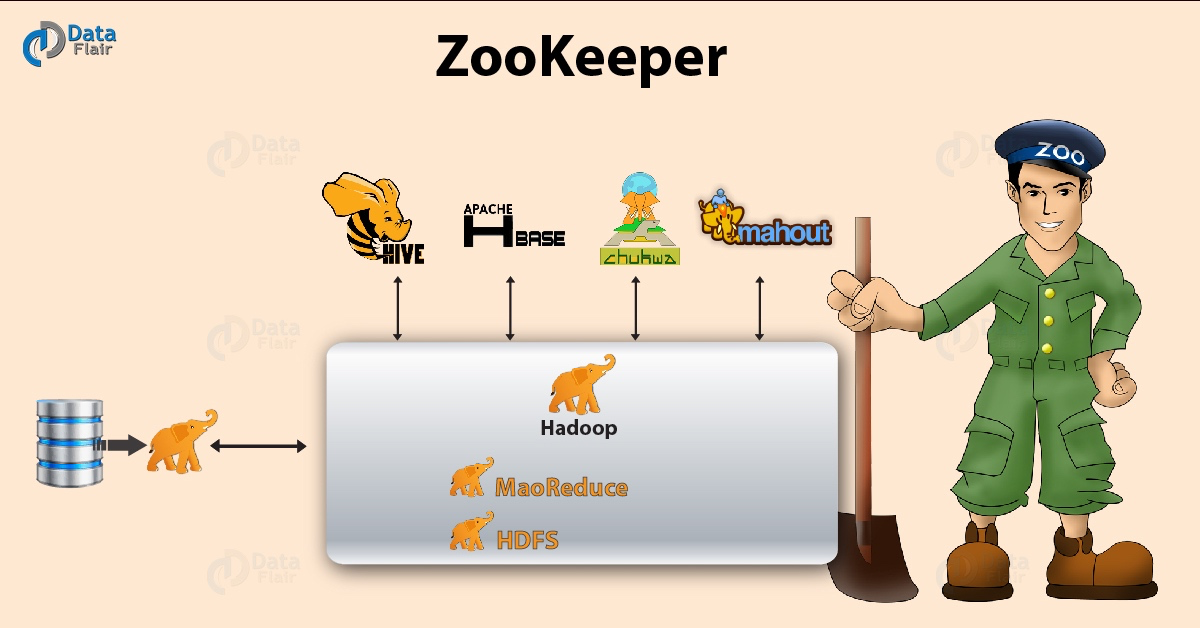
這個技術的出現,在總體上解決了我們所說的拜占庭將軍問題,也就是分散式系統中最大的難題,即協調一致的問題。當然,順便提一句,在分散式系統領域,有一篇很重要的論文,名字叫做[《Paxos Made Simple》](https://lamport.azurewebsites.net/pubs/paxos-simple.pdf),有興趣各位可以讀一下。
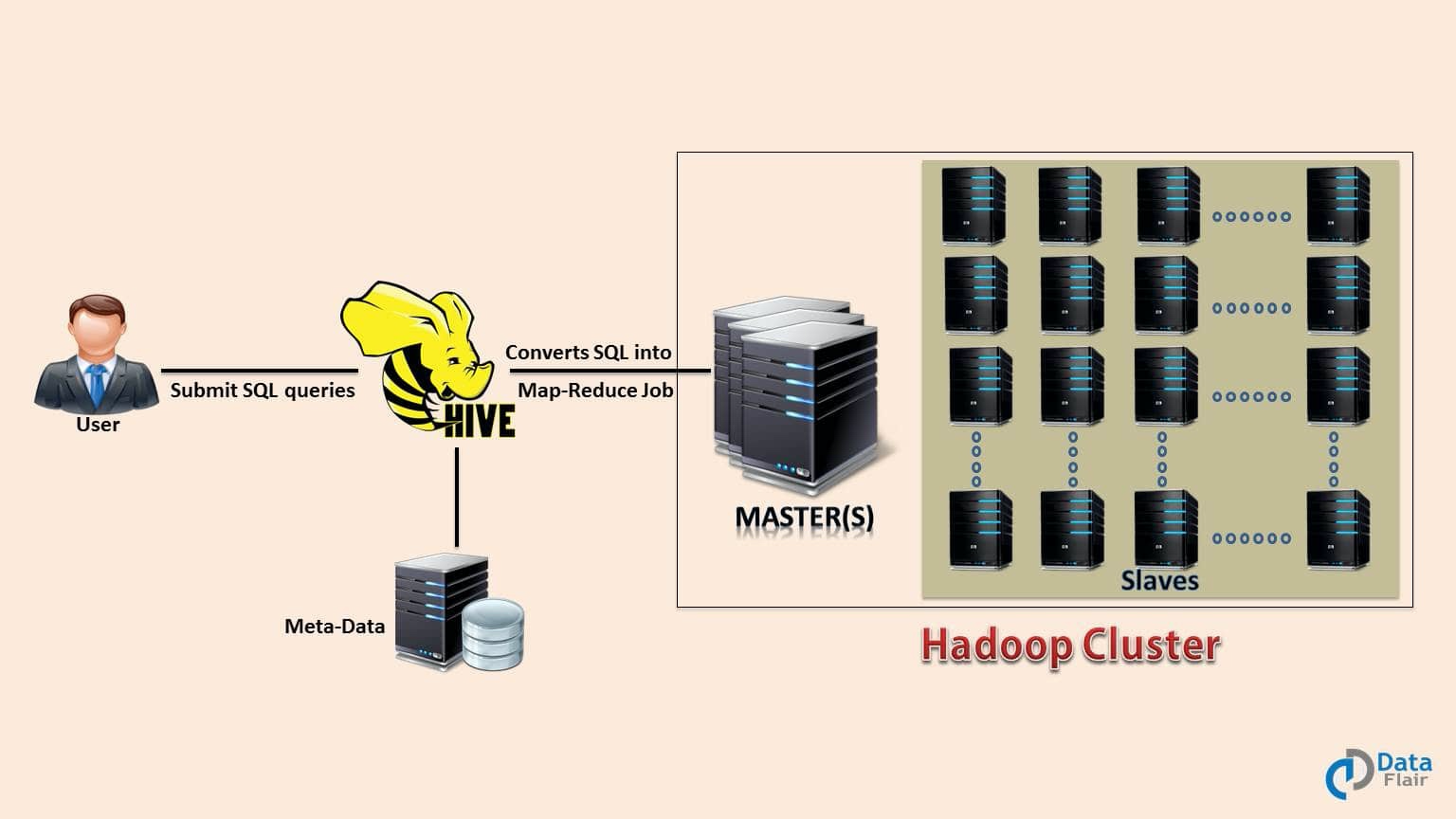
5、**Hive**
Apache Hive是一個開源資料倉庫系統,是一個數據分析框架,其用於查詢和分析儲存在Hadoop檔案中的大型資料集。Hive具有三個主要功能:資料彙總,查詢和分析。Hive使用稱為HiveQL(HQL)的語言,與SQL相似。 HiveQL自動將類似SQL的查詢轉換為MapReduce作業,該作業將在Hadoop上執行。簡而言之,Hive就是在Hadoop上架了一層SQL介面,可以將SQL翻譯成MapReduce去Hadoop上執行,這樣就使得資料開發和分析人員很方便的使用SQL來完成海量資料的統計和分析。
6、**Pig(目前用的很少了)**
Apache Pig是用於分析和查詢HDFS中儲存的巨大資料集的高階語言平臺。Pig作為Hadoop生態系統的組成部分,使用PigLatin語言。它與SQL非常相似。它載入資料,應用所需的過濾器並以所需格式轉儲資料。為了執行程式,Pig需要Java執行時環境。
7、**HBase**
