
Flink系列(0)——準備篇(流處理基礎)
阿新 • • 發佈:2020-11-08
> Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Apache Flink是一個分散式、有狀態的流計算引擎。
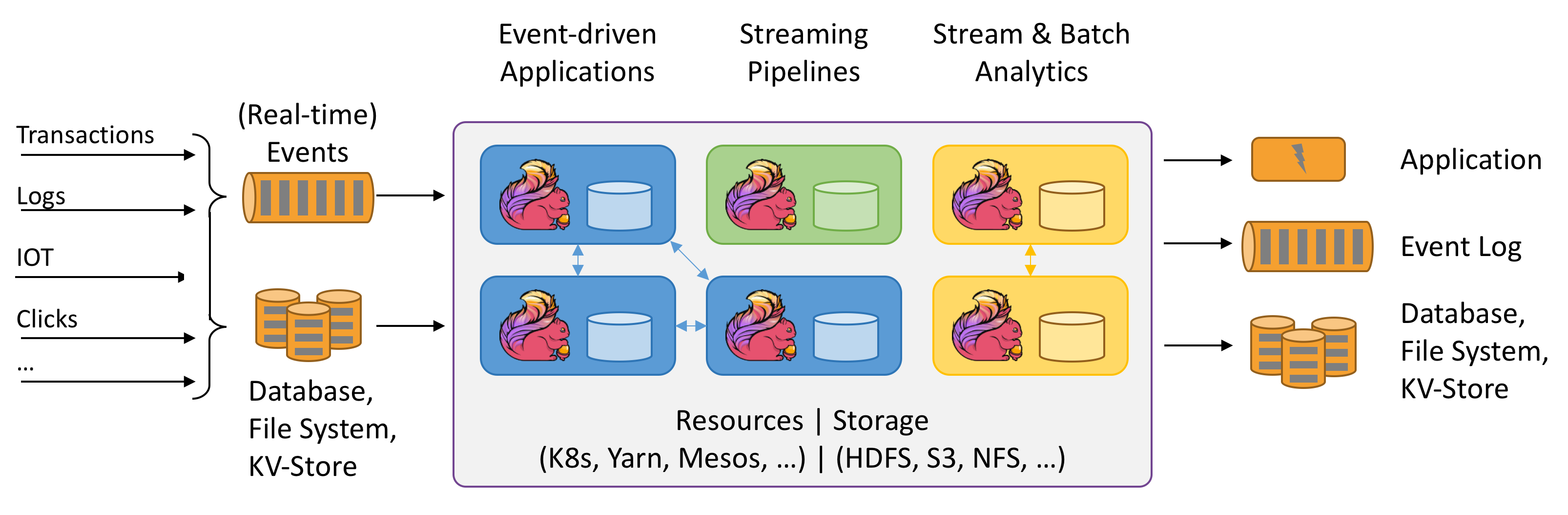
下面將正式開啟Flink系列的學習筆記與總結。(`https://flink.apache.org/`)。此篇是準備篇,主要介紹流處理相關的基礎概念。別小看這些理論,對後續的學習與理解很有幫助哦。
下面很多詞彙來自flink官方:`https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/glossary.html`
## 什麼是資料流
> An event is a statement about a change of the state of the domain modelled by the application. Events can be input and/or output of a stream or batch processing application.
> Any kind of data is produced as a stream of events. Credit card transactions, sensor measurements, machine logs, or user interactions on a website or mobile application, all of these data are generated as a stream.
`資料流`:是一個可能無限的事件序列。這裡的事件可以是實時監控資料、感測器測量值、轉賬交易、物流資訊、電商網購下單、使用者在介面上的操作等等。
流又可分為`無界流`和`有界流`。如下圖所示:
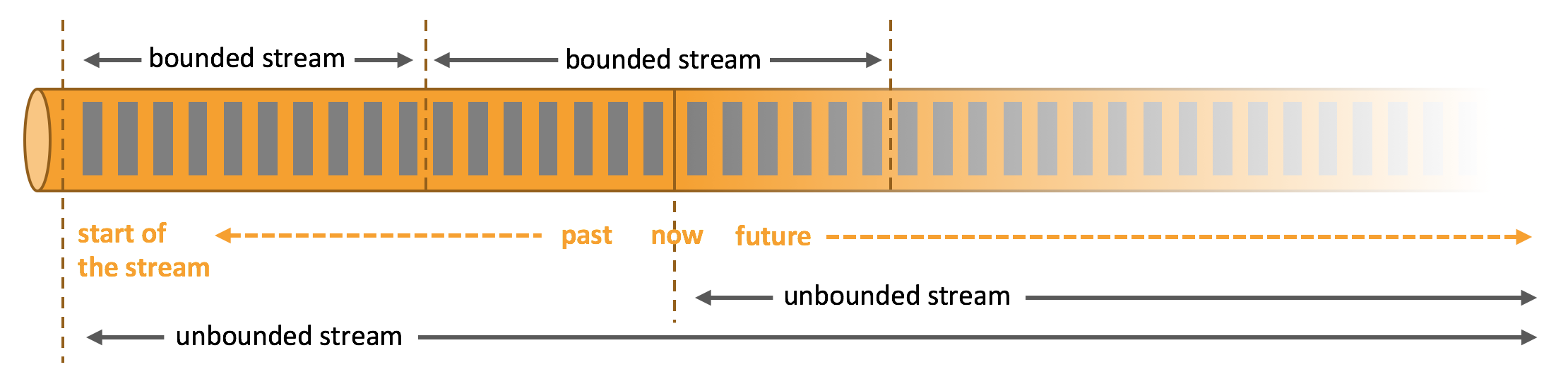
1. `Unbounded streams` have a start but no defined end. They do not terminate and provide data as it is generated.
