
flink:JobGraph生成過程分析
阿新 • • 發佈:2020-11-28
1、JobGraph是由StreamGraph轉換而來,當client將StreamGraph提交後,job啟動前會先完成轉換,統一的轉換入口如下:

2、StreamingJobGraphGenerator類
StreamingJobGraphGenerator的職責就是將StreamGraph轉換成JobGraph,在轉換的過程中要根據StreamGraph中的節點及邊的對應關係進行運算元鏈的合併,同時將一些其他與任務執行相關聯的資訊複製過來,接下來主要需要關注其中的構造方法、轉換方法、判斷能否合併的邏輯、運算元合併的方法、StreamNode轉換為JobVertex等幾個核心方法即可梳理清楚其轉換的業務
2.1、構造方法
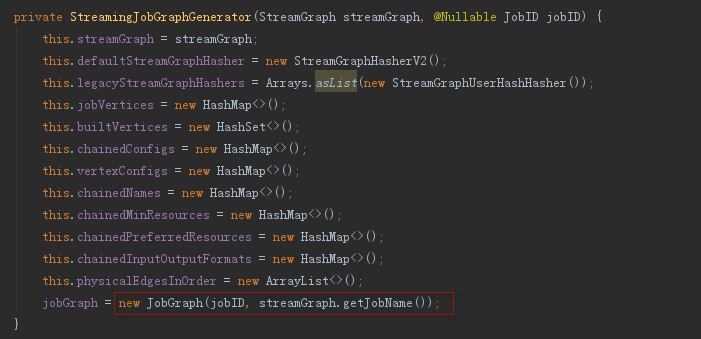
其構造方法中主要包含三個內容,儲存了StreamGraph、構造了JobGraph、同時new了一系列的集合容器用於儲存轉換的中間態
2.2、轉換方法createJobGraph
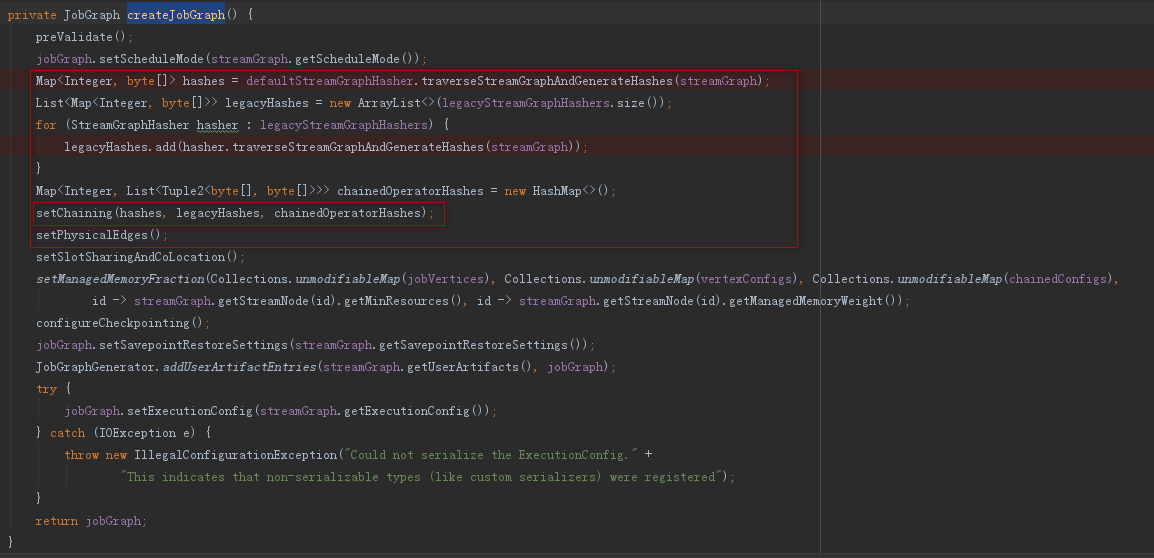
createJobGraph方法中邏輯很清晰,除了合併運算元就是複製一些其他執行引數
2.3、setChaining和createChain方法
在這兩處完成了運算元的合併核心邏輯,其實就是根據能否chain的判定進行不同的處理,其步驟可以歸納為:

a、因為在StreamGraph中已經形成了完整的DAG圖,此處直接遍歷source節點,從source節點往後挨個去createChain