Apache HBase是Hadoop生態系統元件,它是一個分散式資料庫,旨在將結構化資料儲存在可能具有數十億行和數百萬列的表中。 HBase是基於HDFS構建的可擴充套件,分散式和NoSQL資料庫。 HBase,提供對HDFS中讀取或寫入資料的實時訪問。
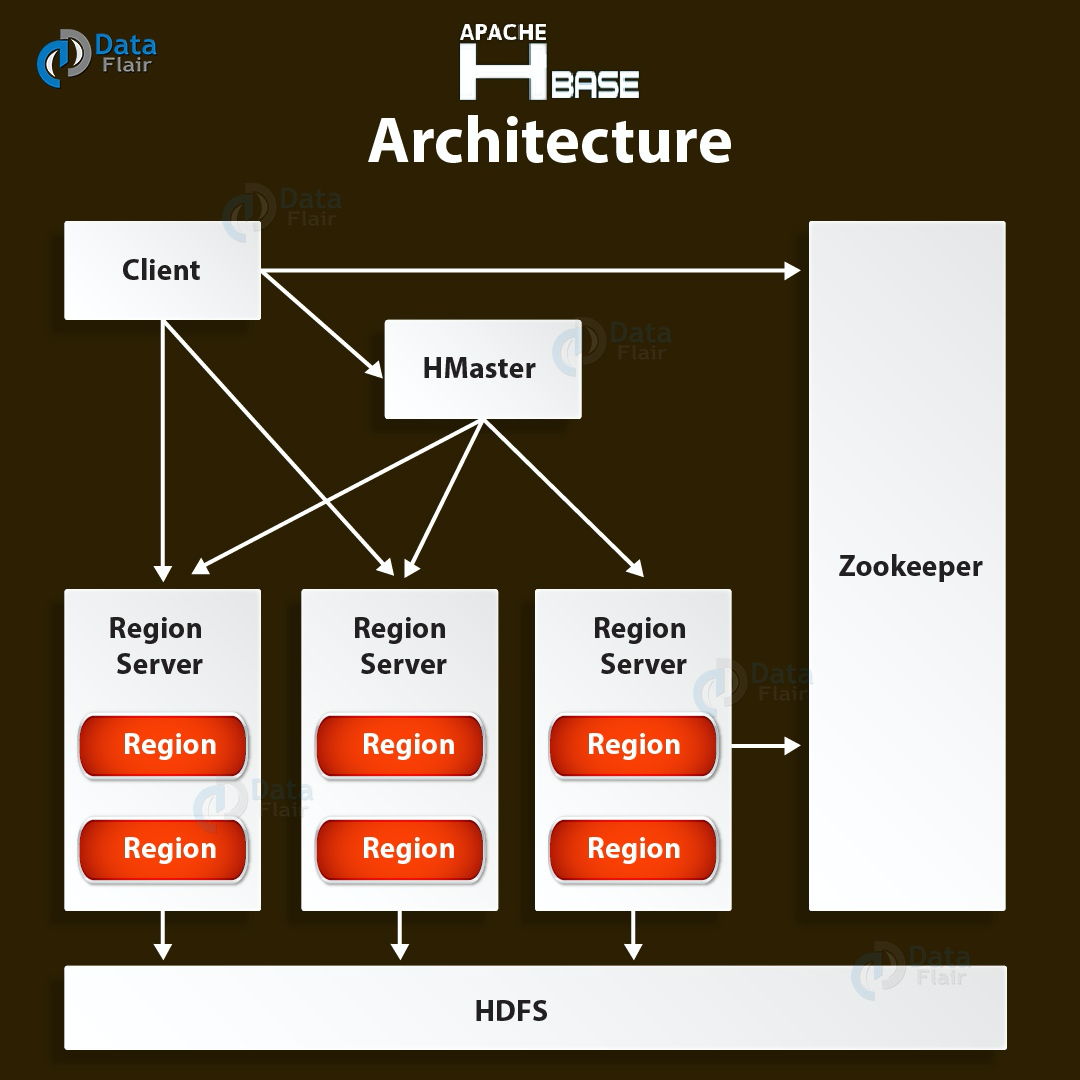
有兩個HBase元件,即HBase Master和RegionServer。HBaseMaster,它不是實際資料儲存的一部分,而是協商所有RegionServer之間的負載平衡,同時其維護和監視Hadoop叢集。具體來說,它執行管理(用於建立,更新和刪除表的介面。)、控制故障轉移、處理DDL操作。RegionServer是工作節點,負責處理來自客戶端的讀取,寫入,更新和刪除請求,程序在Hadoop群集中的每個節點上執行,一般與HDFS DateNode節點保持一致,保證計算向資料移動的特性。
8、**HCatalog**
Apache HCatalog是Hadoop的表和儲存的管理層。它支援Hadoop生態系統中可用的不同元件,例如MapReduce,Hive等,以輕鬆地從叢集讀取和寫入資料。HCatalog是Hive的關鍵元件,使使用者能夠以任何格式和結構儲存其資料。在預設情況下,HCatalog支援RCFile,CSV,JSON,sequenceFile和ORC檔案格式。
9、**Avro**
