
影象分割必備知識點 | Unet++超詳解+註解
阿新 • • 發佈:2020-12-03
文章來自周縱葦大佬的知乎,是Unet++模型的一作大佬,其在2019年底詳細剖析了Unet++模型,講解的非常好。所以在此做一個搬運+個人的理解。 **文中加粗部分為個人做的註解**。需要討論交流的朋友可以加我的微信:cyx645016617,也可以加入我建立的一個氛圍超好的AI演算法交流群。我只是一個在智慧演算法路上緩慢前行的應屆混子。
參考目錄:
[TOC]
## 1 鋪墊
在計算機視覺領域,全卷積網路(FCN)是比較有名的影象分割網路,醫學影象處理方向,U-Net可以說是一個更加炙手可熱的網路,基本上所有的分割問題,我們都會拿U-Net先看一下基本的結果,然後進行“魔改”。
U-Net和FCN非常的相似,U-Net比FCN稍晚提出來,但都發表在2015年,和FCN相比,U-Net的第一個特點是完全對稱,也就是左邊和右邊是很類似的,而FCN的decoder相對簡單,只用了一個deconvolution的操作,之後並沒有跟上卷積結構。第二個區別就是skip connection,FCN用的是加操作(summation),U-Net用的是疊操作(concatenation)。這些都是細節,重點是它們的結構用了一個比較經典的思路,也就是編碼和解碼(encoder-decoder),早在2006年就被Hinton大神提出來發表在了nature上.
當時這個結構提出的主要作用並不是分割,而是壓縮影象和去噪聲。輸入是一幅圖,經過下采樣的編碼,得到一串比原先影象更小的特徵,相當於壓縮,然後再經過一個解碼,理想狀況就是能還原到原來的影象。這樣的話我們存一幅圖的時候就只需要存一個特徵和一個解碼器即可。這個想法我個人認為是很漂亮了。同理,這個思路也可以用在原影象去噪,做法就是在訓練的階段在原圖人為的加上噪聲,然後放到這個編碼解碼器中,目標是可以還原得到原圖。
後來把這個思路被用在了影象分割的問題上,也就是現在我們看到的U-Net結構,在它被提出的三年中,有很多很多的論文去講如何改進U-Net或者FCN,不過這個分割網路的本質的拓撲結構是沒有改動的。舉例來說,去年ICCV上凱明大神提出的Mask RCNN. 相當於一個檢測,分類,分割的集大成者,我們仔細去看它的分割部分,其實使用的也就是這個簡單的FCN結構。說明了這種“U形”的編碼解碼結構確實非常的簡潔,並且最關鍵的一點是好用。
簡單的過一下這個網紅結構,我們先提取出它的拓撲結構,這樣會比較容易分析它的實質,排除很多細節的干擾。
輸入是一幅圖,輸出是目標的分割結果。繼續簡化就是,一幅圖,編碼,或者說降取樣,然後解碼,也就是升取樣,然後輸出一個分割結果。根據結果和真實分割的差異,反向傳播來訓練這個分割網路。我們可以說,U-Net裡面最精彩的部分就是這三部分:
- 下采樣;
- 上取樣;
- skip connection **(這個就是下采樣和上取樣得到的相同尺度的特徵度在通道維度上的拼接,concatenate)**
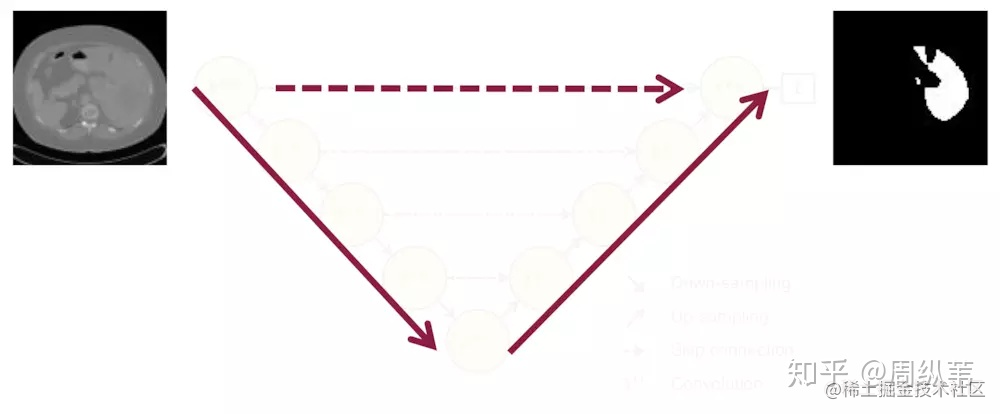
**這個圖中的續建表示一個直觀的模型處理過程,分割任務的輸出和輸入的維度相同;至於向下的實線,表示需要對圖片降取樣(encode過程),向上的實線表示對圖片進行上取樣(decode過程),上一篇講解的Unet很好的體現了這個過程**
超連結
## 2 展開
基本的鋪墊都已經完成了,看著這個拓撲結構,一個非常廣義的問題就是:
這個三年不動的拓撲結構真的一點兒毛病都沒有嗎?