2. `Bounded streams` have a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations
## 資料流上的操作
流處理引擎通常會提供一系列操作來實現資料流的獲取(`Source`)、轉換(`Transformation`)、輸出(`Sink`)。
借用flink官方1.10版本的圖`https://ci.apache.org/projects/flink/flink-docs-release-1.10/concepts/programming-model.html`,如下:
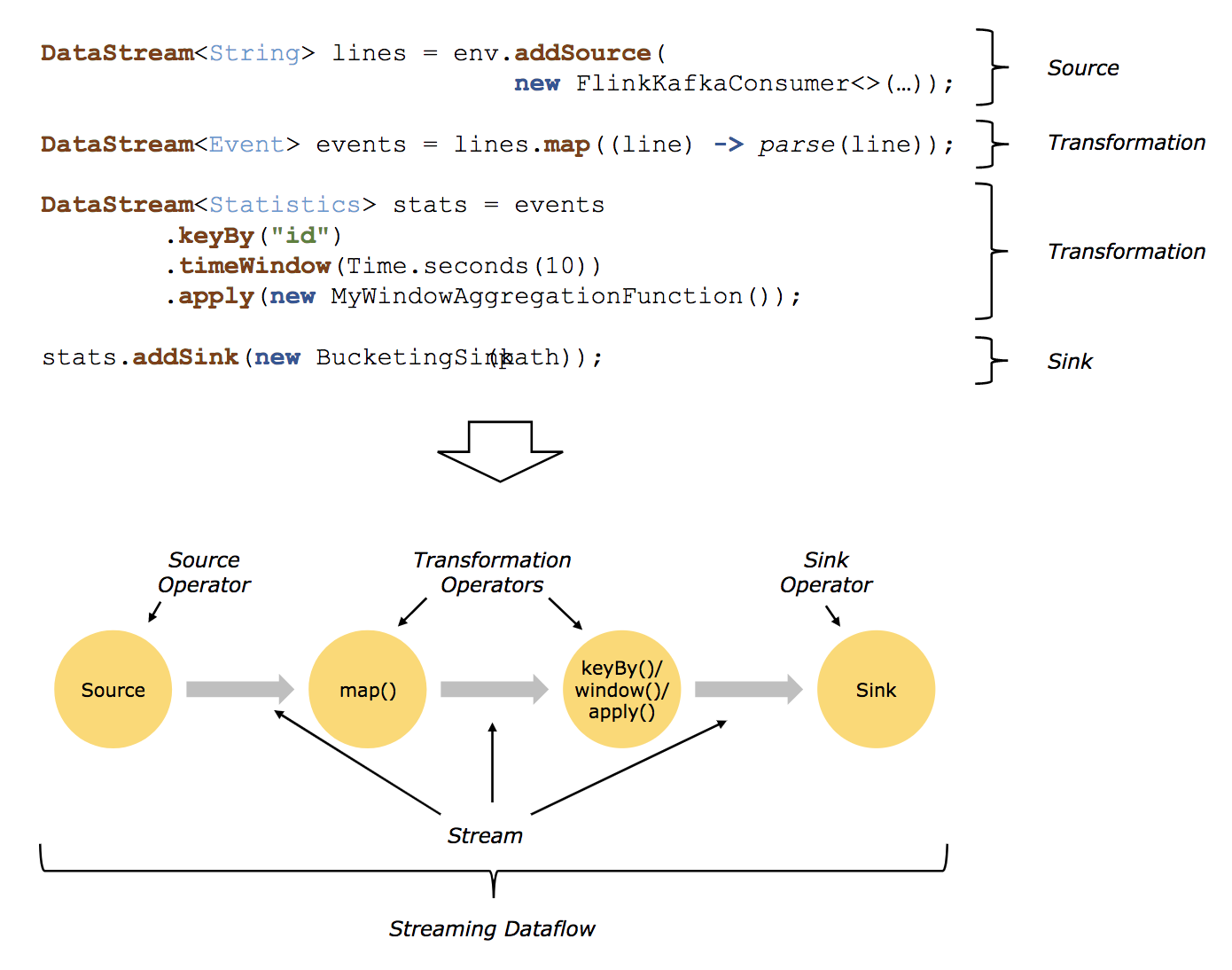
> A `logical graph` is a directed graph where the nodes are Operators and the edges define input/output-relationships of the operators and correspond to data streams or data sets. A logical graph is created by submitting jobs from a Flink Application.`Logical graphs` are also often referred to as `dataflow graphs`.
> `Operator`: Node of a Logical Graph. An Operator performs a certain operation, which is usually executed by a Function. Sources and Sinks are special Operators for data ingestion and data egress.
