
10 張圖開啟 CPU 快取一致性的大門

前言
直接上,不多 BB 了。

正文
CPU Cache 的資料寫入
隨著時間的推移,CPU 和記憶體的訪問效能相差越來越大,於是就在 CPU 內部嵌入了 CPU Cache(快取記憶體),CPU Cache 離 CPU 核心相當近,因此它的訪問速度是很快的,於是它充當了 CPU 與記憶體之間的快取角色。
CPU Cache 通常分為三級快取:L1 Cache、L2 Cache、L3 Cache,級別越低的離 CPU 核心越近,訪問速度也快,但是儲存容量相對就會越小。其中,在多核心的 CPU 裡,每個核心都有各自的 L1/L2 Cache,而 L3 Cache 是所有核心共享使用的。

我們先簡單瞭解下 CPU Cache 的結構,CPU Cache 是由很多個 Cache Line 組成的,CPU Line 是 CPU 從記憶體讀取資料的基本單位,而 CPU Line 是由各種標誌(Tag)+ 資料塊(Data Block)組成,你可以在下圖清晰的看到:

我們當然期望 CPU 讀取資料的時候,都是儘可能地從 CPU Cache 中讀取,而不是每一次都要從記憶體中獲取資料。所以,身為程式設計師,我們要儘可能寫出快取命中率高的程式碼,這樣就有效提高程式的效能,具體的做法,你可以參考我上一篇文章「如何寫出讓 CPU 跑得更快的程式碼?」
事實上,資料不光是隻有讀操作,還有寫操作,那麼如果資料寫入 Cache 之後,記憶體與 Cache 相對應的資料將會不同,這種情況下 Cache 和記憶體資料都不一致了,於是我們肯定是要把 Cache 中的資料同步到記憶體裡的。
問題來了,那在什麼時機才把 Cache 中的資料寫回到記憶體呢?為了應對這個問題,下面介紹兩種針對寫入資料的方法:
- 寫直達(Write Through)
- 寫回(Write Back)
寫直達
保持記憶體與 Cache 一致性最簡單的方式是,把資料同時寫入記憶體和 Cache 中,這種方法稱為寫直達(Write Through)。

在這個方法裡,寫入前會先判斷資料是否已經在 CPU Cache 裡面了:
- 如果資料已經在 Cache 裡面,先將資料更新到 Cache 裡面,再寫入到記憶體裡面;
- 如果資料沒有在 Cache 裡面,就直接把資料更新到記憶體裡面。
寫直達法很直觀,也很簡單,但是問題明顯,無論資料在不在 Cache 裡面,每次寫操作都會寫回到記憶體,這樣寫操作將會花費大量的時間,無疑效能會受到很大的影響。
寫回
既然寫直達由於每次寫操作都會把資料寫回到記憶體,而導致影響效能,於是為了要減少資料寫回記憶體的頻率,就出現了寫回(Write Back)的方法。
在寫回機制中,當發生寫操作時,新的資料僅僅被寫入 Cache Block 裡,只有當修改過的 Cache Block「被替換」時才需要寫到記憶體中,減少了資料寫回記憶體的頻率,這樣便可以提高系統的效能。