在這三年中,U-Net得到的超過2500次的引用,FCN接近6000次的引用,大家都在做什麼樣的改進呢?如果讓你在這個經典的結構基礎上改進,你會去關注哪些點呢?
首先一個問題是:要多深合適?
這裡我想強調的一點是,很多論文給出了他們建議的網路結構,其中包括非常多的細節,比如用什麼卷積,用幾層,怎麼降取樣,學習率多少,優化器用什麼,這些都是比較直觀的引數,其實這些在論文中給出引數並不見得是最好的,所以關注這些的意義不大,一個網路結構,我們真正值得關注的是它的設計傳達了什麼資訊。就拿U-Net來說,原論文給出的結構是原圖經過四次降取樣,四次上取樣,得到分割結果,實際呢,為什麼四次?就是作者喜歡唄,或者說當時作者使用的資料集,四次降取樣的效果好,我們也可以更再專業一點,四次降取樣的接受域或者感受野大小正合適處理影象。或者四次降取樣比較適合輸入影象的尺寸等等,理由一堆,但是你們真的相信嗎?不見得吧。
我先給一個2017年在CVPR上發表的一個名叫PSPNet的分割網路,你會發現,好像整體的架構和U-Net還是像的,只是降取樣的數目減小了,當然,他們也針對性的增強了中間的特徵抓取環節的複雜性。
要是你覺得這個工作還不夠說明4次降取樣不是必須的話,我們再來看看Yoshua Bengio組最近的關於影象分割的論文,這是他們提出的結構,名叫提拉米蘇。
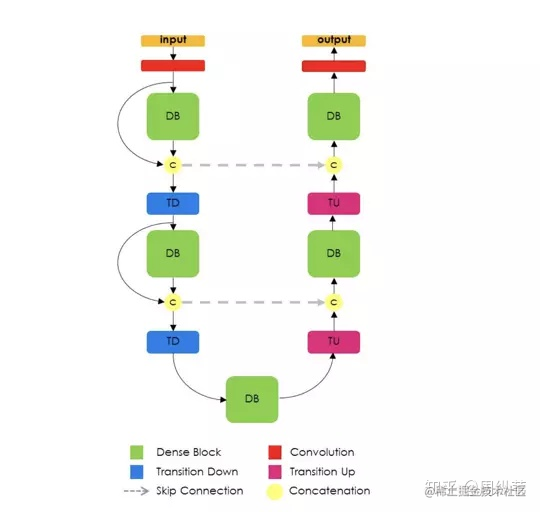
也是U形結構,但你會發現,他們就只用了三次降取樣。所以到底要多深,是不是越深越好?還是一個open quesion。
我想分享的第一個資訊就是:關注論文所傳遞的大方向,不要被論文中的細節侷限了創造力。像這種細節引數的調整是屬於比較樸素的深度學習方法論,很容易花費你很多時間,而最終並沒有自身科研水平的提升。
好,我們回來繼續討論到底需要多深的問題。其實這個是非常靈活的,涉及到的一個點就是特徵提取器,U-Net和FCN為什麼成功,因為它相當於給了一個網路的框架,具體用什麼特徵提取器,隨便。這個時候,高引就出現了,各種在encoder上的微創新絡繹不絕,最直接的就是用ImageNet裡面的明星結構來套嘛,前幾年的BottleNeck,Residual,還有去年的DenseNet,就比誰出文章快。這一類的論文就相當於從1到10的遞進,而U-Net這個低層結構的提出卻是從0到1。說句題外話,像這種從1到10的論文,引用往往不會比從0到1的論文高,因為它不自覺的侷限了自己的擴充套件空間,比如我說,我寫一篇論文,說特徵提取器就必須是dense block,或者必須是residual block效果好,然後名字也就是DenseUNet或者ResUNet,就這樣結束了。所以關於backbone到底用什麼的問題,並不是我這次要講的重點。
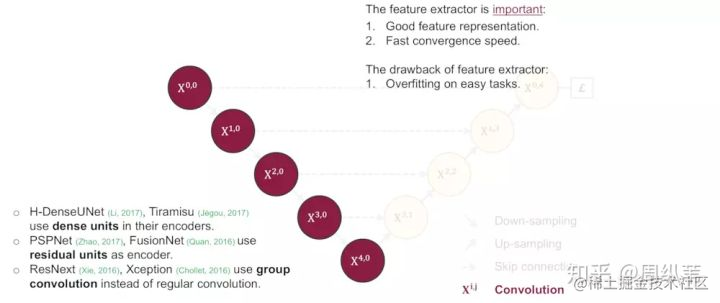
關於到底要多深這個問題,還有一個引申的問題就是,降取樣對於分割網路到底是不是必須的?問這個問題的原因就是,既然輸入和輸出都是相同大小的圖,為什麼要折騰去降取樣一下再升取樣呢?