`dataflow`圖:描述了資料如何在不同的操作之間流動。`dataflow`圖通常為有向圖。圖中節點稱為`運算元`(也常稱為`操作`),表示計算;邊表示資料依賴關係,`運算元`從輸入獲取資料,對其進行計算,然後產生資料併發往輸出以供後續處理。沒有輸入端的運算元稱為`source`,沒有輸出端的運算元稱為`sink`。一個`dataflow`圖至少要有一個`source`和一個`sink`。
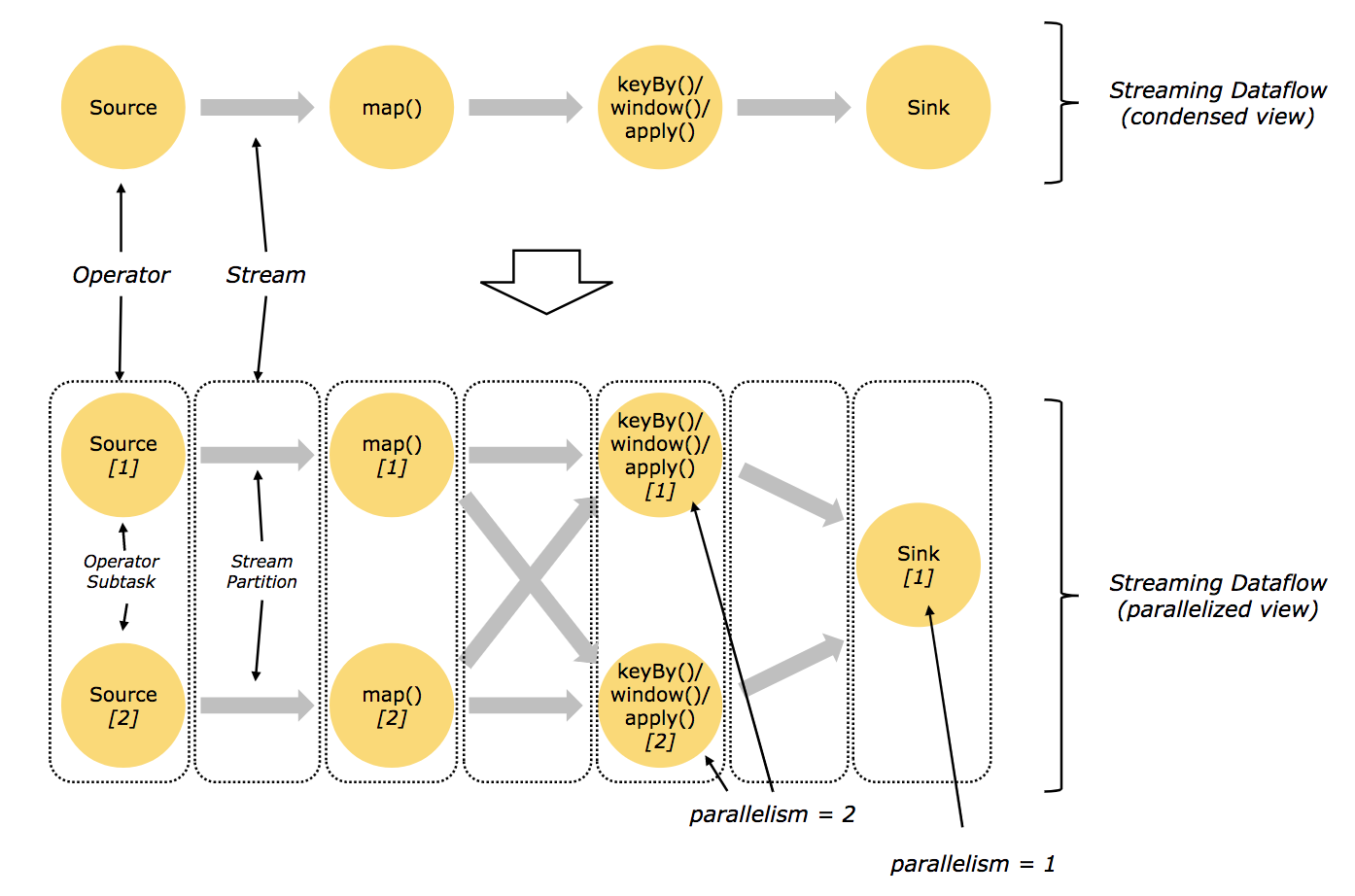
`dataflow`圖被稱作邏輯圖(`logical graph`),因為僅僅表達的是計算邏輯,實際分散式處理時,每個運算元可能會在不同機器上執行多個平行計算。
### Source、Sink、Transformation
> Sources are where your program reads its input from.
> Data sinks consume DataStreams and forward them to files, sockets, external systems, or print them.
資料接入(`Source`)和資料輸出(`Sink`)操作允許流處理引擎和外部系統進行通訊。資料接入操作是從外部資料來源獲取原始資料並將其轉換成適合流處理引擎後續處理的格式。實現資料接入操作邏輯的運算元稱為`Source`,可以來自socket、檔案、kafka等。資料輸出操作是將流處理引擎中的資料以適合外部儲存格式輸出,負責資料輸出的運算元稱為`Sink`,可以寫入檔案、資料庫、kafka等。
> A Transformation is applied on one or more data streams or data sets and results in one or more output data streams or data sets. A transformation might change a data stream or data set on a per-record basis, but might also only change its partitioning or perform an aggregation.