那具體如何做到的呢?下面來詳細說一下:
- 如果當發生寫操作時,資料已經在 CPU Cache 裡的話,則把資料更新到 CPU Cache 裡,同時標記 CPU Cache 裡的這個 Cache Block 為髒(Dirty)的,這個髒的標記代表這個時候,我們 CPU Cache 裡面的這個 Cache Block 的資料和記憶體是不一致的,這種情況是不用把資料寫到記憶體裡的;
- 如果當發生寫操作時,資料所對應的 Cache Block 裡存放的是「別的記憶體地址的資料」的話,就要檢查這個 Cache Block 裡的資料有沒有被標記為髒的,如果是髒的話,我們就要把這個 Cache Block 裡的資料寫回到記憶體,然後再把當前要寫入的資料,寫入到這個 Cache Block 裡,同時也把它標記為髒的;如果 Cache Block 裡面的資料沒有被標記為髒,則就直接將資料寫入到這個 Cache Block 裡,然後再把這個 Cache Block 標記為髒的就好了。
可以發現寫回這個方法,在把資料寫入到 Cache 的時候,只有在快取不命中,同時資料對應的 Cache 中的 Cache Block 為髒標記的情況下,才會將資料寫到記憶體中,而在快取命中的情況下,則在寫入後 Cache 後,只需把該資料對應的 Cache Block 標記為髒即可,而不用寫到記憶體裡。
這樣的好處是,如果我們大量的操作都能夠命中快取,那麼大部分時間裡 CPU 都不需要讀寫記憶體,自然效能相比寫直達會高很多。
快取一致性問題
現在 CPU 都是多核的,由於 L1/L2 Cache 是多個核心各自獨有的,那麼會帶來多核心的快取一致性(Cache Coherence) 的問題,如果不能保證快取一致性的問題,就可能造成結果錯誤。
那快取一致性的問題具體是怎麼發生的呢?我們以一個含有兩個核心的 CPU 作為例子看一看。
假設 A 號核心和 B 號核心同時執行兩個執行緒,都操作共同的變數 i(初始值為 0 )。

這時如果 A 號核心執行了 i++ 語句的時候,為了考慮效能,使用了我們前面所說的寫回策略,先把值為 1 的執行結果寫入到 L1/L2 Cache 中,然後把 L1/L2 Cache 中對應的 Block 標記為髒的,這個時候資料其實沒有被同步到記憶體中的,因為寫回策略,只有在 A 號核心中的這個 Cache Block 要被替換的時候,資料才會寫入到記憶體裡。
如果這時旁邊的 B 號核心嘗試從記憶體讀取 i 變數的值,則讀到的將會是錯誤的值,因為剛才 A 號核心更新 i 值還沒寫入到記憶體中,記憶體中的值還依然是 0。這個就是所謂的快取一致性問題,A 號核心和 B 號核心的快取,在這個時候是不一致,從而會導致執行結果的錯誤。

那麼,要解決這一問題,就需要一種機制,來同步兩個不同核心裡面的快取資料。要實現的這個機制的話,要保證做到下面這 2 點:
- 第一點,某個 CPU 核心裡的 Cache 資料更新時,必須要傳播到其他核心的 Cache,這個稱為寫傳播(Wreite Propagation);
- 第二點,某個 CPU 核心裡對資料的操作順序,必須在其他核心看起來順序是一樣的,這個稱為事務的串形化(Transaction Serialization)。
第一點寫傳播很容易就理解,當某個核心在 Cache 更新了資料,就需要同步到其他核心的 Cache 裡。而對於第二點事務事的串形化,我們舉個例子來理解它。
假設我們有一個含有 4 個核心的 CPU,這 4 個核心都操作共同的變數 i(初始值為 0 )。A 號核心先把 i 值變為 100,而此時同一時間,B 號核心先把 i 值變為 200,這裡兩個修改,都會「傳播」到 C 和 D 號核心。

