
Torrent檔案的解析與轉換
阿新 • • 發佈:2020-11-13
# Torrent簡介
BitTorrent協議的**種子檔案**(英語:Torrent file)可以儲存一組檔案的元資料。這種格式的檔案被BitTorrent協議所定義。副檔名一般為“.torrent”。
.torrent種子檔案本質上是文字檔案,包含Tracker資訊和檔案資訊兩部分。Tracker資訊主要是BT下載中需要用到的Tracker伺服器的地址和針對Tracker伺服器的設定,檔案資訊是根據對目標檔案的計算生成的,計算結果根據BitTorrent協議內的Bencode規則進行編碼。它的主要原理是需要把提供下載的檔案虛擬分成大小相等的塊,塊大小必須為2k的整數次方(由於是虛擬分塊,硬碟上並不產生各個塊檔案),並把每個塊的索引資訊和Hash驗證碼寫入種子檔案中;所以,種子檔案就是被下載檔案的“索引”。
# Torrent結構
Torrent檔案內容都已Bencoding編碼型別進行儲存,整體上是一個字典結構,見下:
## Torrent總體結構
| 鍵名稱 | 資料型別 | 可選項 | 鍵值含義 |
| ------------- | ---------- | -------- | ---------------------------------------------------------- |
| announce | string | required | Tracker的Url |
| info | dictionary | required | 該條對映到一個字典,該字典的鍵將取決於共享的一個或多個檔案 |
| announce-list | array[] | optional | 備用Tracker的Url,以列表形式存在 |
| comment | string | optional | 備註 |
| created by | string | optional | 建立人或建立程式的資訊 |
## Torrent單檔案Info結構
| 鍵名稱 | 資料型別 | 可選項 | 鍵值含義 |
| ------------ | -------- | -------- | ----------------------------- |
| name | string | required | 建議儲存到的檔名稱 |
| piceces | byte[] | required | 每個檔案塊的SHA-1的整合Hash。 |
| piece length | long | required | 每個檔案塊的位元組數 |
## Torrent多檔案Info結構
| 鍵名稱 | 資料型別 | 可選項 | 鍵值含義 |
| ------------ | -------- | -------- | ---------------------------------- |
| name | string | required | 建議儲存到的目錄名稱 |
| piceces | byte[] | required | 每個檔案塊的SHA-1的整合Hash。 |
| piece length | long | required | 每個檔案塊的位元組數 |
| files | array[] | required | 檔案列表,列表儲存的內容是字典結構 |
**files字典結構:**
| 鍵名稱 | 資料型別 | 可選項 | 鍵值含義 |
| ------ | -------- | -------- | ------------------------------------------------------ |
| path | array[] | required | 一個對應子目錄名的字串列表,最後一項是實際的檔名稱 |
| length | long | required | 檔案的大小(以位元組為單位) |
## Torrent實際結構預覽
以`JSON`序列化整個字典後,單檔案和多檔案的結構大致如下,**注意:JSON內容省略了pieces摘要大部分內容,僅展示了開頭部分,另外由於本人序列化工具設定所致,所有的整型都會序列化成字串型別。**
- 單檔案結構
```json
{
"creation date": "1581674765",
"comment": "dynamic metainfo from client",
"announce-list": [
[
"udp://tracker.leechers-paradise.org:6969/announce"
],
[
"udp://tracker.internetwarriors.net:1337/announce"
],
[
"udp://tracker.opentrackr.org:1337/announce"
],
[
"udp://tracker.coppersurfer.tk:6969/announce"
],
[
"udp://tracker.pirateparty.gr:6969/announce"
]
],
"created by": "go.torrent",
"announce": "udp://tracker.leechers-paradise.org:6969/announce",