在資料接入與資料輸出中間,往往有大量的轉換操作(`Transformation`)。轉換操作會分別處理每個事件。這些操作逐個讀取事件,對其應用某些轉換併產生一條新的輸出流。運算元既可以同時接收多個輸入流或產出多條輸出流,也可以進行單流分割、多流合併等。
## 有狀態怎麼理解
在資料流上的操作可以是無狀態的(`stateless`),也可以是有狀態的(`stateful`),無狀態的操作不會維持內部狀態,即處理事件時無需依賴已處理過的事件,也不儲存歷史事件。由於事件處理互不影響而且與事件到來的時間無關,無狀態的操作很容易並行化。此外,如果發生故障,無狀態的運算元可以很容易地重啟並恢復工作。相反,有狀態的運算元可能需要維護之前接收到的事件資訊,它們的狀態會根據新來的事件更新,並用於未來事件的處理邏輯中。有狀態的流處理應用在並行化和容錯方面會更具挑戰性。
有狀態運算元同時使用傳入的事件和內部狀態來計算輸出。由於流式運算元處理的都是潛在無窮無盡的資料,所以必須小心避免內部狀態無限增長。為了限制狀態大小,運算元通常都會只保留到目前為止所見事件的摘要或概覽。這種摘要可能是一個數量值,一個累加值,一個對至今為止全部事件的抽樣,一個視窗緩衝或是一個保留了應用執行過程中某些有價值資訊的自定義資料結構。
不難想象,支援有狀態運算元會面臨很多實現上的挑戰。有狀態運算元需要保證狀態可以恢復,並且即使出現故障也要確保結果正確。
### 至多一次(`At Most Once`)
它表示每個事件至多被處理一次。
任務發生故障時最簡單的措施就是既不恢復丟失的狀態,也不重放丟失的事件。換句話說,事件可以隨意丟棄,不保證結果的正確性。
### 至少一次(`At Least Once`)
它表示所有事件最終都會被處理,雖然有些可能會處理多次。
對大多數應用而言,使用者期望是不丟事件。如果最終結果的正確性僅依賴資訊的完整度,那重複處理或者可以接受。例如,確認某個事件是否出現過,就可以用至少一次保證正確的結果。它最壞的結果也無非就是重複判斷了幾次。但如果要計算某個事件出現的次數,至少一次可能就會返回錯誤的結果。
為了確保至少一次語義的正確性,需要想辦法從源頭或者緩衝區中重放事件。持久化事件日誌會將所有事件寫入永久儲存,這樣在任務故障時就可以重放它們。實現該功能的另一個方法是採用記錄確認(`ack`)。將所有事件存在緩衝區中,直到處理管道中所有任務都確認某個事件已經處理完畢才會將事件丟棄。
### 精確一次(`Exactly Once`)
它表示不但沒有事件丟失,而且每個事件對於內部狀態的更新都只有一次。
精確一次是最嚴格,也是最難實現的一類保障。本質上,精確一次語義意味著應用總會提供正確的結果,就如同故障從未發生過一樣。
精確一次同樣需要事件重放機制。此外,流處理引擎需要確保內部狀態的一致性,即在故障恢復後,計算引擎需要知道某個事件對應的更新是否已經反映到狀態上。事務性更新是實現該目標的一個方法,但它可能會帶來極大的效能開銷。Flink採用了輕量級檢查點機制(`Checkpoint`)來實現精確一次的結果保障。(flink系列後續會有文章重點分析,這裡先知道有這麼一回事即可。)
上面提到的“結果保障”,指的都是流處理引擎內部狀態的一致性。也就是說,我們關注故障恢復後應用程式碼能夠看到的狀態值。請注意,保證應用狀態的一致性和保證輸出的一致性並不是一回事。一旦資料從`Sink`中寫出,除非目標系統支援事務,否則最終結果的正確性難以保證。