Acro是Hadoop生態系統的一部分,是最流行的資料序列化系統。Avro是一個開源專案,為Hadoop提供資料序列化和資料交換服務。這些服務可以一起使用,也可以獨立使用。大資料可以使用Avro交換以不同語言編寫的程式。使用序列化服務程式可以將資料序列化為檔案或訊息。它將資料定義和資料儲存在一個訊息或檔案中,使程式可以輕鬆地動態瞭解儲存在Avro檔案或訊息中的資訊。Avro模式–依靠模式進行序列化/反序列化。Avro需要用於資料寫入/讀取的架構。當Avro資料儲存在檔案中時,其架構也隨之儲存,因此以後任何程式都可以處理檔案。動態型別化–指不生成程式碼的序列化和反序列化。它補充了程式碼生成功能,該功能可在Avro中用於靜態型別的語言,作為可選優化。
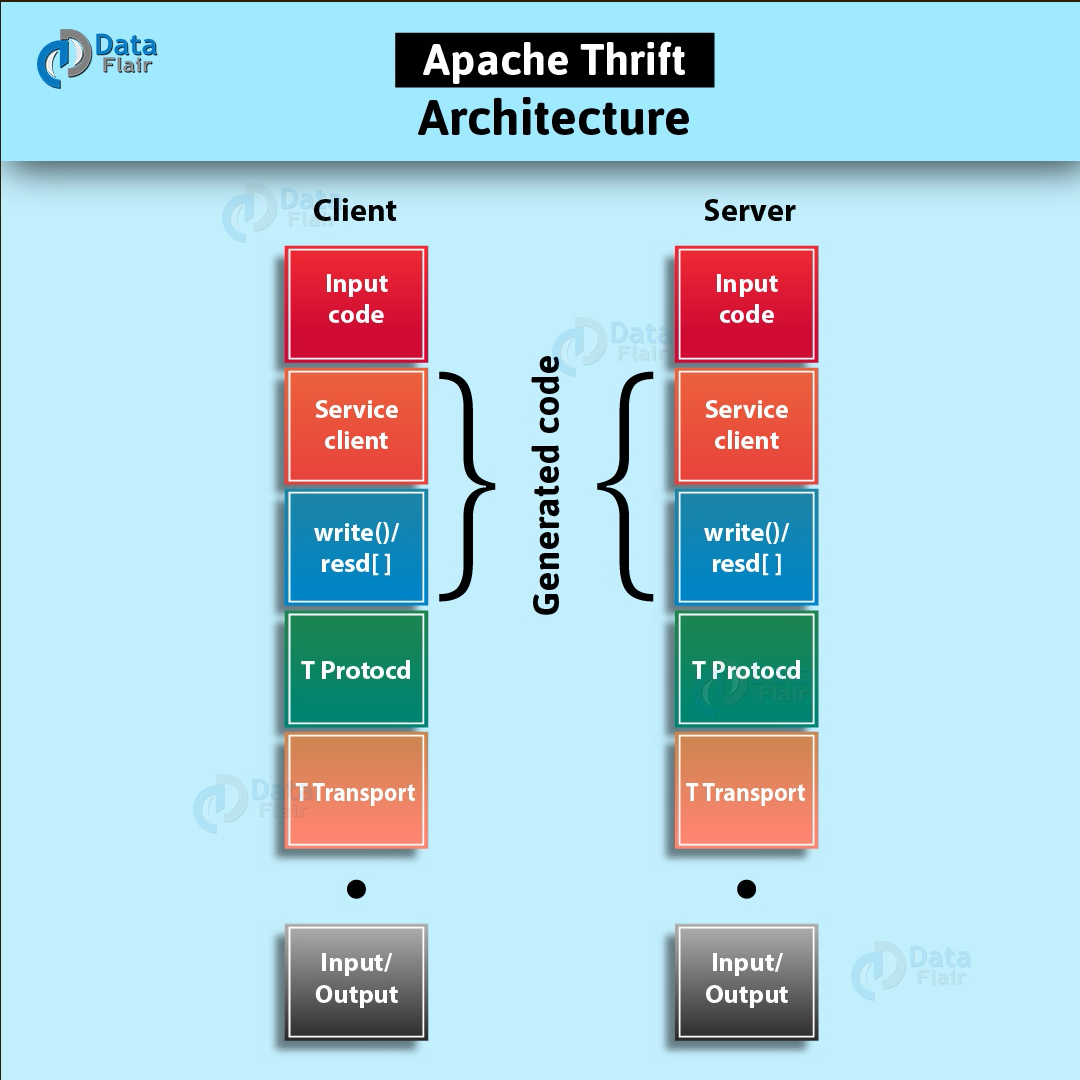
10、**Thrift**
Apache Thrift是一個輕量級、跨語言的遠端服務呼叫框架,最初是由FaceBook開發,後面進入了Apache開源專案。它通過自身的IDL中間語言, 並藉助程式碼生成引擎生成各種主流語言的RPC服務端/客戶端模板程式碼。在Hadoop的技術生態中,很多技術均用到了此框架的技術。
11、**Drill**
Apache Drill是一個低延遲的分散式海量資料(涵蓋結構化、半結構化以及巢狀資料)互動式查詢引擎,使用ANSI SQL相容語法,支援本地檔案、HDFS、HBase、MongoDB等後端儲存,支援Parquet、JSON、CSV、TSV、PSV等資料格式。本質上Apache Drill是一個分散式的mpp(大規模並行處理)查詢層。Drill的目的在於支援更廣泛的資料來源,資料格式,以及查詢語言。受Google的Dremel啟發,Drill滿足上千節點的PB級別資料的互動式商業智慧分析場景。