那麼問題就來了,C 號核心先收到了 A 號核心更新資料的事件,再收到 B 號核心更新資料的事件,因此 C 號核心看到的變數 i 是先變成 100,後變成 200。
而如果 D 號核心收到的事件是反過來的,則 D 號核心看到的是變數 i 先變成 200,再變成 100,雖然是做到了寫傳播,但是各個 Cache 裡面的資料還是不一致的。
所以,我們要保證 C 號核心和 D 號核心都能看到相同順序的資料變化,比如變數 i 都是先變成 100,再變成 200,這樣的過程就是事務的串形化。
要實現事務串形化,要做到 2 點:
- CPU 核心對於 Cache 中資料的操作,需要同步給其他 CPU 核心;
- 要引入「鎖」的概念,如果兩個 CPU 核心裡有相同資料的 Cache,那麼對於這個 Cache 資料的更新,只有拿到了「鎖」,才能進行對應的資料更新。
那接下來我們看看,寫傳播和事務串形化具體是用什麼技術實現的。
匯流排嗅探
寫傳播的原則就是當某個 CPU 核心更新了 Cache 中的資料,要把該事件廣播通知到其他核心。最常見實現的方式是匯流排嗅探(Bus Snooping)。
我還是以前面的 i 變數例子來說明匯流排嗅探的工作機制,當 A 號 CPU 核心修改了 L1 Cache 中 i 變數的值,通過匯流排把這個事件廣播通知給其他所有的核心,然後每個 CPU 核心都會監聽總線上的廣播事件,並檢查是否有相同的資料在自己的 L1 Cache 裡面,如果 B 號 CPU 核心的 L1 Cache 中有該資料,那麼也需要把該資料更新到自己的 L1 Cache。
可以發現,匯流排嗅探方法很簡單, CPU 需要每時每刻監聽總線上的一切活動,但是不管別的核心的 Cache 是否快取相同的資料,都需要發出一個廣播事件,這無疑會加重匯流排的負載。
另外,匯流排嗅探只是保證了某個 CPU 核心的 Cache 更新資料這個事件能被其他 CPU 核心知道,但是並不能保證事務串形化。
於是,有一個協議基於匯流排嗅探機制實現了事務串形化,也用狀態機機制降低了匯流排頻寬壓力,這個協議就是 MESI 協議,這個協議就做到了 CPU 快取一致性。
MESI 協議
MESI 協議其實是 4 個狀態單詞的開頭字母縮寫,分別是:
- Modified,已修改
- Exclusive,獨佔
- Shared,共享
- Invalidated,已失效
這四個狀態來標記 Cache Line 四個不同的狀態。
「已修改」狀態就是我們前面提到的髒標記,代表該 Cache Block 上的資料已經被更新過,但是還沒有寫到記憶體裡。而「已失效」狀態,表示的是這個 Cache Block 裡的資料已經失效了,不可以讀取該狀態的資料。
「獨佔」和「共享」狀態都代表 Cache Block 裡的資料是乾淨的,也就是說,這個時候 Cache Block 裡的資料和記憶體裡面的資料是一致性的。
「獨佔」和「共享」的差別在於,獨佔狀態的時候,資料只儲存在一個 CPU 核心的 Cache 裡,而其他 CPU 核心的 Cache 沒有該資料。這個時候,如果要向獨佔的 Cache 寫資料,就可以直接自由地寫入,而不需要通知其他 CPU 核心,因為只有你這有這個資料,就不存在快取一致性的問題了,於是就可以隨便操作該資料。
另外,在「獨佔」狀態下的資料,如果有其他核心從記憶體讀取了相同的資料到各自的 Cache ,那麼這個時候,獨佔狀態下的資料就會變成共享狀態。
那麼,「共享」狀態代表著相同的資料在多個 CPU 核心的 Cache 裡都有,所以當我們要更新 Cache 裡面的資料的時候,不能直接修改,而是要先向所有的其他 CPU 核心廣播一個請求,要求先把其他核心的 Cache 中對應的 Cache Line 標記為「無效」狀態,然後再更新當前 Cache 裡面的資料。
我們舉個具體的例子來看看這四個狀態的轉換:
- 當 A 號 CPU 核心從記憶體讀取變數 i 的值,資料被快取在 A 號 CPU 核心自己的 Cache 裡面,此時其他 CPU 核心的 Cache 沒有快取該資料,於是標記 Cache Line 狀態為「獨佔」,此時其 Cache 中的資料與記憶體是一致的;
- 然後 B 號 CPU 核心也從記憶體讀取了變數 i 的值,此時會發送訊息給其他 CPU 核心,由於 A 號 CPU 核心已經快取了該資料,所以會把資料返回給 B 號 CPU 核心。在這個時候, A 和 B 核心快取了相同的資料,Cache Line 的狀態就會變成「共享」,並且其 Cache 中的資料與記憶體也是一致的;
- 當 A 號 CPU 核心要修改 Cache 中 i 變數的值,發現數據對應的 Cache Line 的狀態是共享狀態,則要向所有的其他 CPU 核心廣播一個請求,要求先把其他核心的 Cache 中對應的 Cache Line 標記為「無效」狀態,然後 A 號 CPU 核心才更新 Cache 裡面的資料,同時標記 Cache Line 為「已修改」狀態,此時 Cache 中的資料就與記憶體不一致了。
- 如果 A 號 CPU 核心「繼續」修改 Cache 中 i 變數的值,由於此時的 Cache Line 是「已修改」狀態,因此不需要給其他 CPU 核心傳送訊息,直接更新資料即可。
- 如果 A 號 CPU 核心的 Cache 裡的 i 變數對應的 Cache Line 要被「替換」,發現 Cache Line 狀態是「已修改」狀態,就會在替換前先把資料同步到記憶體。
所以,可以發現當 Cache Line 狀態是「已修改」或者「獨佔」狀態時,修改更新其資料不需要傳送廣播給其他 CPU 核心,這在一定程度上減少了匯流排頻寬壓力。
事實上,整個 MESI 的狀態可以用一個有限狀態機來表示它的狀態流轉。還有一點,對於不同狀態觸發的事件操作,可能是來自本地 CPU 核心發出的廣播事件,也可以是來自其他 CPU 核心通過匯流排發出的廣播事件。下圖即是 MESI 協議的狀態圖:

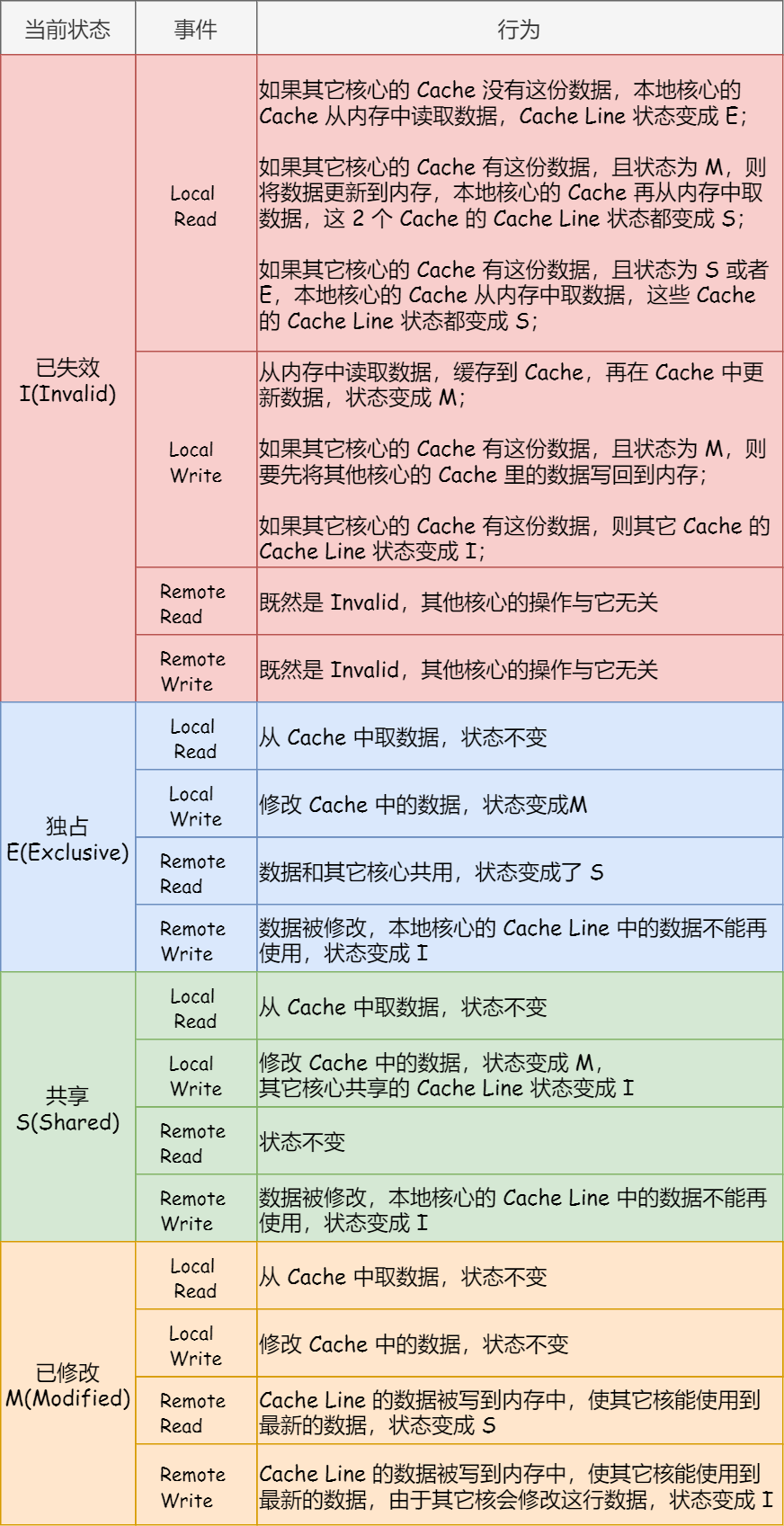
MESI 協議的四種狀態之間的流轉過程,我彙總成了下面的表格,你可以更詳細的看到每個狀態轉換的原因:
總結
CPU 在讀寫資料的時候,都是在 CPU Cache 讀寫資料的,原因是 Cache 離 CPU 很近,讀寫效能相比記憶體高出很多。對於 Cache 裡沒有快取 CPU 所需要讀取的資料的這種情況,CPU 則會從記憶體讀取資料,並將資料快取到 Cache 裡面,最後 CPU 再從 Cache 讀取資料。
而對於資料的寫入,CPU 都會先寫入到 Cache 裡面,然後再在找個合適的時機寫入到記憶體,那就有「寫直達」和「寫回」這兩種策略來保證 Cache 與記憶體的資料一致性:
- 寫直達,只要有資料寫入,都會直接把資料寫入到記憶體裡面,這種方式簡單直觀,但是效能就會受限於記憶體的訪問速度;
- 寫回,對於已經快取在 Cache 的資料的寫入,只需要更新其資料就可以,不用寫入到記憶體,只有在需要把快取裡面的髒資料交換出去的時候,才把資料同步到記憶體裡,這種方式在快取命中率高的情況,效能會更好;