## 視窗操作
官方有篇關於視窗介紹的部落格:`https://flink.apache.org/news/2015/12/04/Introducing-windows.html`
`windows`相關的文件:`https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html#windows`
> `Windows` are at the heart of processing infinite streams. Windows split the stream into “buckets” of finite size, over which we can apply computations.
轉換操作(`Transformation`)可能每處理一個事件就產生結果並(可能)更新狀態。然而,有些操作必須收集並緩衝記錄才能計算結果,例如流式`Join`或者求中位數的聚合(`Aggregation`)。為了在無界資料流上高效地執行這些操作,必須對操作所維持的資料量加以限制。下面將討論支援該項功能的視窗操作。
此外,有了視窗操作,就能在資料流上完成一些具有實際語義價值的計算。比如說,`最近幾分鐘某路口的車流量`、`某路口每10分鐘的車流量`等。
視窗操作會持續建立一些稱為`桶`的有限事件集合,並允許我們基於這些有限集進行計算。事件通常會根據其時間或其他資料屬性分配到不同桶中。為了準確定義視窗運算元語義,我們需要決定事件如何分配到桶中以及視窗用怎樣的頻率產生結果。視窗的行為是由一系列策略定義的,這些視窗策略決定了什麼時間建立桶,事件如何分配到桶中以及桶內資料什麼時間參與計算。其中參與計算的決策會根據觸發條件判定,當觸發條件滿足時,桶內資料會發送給一個計算函式,由它來對桶內的元素應用計算邏輯。這些計算函式可以是某些聚合(例如計數(`count`)、求和(`sum`)、最大值(`max`)、最小值(`min`)、平均值(`avg`)等),也可以是自定義操作。策略的指定可以基於`時間`(例如“最近5秒鐘接收的事件”)、`數量`(例如“最新100個事件”)或其他資料屬性。
接下來就重點介紹幾種常見的視窗語義。
### 滾動視窗
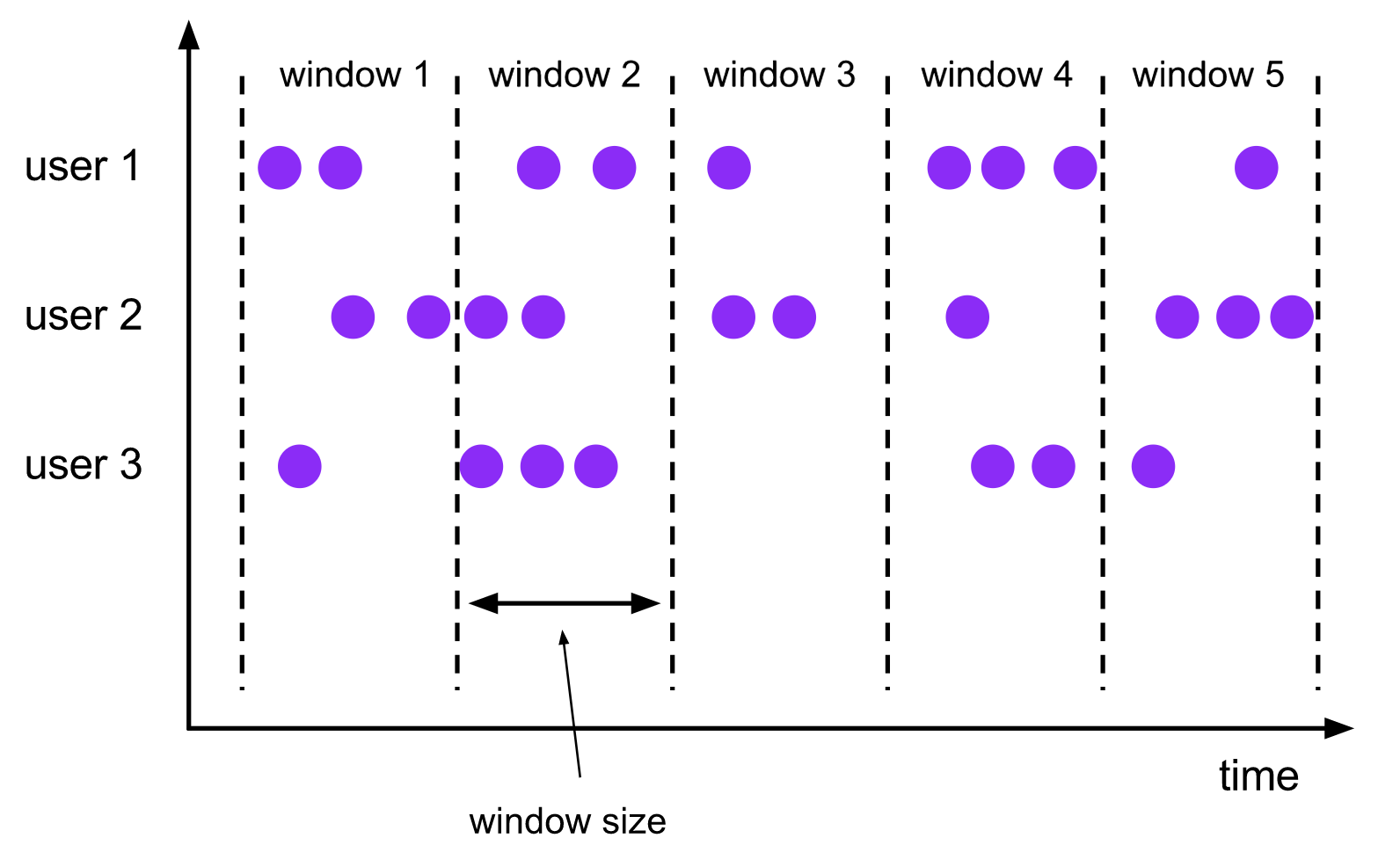
> A `tumbling windows` assigner assigns each element to a window of a specified window size. Tumbling windows have a fixed size and do not overlap. For example, if you specify a tumbling window with a size of 5 minutes, the current window will be evaluated and a new window will be started every five minutes as illustrated by the following figure.
滾動視窗將事件分配到長度固定且互不重疊的桶中。
- 基於數量的(`count-based`)滾動視窗定義了在觸發計算前需要集齊多少條事件;
- 基於時間的(`time-based`)滾動視窗定義了在桶中緩衝事件的時間間隔。如上圖所示,基於時間間隔的滾動視窗將事件彙集到桶中,每隔一段時間(`window size`)觸發一次計算。
### 滑動視窗
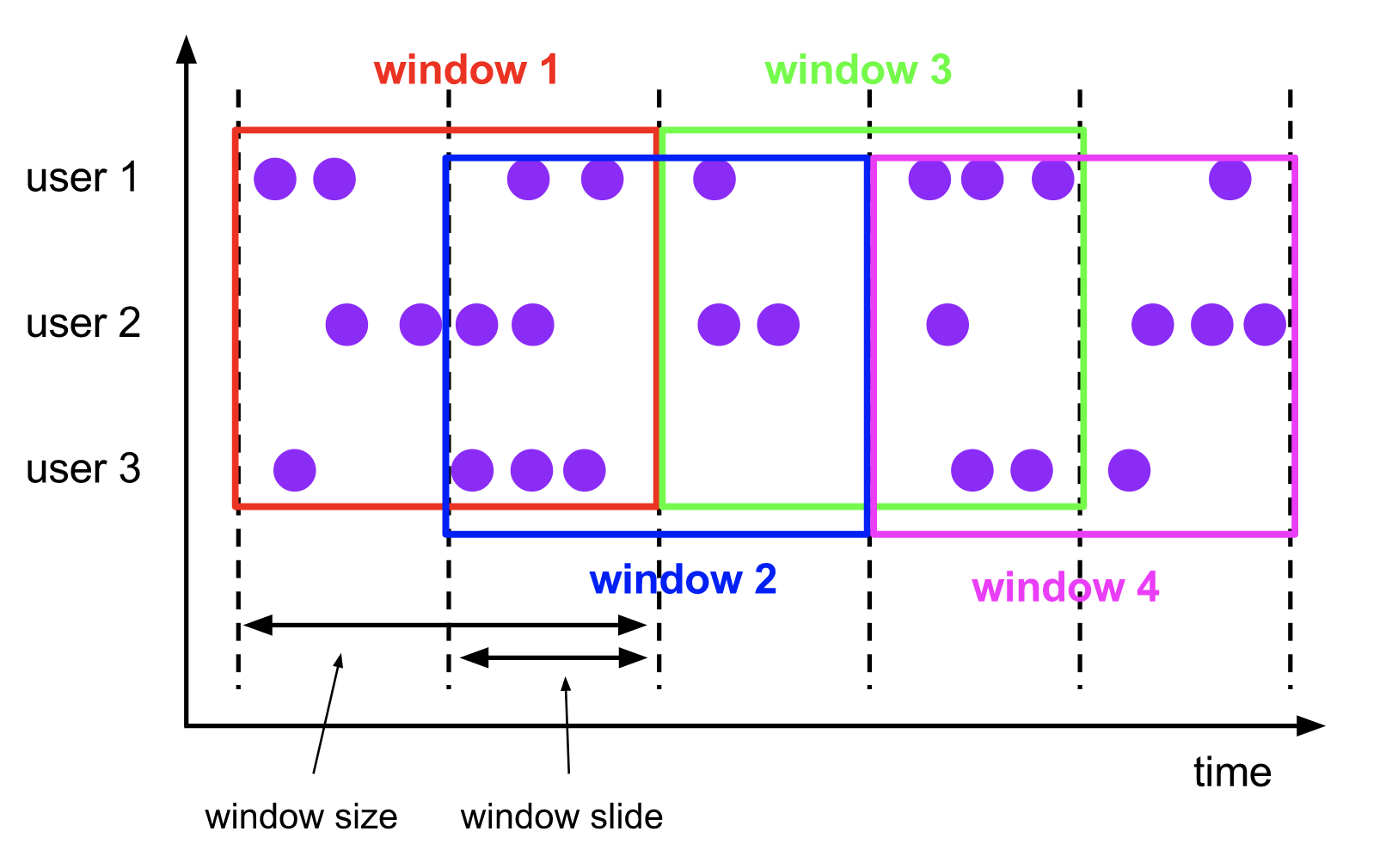