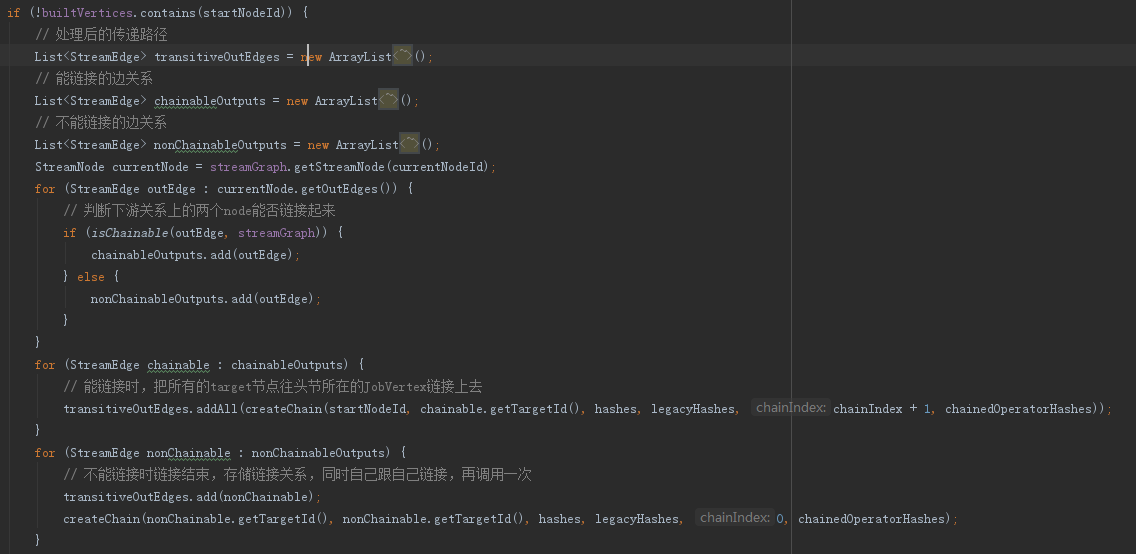
b,createChain時先拿到當前節點的下游節點,然後遞迴處理,構建出整個的傳遞鏈
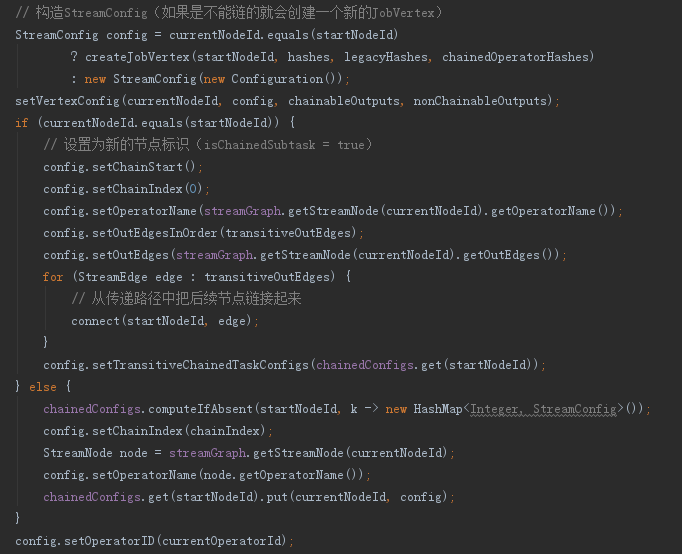
c、在構造JobVertex時,如果從前面傳遞過來的兩個節點ID相同,則證明是頭結點,則生成一個JobVertex,並將傳遞鏈中的後續運算元connect起來,如果不是則表示應當是被合併的運算元,則僅維護StreamConfig即可
d、於此同時也維護好對應的執行資源資料、格式化資料等
2.4、能否chain成鏈的判斷邏輯
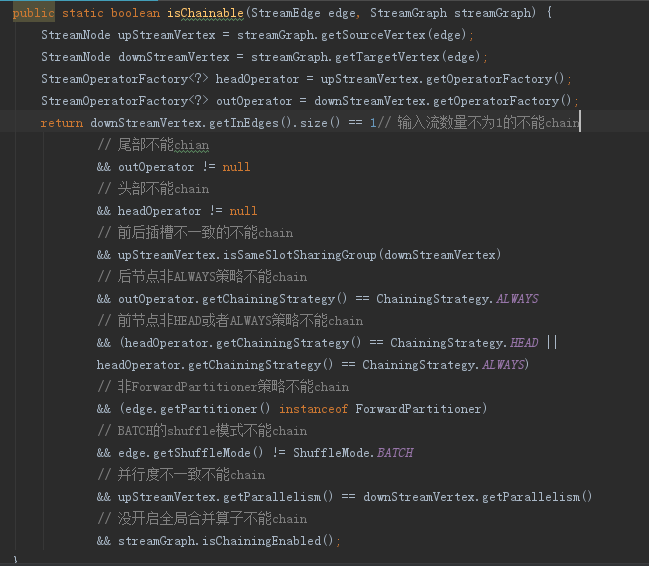
判斷很簡潔明瞭,不再贅述
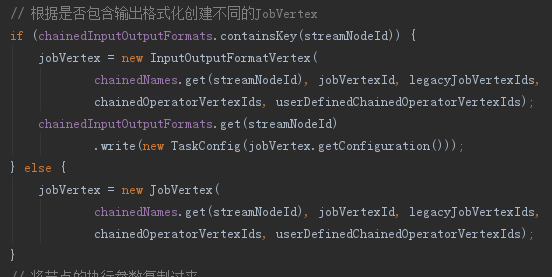
2.5、createJobVertex
如果是頭結點時就將頭節點轉化為一個JobVertex,此處有InputOutputFormatVertex和JobVertex的區別
2.6 connect
此處就是根據不同的策略,將傳遞鏈上的對應關係維護到一個JobEdge中去。
最後,總的來看由於在StreamGraph中已經構建好了DAG的關係和對映,在StreamingJobGraphGenerator將這個對映關係再次優化而已,在此過程中還涉及到JobGraph、JobVertex、JobEdge等物件,這些可以對比StreamGraph、StreamNode和StreamEdge更容易