比較直接的回答當然是降取樣的理論意義,我簡單朗讀一下,它可以增加對輸入影象的一些小擾動的魯棒性,比如影象平移,旋轉等,減少過擬合的風險,降低運算量,和增加感受野的大小。升取樣的最大的作用其實就是把抽象的特徵再還原解碼到原圖的尺寸,最終得到分割結果。
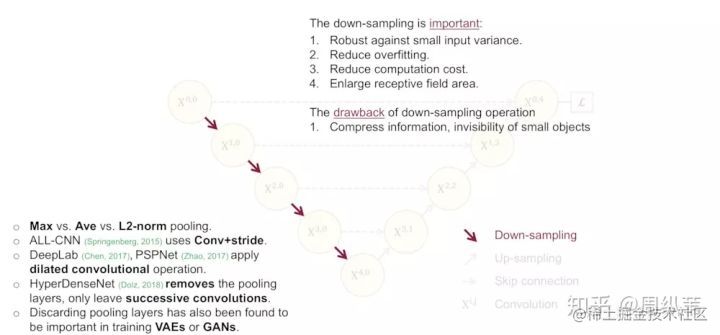

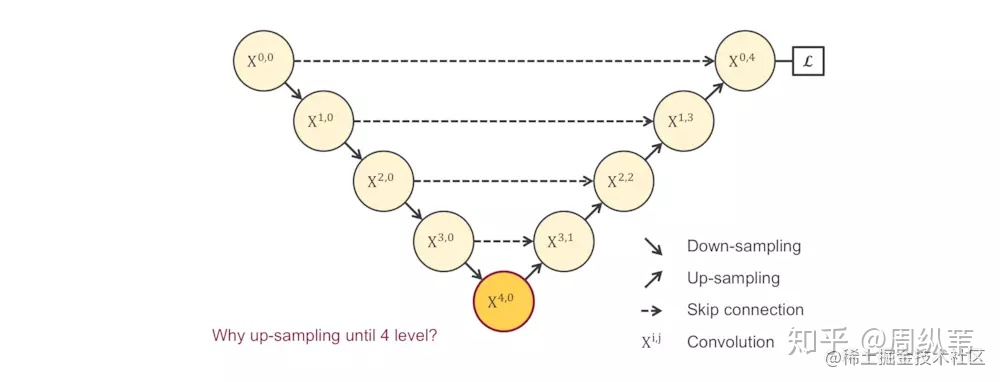
這些理論的解釋都是有道理的,在我的理解中,對於特徵提取階段,淺層結構可以抓取影象的一些簡單的特徵,比如邊界,顏色,而深層結構因為感受野大了,而且經過的卷積操作多了,能抓取到影象的一些說不清道不明的抽象特徵,講的越來越玄學了,總之,淺有淺的側重,深有深的優勢。那我就要問一個比較犀利的問題了,既然淺層特徵和深層特徵都很重要,U-Net為什麼只在4層以後才返回去,也就是隻去抓深層特徵。我不知道有沒有說明白這個問題本身。問題實際是這樣的,看這個圖,既然 $X^{1.0}$,$X^{2.0}$,$X^{3.0}$,$X^{4.0}$所抓取的特徵都很重要,為什麼我非要降到 $X^{4.0}$ 層了才開始上取樣回去呢?
## 3 主體
沿著這個邏輯往下捋,不知道大家能否猜到我的下一頁會放什麼?此處可以摁個暫停。有沒有呼之欲出了?如果排除一切其他干擾,既然我們不知道需要多深,是不是會衍生出一系列像這樣子的U-Net,它們的深度不一。這個不難理解吧。為了搞清楚是不是越深越好,我們應該對它們做一下實驗,看看它們各自的分割表現:
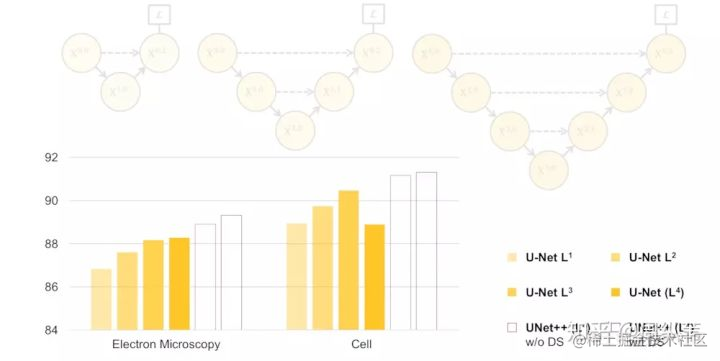
先不要看後兩個UNet++,就看這個不同深度的U-Net的表現,我們可以看出,不是越深越好吧,它背後的傳達的資訊就是,不同層次特徵的重要性對於不同的資料集是不一樣的,並不是說我設計一個4層的U-Net,就像原論文給出的那個結構,就一定對所有資料集的分割問題都最優。
那麼接下來是關鍵,我們心中的目標很明確了,就是使用淺層和深層的特徵!但是總不能訓練這些個U-Net吧,未免也太多了。好,這裡可以暫停一下,想一想,要你來,你怎麼來利用這些不同深度的,各自能抓取不同層次的特徵的U-Net。