> The `sliding windows` assigner assigns elements to windows of fixed length. Similar to a tumbling windows assigner, the size of the windows is configured by the window size parameter. An additional window slide parameter controls how frequently a sliding window is started. Hence, sliding windows can be overlapping if the slide is smaller than the window size. In this case elements are assigned to multiple windows.
滑動視窗將事件分配到大小固定且允許相互重疊的桶中,這意味著每個事件可能會同時屬於多個桶。
> For example, you could have windows of size 10 minutes that slides by 5 minutes. With this you get every 5 minutes a window that contains the events that arrived during the last 10 minutes as depicted by the following figure.
我們通過指定長度(`size`)和滑動間隔(`slide`)來定義滑動視窗。滑動間隔決定每隔多久生成一個新的桶。舉個例子,`SlidingTimeWindows(size = 10min, slide = 5min)`表示的語義是`每隔5分鐘統計一次最近10分鐘的資料`。
### 會話視窗
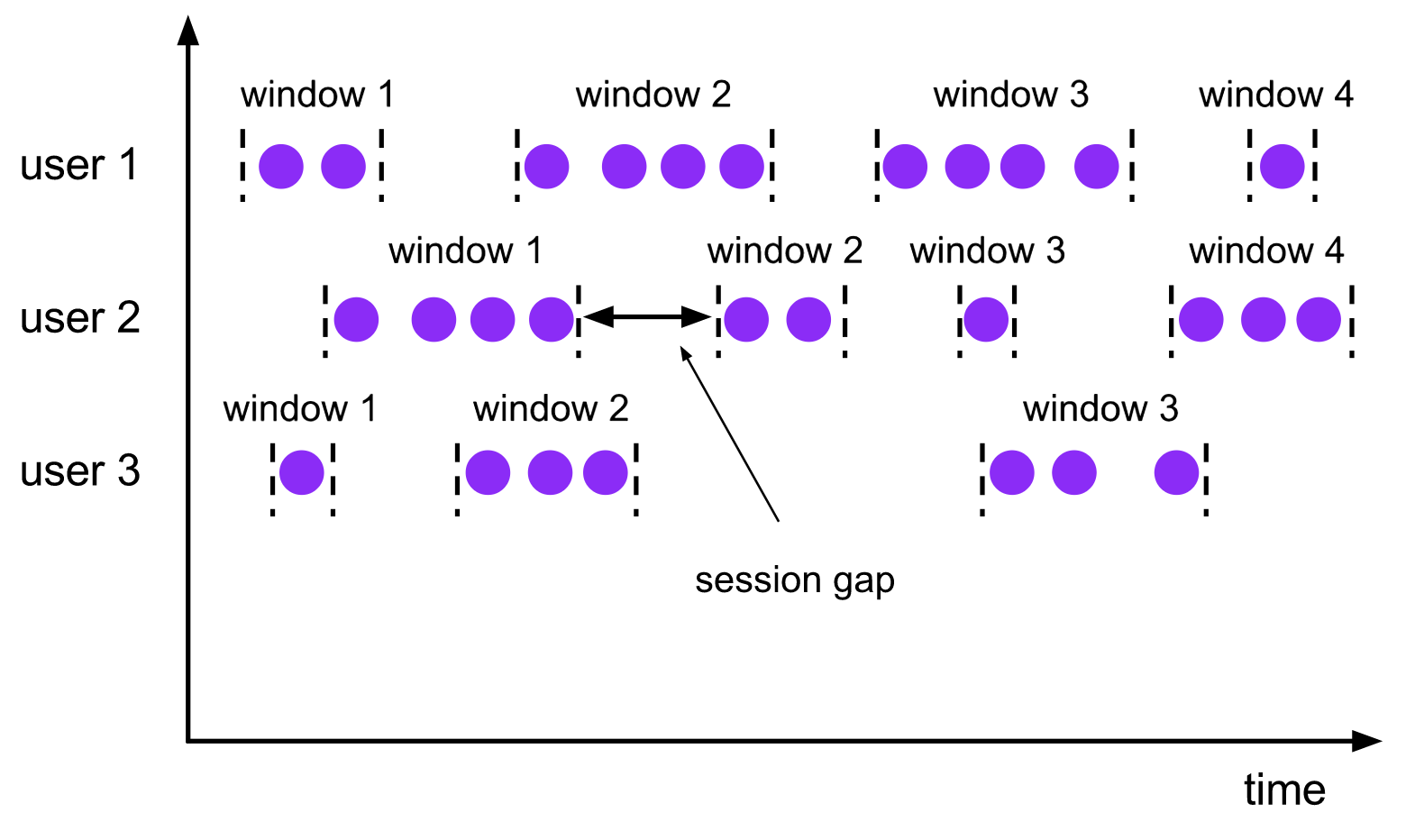
> The `session windows` assigner groups elements by sessions of activity. Session windows do not overlap and do not have a fixed start and end time, in contrast to tumbling windows and sliding windows. Instead a session window closes when it does not receive elements for a certain period of time, i.e., when a gap of inactivity occurred. A session window assigner can be configured with either a static session gap or with a session gap extractor function which defines how long the period of inactivity is. When this period expires, the current session closes and subsequent elements are assigned to a new session window.