12、**Mahout**
Apache Mahout提供了一些經典的機器學習的演算法,皆在幫助開發人員更加方便快捷地建立智慧應用程式。通過ApacheMahout庫,Mahout可以有效地擴充套件到雲中。Mahout包括許多實現,包括聚類、分類、推薦引擎、頻繁子項挖掘。Apache Mahout的主要目標是建立可伸縮的機器學習演算法。這種可伸縮性是針對大規模的資料集而言的。通過Apache Mahout的演算法庫,Mahout可以有效地使用Hadoop叢集的能力進行機器學習的計算與分析。
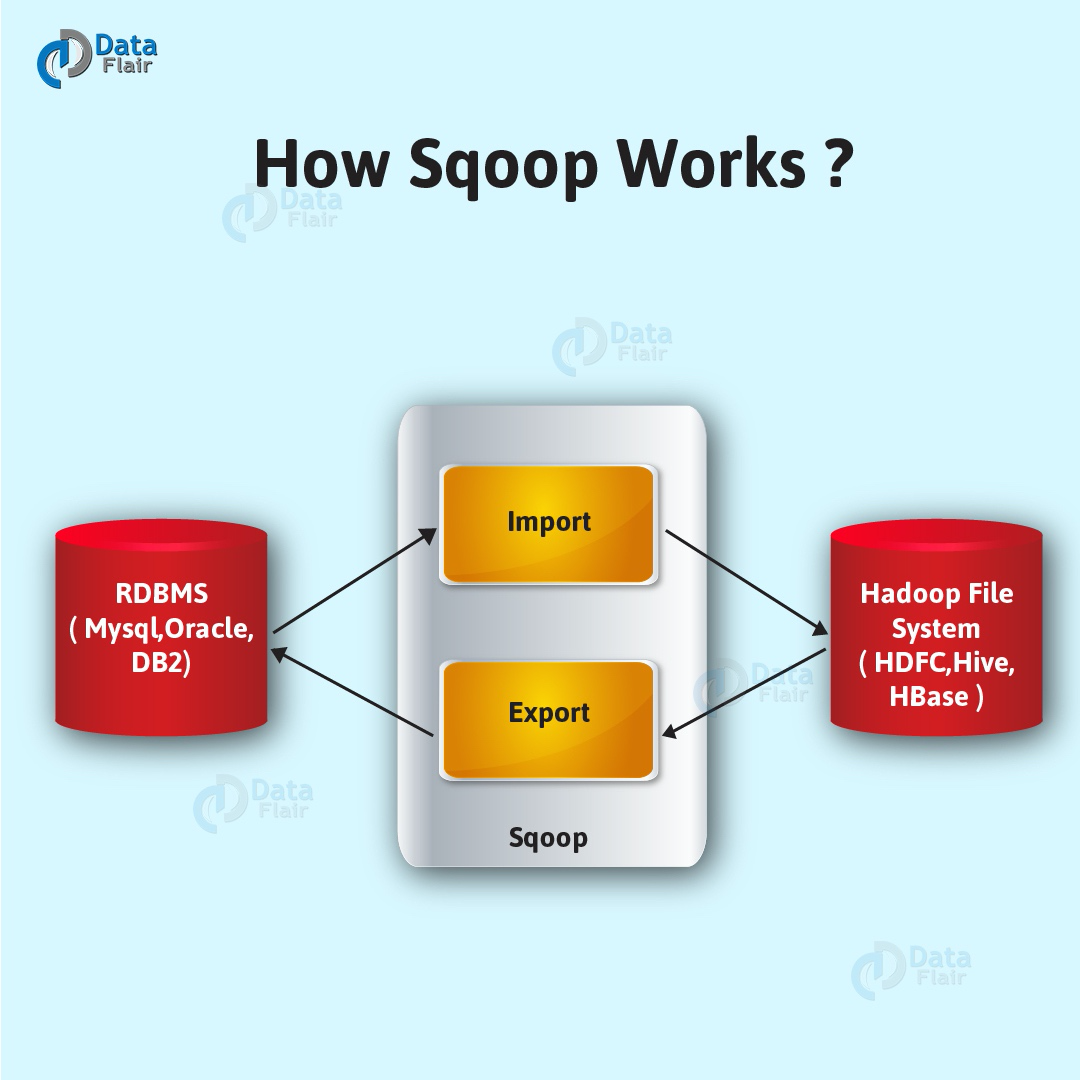
13、**Sqoop**
Apache Sqoop是一款用於hadoop和關係型資料庫之間資料匯入匯出的工具。你可以通過Sqoop把資料從資料庫(比如mysql,oracle)匯入到HDFS中;也可以把資料從HDFS中匯出到關係型資料庫中。Sqoop通過Hadoop的MapReduce匯入匯出,因此提供了很高的並行效能以及良好的容錯性。
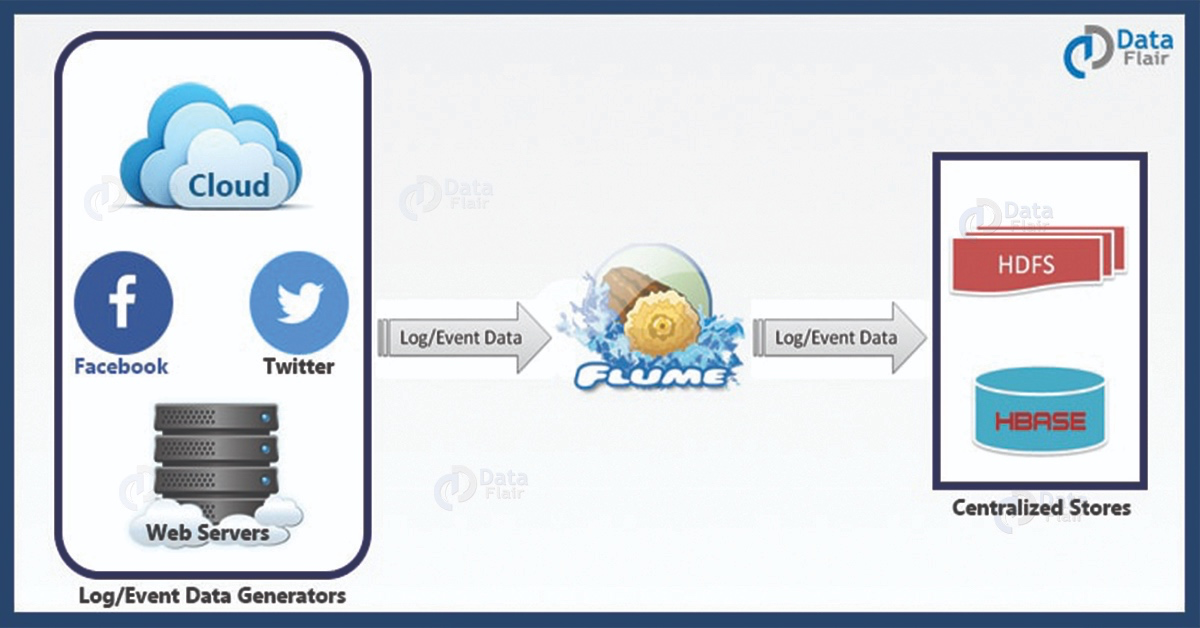
14、**Flume**
Apache Flume是一個分散式的、可靠的、可用的,從多種不同的源收集、聚集、移動大量日誌資料到集中資料儲存的系統。Flume提供對資料進行簡單處理,並寫到各種資料接受方(可定製)的能力 。Flume提供了從console(控制檯)、RPC(Thrift-RPC)、text(檔案)、tail(UNIX tail)、syslog(syslog日誌系統),支援TCP和UDP等2種模式,exec(命令執行)等資料來源上收集資料的能力。它使用一個簡單的可擴充套件資料模型,該模型可用於線上分析應用程式。