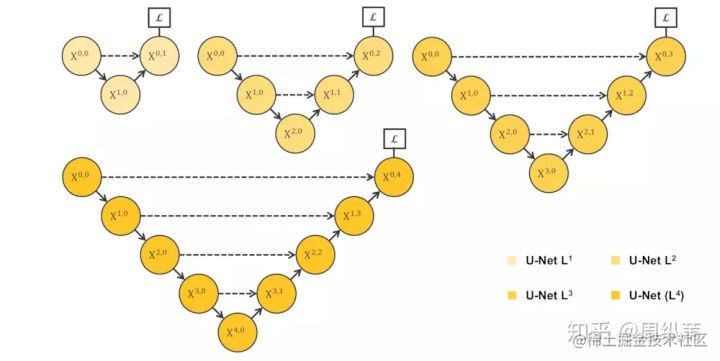
我把圖打出來就很簡單了。
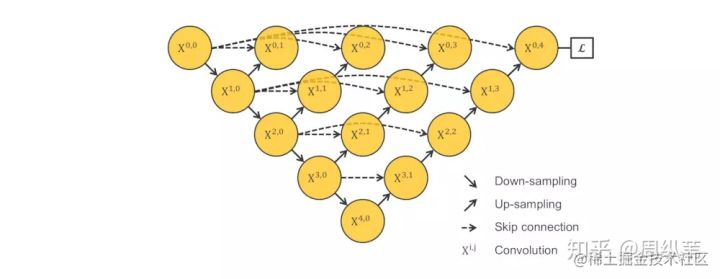
我們來看一看,這樣是不是把1~4層的U-Net全給連一起了。我們來看它們的子集,包含1層U-Net,2層U-Net,以此類推。這個結構的好處就是我不管你哪個深度的特徵有效,我乾脆都給你用上,讓網路自己去學習不同深度的特徵的重要性。第二個好處是它共享了一個特徵提取器,也就是你不需要訓練一堆U-Net,而是隻訓練一個encoder,它的不同層次的特徵由不同的decoder路徑來還原。這個encoder依舊可以靈活的用各種不同的backbone來代替。
可惜的是,這個網路結構是不能被訓練的,原因在於,不會由任何梯度會經過這個紅色區域,因為它和算loss function的地方是在反向傳播時是斷開的。我停頓一下,大家想一想是不是這麼回事。
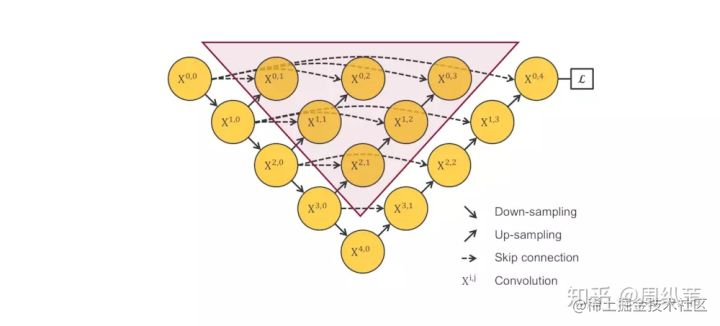
**這個不能梯度下降訓練的問題,仔細看一下圖中的虛線就明白了,三角形中的元素與最終的輸出是不連線的**
請問,如果是你,如何去解決這個問題?
其實既然已經把結構盤成這樣了,還是很自然能想到的吧,我這裡提供有兩個候選的解決方案。
第一個是用deep supervision,強行加梯度是吧,關於這個,我待會兒展開來說。
第二個解決方案是把結構改成這樣子:
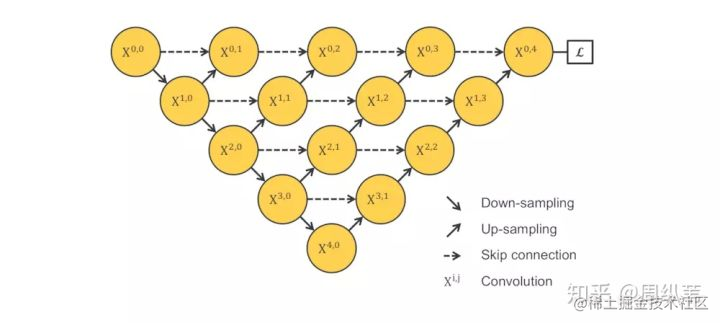
如果沒有我上面說的那一堆話來盤邏輯,這個結構可能不那麼容易想到,但是如果順著思路一步一步的走,這個結構雖然不能說是顯而易見,也算是順理成章的。我的故事還沒有講完,但是我提一句,這個結構由UC Berkeley的團隊提出,發表在今年(**2019年**)的CVPR上,是一個oral的論文,題目是"Deep Layer Aggregation"。
可能就有小夥伴驚呆了,就這樣嗎,就發了CVPR!?是,也不是。。。這只是他們在論文中給出的關於分割網路結構的改進,他們還做了其他的工作,包括分類,和邊緣檢測。但是主要的思路就是剛剛盤的那些,目標就是取整合各個不同層次的特徵。
這只是一個題外話哦,我們繼續來看這個結構,請問,你覺得有什麼問題?