會話視窗在一些實際場景中非常有用,這些場景既不適合用滾動視窗也不適合用滑動視窗。比如說,有一個應用要線上分析使用者行為,在該應用中我們要把事件按照使用者的同一活動或者會話來源進行分組。會話由發生在相鄰時間內的一系列事件外加一段非活動時間組成。具體來說,使用者瀏覽一連串新聞文章的互動過程可以看做是一個會話。由於會話長度並非預先定義好,而是和實際資料有關,所以無論是滾動還是滑動視窗都無法適用該場景。而我們需要一個視窗操作,能將屬於同一會話的事件分配到相同桶中。會話視窗根據會話間隔(`session gap`)將事件分為不同的會話,該間隔值定義了會話在關閉前的非活動時間長度。
## 時間語義
相關文件:`https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/timely-stream-processing.html`
上面介紹的幾種視窗型別都要在生成結果前緩衝資料,不難發現時間成了應用中較為核心的要素。舉例來說,運算元在計算時是應該依賴事件實際發生的時間還是應用處理事件的時間呢?這需要根據具體的應用場景來分析。
流式應用中有兩個不同概念的時間,即處理時間(`Processing time`)和事件時間(`Event time`)。如下圖所示:
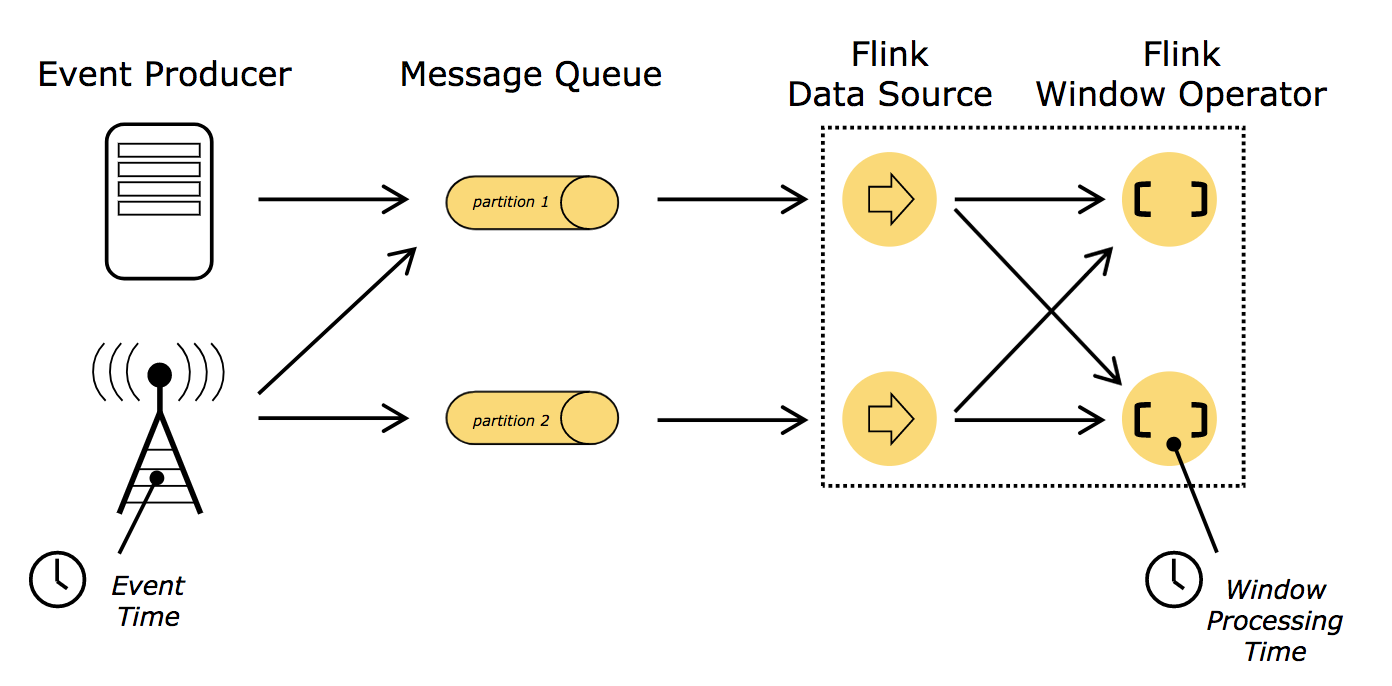
### 處理時間
> `Processing time`: Processing time refers to the system time of the machine that is executing the respective operation.