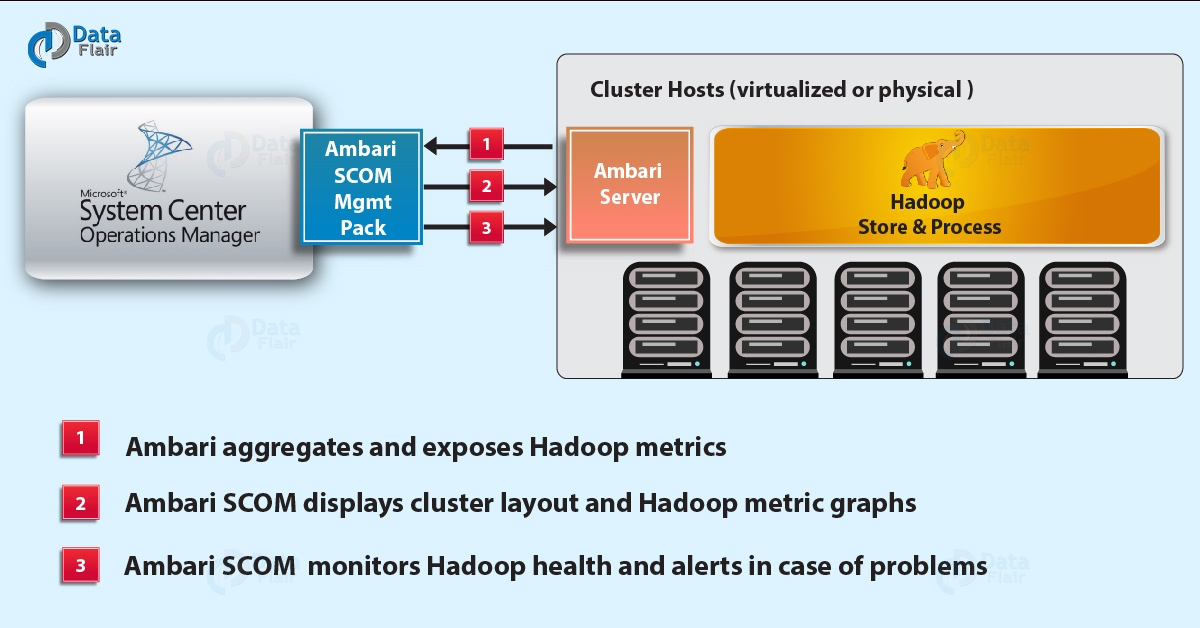
15、**Ambari**
Apache Ambari的功能就是建立、管理、監視Hadoop的叢集,這裡的Hadoop是廣義,指的是 Hadoop 整個生態圈(例如 Hive、Hbase、Sqoop、Zookeeper等)。用一句話來說,Ambari 就是為了讓 Hadoop 以及相關的大資料軟體更容易使用的一個工具。隨著Ambari為操作控制提供一致,安全的平臺,Hadoop管理變得更加簡單。
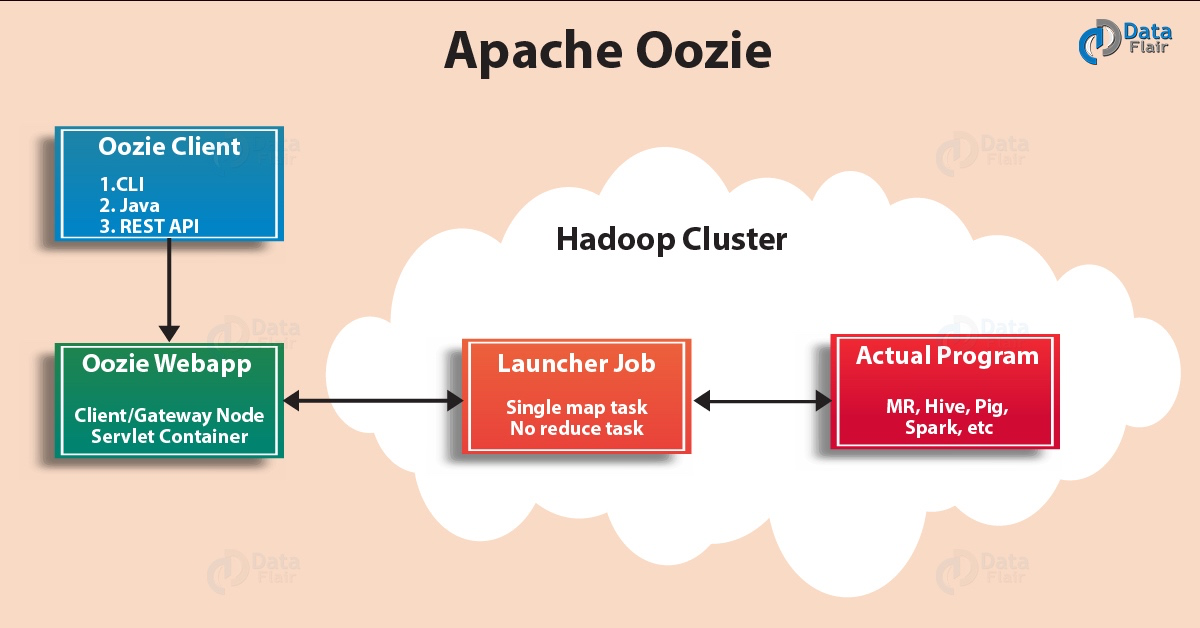
16、**Oozie**
Apache Oozie是用於管理Hadoop作業的工作流排程程式系統。 Oozie將多個作業依次組合為一個邏輯工作單元。 Oozie框架與作為架構中心的Apache Yarn完全整合,並支援Apache MapReduce、Hive、Sqoop等Hadoop技術中需要排程的作業。
以上是Hadoop技術生態圈的講解,但這裡還沒有完,因為在目前業界使用最廣泛的大資料技術中,還有幾個技術不得不提一下。
17、**Spark**