為了回答這個問題,現在我們和上面那個結構對比一下,不難發現這個結構強行去掉了U-Net本身自帶的長連線。取而代之的是一系列的短連線。那麼我們來看看U-Net引以為傲的長連線(**skip-connection**)到底有什麼優點。
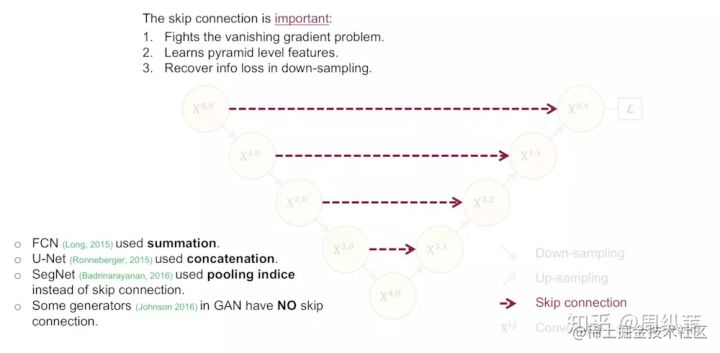
我們認為,U-Net中的長連線是有必要的,它聯絡了輸入影象的很多資訊,有助於還原降取樣所帶來的資訊損失,在一定程度上,我覺得它和殘差的操作非常類似,也就是residual操作,x+f(x)。我不知道大家是否同意這一個觀點。因此,我的建議是最好給出一個綜合長連線和短連線的方案。請問,這個方案在你的腦海中是什麼樣的呢?此處可暫停。
**其實我感覺,就是瘋狂的特徵拼接拼接拼接。。。**
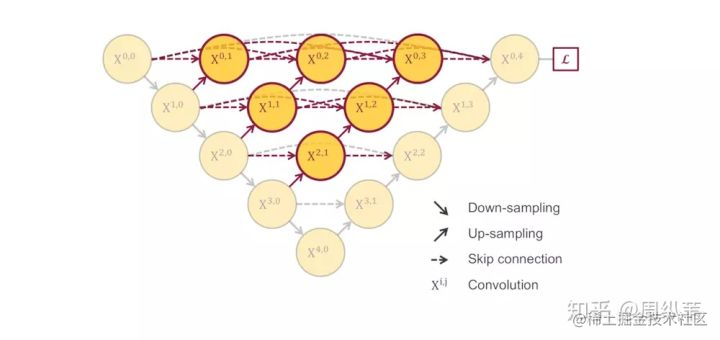
基本上就是這樣一個結構沒跑了是麼。我們來對比一下一開始的U-Net,它其實是這個結構的一個子集。這個結構,就是我們在MICCAI中發表的UNet++。熱心的網友可能會問哦,你的UNet++和剛剛說的那個CVPR的論文結構也太像了吧,我說一下這個工作和UC Berkeley的研究是完全兩個獨立的工作,也算是一個美麗的巧合。UNet++在今年年初時思路就已經成型了,CVPR那篇是我們今年七月份開會的時候看到的,當時UNet++已經被錄用了,所以相當於同時提出。另外,和CVPR的那篇論文相比,我還有一個更精彩的點埋在後面說,剛剛也留了一個伏筆。
好,當你現在盯著UNet++的時候,不知道會不會冷不丁會冒出來一個問題:
這個網路比U-Net效果好,但是這個網路增加了多少的引數,加粗的引數可都是比U-Net多出來的啊?