處理時間是當前流處理運算元所在機器上的本地時鐘時間。
基於處理時間的視窗會包含那些恰好在一段時間內到達視窗運算元的事件,這裡的時間段是按照機器上的本地時鐘時間測量的。
基於`處理時間`的操作結果是不可預測的,計算結果是不確定的。當資料流的處理速度與預期速度不一致、事件到達運算元的順序混亂、本地時鐘不正確,基於`處理時間`的視窗事件可能就會不一樣。
### 事件時間
> `Event time`: Event time is the time that each individual event occurred on its producing device. This time is typically embedded within the records before they enter Flink, and that event timestamp can be extracted from each record.
事件時間是資料流中事件實際發生的時間。它附加在事件自身,在進入流處理引擎(`Flink`)前就存在。
即便事件有延遲,依賴`事件時間`也能反映出真實發生的情況,從而能準確地將事件分配到對應的時間視窗。
基於`事件時間`的操作是可預測的,其結果具有確定性。無論資料流的處理速度如何、事件到達運算元的順序怎樣,基於`事件時間`的視窗都會生成同樣的結果。
使用事件時間要克服的挑戰之一是如何處理延遲事件。不能因為來了事件時間為一年前的事件,一年前的時間視窗就一直不關閉等待遲到事件的到來。這樣就引出了一個重要的問題:`怎麼決定事件時間視窗的觸發時機?`換言之,需要等待多久才能確定已經收到了所有發生在某個特定時間點之前的事件?
> The mechanism in Flink to measure progress in event time is `watermarks`. Watermarks flow as part of the data stream and carry a timestamp t. A Watermark(t) declares that event time has reached time t in that stream, meaning that there should be no more elements from the stream with a timestamp t’ <= t (i.e. events with timestamps older or equal to the watermark).
水位線(`watermark`)是一個全域性進度指標,表示確信不會再有延遲事件到來的某個時間點。本質上,水位線提供了一個邏輯時鐘,用來通知系統當前的事件時間。當一個運算元接收到時間為`t`的水位線,就可以認為不會再收到任何時間戳小於或者等於`t`的事件了。
水位線允許我們在結果的準確性和延遲之間做出取捨。激進的水位線策略保證了低延遲,但隨之而來的是低可信度。該情況下,延遲事件可能會在水位線之後到來,我們必須額外加一些程式碼來處理它們。反之,如果水位線過於保守,雖然可信度得以保證,但可能會無謂地增加了處理延遲。
實際應用中,系統可能難以獲取足夠多的資訊來完美確定水位線。流處理引擎需提供某些機制來處理那些晚於水位線的遲到事件。根據具體需求的不同,可能直接忽略這些事件,可能將它們寫入日誌,或者利用它們修正之前的結果。
### 小結
既然事件時間能解決大多數問題,為何還要去關心處理時間呢?事實上,處理時間也有其適用的場景。處理時間視窗能夠將延遲降至最低。由於無需考慮遲到或亂序的事件,視窗只需簡單地緩衝事件,然後在達到特定時間後立即觸發視窗計算即可。因此,對於那些更重視處理速度而非準確度的應用,處理時間就會派上用場。另一種場景是,你需要週期性地實時報告結果而無論其準確性如何。例如,你想觀察資料流的接入情況,通過計算每秒大致的事件數來檢測資料中斷,就可以使用處理時間來進行視窗計算。
總而言之,雖然處理時間提供了較低的延遲,但它的結果依賴處理速度,具有不確定性。事件時間則與之相反,能保證結果的相對準確性,並允許你處理延遲或無序的事件。
## 如何評測流處理的效能
對於`批處理應用`而言,作業的總執行時間通常會作為效能評測的一個方面。但`流式應用`事件無限輸入、程式持續執行,沒有總執行時間的概念,所以常用延遲和吞吐來評測流式應用的效能。通常,我們希望系統低延遲、高吞吐。
`延遲`:表示處理一個事件所需的時間。即從接收事件至觀察到事件處理效果的時間間隔。比如說,平均延遲為10毫秒,表示平均每條資料會在10毫秒內處理;95%延遲為10毫秒則表示95%的事件會在10毫秒內處理。保證低延遲對很多流式應用(告警系統、網路監測、詐騙識別、風險控制等)至關重要,從而滋生出所謂的`實時應用`。
`吞吐`:表示單位時間可以處理多少事件。可用來衡量系統的處理速度。但要注意,處理速度還取決於資料到來速度,因此,吞吐低不一定意味著系統性能差。在流處理應用中,通常希望系統有能力應對以最大速度到來的事件,即系統滿負載時的效能上限(`峰值吞吐`)。實際生產中,一旦事件到達速度過高導致系統處理不過來,系統就會被迫開始緩衝事件。若此時系統吞吐已到極限,再提高事件到達速度只會讓延遲更大。如果系統還繼續以力不能及的高速度接收事件,那麼緩衝區可能會用盡。這種情況通常被稱為背壓(`backpressure`),我們有多種可選策略來處理它。flink系列後續會有文章重點介紹這塊。
## 參考資料
- [1] [Fabian Hueske & Vasiliki Kalavri 著,崔星燦 譯;基於Apache Flink的流處理(Stream Processing with Apache Flink);中國電力出版社,2020]
- [2] [Apache Flink Documentation v1.11](https://ci.apache.org/projects/flink/flink-docs-release