Apache Spark是一個基於Scala語言編寫的分散式計算框架,最初是由加州大學伯克利分銷AMPLab實驗室開發,相對於MapReduce計算框架,它減少了記憶體與磁碟的IO操作,從而提高了計算時間。Spark採用了基於記憶體的運算,將中間資料結果儲存在記憶體中,方便下次計算呼叫。該框架的計算速度根據官網的介紹,基於記憶體的計算中比MapReduce快100倍,基於磁碟的計算中比MapReduce快10倍。Spark內部有五個重要組成部分,分別是Spark Core、Spark SQL、Spark Streaming、MLlib和GraphX。在存在遞迴迭代運算的場景下,Spark非常適合。
18、**Elastic Search**
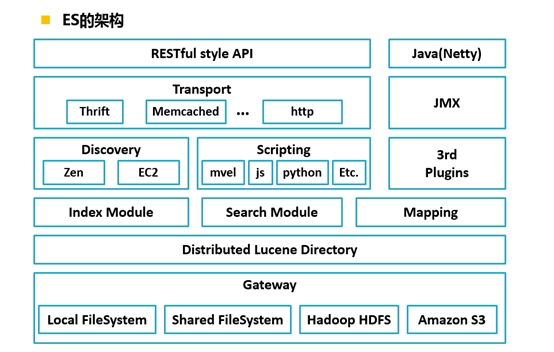
Elastic Search是一個基於Lucene的搜尋伺服器。它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTful web介面。Elasticsearch是用Java語言開發的,並作為Apache許可條款下的開放原始碼釋出,是一種流行的企業級搜尋引擎。Elasticsearch用於雲端計算中,能夠達到實時搜尋,穩定,可靠,快速,安裝使用方便。官方客戶端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和許多其他語言中都是可用的。根據DB-Engines的排名顯示,Elasticsearch是最受歡迎的企業搜尋引擎,其次是Apache Solr,也是基於Lucene。它的核心演算法是倒排索引演算法。
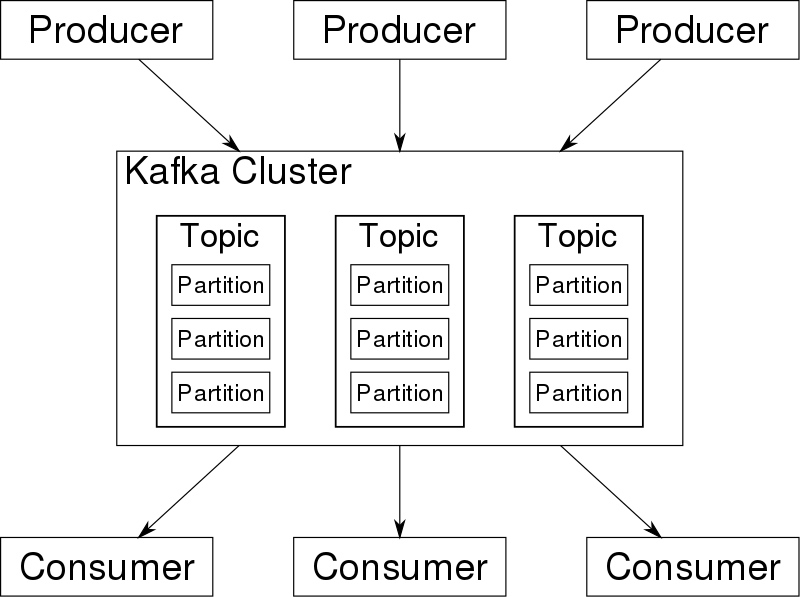