這個問題非常的尖銳,實際上是需要設計實驗來回答的,如何設計這個實驗呢?我們的做法是強行增加U-Net裡面的引數量,讓它變寬,也就是增加它每個層的卷積核個數。由此,我們設計了一個叫wide U-Net的參考結構,先來看看UNet++的引數數量是9.04M,而U-Net是7.76M,多了差不多16%的引數,所以wide U-Net我們在設計時就讓它的引數比UNet++差不多,並且還稍微多一點點,來證明並不是無腦增加引數量,模型效果就會好。
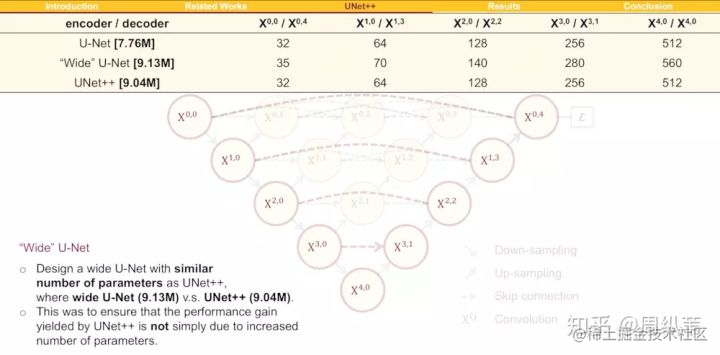
我本人是認為這個回擊力度並不大,因為這樣增加引數說心裡話有點敷衍,應該能找到更好的對比方法。儘管有不足,我們先來看看結果。
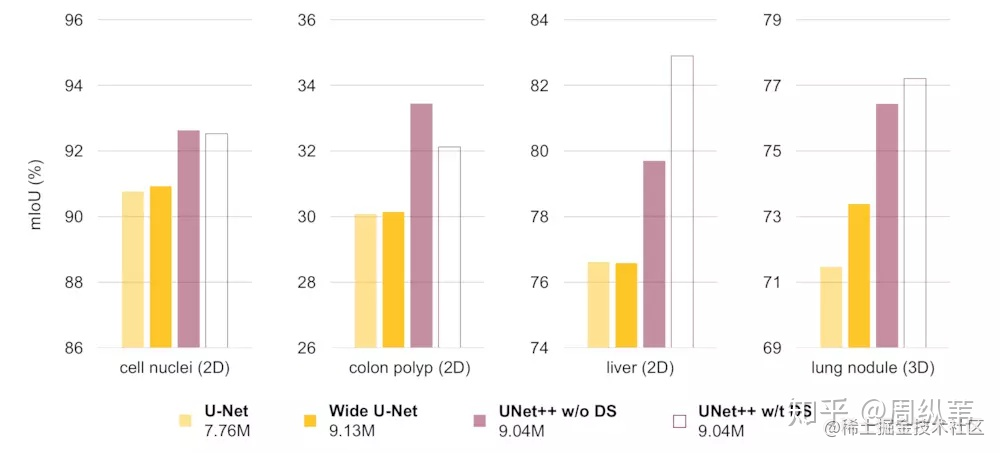
根據現有的結果,我的總結是,單純的把網路變寬,把引數提上去對效果的提升並不大,如何能把引數用在刀刃上是很重要的。那麼UNet++這種設計就是將引數用在刀刃上的一個方案。
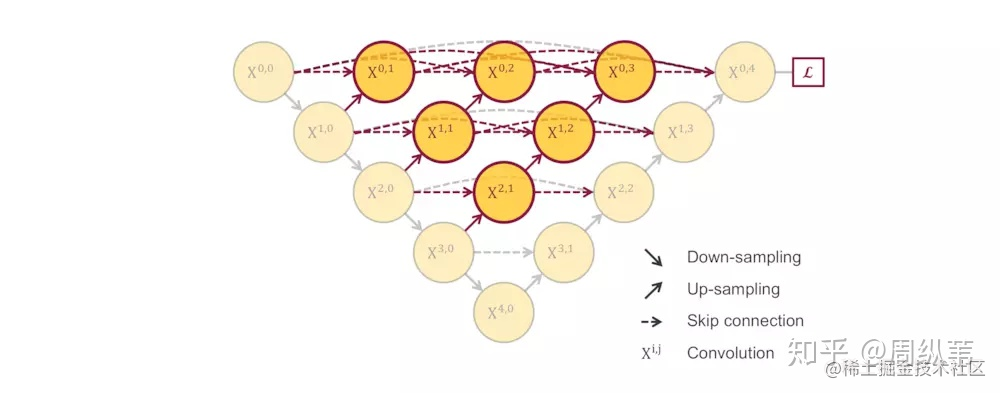
我們在回來看這個UNet++,對於這個主體結構,我們在論文中給出了一些點評,說白了就是把原來空心的U-Net填滿了,優勢是可以抓取不同層次的特徵,將它們通過特徵疊加的方式整合,不同層次的特徵,或者說不同大小的感受野,對於大小不一的目標物件的敏感度是不同的,比如,感受野大的特徵,可以很容易的識別出大物體的,但是在實際分割中,大物體邊緣資訊和小物體本身是很容易被深層網路一次次的降取樣和一次次升取樣給弄丟的,這個時候就可能需要感受野小的特徵來幫助。另一個解讀就是如果你橫著看其中一層的特徵疊加過程,就像一個去年很火的DenseNet的結構,非常的巧合,原先的U-Net,橫著看就很像是Residual的結構,這個就很有意思了,UNet++對於U-Net分割效果提升可能和DenseNet對於ResNet分類效果的提升,原因如出一轍,因此,在解讀中我們也參考了Dense Connection的一些優勢,比方說特徵的再利用等等。
這些解讀都是很直觀的認識,其實在深度學習裡面,某某結構效果優於某某結構的理由,或者你加這個操作比不加操作要好,很多時候是有玄學的味道在裡頭,也有大量的工作也在探索深度網路的可解釋性。關於UNet++的主體結構,我不想花時間贅述了。
## 4 高潮
接下來我要說的這部分,非常的有意思,如果這次分享就給我三分鐘,我可能就會花兩分半鐘在這裡。剛剛在講這裡的時候留了一個伏筆,說這個結構在反向傳播的時候中間部分會收不到過來的梯度,如果只用最右邊的一個loss來做的話。
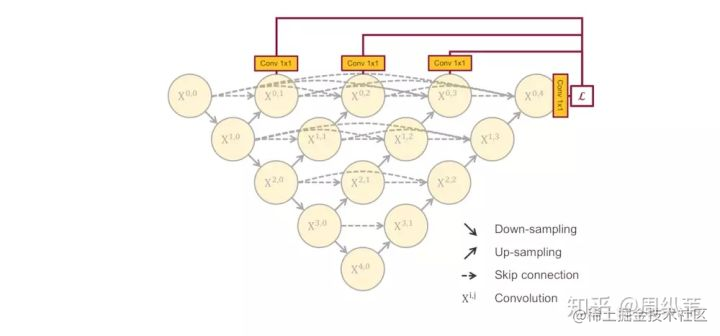