"info": {
"pieces": "レJᅯ\ufff4ᅯ*f\nᄍ\ufff0... ...",
"length": "54358058387",
"name": "Frozen.II.2019.BDREMUX.2160p.HDR.seleZen.mkv",
"piece length": "16777216"
}
}
```
- 多檔案結構
```json
{
"creation date": "1604347014",
"comment": "Torrent downloaded from https://YTS.MX",
"announce-list": [
[
"udp://tracker.coppersurfer.tk:6969/announce"
],
[
"udp://9.rarbg.com:2710/announce"
],
[
"udp://p4p.arenabg.com:1337"
],
[
"udp://tracker.internetwarriors.net:1337"
],
[
"udp://tracker.opentrackr.org:1337/announce"
]
],
"created by": "YTS.AG",
"announce": "udp://tracker.coppersurfer.tk:6969/announce",
"info": {
"pieces": "ᆲimᅬヒ\u000b*゚ᆲト... ...",
"name": "Love And Monsters (2020) [2160p] [4K] [WEB] [5.1] [YTS.MX]",
"files": [
{
"path": [
"Love.And.Monsters.2020.2160p.4K.WEB.x265.10bit.mkv"
],
"length": "5215702961"
},
{
"path": [
"www.YTS.MX.jpg"
],
"length": "53226"
}
],
"piece length": "524288"
}
}
```
# Torrent檔案編碼
根據上文所說,Torrent檔案均以Bencoding編碼進行儲存,故我們需要大致瞭解一下Bencoding編碼。
Bencoding以四種基本型別資料構成:
- string : 字串
- intergers : 整數型別
- lists:列表型別
- dictionary:字典型別
## 字串型別
字串型別由以下結構表示:`字串長度:字串原文`,例如:`42:udp://tracker.pirateparty.gr:6969/announce`。
## 整形型別
整型型別由以下結構表示:`i<整形資料>e`,例如`i1234e`,則表明的整形資料為1234。
## 列表型別
列表型別由以下結構表示:`l<列表資料>e`,即列表以字母`l`開頭,以字母`e`結束,中間的均為列表中的資料,中間的值可以為任意的四種類型之一。
## 字典型別
字典型別由以下結構表示:`d<字典資料>e`,即字典由字母`d`開頭,以字母`e`結束,中間的均為字典中的資料,中間的值可以為任意的四種類型之一。
## 實際組合解析
根據上述描述來看看實際的內容解析,我們以下方的資料為例:
```
d8:announce49:udp://tracker.leechers-paradise.org:6969/announce13:announce-listll49:udp://tracker.leechers-paradise.org:6969/announceel48:udp://tracker.internetwarriors.net:1337/announceeee
```
大家可以先嚐試根據上面的內容對這一串內容進行解析,我將這一串資料拆分開來方便大家理解和檢視,可以明顯看出其由一個擁有兩個鍵值的字典,其中一個鍵為`announce`,另一個鍵為`announce-list`,兩者的值一個為`udp://tracker.leechers-paradise.org:6969/announce`,一個為列表,列表內還嵌套了一層列表。
```
d
8:announce
49:udp://tracker.leechers-paradise.org:6969/announce
13:announce-list
l
l
49:udp://tracker.leechers-paradise.org:6969/announce
e
l
48:udp://tracker.internetwarriors.net:1337/announce
e
e
e
```
# Torrent檔案解析
根據上文對Torrent檔案編碼的瞭解,那麼我們使用程式碼對Torrent檔案就很簡單了。我們只需要讀取種子位元組流,判斷具體是哪種型別並進行相應轉換即可。
即:讀取檔案位元組,判斷位元組屬於哪一種型別:0-9 : 字串型別、i:整形資料、l:列表資料、d:字典資料
再根據每個資料具體型別獲取該資料的內容,再讀取下一個檔案位元組獲取下一個資料型別即可,根據這個分析,虛擬碼如下:
## 獲取字串值
```java