19、**Kafka**
Apache Kafka是一種分散式的,基於釋出 / 訂閱的訊息系統,採用Java和Scala編寫。該平臺為處理即時資料提供了統一、高吞吐、低延遲的服務。目前越來越多的開源分散式處理系統如Cloudera、Apache Storm、Spark都支援與Kafka整合。Kafka是一個訊息系統,原本開發自LinkedIn,用作 LinkedIn 的活動流(Activity Stream)和運營資料處理管道(Pipeline)的基礎。現在它已被多家不同型別的公司 作為多種型別的資料管道和訊息系統使用。它能夠以時間複雜度為 O(1) 的方式提供訊息持久化能力,即使對 TB 級以上資料也能保證常數時間複雜度的訪問效能。它擁有高吞吐率。即使在非常廉價的商用機器上也能做到單機支援每秒 100K 條以上訊息的傳輸。它支援 Kafka Server 間的訊息分割槽,及分散式消費,同時保證每個 Partition 內的訊息順序傳輸。它同時支援離線資料處理和實時資料處理。最後它還支援線上水平擴充套件。
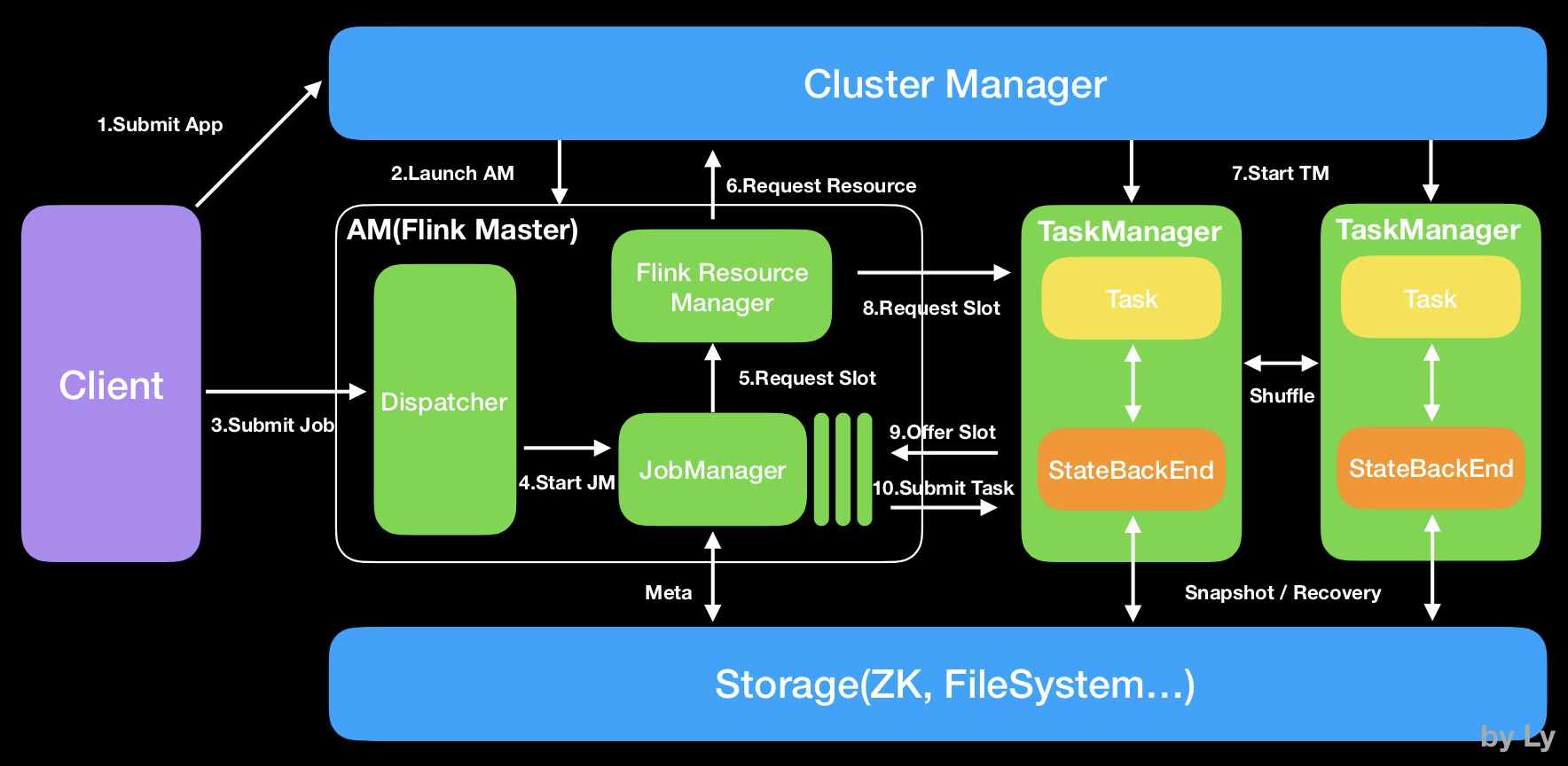
20、**Flink**
Apache Flink是一個框架和分散式處理引擎,用於在無邊界和有邊界資料流上進行有狀態的計算。Flink能在所有常見叢集環境中執行,並能以記憶體速度和任意規模進行計算。Apache Flink 是一個分散式系統,它需要計算資源來執行應用程式。Flink 集成了所有常見的叢集資源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同時也可以作為獨立叢集執行。