剛才說了,一個非常直接的解決方案就是深監督,也就是deep supervision。這個概念不是新的,有很多對U-Net對改進論文中也有用到,具體的實現操作就是在圖中 [公式] , [公式] , [公式] , [公式] 後面加一個1x1的卷積核,相當於去監督每個level,或者每個分支的U-Net的輸出。
我給大家提供三個用Deep Supervision的結構來比較,一個就是這個,第二個是加在UC Berkeley提出的結構上,最後一個是加在UNet++上,請問是你認為哪個會更棒?這是一個開放問題,我這裡不做展開討論,我們論文中使用的是最後一個。
因為deep supervision具體應該套在哪個結構上面不是我想說的重點,deep supervision的優點也在很多論文中有講解,我這裡想著重討論的是當它配合上這樣一個填滿的U-Net結構時,帶來其中一個非常棒的優勢。此處強烈建議暫停,想一想,如果我在訓練過程中在各個level的子網路中加了這種深監督,可以帶來怎樣的好處呢?
兩個字:剪枝。
同時引出三個問題:
- 為什麼UNet++可以被剪枝
- 如何剪枝
- 好處在哪裡
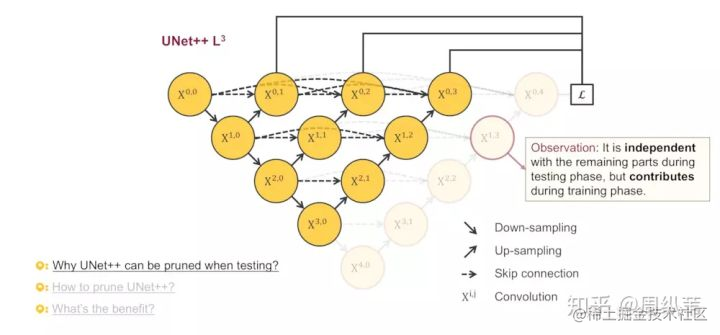
我們來看看為什麼可以剪枝,這張圖特別的精彩。關注被剪掉的這部分,你會發現,在測試的階段,由於輸入的影象只會前向傳播,扔掉這部分對前面的輸出完全沒有影響的,而在訓練階段,因為既有前向,又有反向傳播,被剪掉的部分是會幫助其他部分做權重更新的。這兩句話同樣重要,我再重複一遍,測試時,剪掉部分對剩餘結構不做影響,訓練時,剪掉部分對剩餘部分有影響。這意味什麼?
因為在深監督的過程中,每個子網路的輸出都其實已經是影象的分割結果了,所以如果小的子網路的輸出結果已經足夠好了,我們可以隨意的剪掉那些多餘的部分了。
來看一下這個動圖,為了定義的方便起見,我們把每個剪完剩下的子網路根據它們的深度命名為UNet++ L1,L2,L3,L4,後面會簡稱為L1~L4。最理想的狀態是什麼?當然是L1嘍,如果L1的輸出結果足夠好,剪完以後的分割網路會變得非常的小。
**這個剪枝其實很簡單, 跟決策樹的剪枝的規則相比簡單許多。因為Unet++會給出四個輸出,如果三層的那個輸出準確度夠高了,那麼就沒有必要在推理階段還要第四層的了。我記得從GoogleNet開始就有這種輔助輸出的概念了,GoogleNet是分類網路所以其中叫做輔助分類器(好像是),專業的概念應該是深度監督deep supervision,感興趣的可以查一下**
**在訓練階段我們需要四層的特徵指導來訓練,所以訓練中還是要用完整的模型來訓練。推理階段,作者考慮也許可以犧牲掉很小的精度來實現模型引數的大幅度減小(總之這個剪枝的技巧我覺得沒什麼用,仁者見仁哈)。好我們繼續看後面作者的解釋**
這裡我想問兩個問題:
- 為什麼要在測試的時候剪枝,而不是直接拿剪完的L1,L2,L3訓練?
- 怎麼去決定剪多少?