當今 CPU 都是多核的,每個核心都有各自獨立的 L1/L2 Cache,只有 L3 Cache 是多個核心之間共享的。所以,我們要確保多核快取是一致性的,否則會出現錯誤的結果。
要想實現快取一致性,關鍵是要滿足 2 點:
- 第一點是寫傳播,也就是當某個 CPU 核心發生寫入操作時,需要把該事件廣播通知給其他核心;
- 第二點是事物的序列化,這個很重要,只有保證了這個,次啊能保障我們的資料是真正一致的,我們的程式在各個不同的核心上執行的結果也是一致的;
基於匯流排嗅探機制的 MESI 協議,就滿足上面了這兩點,因此它是保障快取一致性的協議。
MESI 協議,是已修改、獨佔、共享、已實現這四個狀態的英文縮寫的組合。整個 MSI 狀態的變更,則是根據來自本地 CPU 核心的請求,或者來自其他 CPU 核心通過匯流排傳輸過來的請求,從而構成一個流動的狀態機。另外,對於在「已修改」或者「獨佔」狀態的 Cache Line,修改更新其資料不需要傳送廣播給其他 CPU 核心。
說幾句

哈嘍,我是小林,就愛圖解計算機基礎,如果覺得文章對你有幫助,歡迎分享給你的朋友,也給小林點個「贊」,這對小林非常重要,謝謝你們,給各位小姐姐小哥哥們抱拳了,我們下次見!
推薦閱讀
面試官:如何寫出讓 CPU 跑得更快的程式碼?
讀者問:小林你的 500 張圖是怎麼畫的?