// 當讀取到位元組對應的內容為0-9時進入該方法
String readString(byte[] info,int offset) {
// 讀取‘:’以前的資料,即字串長度
int length = readLength(info,offset);
// 根據字串長度,獲取實際字串內容
string data = readData(info,length,offset);
// 返回讀取到的字串內容,整個讀取過程中讀過的偏移量要累加到offset
return data;
}
```
## 獲取整數型別
這裡有一個注意項,考慮到資料邊界問題,例如`java`等語言,推薦使用`Long`型別,以防資料越界。
```java
// 當讀取到的位元組對應的內容為i時,進入該方法
Long readInt(byte[] info,int offset) {
// 讀取第一個'e'之前的資料,包括'e'
string data = readInt(info,offset)
return Long.valueOf(data);
}
```
## 獲取列表型別
因為列表型別中可以夾雜所有四種類型中任意要給即需要用到上面兩個方法。
```java
// 當讀取到的位元組對應的內容為l時,進入該方法
List readList(byte[] info,int offset){
List list = new List();
// 讀取到第一個'e'為止
while(info[offset] != 'e'){
swtich(info[offset]){
// 如果是列表,讀取列表並向列表新增
case 'l':
list.add(readList(info,offset));
break;
// 如果是字典,讀取字典並向列表新增
case 'd':
list.add(readDictionary(info,offset));
break;
// 如果是整形資料,讀取資料並向列表新增
case 'i':
list.add(readInt(info,offset));
break;
// 如果是字串,讀取字串資料並向列表新增
case '0-9':
list.add(readString(info,offset));
}
}
// offset向前移一位,把列表的結束符'e'移動為已讀
offset++;
return list;
}
```
## 讀取字典型別
讀取字典型別與列表十分相似,唯一不同的就是需要區分鍵值,**字典的鍵只可能為字串**,故依次來判斷。
```java
// 當讀取到的位元組對應的內容為d時,進入該方法
Dictionary readDictionary(byte[] info,int offset){
Dictionary dic = new Dictionary();
// key為null時,字串為鍵,否則為值
String key = null;
// 讀取到第一個'e'為止
while(info[offset] != 'e'){
swtich(info[offset]){
// 如果是列表,讀取列表並向字典新增,新增列表時肯定存在鍵,直接新增並將鍵置空
case 'l':
dic.put(key,readList(info,offset));
key = null;
break;
// 如果是字典,讀取字典並向字典新增,新增字典時肯定存在鍵,直接新增並將鍵置空
case 'd':
dic.put(key,readDictionary(info,offset));
key = null;
break;
// 如果是整形資料,讀取資料並向字典新增,新增整形資料時肯定存在鍵,直接新增並將鍵置空
case 'i':
dic.put(key,readInt(info,offset));
key = null;
break;
// 如果是字串
case '0-9':
string data = readString(info,offset);
// key為null時,字串為鍵,否則為值
if(key == null){
key = data;
}else{
dic.put(key,data);
key = null;
}
}
}
// offset向前移一位,把列表的結束符'e'移動為已讀
offset++;
return dic;
}
```
# Torrent檔案與Magnet
磁力連結與Torrent檔案是可以相互轉換的,此文只討論根據Torrent檔案如何轉換為Magnet磁力連結。
## Magnet概述
磁力連結由一組引數組成,引數間的順序沒有講究,其格式與在HTTP連結末尾的查詢字串相同。最常見的引數是"xt",是"exact topic"的縮寫,通常是一個特定檔案的內容雜湊函式值形成的URN,例如:
```
magnet:?xt=urn:bith:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C
```
注意,雖然這個連結指向一個特定檔案,但是客戶端應用程式仍然必須進行搜尋來確定哪裡,如果有,能夠獲取那個檔案(即通過DHT進行搜尋,這樣就實現了Magnet到Torrent的轉換,本文不討論)。
部分欄位名見下方表格:
| 欄位名 | 含義 |