Flink被設計為能夠很好地工作在上述每個資源管理器中,這是通過資源管理器特定(resource-manager-specific)的部署模式實現的。Flink 可以採用與當前資源管理器相適應的方式進行互動。部署 Flink 應用程式時,Flink 會根據應用程式配置的並行性自動標識所需的資源,並從資源管理器請求這些資源。在發生故障的情況下,Flink 通過請求新資源來替換髮生故障的容器。提交或控制應用程式的所有通訊都是通過 REST 呼叫進行的,這可以簡化 Flink 與各種環境中的整合。Flink旨在任意規模上執行有狀態流式應用。因此,應用程式被並行化為可能數千個任務,這些任務分佈在叢集中併發執行。所以應用程式能夠充分利用無盡的 CPU、記憶體、磁碟和網路 IO。而且 Flink 很容易維護非常大的應用程式狀態。其非同步和增量的檢查點演算法對處理延遲產生最小的影響,同時保證精確一次狀態的一致性。
以上就是大資料應用比較廣泛的技術架構的介紹。
最後我想說的是,技術會一直更新演變下去,但核心的思想總是不會改變的,在學習技術的過程中,需要的是對思想的理解與運用,而不是就一個技術而學一個技術。同時,沒有任何一個技術是完美無缺的,只有適合與不適合的區別。在實際的業務場景下,根據公司的實際情況,選擇合適的大資料技術架構完成需求業務才是重中之重。
![](https://img2020.cnblogs.com/blog/1626376/202010/1626376-20201022205125475-18481579