對於為什麼要在測試的時候剪枝,而不是直接拿剪完的L1,L2,L3訓練,我們的解釋其實上一頁ppt上面寫了,剪掉的部分在訓練時的反向傳播中是有貢獻的,如果直接拿L1,L2,L3訓練,就相當於只訓練了不同深度的U-Net,最後的結果會很差。
第二個問題,如何去決定剪多少,還是比較好回答的。因為在訓練模型的時候會把資料分為訓練集,驗證集和測試集,訓練集上是一定擬合的很好的,測試集是我們不能碰的,所以我們會根據子網路在驗證集的結果來決定剪多少。所謂的驗證集就是一開始從訓練集中分出來的資料,用來監測訓練過程用的。
好,講完了思路,我們來看結果。
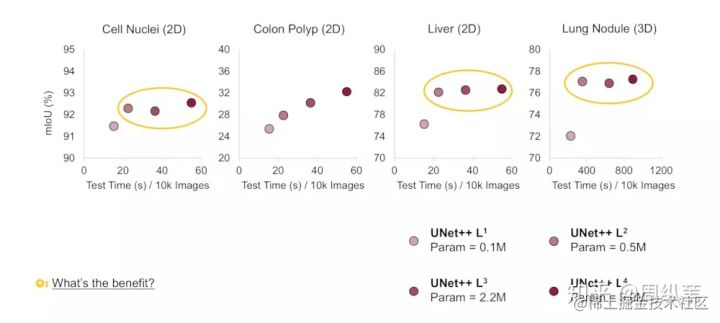
先看看L1~L4的網路引數量,差了好多,L1只有0.1M,而L4有9M,也就是理論上如果L1的結果我是滿意的,那麼模型可以被剪掉的引數達到98.8%。不過根據我們的四個資料集,L1的效果並不會那麼好,因為太淺了嘛。但是其中有三個資料集顯示L2的結果和L4已經非常接近了,也就是說對於這三個資料集,在測試階段,我們不需要用9M的網路,用半M的網路足夠了。
回想一下一開始我提出的問題,網路需要多深合適,這幅圖是不是就一目瞭然。網路的深度和資料集的難度是有關係的,這四個資料集當中,第二個,也就是息肉分割是最難的,大家可以看到縱座標,它代表分割的評價指標,越大越好,其他都能達到挺高的,但是唯獨息肉分割只有在30左右,對於比較難的資料集,可以看到網路越深,它的分割結果是在不斷上升的。對於大多數比較簡單的分割問題,其實並不需要非常深,非常大的網路就可以達到很不錯的精度了。
橫座標代表的是在測試階段,單顯示卡12G的TITAN X (Pascal)下,分割一萬張圖需要的時間。我們可以看到不同的模型大小,測試的時間差好多。如果比較L2和L4的話,就差了三倍之多。
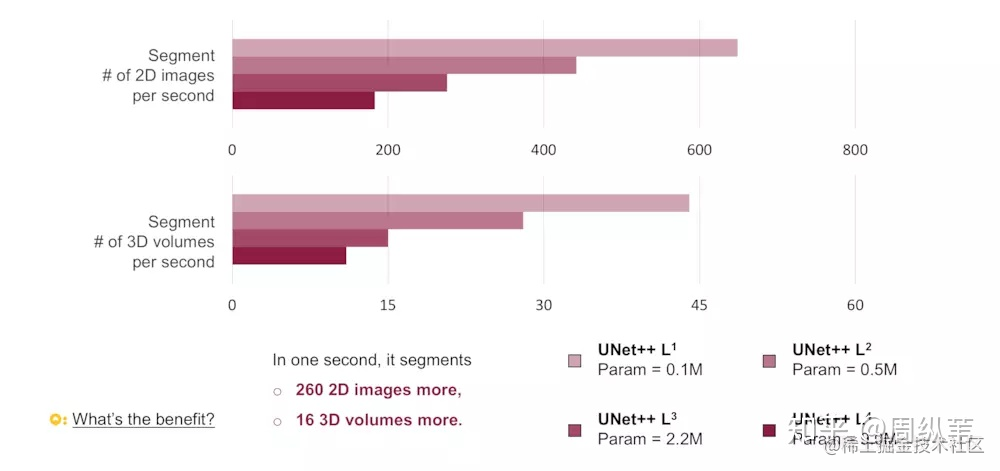
對於測試的速度,用這一幅圖會更清晰。我們統計了用不同的模型,1秒鐘可以分割多少的圖。如果用L2來代替L4的話,速度確實能提升三倍。
剪枝應用最多的就是在移動手機端了,根據模型的引數量,如果L2得到的效果和L4相近,模型的記憶體可以省18倍。還是非常可觀的數目。
關於剪枝的這部分我認為是對原先的U-Net的一個很大的改觀,原來的結構過於刻板,並且沒有很好的利用不用層級的特徵。
簡單的總結一下,UNet++的第一個優勢就是精度的提升,這個應該它整合了不同層次的特徵所帶來的,第二個是靈活的網路結構配合深監督,讓引數量巨大的深度網路在可接受的精度範圍內大幅度的縮減引數量。
## 5 最後一提
再次放上我們的UNet++結構
![](https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/8ecd1a0a179c4da9a73554def08e1d2b~tplv-k3u1fbpfcp-watermar