| ------ | ------------------------------------------------------------ |
| magnet | 協議名 |
| xt | exact topic的縮寫,包含檔案雜湊值的統一資源名稱。BTIH(BitTorrent Info Hash)表示雜湊方法名,這裡還可以使用ED2K,AICH,SHA1和MD5等。這個值是檔案的識別符號,是不可缺少的。 |
| dn | display name的縮寫,表示向用戶顯示的檔名。這一項是選填的。 |
| tr | tracker的縮寫,表示tracker伺服器的地址。這一項也是選填的。 |
| bith | BitTorrent info hash,種子雜湊函式 |
## Torrent轉換為Magnet
- dn : 向用戶顯示的檔名
即為Torrent檔案中,Info字典下的name鍵所對應的值
- tr : tracker伺服器地址
即為Torrent檔案中,announce以及announce-list兩個鍵所對應的值
- bitch : 種子雜湊值
即為Torrent檔案中,info對應的字典的SHA1雜湊值(Hex)
根據下圖,為`4:infod`,以`d`的地址作為雜湊原文的起始索引,則為Adress:00 01A3
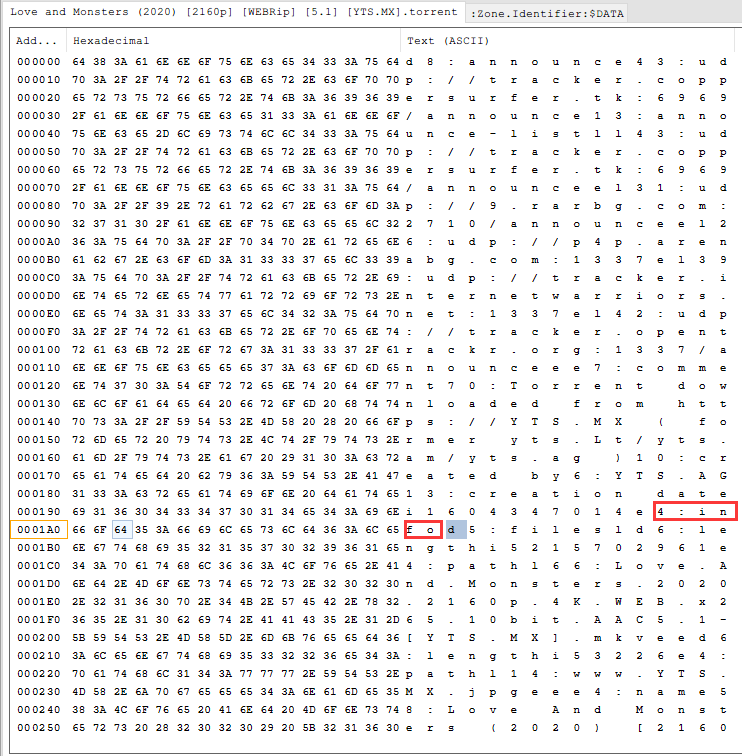
到整個info結束,以`e`的地址作為雜湊原文的終止索引地址,則為Adress:03 0BE7

根據上述可知:
```
magnet = 'magnet:?xt=urn:btih:'+Hex(Sha1(info))+'&dn='+encode(name)+'&tr='+encode(announce)
```
結合上一部分的實現,我們可以在讀取info時記錄startindex和endindex,即:
```java
Dictionary readDictionary(byte[] info,int offset){
//...
case 'd':
bool record = key == 'info';
if(record){
startindex = offset;
}
readDictoinary(info,offset);
if(record){
endindex = offset
}
}
string getBith(byte[] info,int start,int end){
// 獲取info中從start到end的位元組陣列,並對其進行摘要計算
byte[] infoByte = new byte[infoEnd - infoStart + 1];
System.arraycopy(torrentBytes, infoStart, infoByte, 0, infoEnd - infoStart + 1);
return Hex.toHex(Sha1.toSha1(infoByte));
}
```
# 具體實現
本人通過Java實現了以上部分邏輯(Torrent檔案解析以及Magnet連結生成),若有需要參考的讀者可以到以下網址獲取相關內容:
工具類目錄:https://github.com/Rekent/common-utils/tree/master/src/main/java/com/rekent/tools/utils/torrent
解析類原始碼:https://github.com/Rekent/common-utils/blob/master/src/main/java/com/rekent/tools/utils/torrent/TorrentFileResovler.java
依賴jar包:https://github.com/Rekent/common-utils/releases/tag/v0.0.3
呼叫方式:
```java
public void testResolve() throws Exception {
String path = "C:\\Users\\Refkent\\Downloads\\Test.torrent";
TorrentFile torrentFile = TorrentFileUtils.resolve(path);
System.out.println(torrentFile.print());
System.out.println(torrentFile.getHash());
System.out.println(torrentFile.getMagnetUri());
}
```
# Reference
- [Wiki - 種子檔案](https://bk.tw.lvfukeji.com/wiki/%E7%A7%8D%E5%AD%90%E6%96%87%E4%BB%B6)
- [Wiki - 磁力連結](https://bk.tw.lvfukeji.com/wiki/%E7%A3%81%E5%8A%9B%E9%93%BE%E6%8E%A5)
- [Blog - BT種子檔案(.torrent)的具體檔案結構](https://blog.csdn.net/m0_37889044/article/details/10